worldcuisines
1.0.0
介紹? WorldCuisines是一種大規模的多語言和多元文化VQA基準,挑戰了視覺語言模型(VLMS),以了解9個語言家族的30多種語言和方言中的文化食品多樣性,其中有超過100萬個數據點可從2.4k菜餚中獲得6K圖像。作為基準,我們有三套:

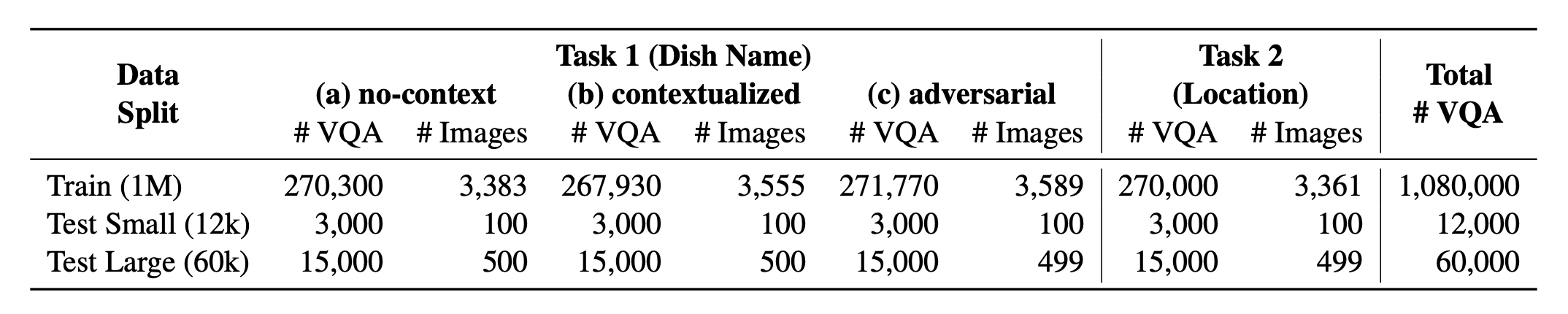
?世界助理?包括其兩個受支持的任務中的平衡比例。我們提供超過100萬的培訓數據和60K評估數據。我們的基準測試評估VLM在兩個任務上:DISH名稱預測和DIS位置預測。這些設置包括無關,上下文化和對抗性注入的提示,作為模型的輸入。
我們的數據集可用嗎?擁抱面部數據集。可以找到支持KB數據?擁抱面部數據集。
這是論文[arxiv]的源代碼。此代碼是使用Python編寫的。如果您在研究中使用此工具包中的任何代碼或數據集,請引用相關論文。
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
}如果您想獲得我們評估的所有VLLM的最終結果,請參閱此排行榜以獲取摘要。原始結果放置在evaluation/score/json目錄中。
請運行以下命令以安裝所需的庫以復制基準結果。
pip pip install -r requirements.txt
conda conda env create -f env.yml
對於Pangea,請運行以下內容
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
所有實驗結果將存儲在evaluation/result/目錄中。使用所有任務的精度(特別是針對開放式任務(OEQ))評估結果,我們使用使用多參考計算的精度。您可以使用以下命令執行每個實驗:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| 爭論 | 描述 | 示例 /默認值 |
|---|---|---|
--task | 評估的任務編號(1或2) | 1 (默認), 2 |
--type | 評估的問題類型( oe或mc ) | mc (默認), oe |
--model_path | 通往模型的路徑 | Qwen/Qwen2-VL-72B-Instruct (默認) +其他 |
--fp32 | 使用float32代替float16 / bfloat16 | False (默認) |
--multi_gpu | 使用多個GPU | False (默認) |
-n , --chunk_num | 將數據拆分為 | 1 (默認) |
-k , --chunk_id | 塊ID(基於0) | 0 (默認) |
-s , --st_idx | 啟動切片數據的索引(包括) | None (默認) |
-e , --ed_idx | 切片數據的結束索引(獨家) | None (默認) |
我們支持以下模型(您可以修改我們的代碼以使用其他模型進行評估)。
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (請按照環境設置中提到的安裝LLAVA)編輯evaluation/score/score.yml以確定評分模式,評估集和評估VLM。請注意, mc表示多項選擇,而oe表示開放式。
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash除了生成oe分數的multi模式(將答案與所有語言的黃金標籤進行比較)外,我們還支持其他黃金標籤參考設置:
single參考:僅將答案與原始語言的金標籤進行比較。dual參考:將原始語言和英語的黃金標籤的答案比較。設置後,運行此命令:
cd evaluation/score/
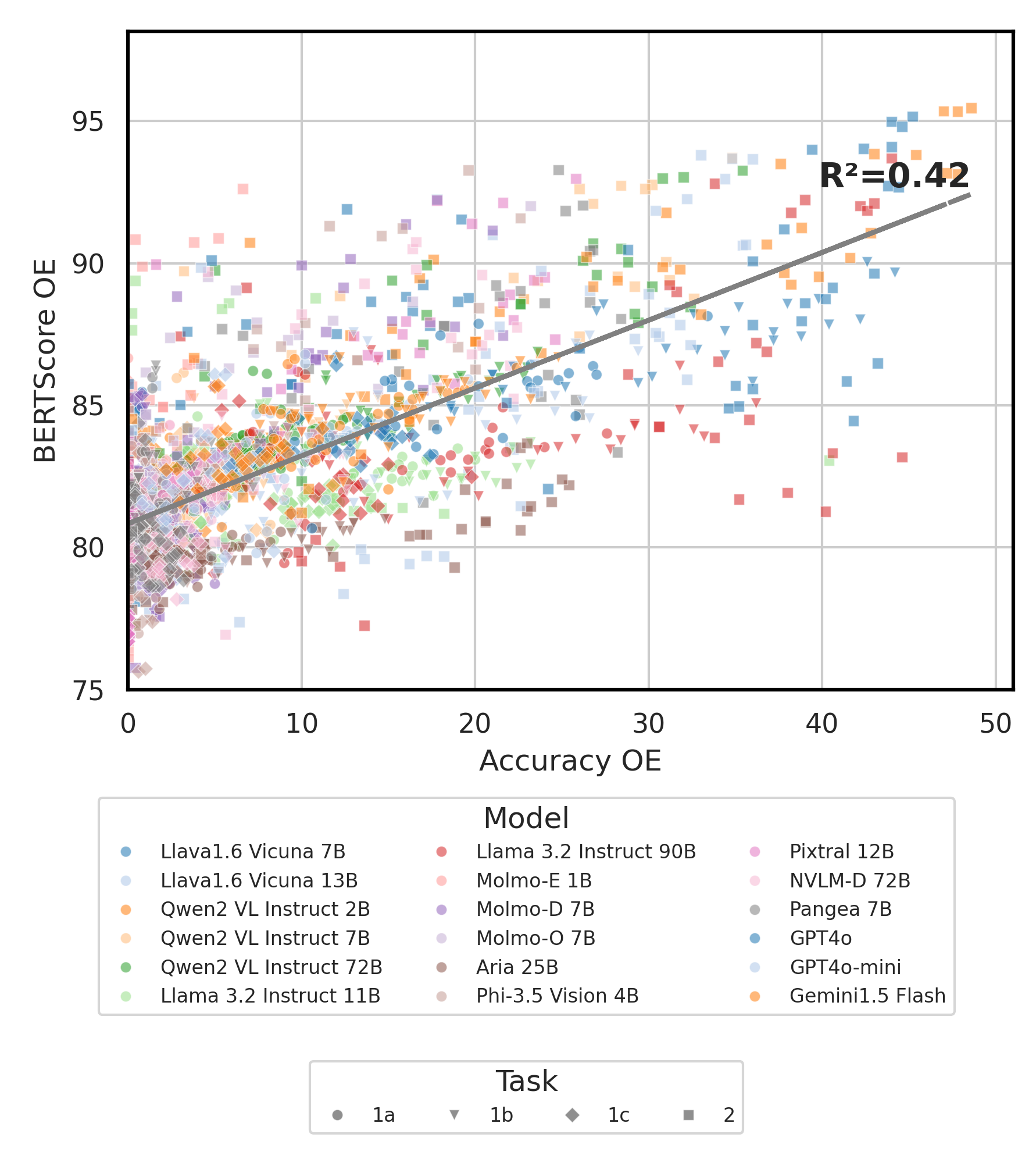
python score.py我們提供雷達,散射和連接的散點線圖,以可視化所有VLM的評分結果evaluation/score/plot/ 。
要生成所有雷達圖,請使用:
python evaluation/score/plot/visualization.py
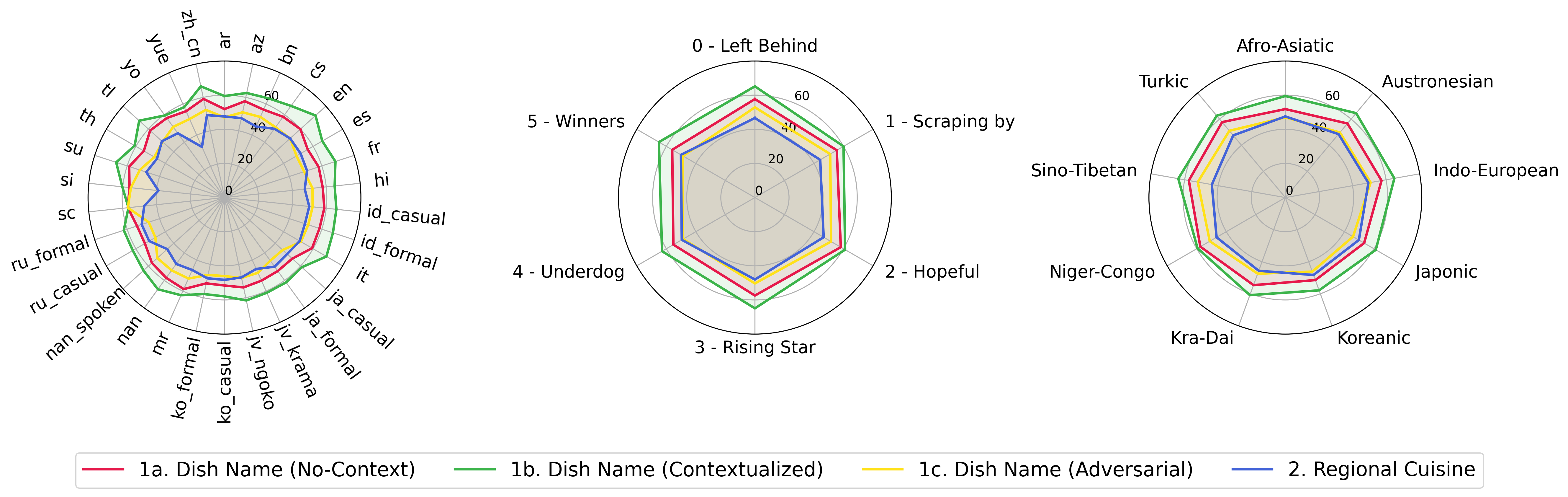
您還可以修改evaluation/score/score.yml plot_mapper.yml
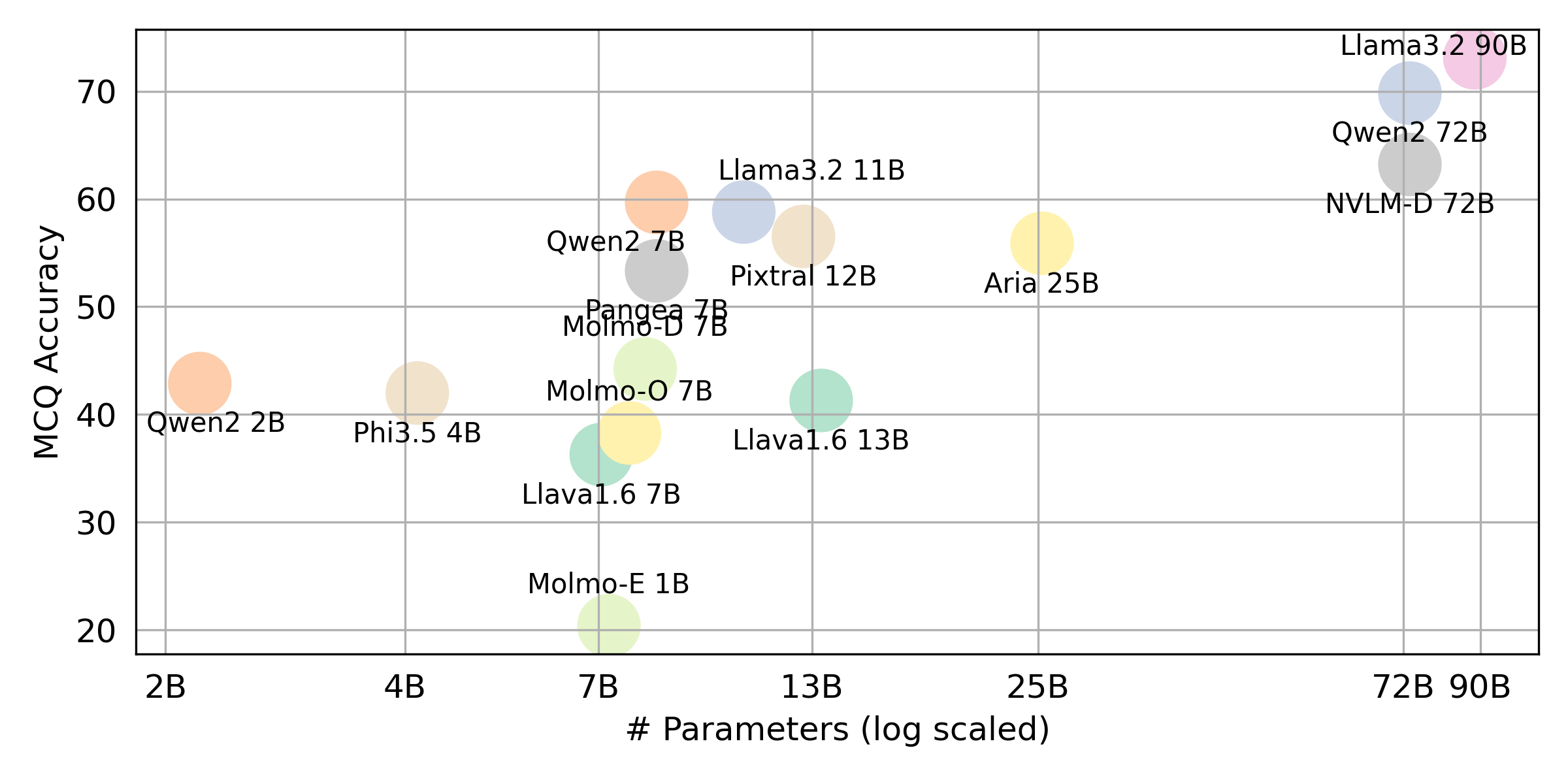
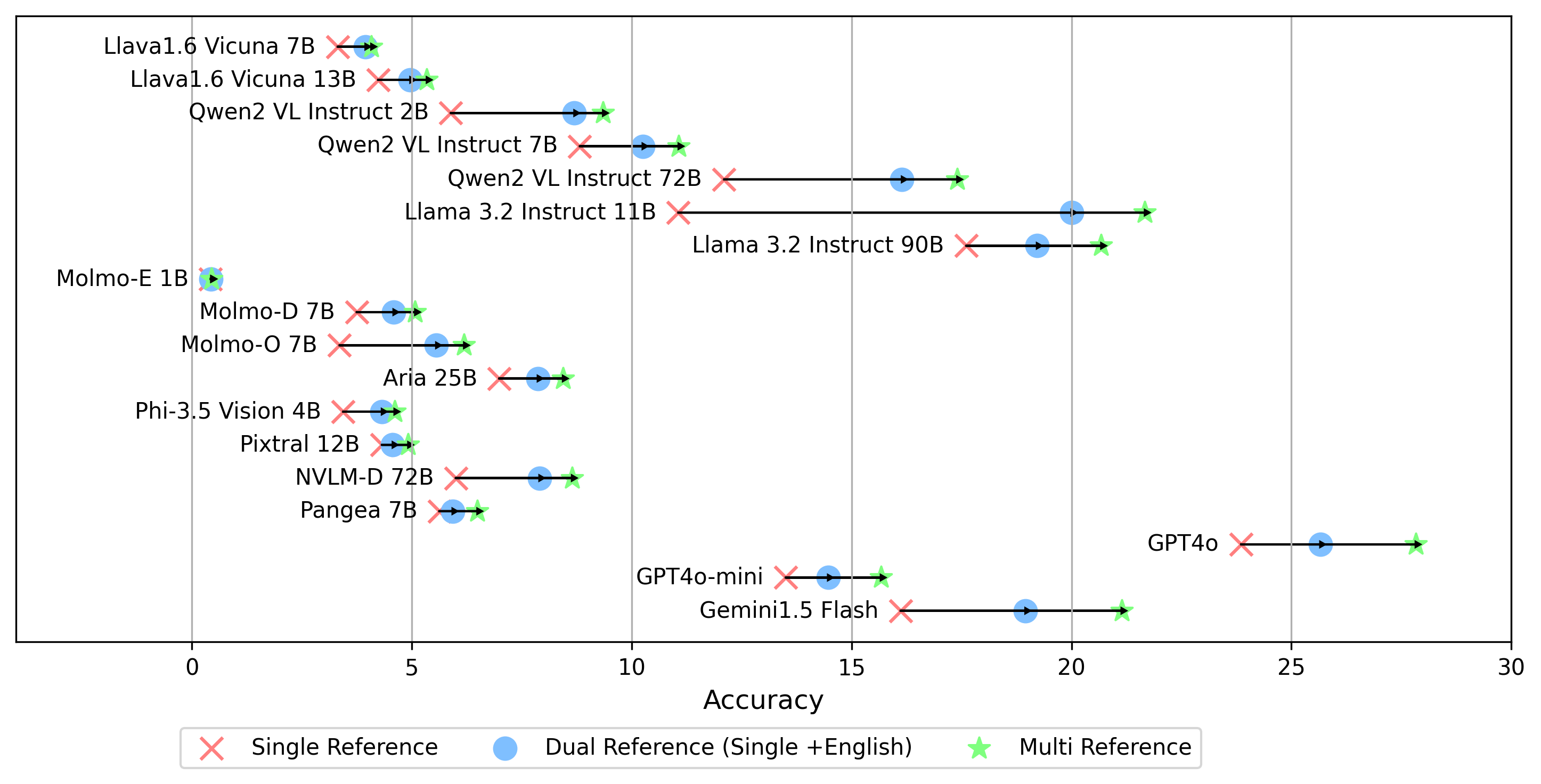
其他繪圖生成腳本在同一目錄中的*.ipynb文件中可用。
我們的代碼庫支持多個模型的實驗使用,為自定義列表提供了靈活性:
(截至2024年10月,上一次測試)
要從知識庫生成VQA數據集,您可以參考generate_vqa/sampling.py腳本。該腳本在培訓和測試集中生成了用於各種任務的數據集。
示例命令:要生成用於測試小型,測試大型和火車集的數據集,請運行以下命令:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| 爭論 | 描述 | 例子 |
|---|---|---|
-o , --output-csv | 輸出CSV路徑將保存生成的VQA數據集。 | generated_data/test_small_task1.csv |
-n , --num-samples | 要生成的最大實例數。如果要求的樣本超出可能,則腳本將進行調整。 | 9000 |
-nd , --n-dish-max | 最大唯一的菜餚來品嚐。 | 100 |
-np1a , --n-prompt-max-type1a | 在每次迭代中,任務1(a)(a)(無封閉式)的最大唯一提示。 | 1 |
-np1b , --n-prompt-max-type1b | 任務1(b)(上下文化)到每道迭代中每道菜的最大唯一提示。 | 1 |
-np1c , --n-prompt-max-type1c | 任務1(c)(對抗)到每道迭代中每道菜的最大唯一提示。 | 1 |
-np2 , --n-prompt-max-type2 | 在每次迭代中,任務2到每道菜的最大唯一提示。 | 1 |
--is-eval , --no-is-eval | 是生成評估(測試)還是培訓數據集。 | --is-eval測試, --no-is-eval for Train |
| 爭論 | 描述 | 例子 |
|---|---|---|
-fr , --food-raw-path | 通往生食數據CSV的路徑。 | food_raw_6oct.csv |
-fc , --food-cleaned-path | 通往清潔食品數據CSV的路徑。 | food_cleaned.csv |
-q , --query-context-path | 查詢上下文CSV的路徑。 | query_ctx.csv |
-l , --loc-cuis-path | 通往位置和美食CSV的路徑。 | location_and_cuisine.csv |
-ll , --list-of-languages | 指定語言用作字符串列表。 | '["en", "id_formal"]' |
-aw , --alias-aware | 用平行別名啟用對抗答案 | --alias-aware需要查找包含所有語言平行翻譯的答案的要求, --no-alias-aware放鬆並行菜餚名稱要求 |
如果您有任何疑問,請隨時創建問題。並且,創建用於修復錯誤或添加改進的PR。
如果您有興趣創建這項工作的擴展,請隨時與我們聯繫!
支持我們的開源工作
我們正在改進代碼,尤其是在推理部分上,以生成evaluation/result和評分可視化代碼統一,以使其更具用戶友好和可定制。


