COPEN
1.0.0
EMNLP 2022 Paper '' Copenのデータセットとコード:事前に訓練された言語モデルにおける概念的知識の調査」。コペンは、事前訓練された言語モデル(PLM)の概念的理解能力を分析することを目的とする概念的知識ポロビングベンチマークです。具体的には、コペンは3つのタスクで構成されています。
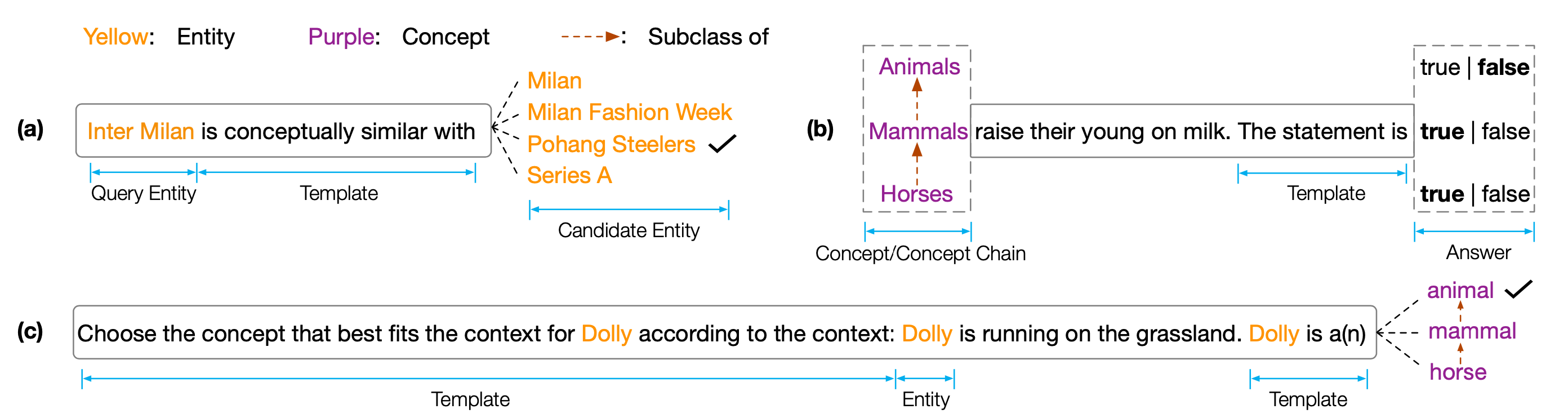
さまざまなサイズとタイプのPLMでの広範な実験は、既存のPLMが体系的に概念的知識を欠いており、さまざまな偽の相関に苦しんでいることを示しています。これは、PLMSで人間のような認知を実現するための重要なボトルネックであると考えています。概念的な知識豊富なPLMSを開発するには、より概念的な目標またはアーキテクチャが必要です。
テスト結果を取得するには、結果をCodalabに提出する必要があります。
コードリポジトリは、 PytorchとTransformersに基づいています。次のコマンドを使用して、必要なすべての依存関係をインストールしてください。 pip install -r requirements.txt
コペンベンチマークはTsinghua Cloudに配置されています。次のコマンドを使用してデータセットをダウンロードし、プロポーパスに配置してください。
cd data/
wget --content-disposition https://cloud.tsinghua.edu.cn/f/f0b33fb429fa4575aa7f/ ? dl=1
unzip copen_data.zip
mkdir task1/data
mkdir task2/data
mkdir task3/data
mv copen_data/task1/ * task1/data
mv copen_data/task2/ * task2/data
mv copen_data/task3/ * task3/data cd task1
python probing_data_processor.py
cd ../
cd task2
python probing_data_processor.py
cd ../
cd task3
python probing_data_processor.py
cd ../python processor_utils.py task1 mc
python processor_utils.py task2 sc
python processor_utils.py task3 mc cd code/probing
bash task1/run.sh 0 bert bert-base-uncased
bash task2/run.sh 0 bert bert-base-uncased
bash task3/run.sh 0 bert bert-base-uncased cd code/finetuning
cd task1/
bash ../run.sh 0 bert bert-base-uncased task1 mc 42
cd task2/
bash ../run.sh 0 bert bert-base-uncased task2 sc 42
cd task3/
bash ../run.sh 0 bert bert-base-uncased task3 mc 42私たちのコードやベンチマークがあなたを助けているなら、私たちを引用してください:
@inproceedings{peng2022copen,
title={COPEN: Probing Conceptual Knowledge in Pre-trained Language Models},
author={Peng, Hao and Wang, Xiaozhi and Hu, Shengding and Jin, Hailong and Hou, Lei and Li, Juanzi and Liu, Zhiyuan and Liu, Qun},
booktitle={Proceedings of EMNLP},
year={2022}
}


