COPEN
1.0.0
Datensatz und Code für EMNLP 2022 Papier '' Kopen: Konzeptuelle Kenntnisse in vorgeborenen Sprachmodellen ''. Kopen ist ein konzeptionelles Wissen, das die konzeptionelle Verständnisfunktionen von vorgeborenen Sprachmodellen (PLMs) analysieren sollen. Insbesondere besteht Kopen aus drei Aufgaben:
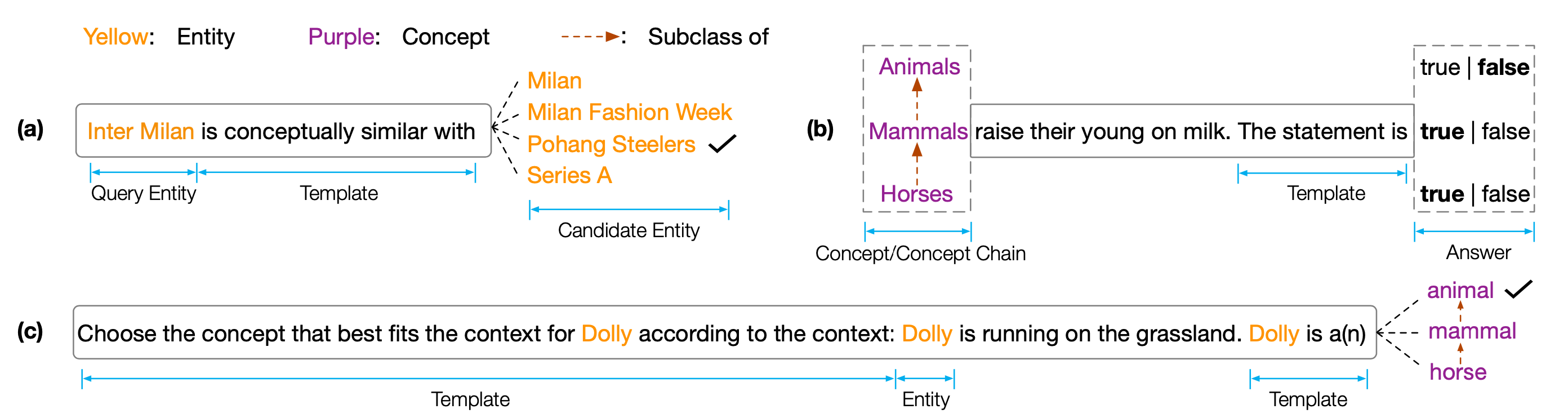
Umfangreiche Experimente an verschiedenen Größen und Arten von PLMs zeigen, dass vorhandener PLMs systematisch konzeptionelles Wissen fehlt und an verschiedenen falschen Korrelationen leiden. Wir glauben, dass dies ein kritischer Engpass für die Verwirklichung der menschlichen Kognition in PLMs ist. Es sind mehr konzeptbewusste Ziele oder Architekturen erforderlich, um konzeptionelle sachkundige PLMs zu entwickeln.
Um die Testergebnisse zu erhalten, müssen Sie Ihre Ergebnisse an Codalab senden.
Das Code -Repository basiert auf Pytorch und Transformers . Bitte verwenden Sie den folgenden Befehl, um alle erforderlichen Abhängigkeiten zu installieren. pip install -r requirements.txt
Der Kopen -Benchmark wird in Tsinghua Cloud platziert. Bitte verwenden Sie den folgenden Befehl, um die Datensätze herunterzuladen und in den Proporpfad zu platzieren.
cd data/
wget --content-disposition https://cloud.tsinghua.edu.cn/f/f0b33fb429fa4575aa7f/ ? dl=1
unzip copen_data.zip
mkdir task1/data
mkdir task2/data
mkdir task3/data
mv copen_data/task1/ * task1/data
mv copen_data/task2/ * task2/data
mv copen_data/task3/ * task3/data cd task1
python probing_data_processor.py
cd ../
cd task2
python probing_data_processor.py
cd ../
cd task3
python probing_data_processor.py
cd ../python processor_utils.py task1 mc
python processor_utils.py task2 sc
python processor_utils.py task3 mc cd code/probing
bash task1/run.sh 0 bert bert-base-uncased
bash task2/run.sh 0 bert bert-base-uncased
bash task3/run.sh 0 bert bert-base-uncased cd code/finetuning
cd task1/
bash ../run.sh 0 bert bert-base-uncased task1 mc 42
cd task2/
bash ../run.sh 0 bert bert-base-uncased task2 sc 42
cd task3/
bash ../run.sh 0 bert bert-base-uncased task3 mc 42Wenn unsere Codes oder Benchmark Ihnen helfen, zitieren Sie uns bitte:
@inproceedings{peng2022copen,
title={COPEN: Probing Conceptual Knowledge in Pre-trained Language Models},
author={Peng, Hao and Wang, Xiaozhi and Hu, Shengding and Jin, Hailong and Hou, Lei and Li, Juanzi and Liu, Zhiyuan and Liu, Qun},
booktitle={Proceedings of EMNLP},
year={2022}
}


