worldcuisines
1.0.0
แนะนำ? Worldcuisines ซึ่งเป็นมาตรฐาน VQA หลายภาษาและหลากหลายวัฒนธรรมที่ท้าทายรูปแบบภาษาวิสัยทัศน์ (VLMs) เพื่อทำความเข้าใจความหลากหลายของอาหารทางวัฒนธรรมในกว่า 30 ภาษาและภาษาถิ่น ใน 9 ครอบครัวภาษา โดยมี จุดข้อมูลมากกว่า 1 ล้าน รายการที่สร้าง ขึ้น จากอาหาร 2.4k ตามมาตรฐานเรามีสามชุด:

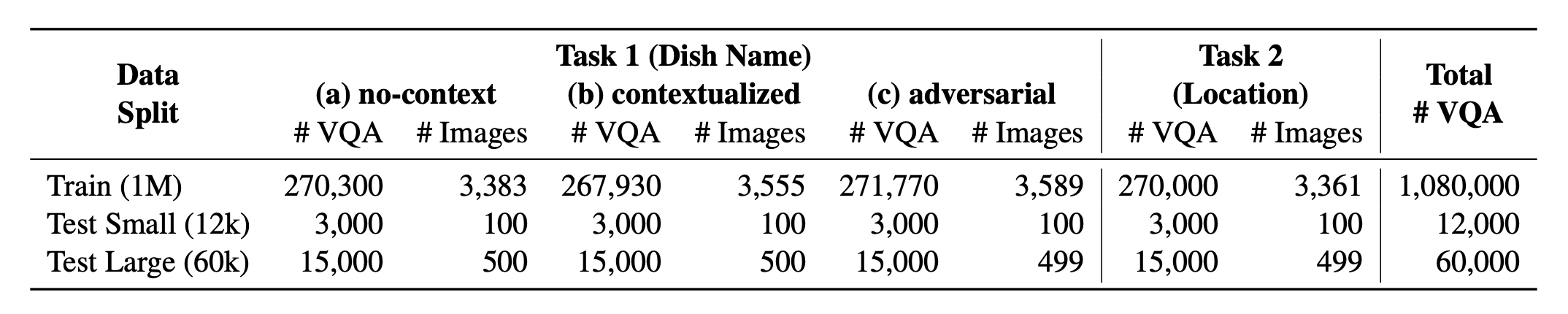
- Worldcuisines? ประกอบด้วยสัดส่วนที่สมดุลของ งาน 2 อย่างที่ได้รับการสนับสนุน เราให้ ข้อมูลการฝึกอบรมมากกว่า 1M และ ข้อมูลการประเมิน 60K เกณฑ์มาตรฐานของเราประเมิน VLMs ในสองงาน: การทำนายชื่อจานและการทำนายตำแหน่งจาน การตั้งค่ารวมถึง ไม่มีบริบท บริบท และพรอมต์ Infused Adversarial เป็นอินพุตของโมเดล
ชุดข้อมูลของเรามีอยู่ที่? กอดชุดข้อมูล ข้อมูล KB ที่รองรับสามารถพบได้ที่? กอดชุดข้อมูล
นี่คือซอร์สโค้ดของกระดาษ [arxiv] รหัสนี้เขียนขึ้นโดยใช้ Python หากคุณใช้รหัสหรือชุดข้อมูลใด ๆ จากชุดเครื่องมือนี้ในการวิจัยของคุณโปรดอ้างอิงกระดาษที่เกี่ยวข้อง
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} หากคุณต้องการได้รับผลลัพธ์สุดท้ายสำหรับ VLLM ทั้งหมดที่เราประเมินโปรดดูที่ลีดเดอร์บอร์ดนี้สำหรับการสรุป ผลลัพธ์ดิบจะถูกวางไว้ในไดเรกทอรี evaluation/score/json
โปรดเรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งไลบรารีที่จำเป็นเพื่อทำซ้ำผลลัพธ์มาตรฐาน
pip pip install -r requirements.txt
conda conda env create -f env.yml
สำหรับ Pangea โปรดเรียกใช้สิ่งต่อไปนี้
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
ผลการทดลองทั้งหมดจะถูกเก็บไว้ใน evaluation/result/ ไดเรกทอรี ผลลัพธ์ได้รับการประเมินโดยใช้ความแม่นยำสำหรับงานทั้งหมดโดยเฉพาะสำหรับงานปลายเปิด (OEQ) เราใช้ความแม่นยำที่คำนวณโดยใช้ การอ้างอิงแบบหลายการอ้างอิง คุณสามารถดำเนินการทดสอบแต่ละครั้งโดยใช้คำสั่งต่อไปนี้:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| การโต้แย้ง | คำอธิบาย | ตัวอย่าง / ค่าเริ่มต้น |
|---|---|---|
--task | หมายเลขงานเพื่อประเมิน (1 หรือ 2) | 1 (ค่าเริ่มต้น), 2 |
--type | ประเภทของคำถามที่จะประเมิน ( oe หรือ mc ) | mc (ค่าเริ่มต้น), oe |
--model_path | เส้นทางสู่โมเดล | Qwen/Qwen2-VL-72B-Instruct (ค่าเริ่มต้น) + อื่น ๆ |
--fp32 | ใช้ float32 แทน float16 / bfloat16 | False (ค่าเริ่มต้น) |
--multi_gpu | ใช้ GPU หลายตัว | False (ค่าเริ่มต้น) |
-n , --chunk_num | จำนวนชิ้นที่จะแยกข้อมูลออกเป็น | 1 (ค่าเริ่มต้น) |
-k , --chunk_id | chunk id (0-based) | 0 (ค่าเริ่มต้น) |
-s , --st_idx | เริ่มดัชนีสำหรับการหั่นข้อมูล (รวม) | None (ค่าเริ่มต้น) |
-e , --ed_idx | ดัชนีสิ้นสุดสำหรับการหั่นข้อมูล (พิเศษ) | None (ค่าเริ่มต้น) |
เราสนับสนุนโมเดลต่อไปนี้ (คุณสามารถแก้ไขรหัสของเราเพื่อเรียกใช้การประเมินผลกับรุ่นอื่น ๆ )
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (โปรดติดตั้ง llava ตามที่กล่าวไว้ใน⚡การตั้งค่าสภาพแวดล้อม) แก้ไข evaluation/score/score.yml เพื่อกำหนดโหมดการให้คะแนนชุดการประเมินและประเมิน VLMS โปรดทราบว่า mc หมายถึงแบบปรนัยและ oe หมายถึงเปิดปลาย
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash นอกเหนือจากโหมด multi สำหรับการสร้างคะแนน oe ซึ่งเปรียบเทียบคำตอบของฉลากทองคำในทุกภาษาเรายังสนับสนุนการตั้งค่าการอ้างอิงฉลากทองคำอื่น ๆ :
single : เปรียบเทียบคำตอบเฉพาะกับฉลากทองคำในภาษาดั้งเดิมdual : เปรียบเทียบคำตอบของฉลากทองคำในภาษาดั้งเดิมและภาษาอังกฤษเมื่อตั้งค่าแล้วให้เรียกใช้คำสั่งนี้:
cd evaluation/score/
python score.py เราจัดทำพล็อตเรดาร์กระจายและเชื่อมต่อเพื่อแสดงผลการให้คะแนนสำหรับ VLMs ทั้งหมดใน evaluation/score/plot/
ในการสร้าง พล็อตเรดาร์ ทั้งหมดให้ใช้:
python evaluation/score/plot/visualization.py
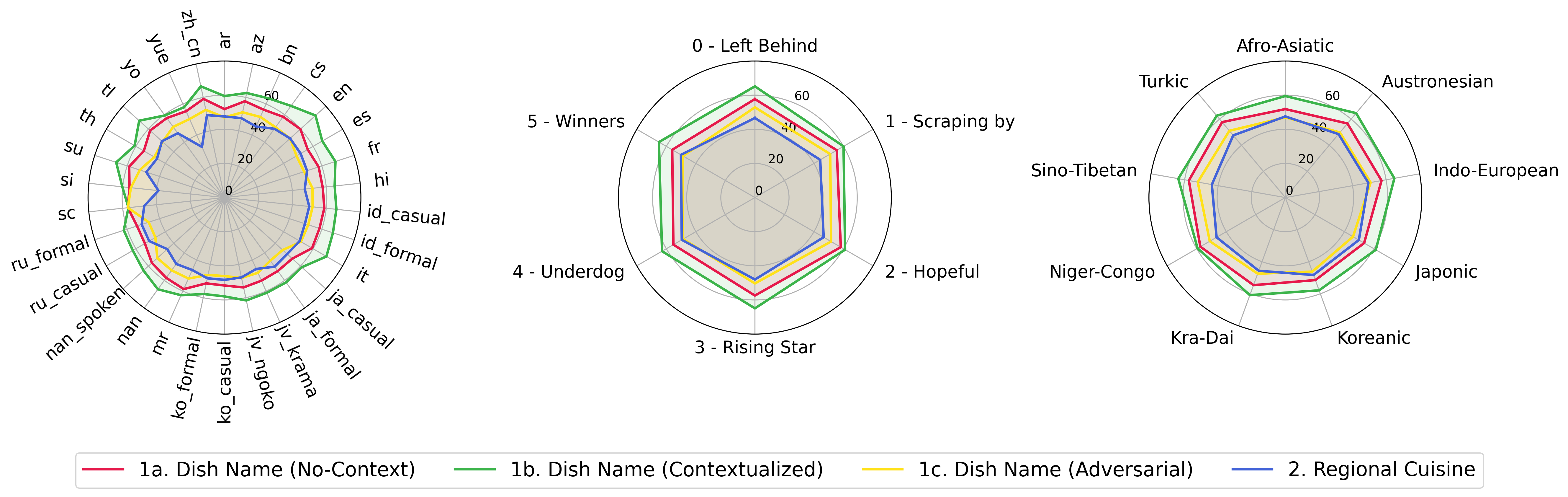
นอกจากนี้คุณยังสามารถแก้ไข evaluation/score/score.yml เพื่อเลือก VLMs ที่จะเห็นภาพและปรับฉลากพล็อตใน plot_mapper.yml
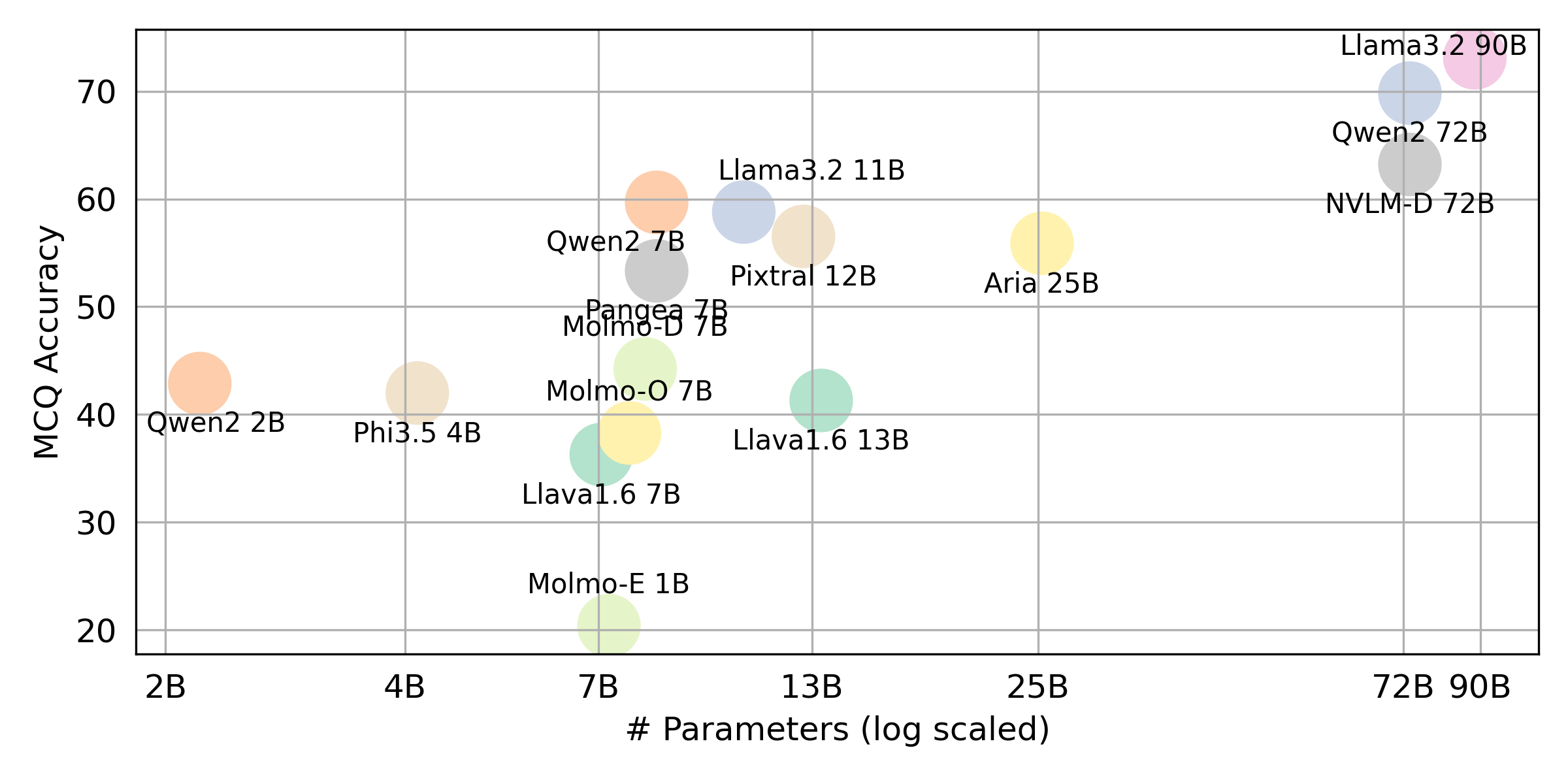
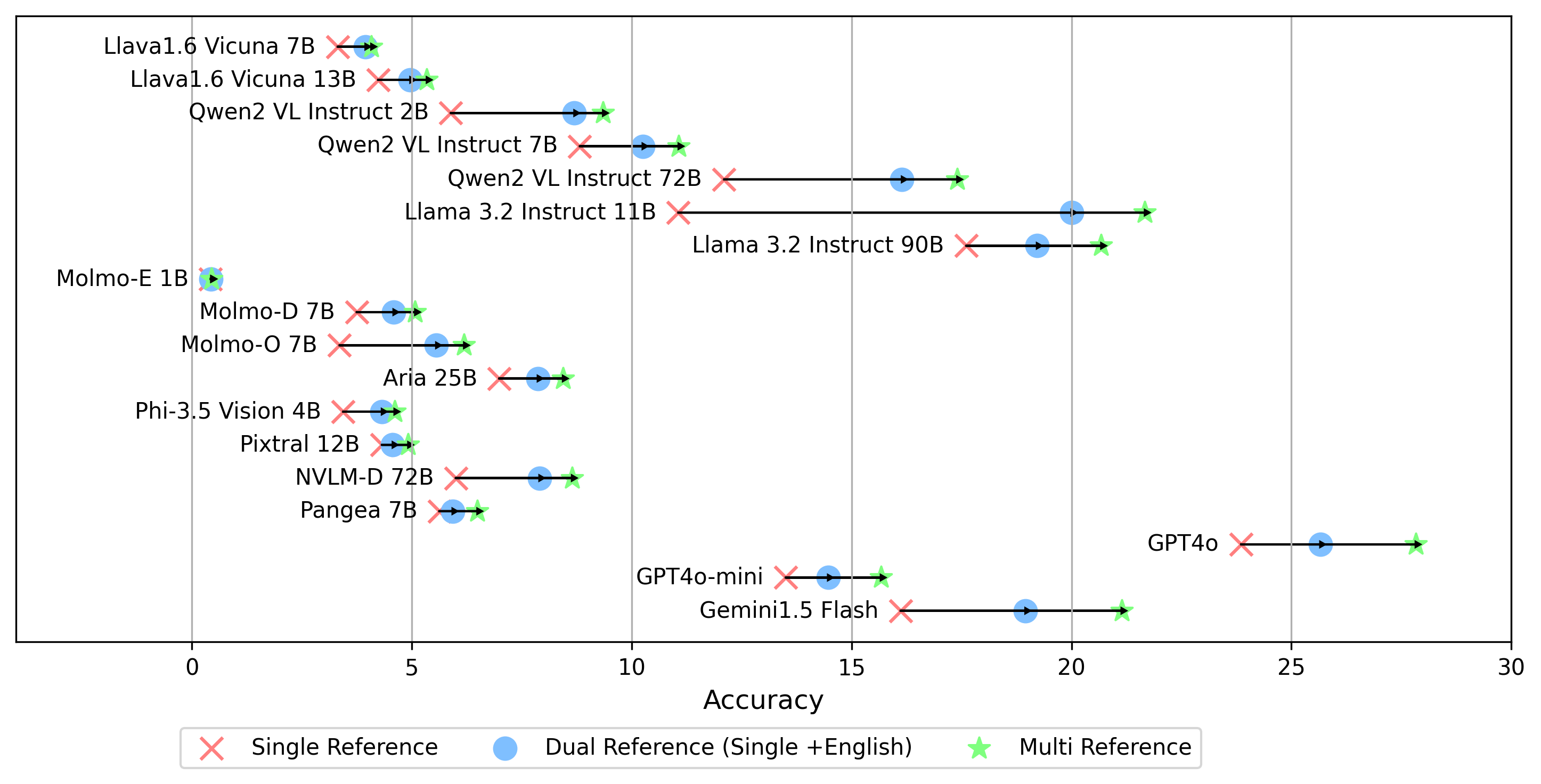
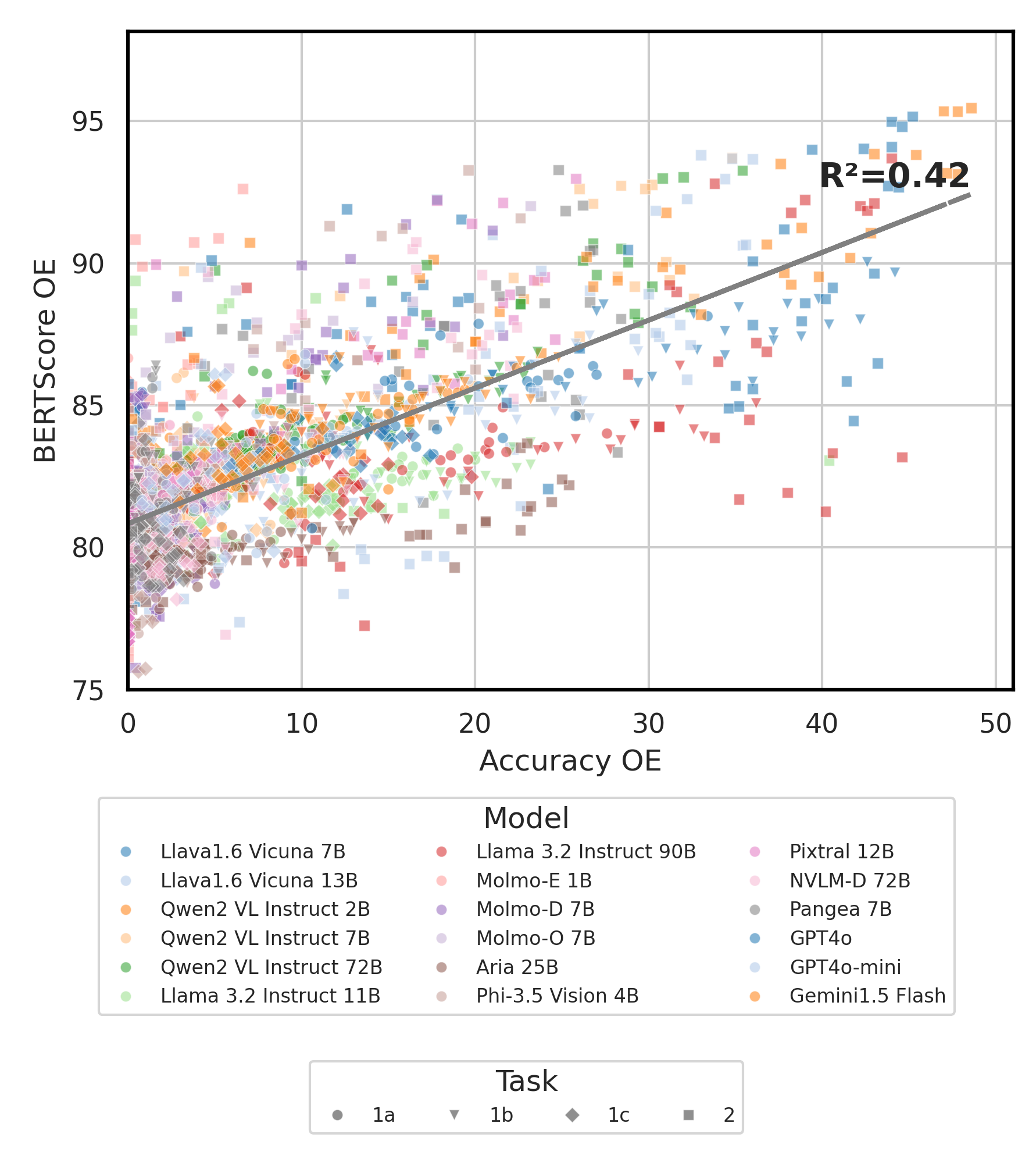
สคริปต์การสร้างพล็อตอื่น ๆ มีอยู่ในไฟล์ *.ipynb ภายในไดเรกทอรีเดียวกัน
codebase ของเรารองรับการใช้งานหลายรุ่นสำหรับการทดลองให้ความยืดหยุ่นสำหรับการปรับแต่งรายการที่แสดงด้านล่าง:
(ทดสอบครั้งล่าสุดเมื่อเดือนตุลาคม 2567)
ในการสร้างชุดข้อมูล VQA จากฐานความรู้คุณสามารถอ้างถึงสคริปต์ generate_vqa/sampling.py สคริปต์นี้สร้างชุดข้อมูลสำหรับงานต่าง ๆ ทั้งในชุดการฝึกอบรมและการทดสอบ
คำสั่งตัวอย่าง: เพื่อสร้างชุดข้อมูลสำหรับ การทดสอบขนาดเล็ก ทดสอบขนาดใหญ่ และชุด รถไฟ เรียกใช้คำสั่งต่อไปนี้:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| การโต้แย้ง | คำอธิบาย | ตัวอย่าง |
|---|---|---|
-o , --output-csv | เส้นทาง CSV เอาท์พุทซึ่งจะบันทึกชุดข้อมูล VQA ที่สร้างขึ้น | generated_data/test_small_task1.csv |
-n , --num-samples | จำนวนอินสแตนซ์สูงสุดที่จะสร้าง หากมีการร้องขอตัวอย่างมากกว่าที่เป็นไปได้สคริปต์จะปรับ | 9000 |
-nd , --n-dish-max | จำนวนอาหารที่ไม่ซ้ำกันสูงสุดในการสุ่มตัวอย่างจาก | 100 |
-np1a , --n-prompt-max-type1a | พรอมต์ที่ไม่ซ้ำกันสูงสุดจากภารกิจ 1 (a) (ไม่มีบริบท) ตัวอย่างต่อจานในการทำซ้ำแต่ละครั้ง | 1 |
-np1b , --n-prompt-max-type1b | พรอมต์ที่ไม่ซ้ำกันสูงสุดจากภารกิจ 1 (b) (บริบท) เป็นตัวอย่างต่อจานในการทำซ้ำแต่ละครั้ง | 1 |
-np1c , --n-prompt-max-type1c | พรอมต์ที่ไม่ซ้ำกันสูงสุดจากภารกิจ 1 (c) (ฝ่ายตรงข้าม) เป็นตัวอย่างต่อจานในการทำซ้ำแต่ละครั้ง | 1 |
-np2 , --n-prompt-max-type2 | พรอมต์ที่ไม่ซ้ำกันสูงสุดจากภารกิจ 2 เพื่อสุ่มตัวอย่างต่อจานในการทำซ้ำแต่ละครั้ง | 1 |
--is-eval , --no-is-eval | ไม่ว่าจะสร้างชุดข้อมูลการประเมินผล (ทดสอบ) หรือการฝึกอบรม | --is-eval สำหรับการทดสอบ --no-is-eval สำหรับรถไฟ |
| การโต้แย้ง | คำอธิบาย | ตัวอย่าง |
|---|---|---|
-fr , --food-raw-path | เส้นทางไปยังข้อมูลอาหารดิบ CSV | food_raw_6oct.csv |
-fc , --food-cleaned-path | เส้นทางไปยังข้อมูลอาหารที่ทำความสะอาด CSV | food_cleaned.csv |
-q , --query-context-path | เส้นทางไปยังบริบทแบบสอบถาม CSV | query_ctx.csv |
-l , --loc-cuis-path | เส้นทางไปยังสถานที่และอาหาร CSV | location_and_cuisine.csv |
-ll , --list-of-languages | ระบุภาษาที่จะใช้เป็นรายการสตริง | '["en", "id_formal"]' |
-aw , --alias-aware | เปิดใช้งานคำตอบที่เป็นปฏิปักษ์กับนามแฝงแบบขนานแทนที่จะเปลี่ยนอาหารโดยไม่ต้องแปลเป็นภาษาอังกฤษ | --alias-aware ถึงความต้องการในการค้นหาคำตอบที่มีการแปลแบบขนานในทุกภาษา --no-alias-aware |
อย่าลังเลที่จะสร้างปัญหาหากคุณมีคำถามใด ๆ และสร้าง PR สำหรับการแก้ไขข้อบกพร่องหรือเพิ่มการปรับปรุง
หากคุณสนใจที่จะสร้างส่วนขยายของงานนี้อย่าลังเลที่จะติดต่อเรา!
สนับสนุนความพยายามของเราโอเพนซอร์ส
เรากำลังปรับปรุงรหัสโดยเฉพาะอย่างยิ่งในส่วนการอนุมานเพื่อสร้าง evaluation/result และการให้คะแนนการรวมรหัสการสร้างภาพเพื่อให้เป็นมิตรกับผู้ใช้และปรับแต่งได้มากขึ้น


