worldcuisines
1.0.0
Présentation? Worldcuisines , une référence VQA multilingue et multiculturelle à grande échelle qui remet en question les modèles de vision (VLM) pour comprendre la diversité des aliments culturels dans plus de 30 langues et dialectes , à travers 9 familles de langues , avec plus d' un million de points de données disponibles à partir de plats 2,4K avec des images 6K . En tant que référence, nous avons trois sets:

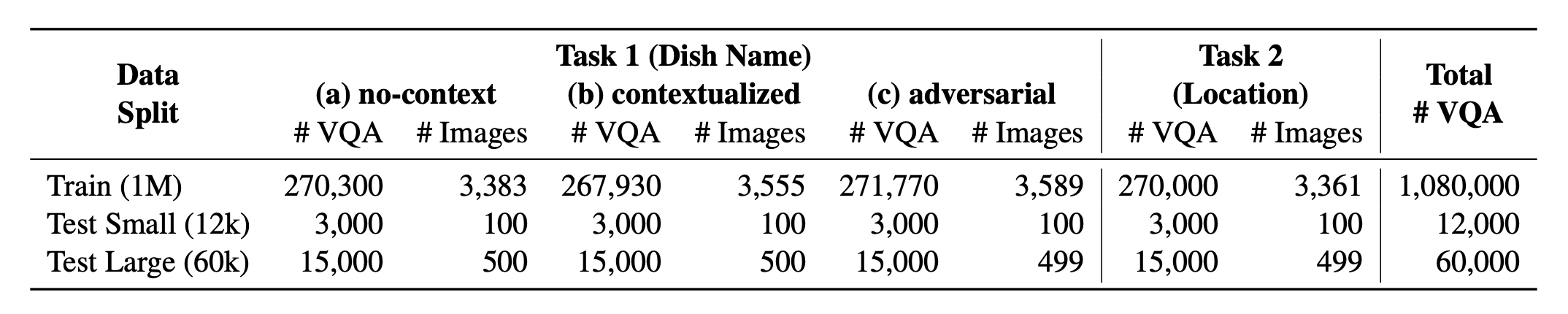
? WorldCuisines? comprend une proportion équilibrée de ses 2 tâches soutenues . Nous fournissons plus de données de formation 1M et des données d'évaluation de 60k . Notre référence évalue les VLM sur deux tâches: prédiction du nom du plat et prédiction de l'emplacement du plat. Les paramètres incluent l'invite infusée sans contexte , contextualisée et adversaire comme entrée du modèle.
Notre ensemble de données est disponible? Ensemble de données de visage étreint. Les données KB à l'appui se trouvent à? Ensemble de données de visage étreint.
Il s'agit du code source du papier [arXiv]. Ce code a été écrit à l'aide de Python. Si vous utilisez un code ou des ensembles de données à partir de cette boîte à outils dans votre recherche, veuillez citer l'article associé.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} Si vous souhaitez obtenir le résultat final pour tous les VLLM que nous évaluons, veuillez vous référer à ce classement pour le résumé. Les résultats bruts sont placés dans le répertoire evaluation/score/json .
Veuillez exécuter la commande suivante pour installer les bibliothèques requises pour reproduire les résultats de référence.
pip pip install -r requirements.txt
conda conda env create -f env.yml
Pour Pangea, veuillez exécuter ce qui suit
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
Tous les résultats de l'expérience seront stockés dans l' evaluation/result/ répertoire. Les résultats sont évalués en utilisant la précision pour toutes les tâches, en particulier pour la tâche ouverte (OEQ), nous utilisons la précision calculée à l'aide de la référence multiple . Vous pouvez exécuter chaque expérience en utilisant les commandes suivantes:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| Argument | Description | Exemple / par défaut |
|---|---|---|
--task | Numéro de tâche à évaluer (1 ou 2) | 1 (par défaut), 2 |
--type | Type de question à évaluer ( oe ou mc ) | mc (par défaut), oe |
--model_path | Chemin vers le modèle | Qwen/Qwen2-VL-72B-Instruct (par défaut) + Autres |
--fp32 | Utilisez float32 au lieu de float16 / bfloat16 | False (par défaut) |
--multi_gpu | Utilisez plusieurs GPU | False (par défaut) |
-n , --chunk_num | Nombre de morceaux pour diviser les données en | 1 (par défaut) |
-k , --chunk_id | Chunk ID (basé sur 0) | 0 (par défaut) |
-s , --st_idx | Démarrer l'index pour trancher les données (inclusive) | None (par défaut) |
-e , --ed_idx | Index de fin pour trancher les données (exclusive) | None (par défaut) |
Nous prenons en charge les modèles suivants (vous pouvez modifier notre code pour exécuter l'évaluation avec d'autres modèles).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (veuillez installer Llava comme mentionné dans la configuration de l'environnement) Modifiez evaluation/score/score.yml pour déterminer le mode de notation, l'ensemble d'évaluation et les VLM évalués. Notez que mc signifie choix multiple et oe signifie ouverture.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash En plus du mode multi pour la génération du score oe , qui compare la réponse aux étiquettes d'or dans toutes les langues, nous prenons également en charge d'autres paramètres de référence d'étiquette d'or:
single : compare la réponse uniquement à l'étiquette d'or dans la langue d'origine.dual référence : compare la réponse à l'étiquette d'or dans la langue d'origine et l'anglais.Une fois défini, exécutez cette commande:
cd evaluation/score/
python score.py Nous fournissons des diagrammes de radar, de dispersion et de ligne de dispersion connectés pour visualiser les résultats de notation pour tous les VLM dans evaluation/score/plot/ .
Pour générer tout le tracé radar , utilisez:
python evaluation/score/plot/visualization.py
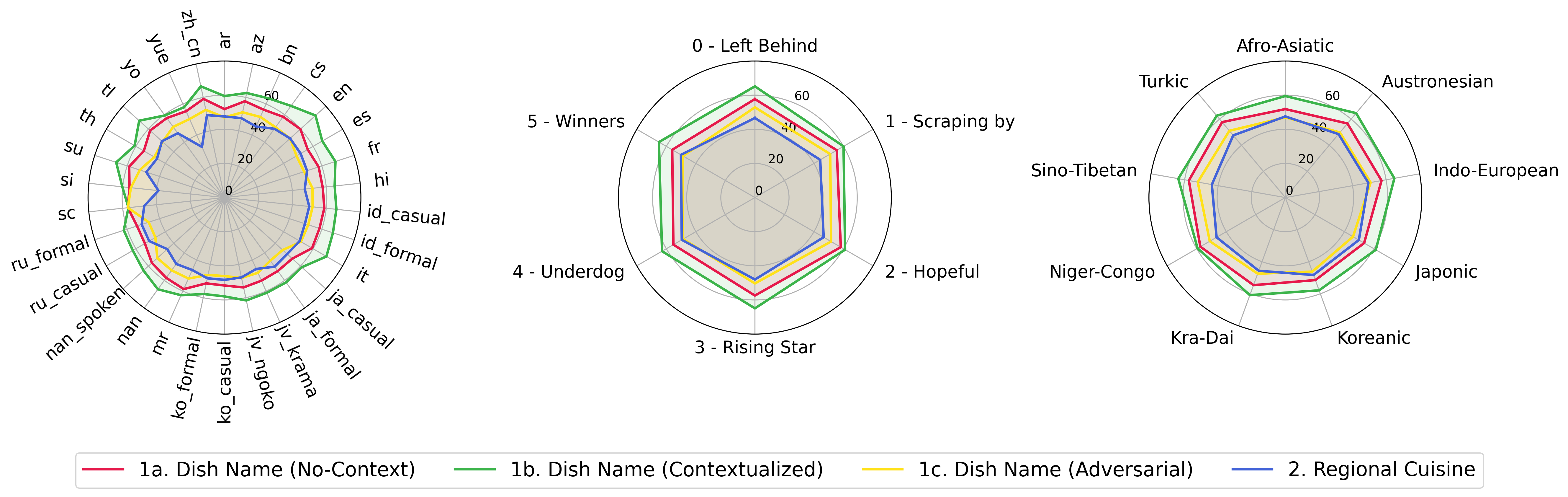
Vous pouvez également modifier evaluation/score/score.yml pour sélectionner les VLM à visualiser et ajuster les étiquettes de tracé dans plot_mapper.yml .
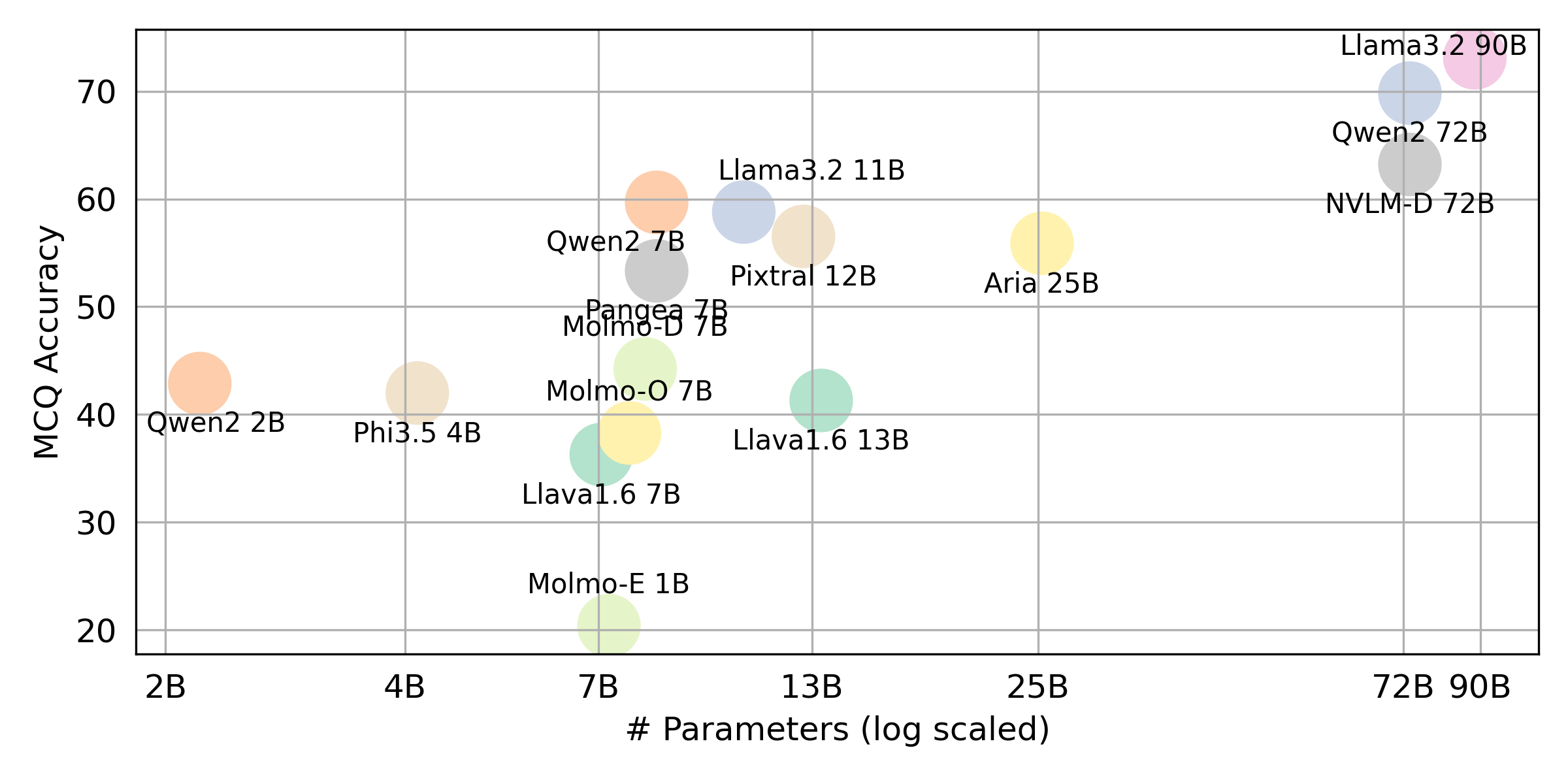
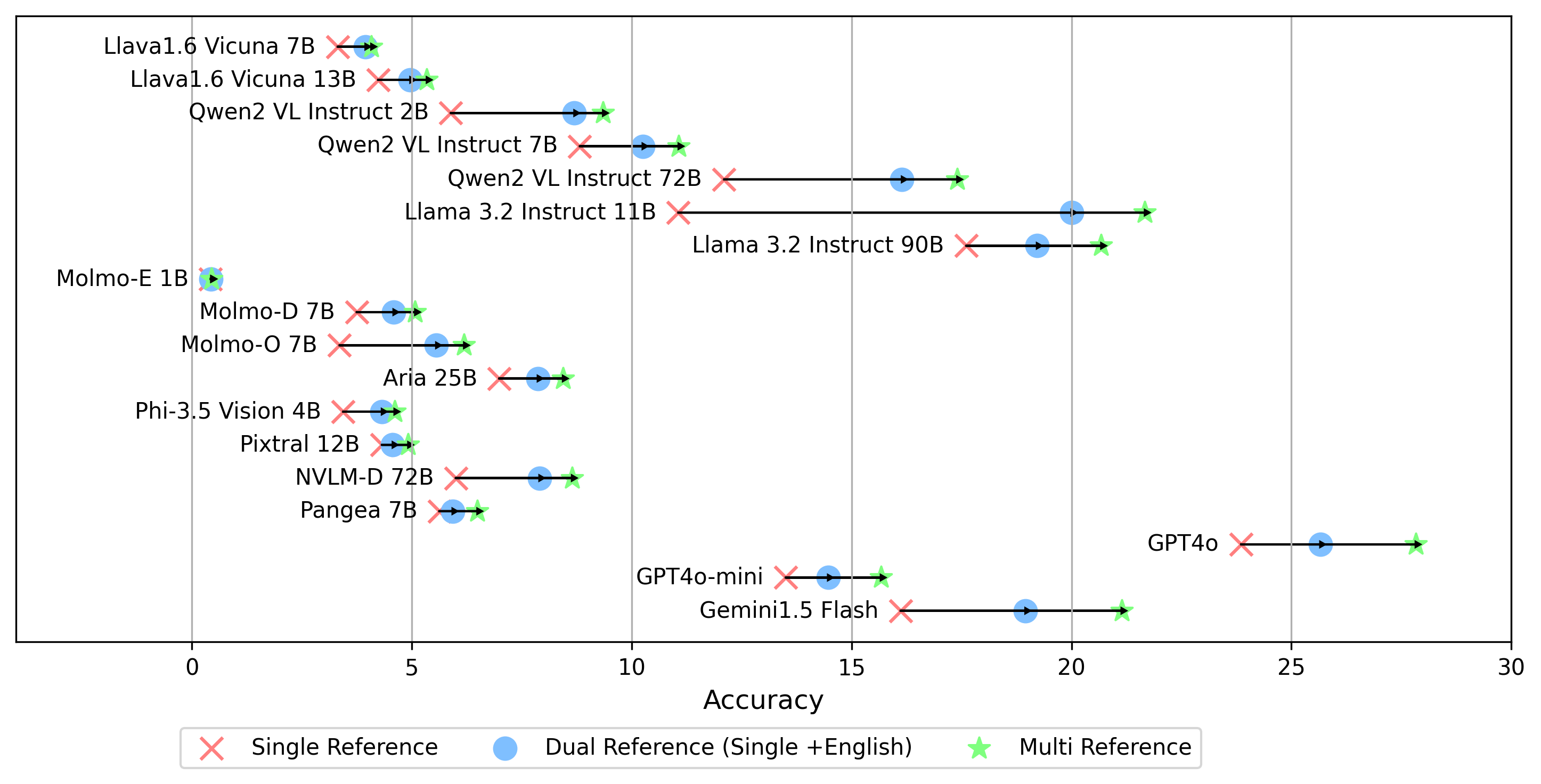
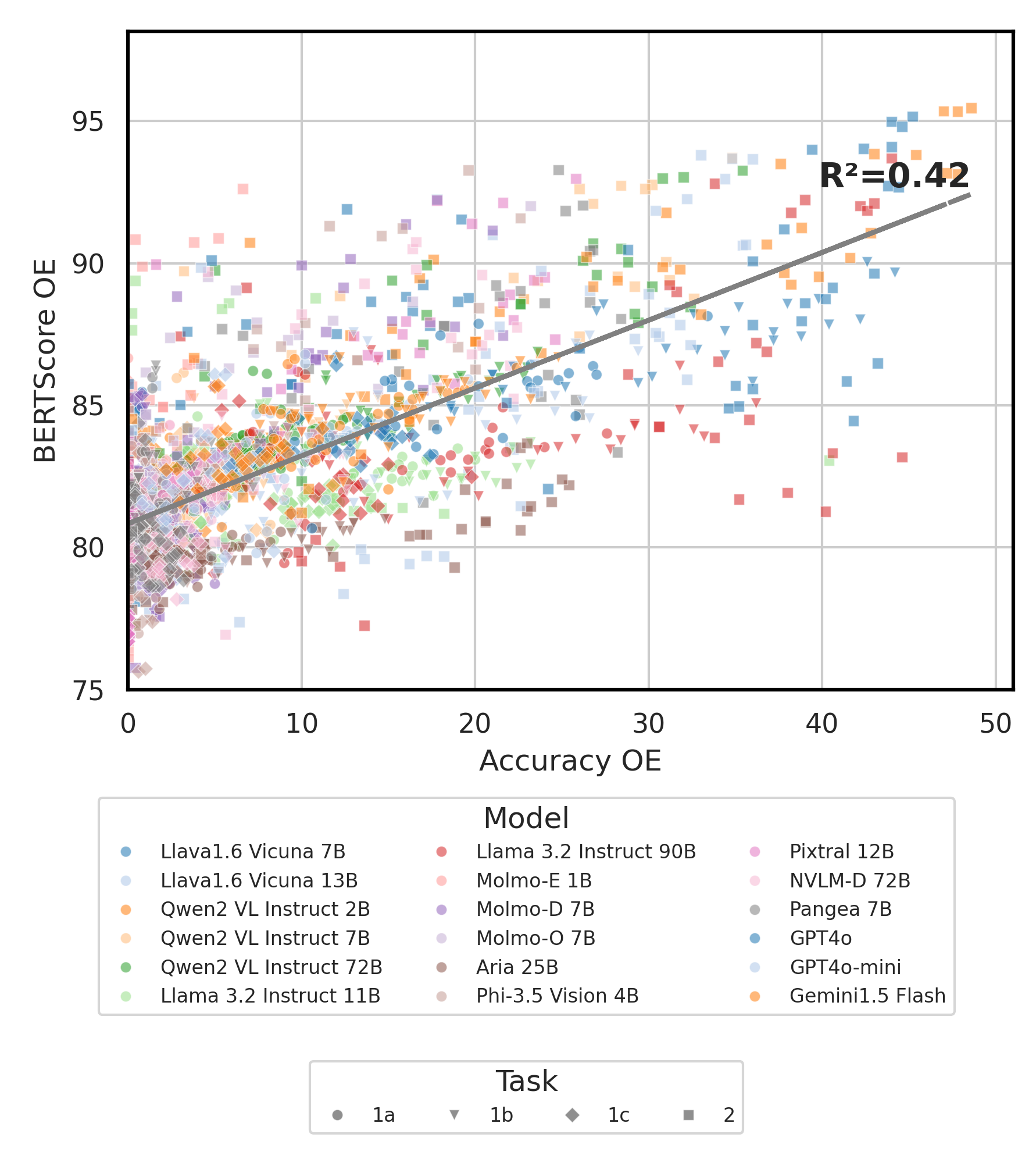
D'autres scripts de génération de tracé sont disponibles dans les fichiers *.ipynb dans le même répertoire.
Notre base de code prend en charge l'utilisation de plusieurs modèles pour les expériences, offrant une flexibilité pour la personnalisation de la liste ci-dessous:
(Dernière testée en octobre 2024)
Pour générer un ensemble de données VQA à partir de la base de connaissances, vous pouvez vous référer au script generate_vqa/sampling.py . Ce script génère l'ensemble de données pour diverses tâches dans les ensembles de formation et de test.
Exemples de commandes: Pour générer des ensembles de données pour tester petit , tester grand et des ensembles de train , exécutez les commandes suivantes:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| Argument | Description | Exemple |
|---|---|---|
-o , --output-csv | Sortie du chemin CSV où l'ensemble de données VQA généré sera enregistré. | generated_data/test_small_task1.csv |
-n , --num-samples | Nombre maximum d'instances à générer. Si plus d'échantillons sont demandés que possible, le script s'ajustera. | 9000 |
-nd , --n-dish-max | Nombre unique maximum de plats à échantillon. | 100 |
-np1a , --n-prompt-max-type1a | Invites uniques maximales de la tâche 1 (a) (sans contexte) à échantillonner par plat dans chaque itération. | 1 |
-np1b , --n-prompt-max-type1b | Invites uniques maximales de la tâche 1 (b) (contextualisée) à échantillonner par plat dans chaque itération. | 1 |
-np1c , --n-prompt-max-type1c | Invites uniques maximales de la tâche 1 (c) (adversariat) à échantillonner par plat dans chaque itération. | 1 |
-np2 , --n-prompt-max-type2 | Invites uniques maximales de la tâche 2 à échantillon par plat dans chaque itération. | 1 |
--is-eval , --no-is-eval | Que ce soit pour générer des ensembles d'évaluation (test) ou de formation. | --is-eval pour le test, --no-is-eval pour le train |
| Argument | Description | Exemple |
|---|---|---|
-fr , --food-raw-path | Chemin vers les données alimentaires crues CSV. | food_raw_6oct.csv |
-fc , --food-cleaned-path | Chemin vers les données alimentaires nettoyées CSV. | food_cleaned.csv |
-q , --query-context-path | Chemin vers le contexte de la requête CSV. | query_ctx.csv |
-l , --loc-cuis-path | Chemin vers l'emplacement et la cuisine CSV. | location_and_cuisine.csv |
-ll , --list-of-languages | Spécifiez les langues à utiliser comme liste de chaînes. | '["en", "id_formal"]' |
-aw , --alias-aware | Activer les réponses contradictoires avec des alias parallèles au lieu de remplacer les plats sans traduction par l'anglais | --alias-aware pour l'exigence de trouver des réponses qui contiennent une traduction parallèle dans toutes les langues, --no-alias-aware pour relaxer le nom des plats parallèles |
N'hésitez pas à créer un problème si vous avez des questions. Et, créez un RP pour corriger les bogues ou ajouter des améliorations.
Si vous êtes intéressé à créer une extension de ce travail, n'hésitez pas à nous contacter!
Soutenez notre effort open source
Nous améliorons le code, en particulier sur la partie d'inférence pour générer evaluation/result et une notation de l'unification du code de visualisation, pour la rendre plus conviviale et personnalisable.


