worldcuisines
1.0.0
紹介? WorldCuisinesは、 9つの言語ファミリで30を超える言語と方言の文化的食物の多様性を理解するためにビジョン言語モデル(VLM)に挑戦する大規模な多言語および多文化VQAベンチマークであり、 6K画像の2.4K料理から生成された100万件以上のデータポイントがあります。ベンチマークとして、3つのセットがあります。

? worldcuisines?サポートされている2つのタスクのバランスの取れた割合で構成されています。 1Mを超えるトレーニングデータと60kの評価データを提供します。私たちのベンチマークは、皿名の予測と皿の場所の予測という2つのタスクでVLMを評価します。設定には、モデルの入力として、非コンテキスト、コンテキスト化、および敵対的な注入プロンプトが含まれます。
データセットはで利用できますか?フェイスデータセットを抱き締める。サポートするKBデータはで見つけることができますか?フェイスデータセットを抱き締める。
これは、ペーパー[arxiv]のソースコードです。このコードは、Pythonを使用して記述されています。調査でこのツールキットのコードまたはデータセットを使用する場合は、関連する論文を引用してください。
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
}私たちが評価するすべてのVLLMの最終結果を取得したい場合は、要約についてはこのリーダーボードを参照してください。生の結果はevaluation/score/jsonディレクトリに配置されます。
次のコマンドを実行して、ベンチマーク結果を再現するために必要なライブラリをインストールしてください。
pip経由 pip install -r requirements.txt
conda経由 conda env create -f env.yml
Pangeaについては、以下を実行してください
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
すべての実験結果はevaluation/result/ディレクトリに保存されます。結果は、すべてのタスクの精度を使用して評価されます。特に、オープンエンドタスク(OEQ)に対して、マルチリファレンスを使用して計算された精度を使用します。次のコマンドを使用して各実験を実行できます。
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| 口論 | 説明 | 例 /デフォルト |
|---|---|---|
--task | 評価するタスク番号(1または2) | 1 (デフォルト)、 2 |
--type | 評価する質問の種類( oeまたはmc ) | mc (デフォルト)、 oe |
--model_path | モデルへのパス | Qwen/Qwen2-VL-72B-Instruct (デフォルト) +その他 |
--fp32 | float16 / bfloat16の代わりにfloat32使用します | False (デフォルト) |
--multi_gpu | 複数のGPUを使用します | False (デフォルト) |
-n 、 --chunk_num | データを分割するチャンクの数 | 1 (デフォルト) |
-k 、 --chunk_id | チャンクID(0ベース) | 0 (デフォルト) |
-s 、 --st_idx | スライスデータのインデックスを開始する(包括的) | None (デフォルト) |
-e 、 --ed_idx | スライスデータの終了インデックス(排他的) | None (デフォルト) |
次のモデルをサポートします(他のモデルで評価を実行するためにコードを変更できます)。
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (⚡環境セットアップに記載されているようにLlavaをインストールしてください)evaluation/score/score.ymlを編集して、スコアリングモード、評価セット、および評価されたVLMを決定します。 mc複数選択を意味し、 oeオープンエンドを意味することに注意してください。
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flashすべての言語のゴールデンラベルと比較するoeスコアを生成するためのmultiモードに加えて、他のゴールデンラベル参照設定もサポートしています。
single参照:答えを元の言語のゴールデンラベルと比較します。dualリファレンス:元の言語と英語のゴールデンラベルとの答えを比較します。設定したら、このコマンドを実行します。
cd evaluation/score/
python score.pyevaluation/score/plot/のすべてのVLMのスコアリング結果を視覚化するために、レーダー、散布、および接続された散布線プロットを提供します。
すべてのレーダープロットを生成するには、使用してください。
python evaluation/score/plot/visualization.py
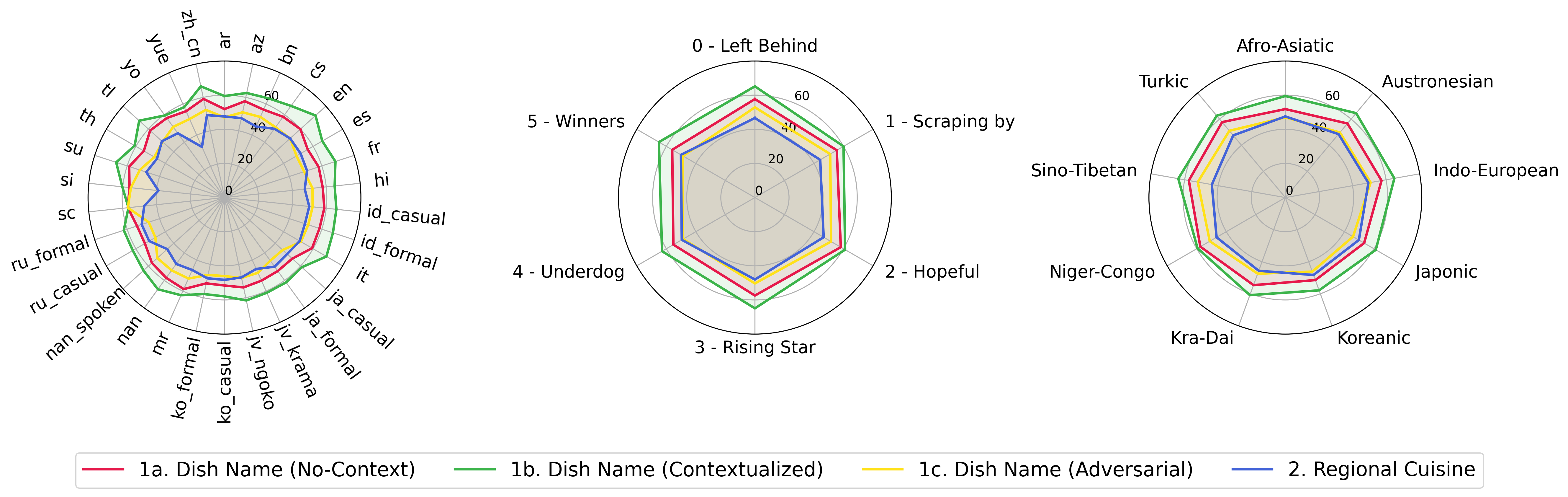
また、 evaluation/score/score.ymlを変更して、 plot_mapper.ymlのプロットラベルを視覚化および調整するVLMSを選択することもできます。
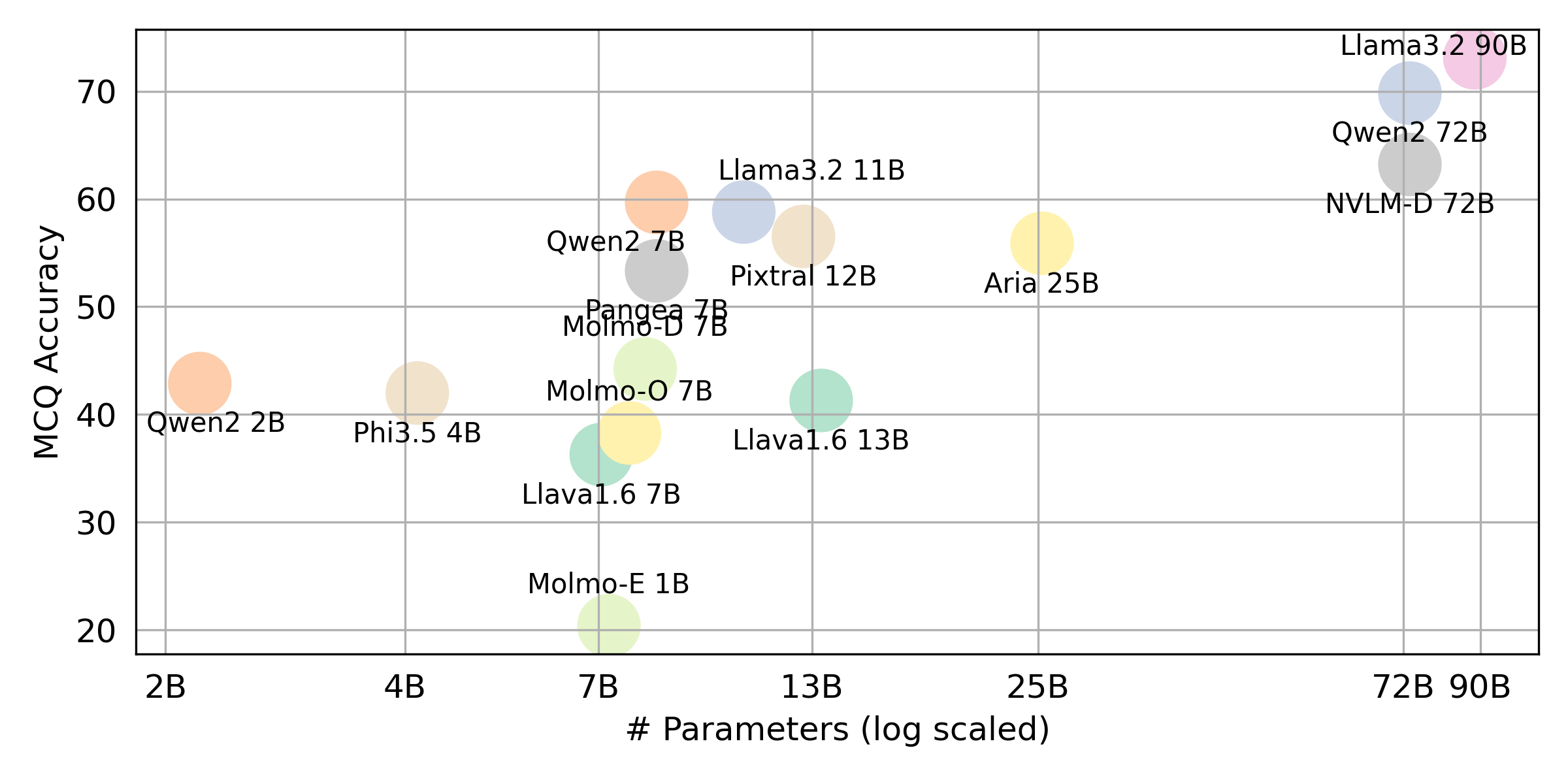
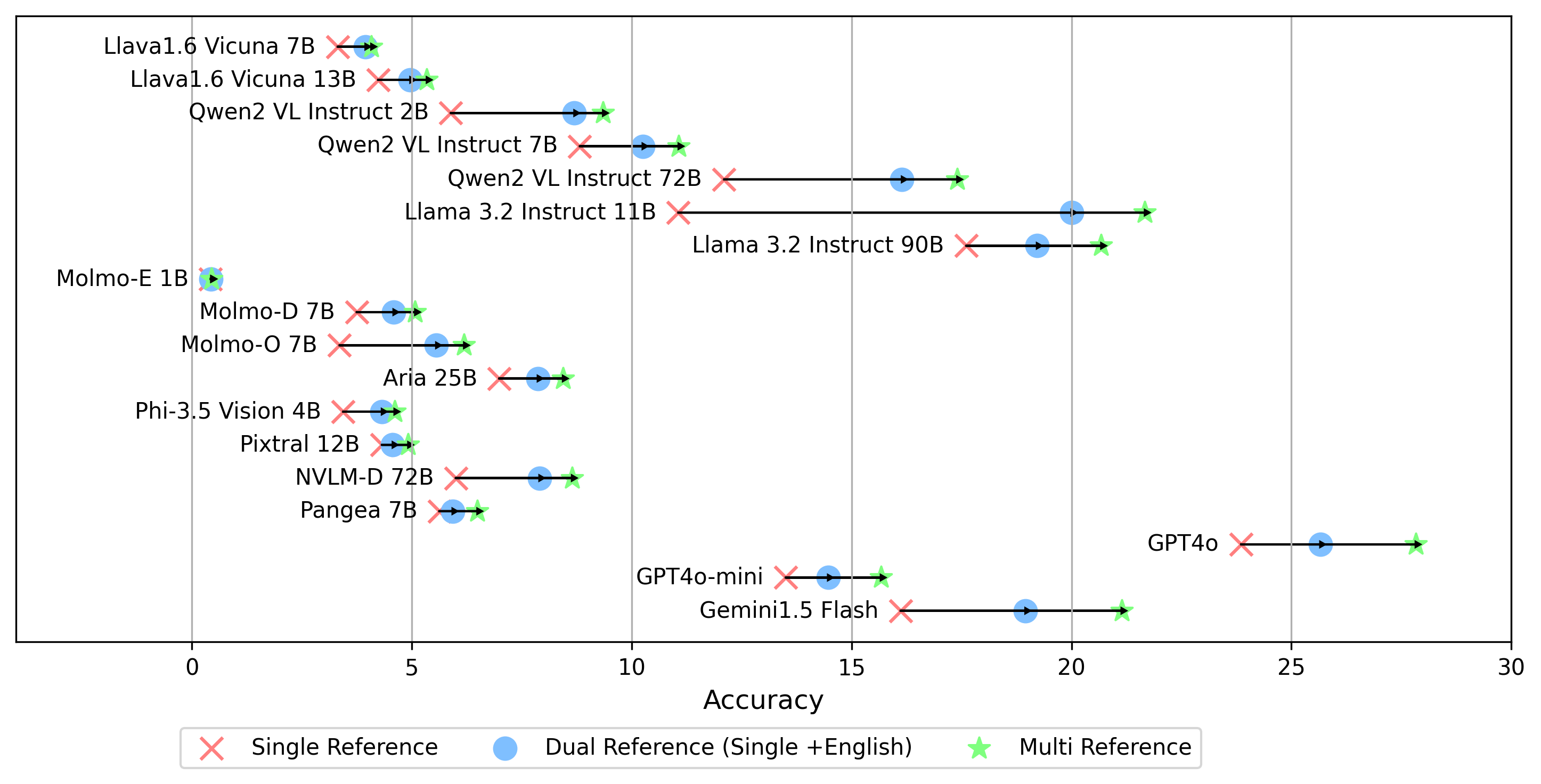
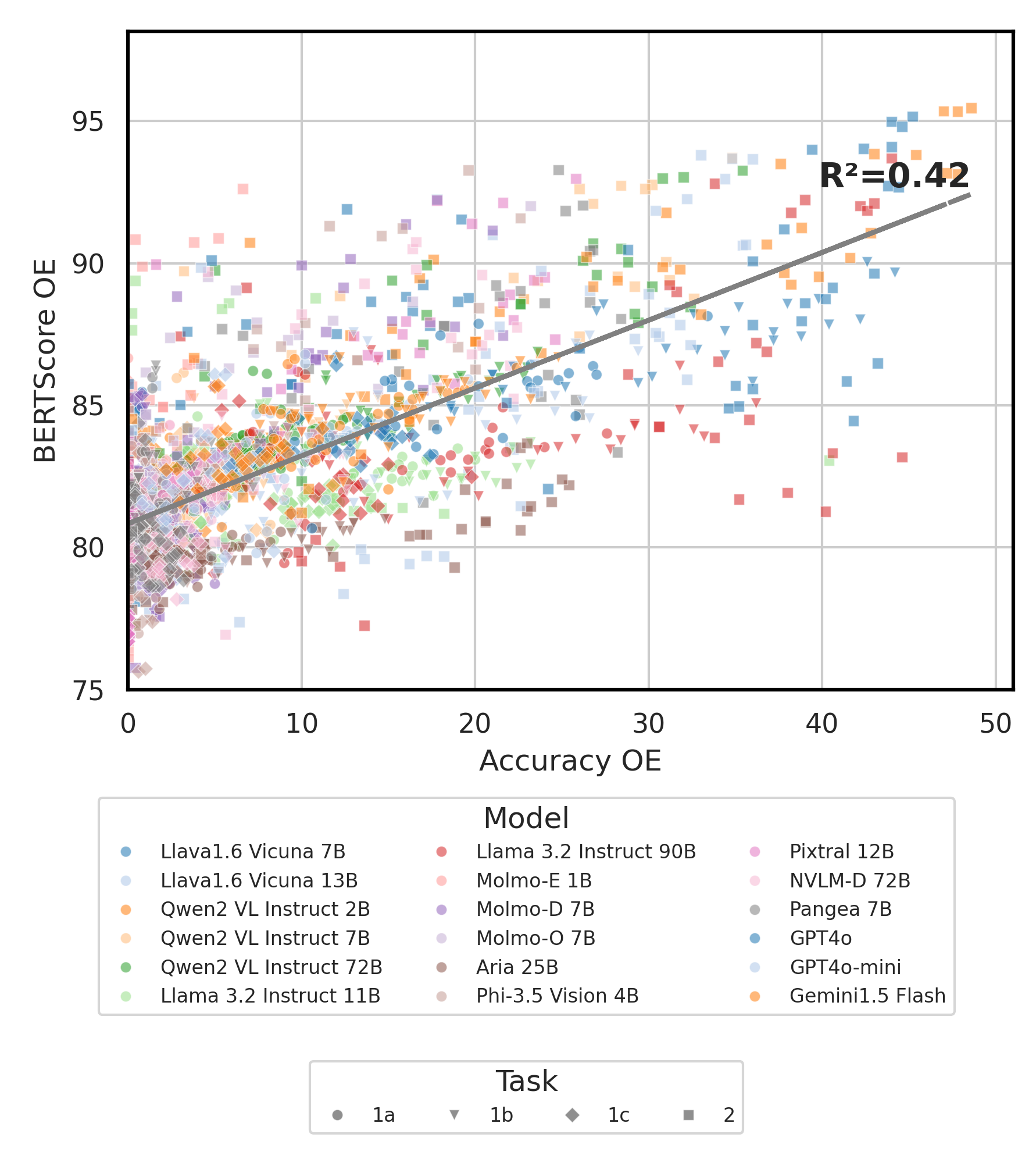
他のプロット生成スクリプトは、同じディレクトリ内の*.ipynbファイルで使用できます。
私たちのコードベースは、実験のための複数のモデルの使用をサポートしており、以下に示すリストのカスタマイズに柔軟性を提供します。
(2024年10月の時点で最後にテストされました)
ナレッジベースからVQAデータセットを生成するには、 generate_vqa/sampling.pyスクリプトを参照できます。このスクリプトは、トレーニングセットとテストセットの両方で、さまざまなタスクのデータセットを生成します。
コマンドの例:テスト用のデータセットを小さく、大型テスト、トレーニングセットのテストを生成するには、次のコマンドを実行します。
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| 口論 | 説明 | 例 |
|---|---|---|
-o 、 --output-csv | 生成されたVQAデータセットが保存されるCSVパス出力パス。 | generated_data/test_small_task1.csv |
-n 、 --num-samples | 生成されるインスタンスの最大数。可能なよりも多くのサンプルが要求されている場合、スクリプトは調整されます。 | 9000 |
-nd 、 --n-dish-max | サンプリングする最大の一意の料理数。 | 100 |
-np1a 、 --n-prompt-max-type1a | タスク1(a)(no-context)から各反復の皿ごとのサンプルまでの最大の一意のプロンプト。 | 1 |
-np1b 、 --n-prompt-max-type1b | タスク1(b)(コンテキスト化)から各反復の皿ごとのサンプルへの最大の一意のプロンプト。 | 1 |
-np1c 、 --n-prompt-max-type1c | タスク1(c)(敵対)から各反復の皿ごとのサンプルまでの最大の一意のプロンプト。 | 1 |
-np2 、 --n-prompt-max-type2 | 各反復で、タスク2から皿ごとのサンプルまでの最大一意のプロンプト。 | 1 |
--is-eval 、 --no-is-eval | 評価(テスト)またはトレーニングデータセットを生成するかどうか。 | --is-eval for test、 --no-is-eval |
| 口論 | 説明 | 例 |
|---|---|---|
-fr 、 --food-raw-path | ローフードデータCSVへのパス。 | food_raw_6oct.csv |
-fc 、 --food-cleaned-path | 清掃された食品データCSVへのパス。 | food_cleaned.csv |
-q 、 --query-context-path | クエリコンテキストCSVへのパス。 | query_ctx.csv |
-l 、 --loc-cuis-path | 場所と料理のCSVへの道。 | location_and_cuisine.csv |
-ll 、 --list-of-languages | 文字列のリストとして使用する言語を指定します。 | '["en", "id_formal"]' |
-aw 、 --alias-aware | 翻訳なしで皿を交換する代わりに、平行したエイリアスで敵対的な答えを有効にする | --alias-aware --no-alias-awareは、並列皿名の要件を緩和するために、 |
ご質問がある場合は、お気軽に問題を作成してください。また、バグを修正したり、改善を追加するためのPRを作成します。
この作品の延長を作成することに興味がある場合は、お気軽にご連絡ください!
オープンソースの取り組みをサポートします
特に、 evaluation/resultとスコアリングの視覚化コード統合を生成するための推論部分でコードを改善し、よりユーザーフレンドリーでカスタマイズ可能にします。


