worldcuisines
1.0.0
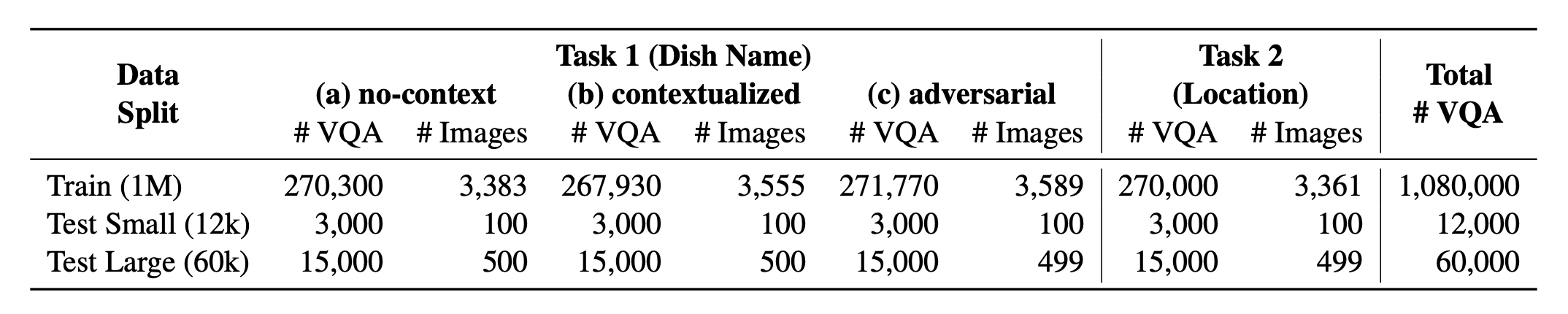
소개? WorldCuissines , VLM (Vision-Language Models)에 도전하는 대규모 규모의 다문화 및 다문화 VQA 벤치 마크 인 WorldCuisines는 9 개 이상의 언어 및 방언 의 문화 식품 다양성, 9 개의 언어 패밀리 에서 6K 이미지가있는 2.4K 접시에서 생성 된 1 백만 개가 넘는 데이터 포인트를 통해 문화 식품 다양성을 이해하도록 도전합니다. 벤치 마크로 세트가 있습니다.

? WorldCuisines? 2 개의 지원되는 작업 의 균형 잡힌 비율로 구성됩니다. 우리는 1m 이상의 교육 데이터 와 60K 평가 데이터를 제공합니다. 당사의 벤치 마크는 접시 이름 예측과 접시 위치 예측의 두 가지 작업에서 VLM을 평가합니다. 설정에는 모델의 입력으로 컨텍스트가없고 , 상황에 맞는 및 적대적 주입 프롬프트가 포함됩니다.
우리의 데이터 세트는에서 사용할 수 있습니까? 포옹 페이스 데이터 세트. 지원 KB 데이터는 찾을 수 있습니까? 포옹 페이스 데이터 세트.
이것은 논문 [arxiv]의 소스 코드입니다. 이 코드는 Python을 사용하여 작성되었습니다. 연구 에서이 툴킷의 코드 나 데이터 세트를 사용하는 경우 관련 논문을 인용하십시오.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} 우리가 평가 한 모든 VLLM에 대한 최종 결과를 얻으려면 요약에 대해서는이 리더 보드를 참조하십시오. 원시 결과는 evaluation/score/json 디렉토리에 배치됩니다.
벤치 마크 결과를 재현하려면 필요한 라이브러리를 설치하려면 다음 명령을 실행하십시오.
pip 를 통해 pip install -r requirements.txt
conda 통해 conda env create -f env.yml
Pangea의 경우 다음을 실행하십시오
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
모든 실험 결과는 evaluation/result/ 디렉토리에 저장됩니다. 결과는 모든 작업, 특히 오픈 엔드 작업 (OEQ)의 정확도를 사용하여 평가되며, 다중 참조를 사용하여 계산 된 정확도를 사용합니다. 다음 명령을 사용하여 각 실험을 실행할 수 있습니다.
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| 논쟁 | 설명 | 예 / 기본값 |
|---|---|---|
--task | 평가할 작업 번호 (1 또는 2) | 1 (기본값), 2 |
--type | 평가할 질문 유형 ( oe 또는 mc ) | mc (기본값), oe |
--model_path | 모델로가는 길 | Qwen/Qwen2-VL-72B-Instruct (기본값) + 기타 |
--fp32 | float16 / bfloat16 대신 float32 사용하십시오 | False (기본값) |
--multi_gpu | 여러 GPU를 사용하십시오 | False (기본값) |
-n , --chunk_num | 데이터를 분할 할 청크 수 | 1 (기본값) |
-k , --chunk_id | 청크 ID (0 기반) | 0 (기본값) |
-s , --st_idx | 데이터 슬라이싱 데이터에 대한 인덱스 시작 (포함) | None (기본값) |
-e , --ed_idx | 슬라이싱 데이터에 대한 최종 인덱스 (독점) | None (기본값) |
우리는 다음 모델을 지원합니다 (다른 모델에서 평가를 실행하기 위해 코드를 수정할 수 있음).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (⚡ 환경 설정에 언급 된대로 llava를 설치하십시오) evaluation/score/score.yml 편집 스코어링 모드, 평가 세트 및 평가 된 VLM을 결정합니다. mc 객관식을 의미하며 oe 개방형을 의미합니다.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash oe 점수를 생성하기위한 multi 모드 외에도 모든 언어의 골든 레이블에 대한 답을 비교하는 다른 황금 레이블 참조 설정을 지원합니다.
single 참조 : 원래 언어로 된 Golden Label 과만 답을 비교합니다.dual 참조 : 원래 언어와 영어로 된 Golden 레이블과의 답변을 비교합니다.설정되면이 명령을 실행하십시오.
cd evaluation/score/
python score.py 우리는 evaluation/score/plot/ 의 모든 VLM에 대한 점수 결과를 시각화하기 위해 레이더, 산란 및 연결된 산점도 플롯을 제공합니다.
모든 레이더 플롯을 생성하려면 사용하십시오.
python evaluation/score/plot/visualization.py
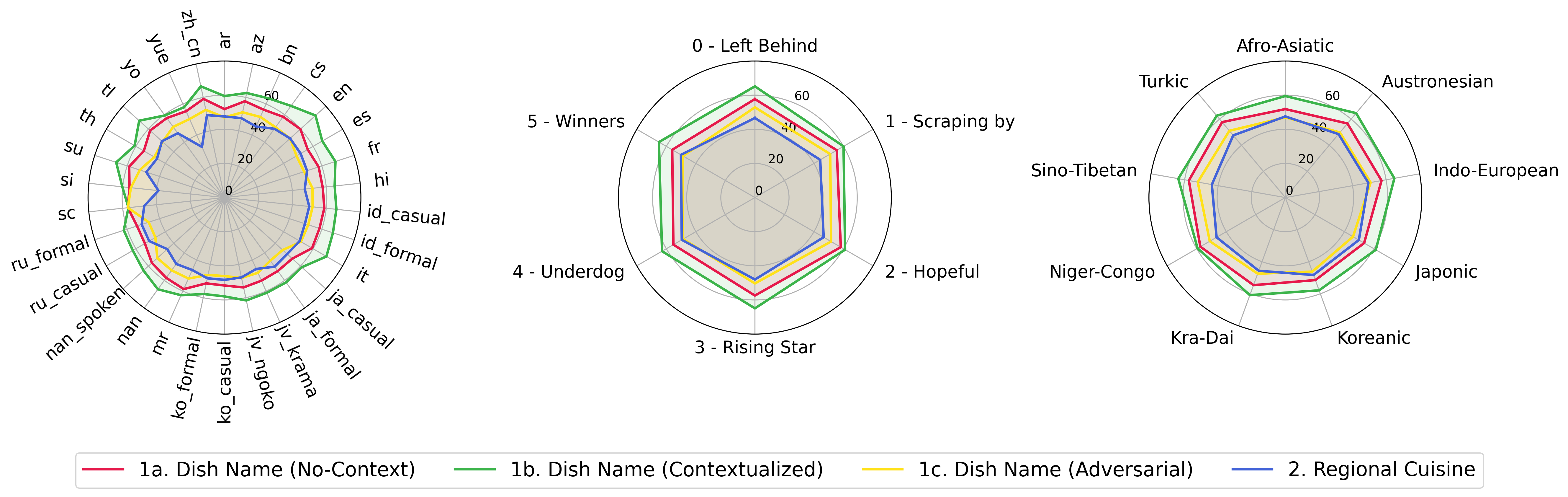
또한 evaluation/score/score.yml 수정하여 plot_mapper.yml 에서 플롯 레이블을 시각화하고 조정할 VLM을 선택할 수도 있습니다.
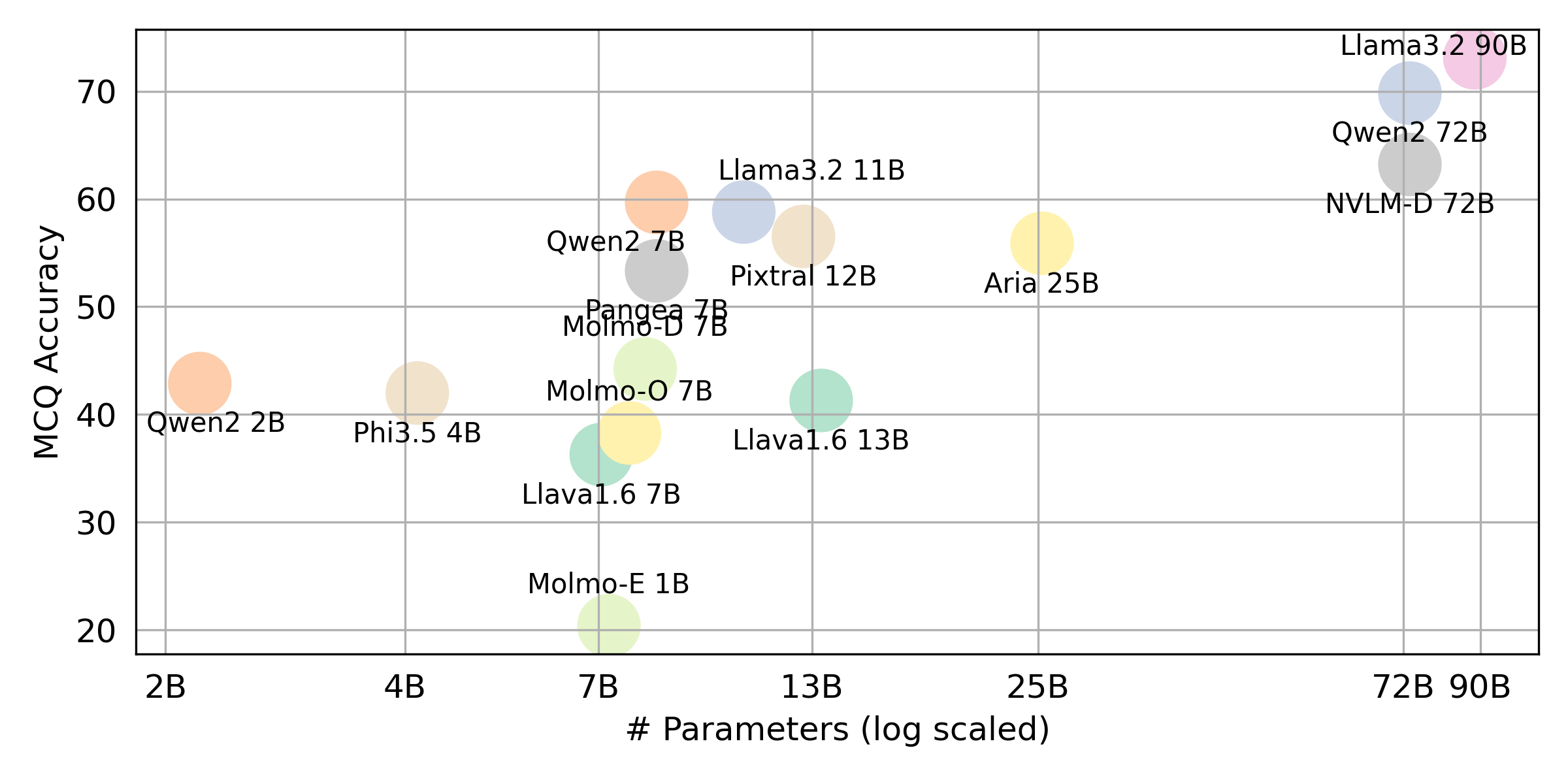
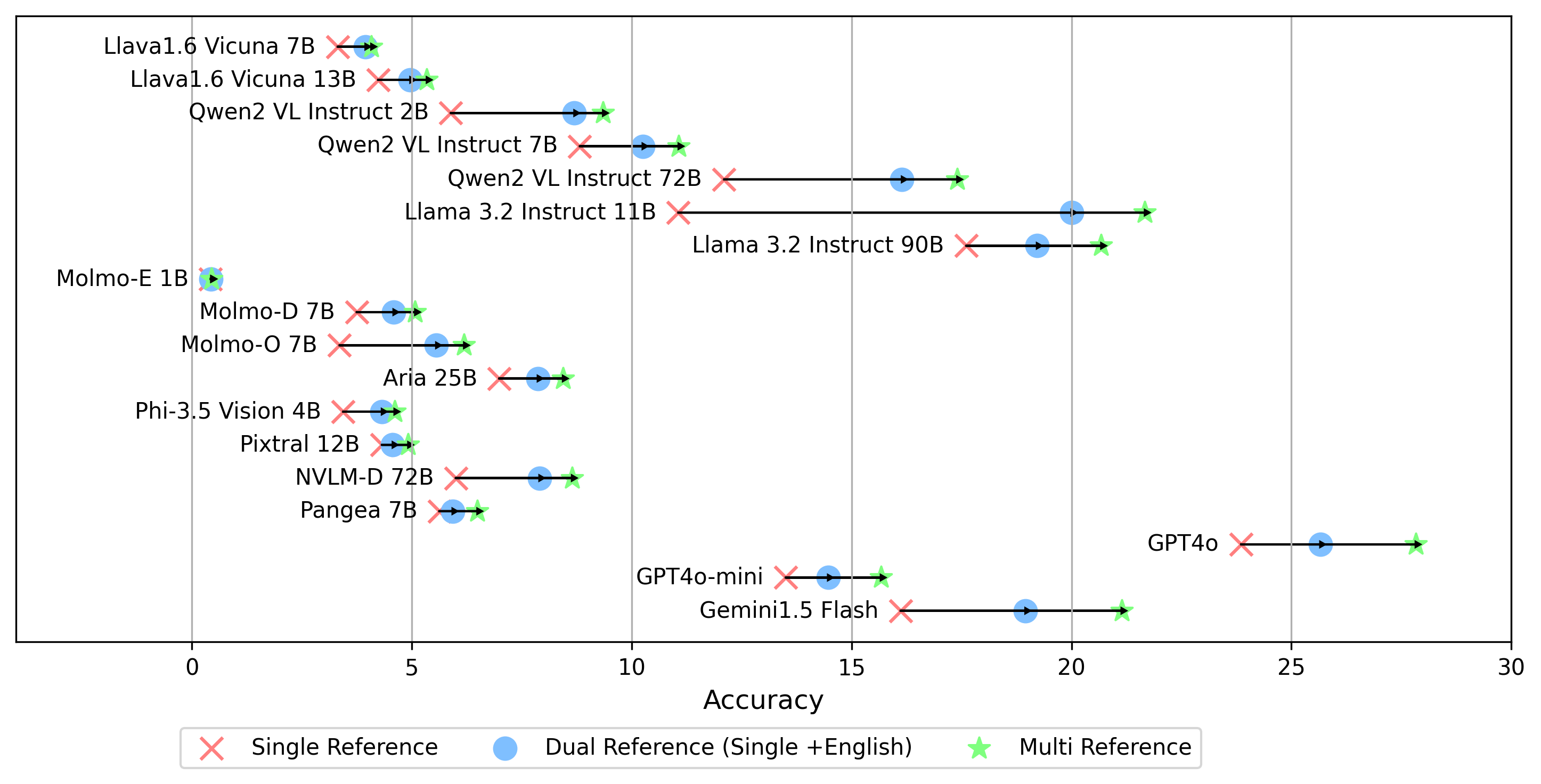
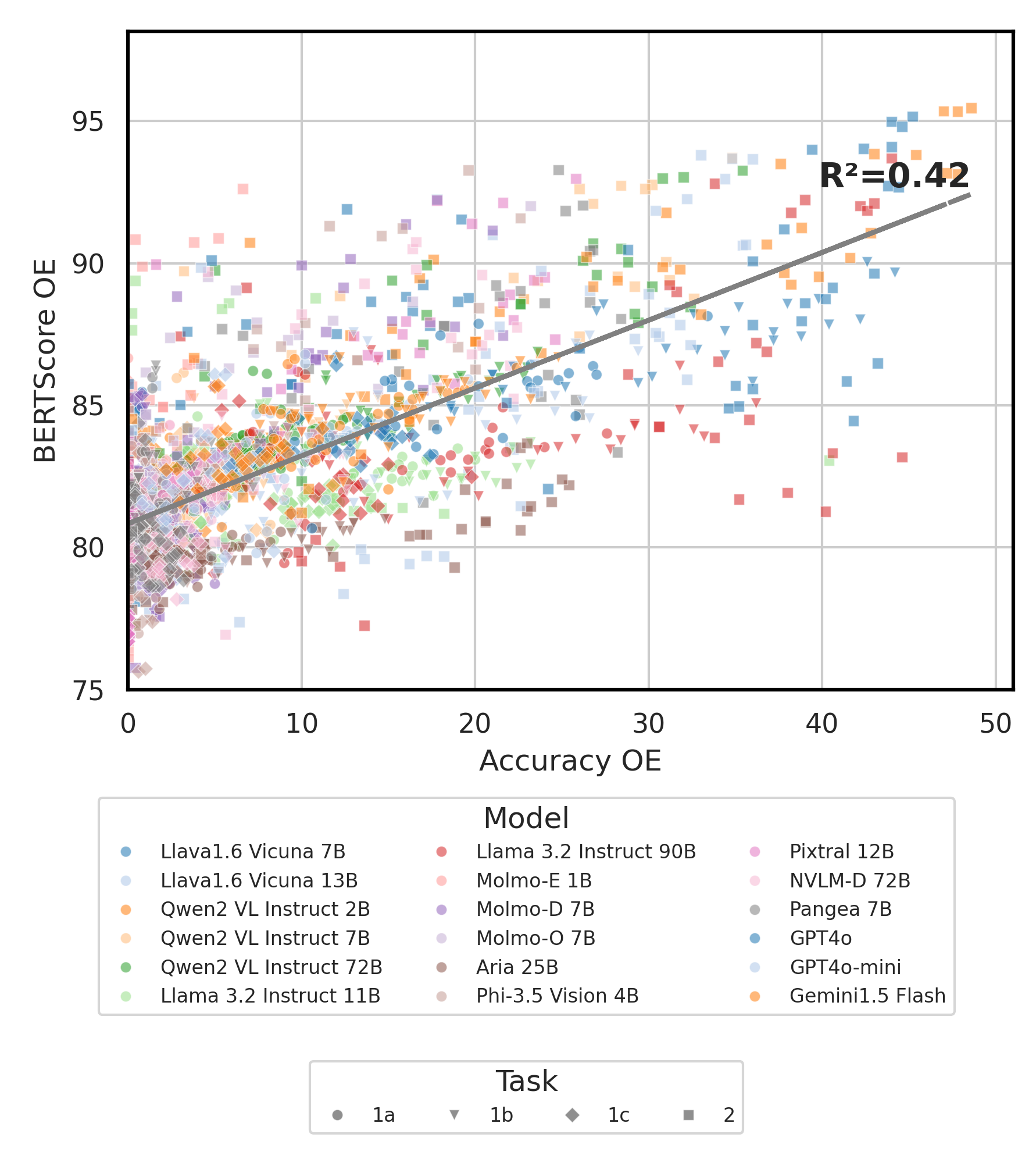
다른 플롯 생성 스크립트는 동일한 디렉토리의 *.ipynb 파일에서 사용할 수 있습니다.
당사의 코드베이스는 실험에 대한 여러 모델의 사용을 지원하여 아래에 표시된 목록을 사용자 정의 할 수있는 유연성을 제공합니다.
(2024 년 10 월에 마지막으로 테스트)
지식 기반에서 VQA 데이터 세트를 생성하려면 generate_vqa/sampling.py 스크립트를 참조 할 수 있습니다. 이 스크립트는 교육 및 테스트 세트에서 다양한 작업에 대한 데이터 세트를 생성합니다.
예제 명령 : 작은 테스트 용 데이터 세트를 생성하고, 큰 테스트 및 트레인 세트를 테스트하려면 다음 명령을 실행하십시오.
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| 논쟁 | 설명 | 예 |
|---|---|---|
-o , --output-csv | 생성 된 VQA 데이터 세트가 저장되는 출력 CSV 경로. | generated_data/test_small_task1.csv |
-n , --num-samples | 생성 할 최대 인스턴스 수. 가능한 한 더 많은 샘플이 요청되면 스크립트가 조정됩니다. | 9000 |
-nd , --n-dish-max | 샘플에서 최대의 독특한 수의 요리. | 100 |
-np1a , --n-prompt-max-type1a | 작업 1 (a) (컨텍스트 없음)에서 각 반복에서 접시 당 샘플로 최대의 고유 한 프롬프트. | 1 |
-np1b , --n-prompt-max-type1b | 작업 1 (b) (맥락화)에서 각 반복에서 접시 당 샘플로 최대의 고유 한 프롬프트. | 1 |
-np1c , --n-prompt-max-type1c | 작업 1 (c) (적대)에서 각 반복에서 접시 당 샘플로 최대의 고유 한 프롬프트. | 1 |
-np2 , --n-prompt-max-type2 | 각 반복에서 접시 당 작업 2에서 샘플까지 최대의 고유 한 프롬프트. | 1 |
--is-eval , --no-is-eval | 평가 (테스트) 또는 교육 데이터 세트 생성 여부. | --is-eval ,-열차를위한 --no-is-eval |
| 논쟁 | 설명 | 예 |
|---|---|---|
-fr , --food-raw-path | 날 음식 데이터 CSV 로의 경로. | food_raw_6oct.csv |
-fc , --food-cleaned-path | 청소 식품 데이터 CSV로가는 길. | food_cleaned.csv |
-q , --query-context-path | 쿼리 컨텍스트 CSV 경로. | query_ctx.csv |
-l , --loc-cuis-path | 위치 및 요리 CSV로가는 길. | location_and_cuisine.csv |
-ll , --list-of-languages | 문자열 목록으로 사용할 언어를 지정하십시오. | '["en", "id_formal"]' |
-aw , --alias-aware | 영어로 번역하지 않고 요리를 교체하는 대신 병렬 별명으로 대적 답변을 활성화하십시오. | -모든 언어에서 병렬 번역이 포함 된 답변을 찾는 요구 사항에 대한 --no-alias-aware 평행 요리 이름 요구 사항을 완화하기위한 --alias-aware 인식. |
궁금한 점이 있으시면 문제를 해결하십시오. 그리고 버그를 고치거나 개선을 추가하기위한 PR을 만듭니다.
이 작품의 확장을 만들고 싶다면 언제든지 우리에게 연락하십시오!
우리의 오픈 소스 노력을 지원하십시오
우리는 특히 사용자 친화적이고 사용자 정의 할 수 있도록 evaluation/result 및 스코어 시각화 코드 통일을 생성하기 위해 특히 추론 부분을 개선하고 있습니다.


