COPEN
1.0.0
EMNLP 2022 용 데이터 세트 및 코드``코펜 : 사전 훈련 된 언어 모델에 대한 개념적 지식 조사 ''. Copen은 사전 훈련 된 언어 모델 (PLM)의 개념적 이해 능력을 분석하는 것을 목표로하는 개념적 지식 Porobing 벤치 마크입니다. 특히 Copen은 세 가지 작업으로 구성됩니다.
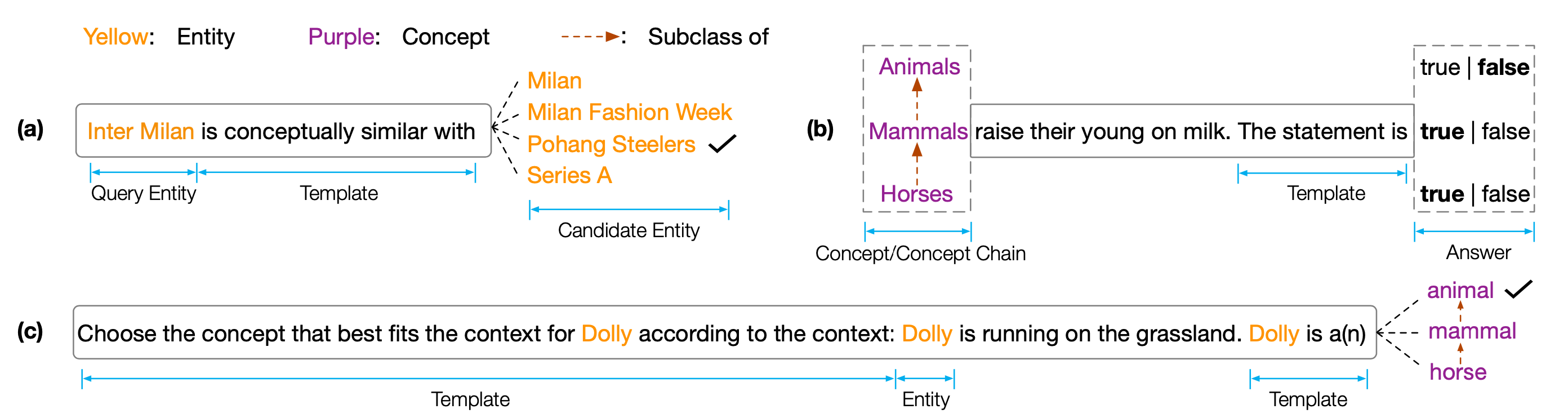
다양한 크기와 유형의 PLM에 대한 광범위한 실험은 기존 PLM이 체계적으로 개념적 지식이 부족하고 다양한 가짜 상관 관계를 겪음을 보여줍니다. 우리는 이것이 PLM에서 인간과 같은 인식을 실현하기위한 중요한 병목 현상이라고 생각합니다. 개념적 지식이 풍부한 PLM을 개발하려면 더 많은 개념 인식 목표 또는 아키텍처가 필요합니다.
테스트 결과를 얻으려면 결과를 Codalab에 제출해야합니다.
코드 저장소는 Pytorch 및 Transformers 기반으로합니다. 다음 명령을 사용하여 필요한 모든 부양 가족을 설치하십시오. pip install -r requirements.txt
Copen 벤치 마크는 Tsinghua Cloud에 배치됩니다. 다음 명령을 사용하여 데이터 세트를 다운로드하여 Propor 경로에 배치하십시오.
cd data/
wget --content-disposition https://cloud.tsinghua.edu.cn/f/f0b33fb429fa4575aa7f/ ? dl=1
unzip copen_data.zip
mkdir task1/data
mkdir task2/data
mkdir task3/data
mv copen_data/task1/ * task1/data
mv copen_data/task2/ * task2/data
mv copen_data/task3/ * task3/data cd task1
python probing_data_processor.py
cd ../
cd task2
python probing_data_processor.py
cd ../
cd task3
python probing_data_processor.py
cd ../python processor_utils.py task1 mc
python processor_utils.py task2 sc
python processor_utils.py task3 mc cd code/probing
bash task1/run.sh 0 bert bert-base-uncased
bash task2/run.sh 0 bert bert-base-uncased
bash task3/run.sh 0 bert bert-base-uncased cd code/finetuning
cd task1/
bash ../run.sh 0 bert bert-base-uncased task1 mc 42
cd task2/
bash ../run.sh 0 bert bert-base-uncased task2 sc 42
cd task3/
bash ../run.sh 0 bert bert-base-uncased task3 mc 42우리의 코드 나 벤치 마크가 도움이되면 우리를 인용하십시오.
@inproceedings{peng2022copen,
title={COPEN: Probing Conceptual Knowledge in Pre-trained Language Models},
author={Peng, Hao and Wang, Xiaozhi and Hu, Shengding and Jin, Hailong and Hou, Lei and Li, Juanzi and Liu, Zhiyuan and Liu, Qun},
booktitle={Proceedings of EMNLP},
year={2022}
}


