COPEN
1.0.0
EMNLP 2022論文的數據集和代碼“哥倫:探測預訓練的語言模型中的概念知識”。 Copen是一種概念知識門檻基準,旨在分析預訓練的語言模型(PLM)的概念理解能力。具體而言,哥倫族由三個任務組成:
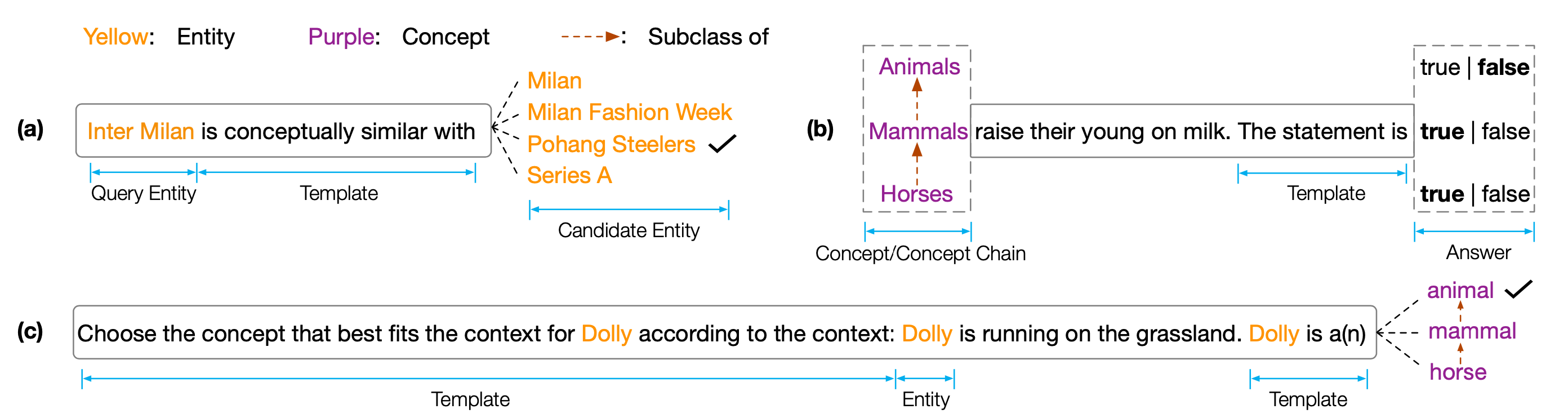
對不同尺寸和類型的PLM類型的廣泛實驗表明,現有的PLM系統地缺乏概念知識,並且遭受了各種虛假相關性。我們認為,這是實現PLM中類似人類認知的關鍵瓶頸。需要更多的概念意識的目標或架構來開發概念知識淵博的PLM。
要獲得測試結果,您需要將結果提交給Codalab。
代碼存儲庫基於Pytorch和Transformers 。請使用以下命令安裝所有必要的依賴性。 pip install -r requirements.txt
將副基準放置在Tsinghua Cloud上,請使用以下命令下載數據集並將其放置在預言路徑中。
cd data/
wget --content-disposition https://cloud.tsinghua.edu.cn/f/f0b33fb429fa4575aa7f/ ? dl=1
unzip copen_data.zip
mkdir task1/data
mkdir task2/data
mkdir task3/data
mv copen_data/task1/ * task1/data
mv copen_data/task2/ * task2/data
mv copen_data/task3/ * task3/data cd task1
python probing_data_processor.py
cd ../
cd task2
python probing_data_processor.py
cd ../
cd task3
python probing_data_processor.py
cd ../python processor_utils.py task1 mc
python processor_utils.py task2 sc
python processor_utils.py task3 mc cd code/probing
bash task1/run.sh 0 bert bert-base-uncased
bash task2/run.sh 0 bert bert-base-uncased
bash task3/run.sh 0 bert bert-base-uncased cd code/finetuning
cd task1/
bash ../run.sh 0 bert bert-base-uncased task1 mc 42
cd task2/
bash ../run.sh 0 bert bert-base-uncased task2 sc 42
cd task3/
bash ../run.sh 0 bert bert-base-uncased task3 mc 42如果我們的代碼或基準對您有所幫助,請引用我們:
@inproceedings{peng2022copen,
title={COPEN: Probing Conceptual Knowledge in Pre-trained Language Models},
author={Peng, Hao and Wang, Xiaozhi and Hu, Shengding and Jin, Hailong and Hou, Lei and Li, Juanzi and Liu, Zhiyuan and Liu, Qun},
booktitle={Proceedings of EMNLP},
year={2022}
}


