worldcuisines
1.0.0
Introducir? WorldCisines , un punto de referencia VQA multilingüe a gran escala y multicultural que desafía los modelos en idioma de visión (VLMS) para comprender la diversidad cultural de alimentos en más de 30 idiomas y dialectos , en 9 familias de idiomas , con más de 1 millón de puntos de datos disponibles generados a partir de 2.4k pliegue con imágenes de 6k . Como punto de referencia, tenemos tres conjuntos:

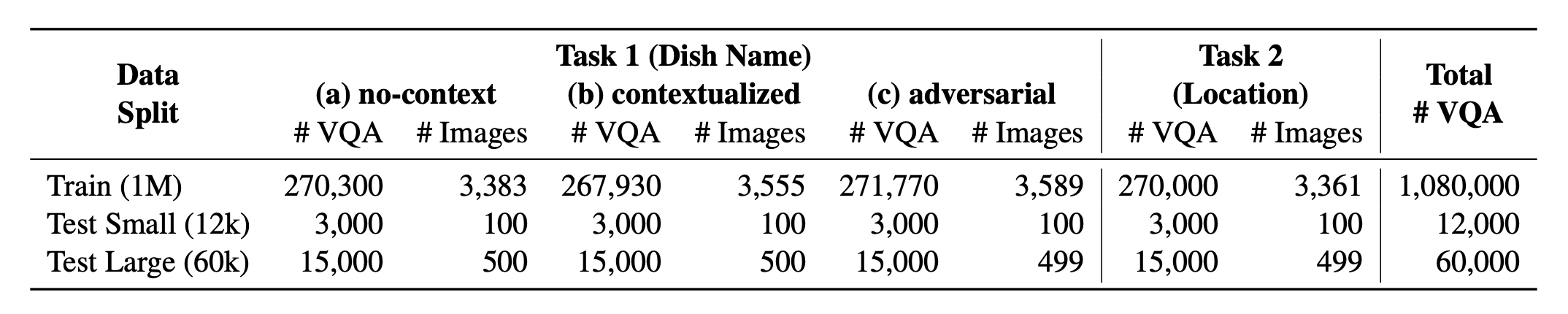
? ¿Vacinas mundiales? comprende una proporción equilibrada de sus 2 tareas respaldadas . Proporcionamos más de 1M Datos de capacitación y datos de evaluación de 60k . Nuestro punto de referencia evalúa VLM en dos tareas: predicción del nombre del plato y predicción de ubicación del plato. La configuración incluye el indicador sin contexto , contextualizado e infundido adversario como la entrada del modelo.
Nuestro conjunto de datos está disponible en? Abrazando el conjunto de datos de la cara. Los datos de KB de apoyo se pueden encontrar? Abrazando el conjunto de datos de la cara.
Este es el código fuente del documento [ARXIV]. Este código ha sido escrito usando Python. Si usa algún código o conjunto de datos de este conjunto de herramientas en su investigación, cita el documento asociado.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} Si desea obtener el resultado final para todos los VLLM que evaluamos, consulte esta tabla de clasificación para obtener el resumen. Los resultados sin procesar se colocan en el directorio evaluation/score/json .
Ejecute el siguiente comando para instalar las bibliotecas requeridas para reproducir los resultados de referencia.
pip pip install -r requirements.txt
conda conda env create -f env.yml
Para Pangea, ejecute lo siguiente
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
Todos los resultados del experimento se almacenarán en la evaluation/result/ directorio. Los resultados se evalúan utilizando la precisión para todas las tareas, específicamente para tareas abiertas (OEQ), utilizamos precisión calculada utilizando la referencia múltiple . Puede ejecutar cada experimento usando los siguientes comandos:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| Argumento | Descripción | Ejemplo / predeterminado |
|---|---|---|
--task | Número de tarea para evaluar (1 o 2) | 1 (predeterminado), 2 |
--type | Tipo de pregunta para evaluar ( oe o mc ) | mc (predeterminado), oe |
--model_path | Camino hacia el modelo | Qwen/Qwen2-VL-72B-Instruct (predeterminado) + otros |
--fp32 | Use float32 en lugar de float16 / bfloat16 | False (predeterminado) |
--multi_gpu | Use múltiples GPU | False (predeterminado) |
-n , --chunk_num | Número de fragmentos para dividir los datos en | 1 (predeterminado) |
-k , --chunk_id | ID de fragmento (basado en 0) | 0 (predeterminado) |
-s , --st_idx | Iniciar índice para cortar datos (inclusive) | None (predeterminado) |
-e , --ed_idx | Índice final para cortar datos (exclusivo) | None (predeterminado) |
Apoyamos los siguientes modelos (puede modificar nuestro código para ejecutar la evaluación con otros modelos).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (instale llava como se menciona en la configuración del entorno ⚡) Editar evaluation/score/score.yml para determinar el modo de puntuación, conjunto de evaluación y VLMS evaluado. Tenga en cuenta que mc significa opción múltiple y oe significa abierto.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash Además del modo multi para generar la puntuación oe , que compara la respuesta con las etiquetas doradas en todos los idiomas, también admitimos otras configuraciones de referencia de etiquetas doradas:
single : compara la respuesta solo con la etiqueta dorada en el idioma original.dual : compara la respuesta con la etiqueta dorada en el idioma original e inglés.Una vez configurado, ejecute este comando:
cd evaluation/score/
python score.py Proporcionamos gráficos de radar, dispersión y línea de dispersión conectadas para visualizar los resultados de puntuación para todos los VLM en evaluation/score/plot/ .
Para generar toda la parcela de radar , use:
python evaluation/score/plot/visualization.py
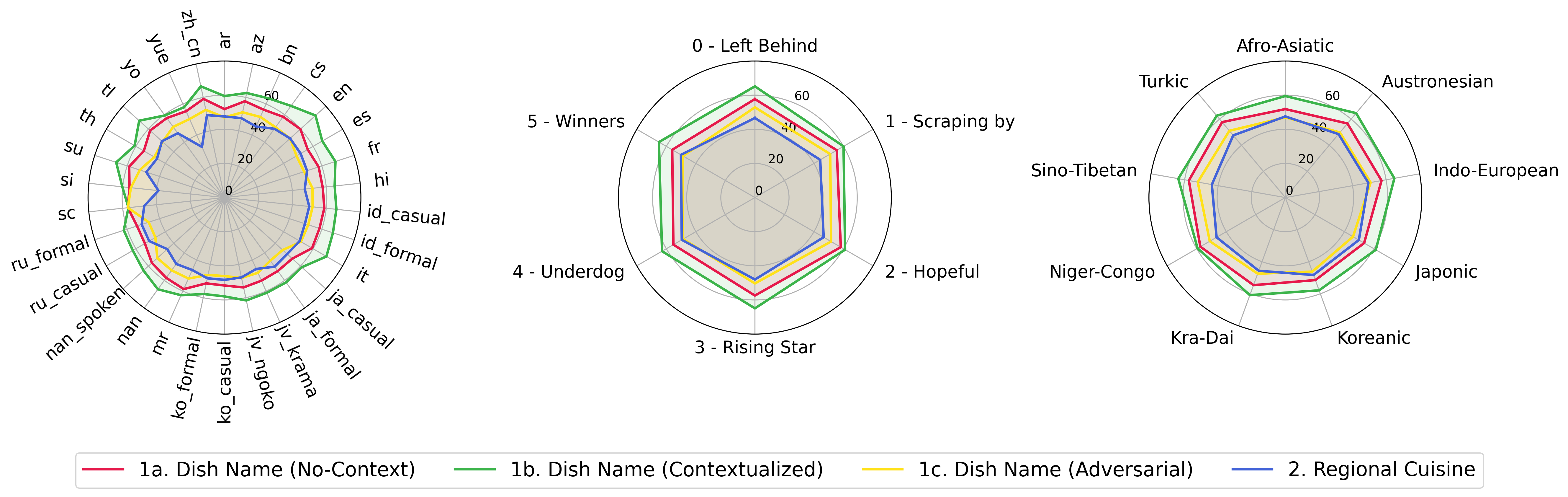
También puede modificar evaluation/score/score.yml para seleccionar qué VLMS visualizar y ajustar las etiquetas de la traza en plot_mapper.yml .
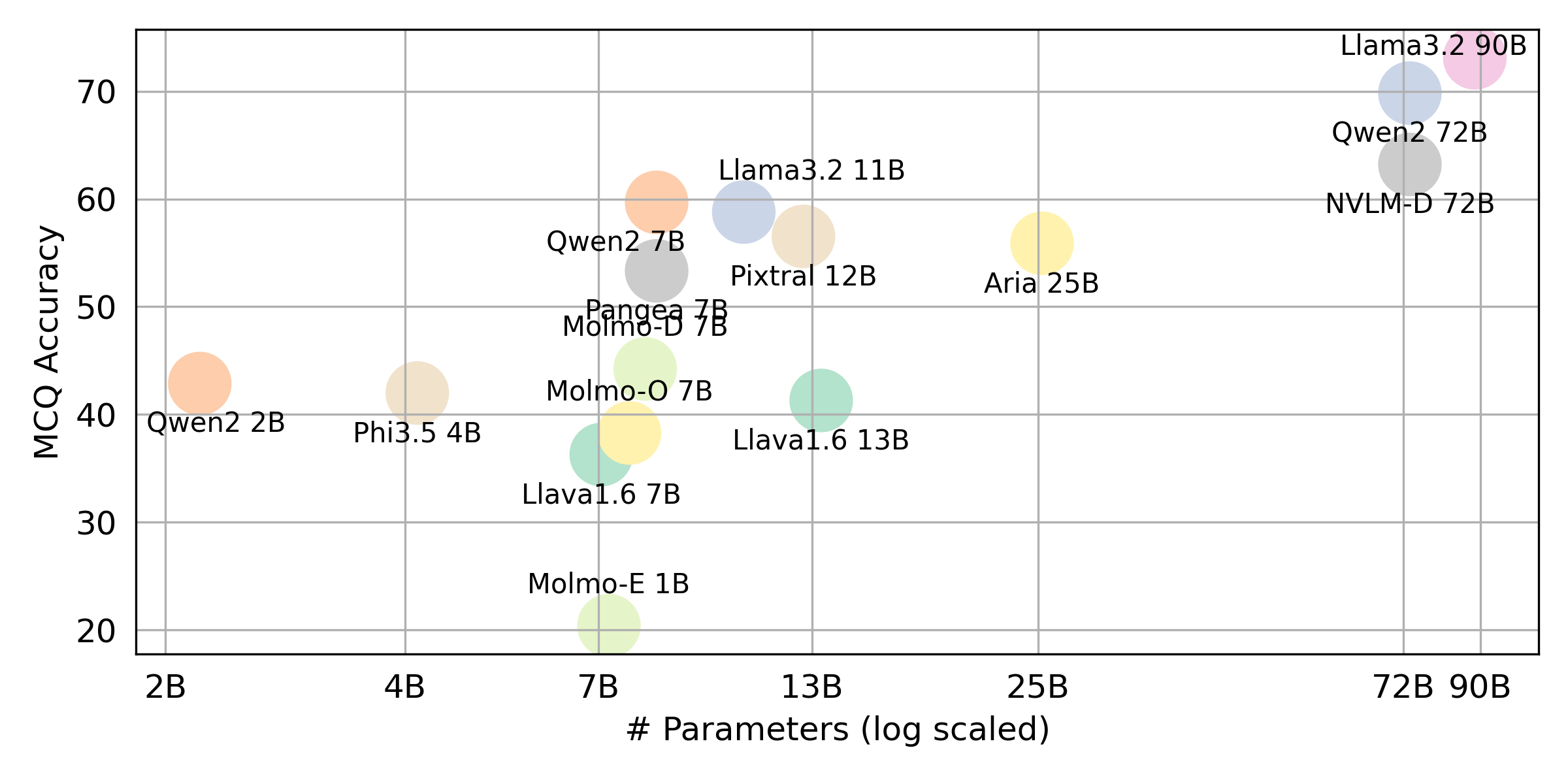
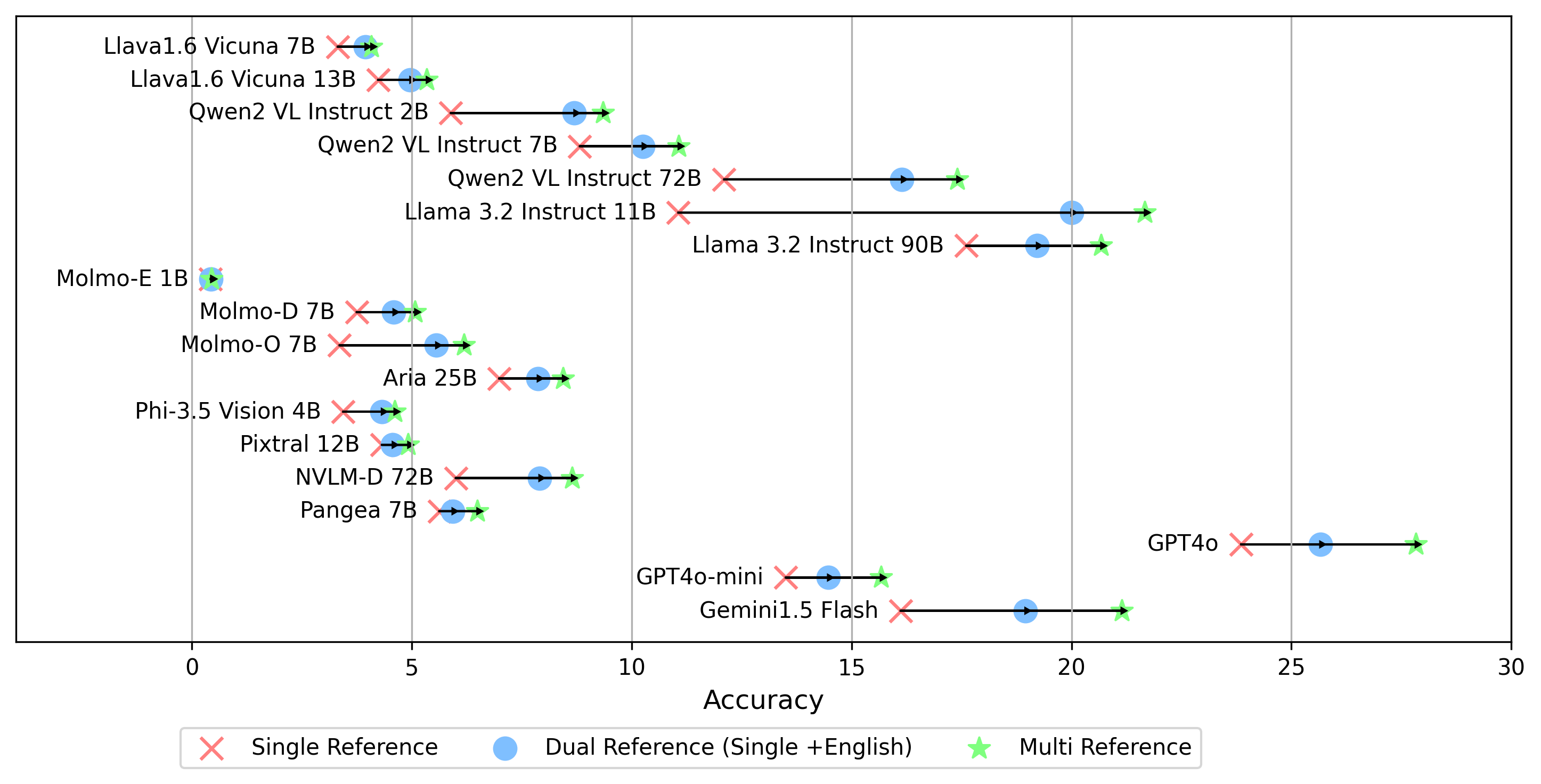
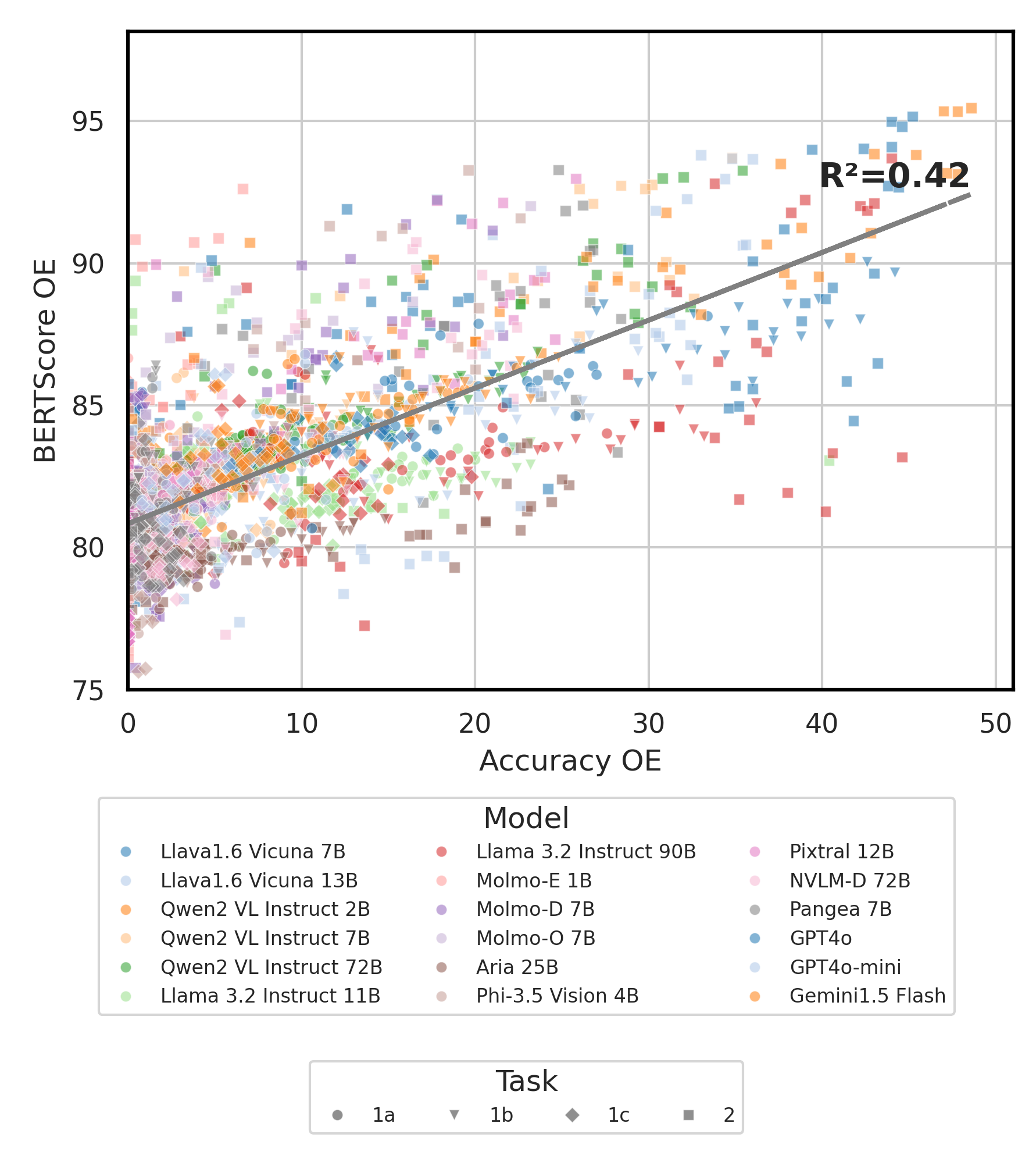
Otros scripts de generación de gráficos están disponibles en los archivos *.ipynb dentro del mismo directorio.
Nuestra base de código admite el uso de múltiples modelos para los experimentos, proporcionando flexibilidad para la personalización de la lista que se muestra a continuación:
(Últimamente probado a partir de octubre de 2024)
Para generar un conjunto de datos VQA desde la base de conocimiento, puede consultar el script generate_vqa/sampling.py . Este script genera el conjunto de datos para varias tareas en conjuntos de capacitación y prueba.
Comandos de ejemplo: Para generar conjuntos de datos para probar pequeños , probar grandes y conjuntos de trenes , ejecute los siguientes comandos:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| Argumento | Descripción | Ejemplo |
|---|---|---|
-o , --output-csv | Ruta CSV de salida donde se guardará el conjunto de datos VQA generado. | generated_data/test_small_task1.csv |
-n , --num-samples | Número máximo de instancias a generar. Si se solicitan más muestras que posible, el script se ajustará. | 9000 |
-nd , --n-dish-max | Máximo número único de platos a la muestra de. | 100 |
-np1a , --n-prompt-max-type1a | Las indicaciones únicas máximas de la Tarea 1 (a) (sin contexto) para probar por plato en cada iteración. | 1 |
-np1b , --n-prompt-max-type1b | Las indicaciones únicas máximas de la Tarea 1 (b) (contextualizada) para probar por plato en cada iteración. | 1 |
-np1c , --n-prompt-max-type1c | Máximas indicaciones únicas de la Tarea 1 (c) (adversar) para probar por plato en cada iteración. | 1 |
-np2 , --n-prompt-max-type2 | Máximo indicaciones únicas de la tarea 2 a la muestra por plato en cada iteración. | 1 |
--is-eval , --no-is-eval | Si generar evaluación (prueba) o conjuntos de datos de capacitación. | --is-eval para la prueba, --no-is-eval para tren |
| Argumento | Descripción | Ejemplo |
|---|---|---|
-fr , --food-raw-path | Camino hacia los datos de alimentos crudos CSV. | food_raw_6oct.csv |
-fc , --food-cleaned-path | Camino hacia los datos de alimentos limpios CSV. | food_cleaned.csv |
-q , --query-context-path | Camino hacia el contexto de consulta CSV. | query_ctx.csv |
-l , --loc-cuis-path | Camino a la ubicación y la cocina CSV. | location_and_cuisine.csv |
-ll , --list-of-languages | Especifique los idiomas que se utilizarán como una lista de cadenas. | '["en", "id_formal"]' |
-aw , --alias-aware | Habilite respuestas adversas con alias paralelos en lugar de reemplazar los platos sin traducción con inglés | --alias-aware del requisito de encontrar respuestas que contengan traducción paralela en todos los idiomas, --no-alias-aware para relajar el requisito de nombre de los platos paralelos |
No dude en crear un problema si tiene alguna pregunta. Y, cree un PR para corregir errores o agregar mejoras.
Si está interesado en crear una extensión de este trabajo, ¡no dude en comunicarse con nosotros!
Apoyar nuestro esfuerzo de código abierto
Estamos mejorando el código, especialmente en la parte de inferencia para generar evaluation/result y puntuación de la unificación del código de visualización, para que sea más fácil de usar y personalizable.


