worldcuisines
1.0.0
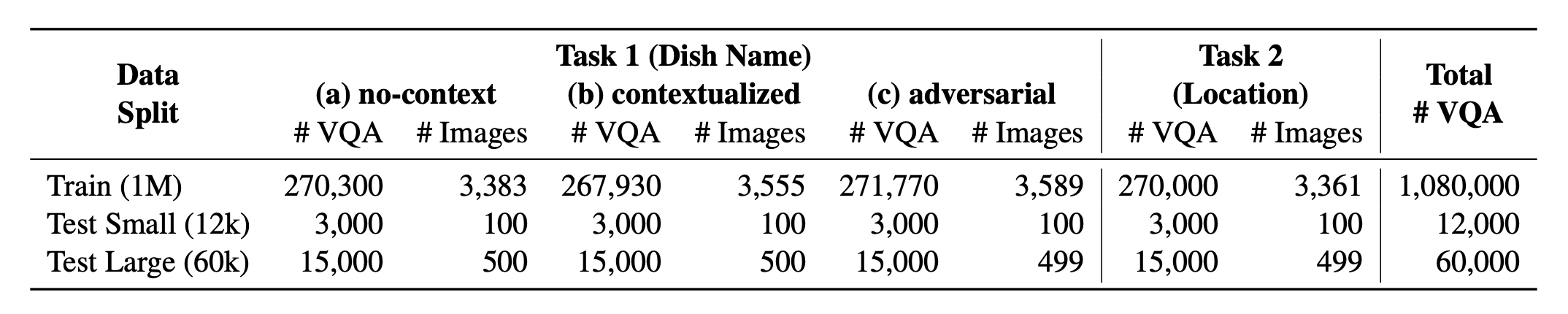
تقديم؟ WorldCuisines ، وهو مؤشر VQA متعدد اللغات ومتعدد الثقافات يتحدى نماذج لغة الرؤية (VLMs) لفهم التنوع الغذائي الثقافي بأكثر من 30 لغة ولهجات ، عبر 9 أسر لغوية ، مع أكثر من مليون نقطة بيانات متوفرة من أطباق 2.4 ألف مع 6 كيلو فولت. كمعيار ، لدينا ثلاث مجموعات:

؟ WorldCuisines؟ تضم نسبة متوازنة من مهامها المدعومة . نحن نقدم أكثر من مليون بيانات تدريب وبيانات تقييم 60K . يقيس المعيار لدينا VLMs على مهمتين: تنبؤ اسم الطبق والتنبؤ بموقع الطبق. تتضمن الإعدادات موجه NO-Context و Contextualized و Hearversarial Consing كمدخلات للنموذج.
مجموعة البيانات الخاصة بنا متوفرة في؟ معانقة مجموعة بيانات الوجه. يمكن العثور على بيانات KB الداعمة في؟ معانقة مجموعة بيانات الوجه.
هذا هو الكود المصدر للورقة [Arxiv]. تمت كتابة هذا الرمز باستخدام Python. إذا كنت تستخدم أي رمز أو مجموعات بيانات من مجموعة الأدوات هذه في بحثك ، فيرجى الاستشهاد بالورقة المرتبطة بها.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} إذا كنت ترغب في الحصول على النتيجة النهائية لجميع VLLMs التي نقوم بتقييمها ، فيرجى الرجوع إلى هذا اللوحة المتصدرين للحصول على الملخص. يتم وضع النتائج الأولية في دليل evaluation/score/json .
يرجى تشغيل الأمر التالي لتثبيت المكتبات المطلوبة لإعادة إنتاج النتائج القياسية.
pip pip install -r requirements.txt
conda conda env create -f env.yml
لـ Pangea ، يرجى تشغيل ما يلي
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
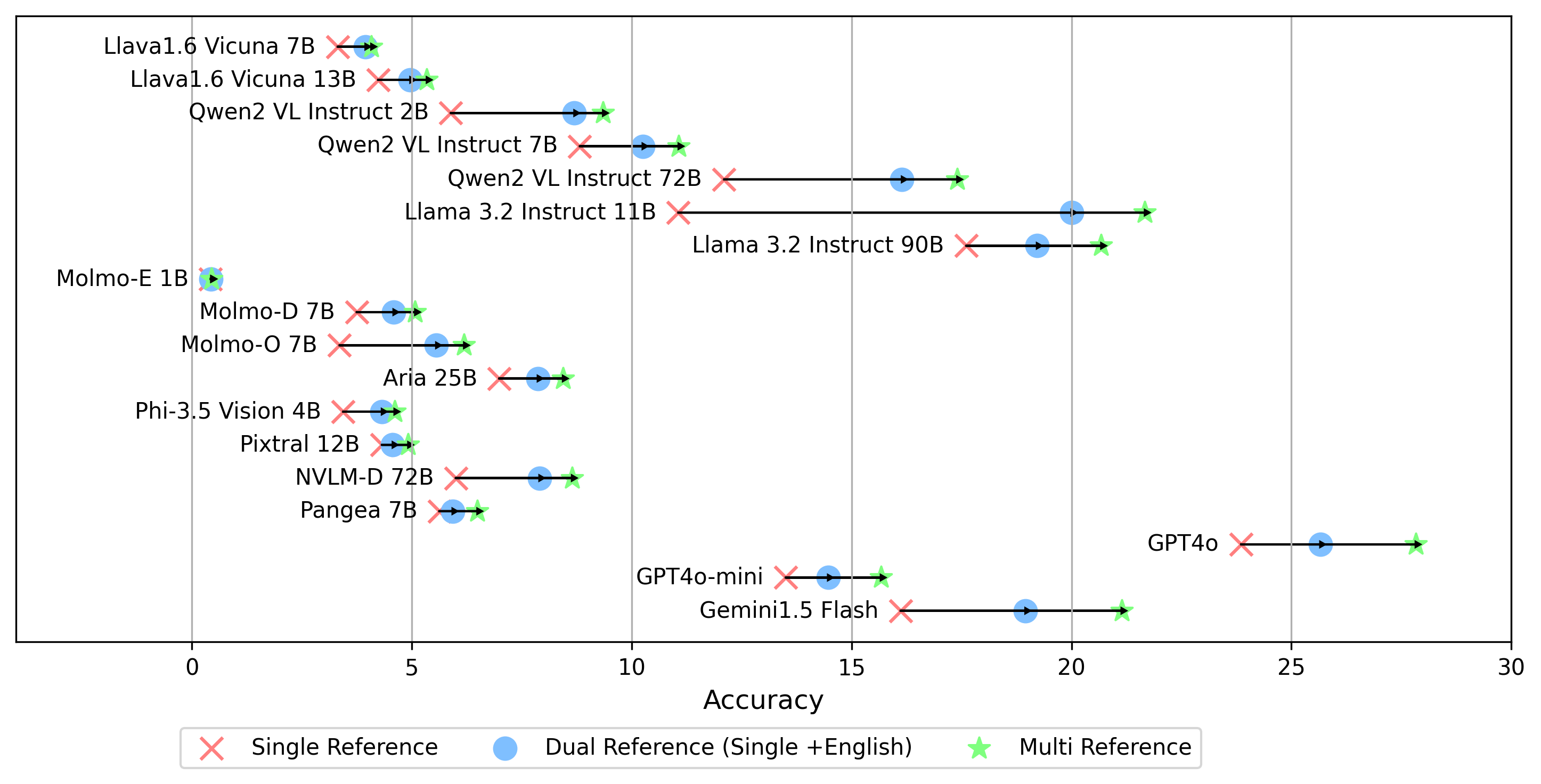
سيتم تخزين جميع نتائج التجربة في evaluation/result/ الدليل. يتم تقييم النتائج باستخدام دقة جميع المهام ، وتحديداً للمهمة المفتوحة (OEQ) ، نستخدم الدقة المحسوبة باستخدام المرجع المتعدد . يمكنك تنفيذ كل تجربة باستخدام الأوامر التالية:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| دعوى | وصف | مثال / افتراضي |
|---|---|---|
--task | رقم المهمة للتقييم (1 أو 2) | 1 (افتراضي) ، 2 |
--type | نوع السؤال الذي يجب تقييمه ( oe أو mc ) | mc (افتراضي) ، oe |
--model_path | طريق إلى النموذج | Qwen/Qwen2-VL-72B-Instruct (افتراضي) + آخرون |
--fp32 | استخدم float32 بدلاً من float16 / bfloat16 | False (افتراضي) |
--multi_gpu | استخدم وحدات معالجة الرسومات المتعددة | False (افتراضي) |
-n ، --chunk_num | عدد القطع لتقسيم البيانات إلى | 1 (افتراضي) |
-k ، --chunk_id | معرف القطع (0) | 0 (افتراضي) |
-s ، --st_idx | ابدأ فهرس لتقطيع البيانات (شاملة) | None (افتراضي) |
-e ، --ed_idx | فهرس نهاية لتقطيع البيانات (حصري) | None (افتراضي) |
نحن ندعم النماذج التالية (يمكنك تعديل الكود لدينا لتشغيل التقييم مع نماذج أخرى).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (يرجى تثبيت Llava كما هو مذكور في إعداد البيئة) تحرير evaluation/score/score.yml . لاحظ أن mc تعني الاختيار من متعدد و oe يعني مفتوحة.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash بالإضافة إلى الوضع multi لإنشاء درجة oe ، والتي تقارن الإجابة على الملصقات الذهبية عبر جميع اللغات ، فإننا ندعم أيضًا إعدادات الإشارة إلى الملصقات الذهبية الأخرى:
single : يقارن الإجابة فقط بالتسمية الذهبية باللغة الأصلية.dual : يقارن إجابة الملصق الذهبي باللغة الأصلية والإنجليزية.بمجرد تعيين ، قم بتشغيل هذا الأمر:
cd evaluation/score/
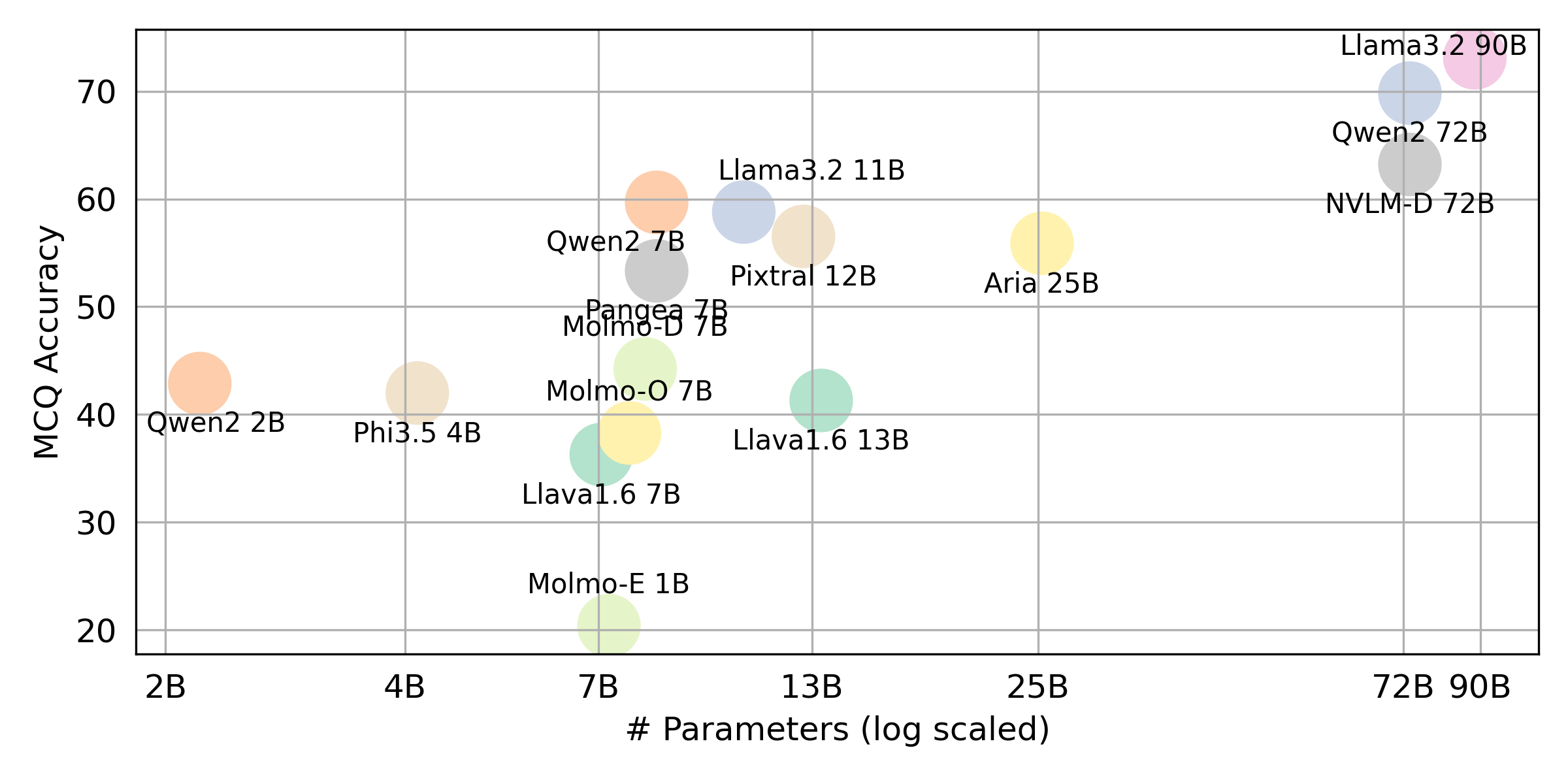
python score.py نحن نقدم قطع الرادار ، المبعثر ، ومخططات خط المبعثرة لتصور نتائج التهديف لجميع VLMs في evaluation/score/plot/ .
لتوليد جميع مؤامرة الرادار ، استخدم:
python evaluation/score/plot/visualization.py
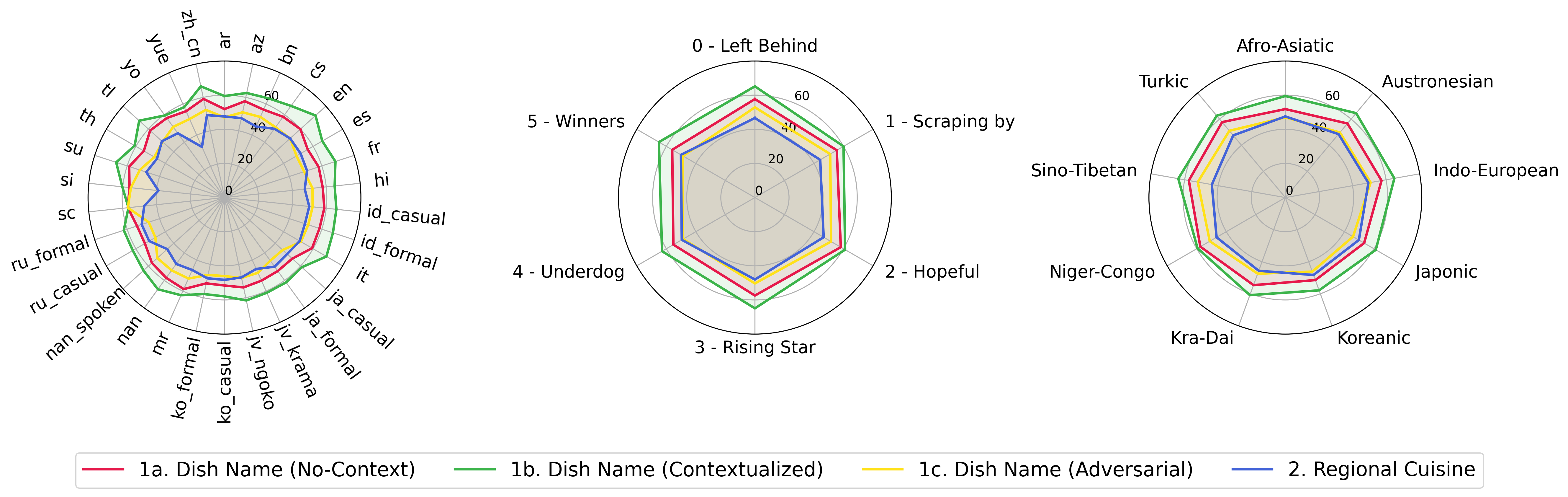
plot_mapper.yml أيضًا تعديل evaluation/score/score.yml .
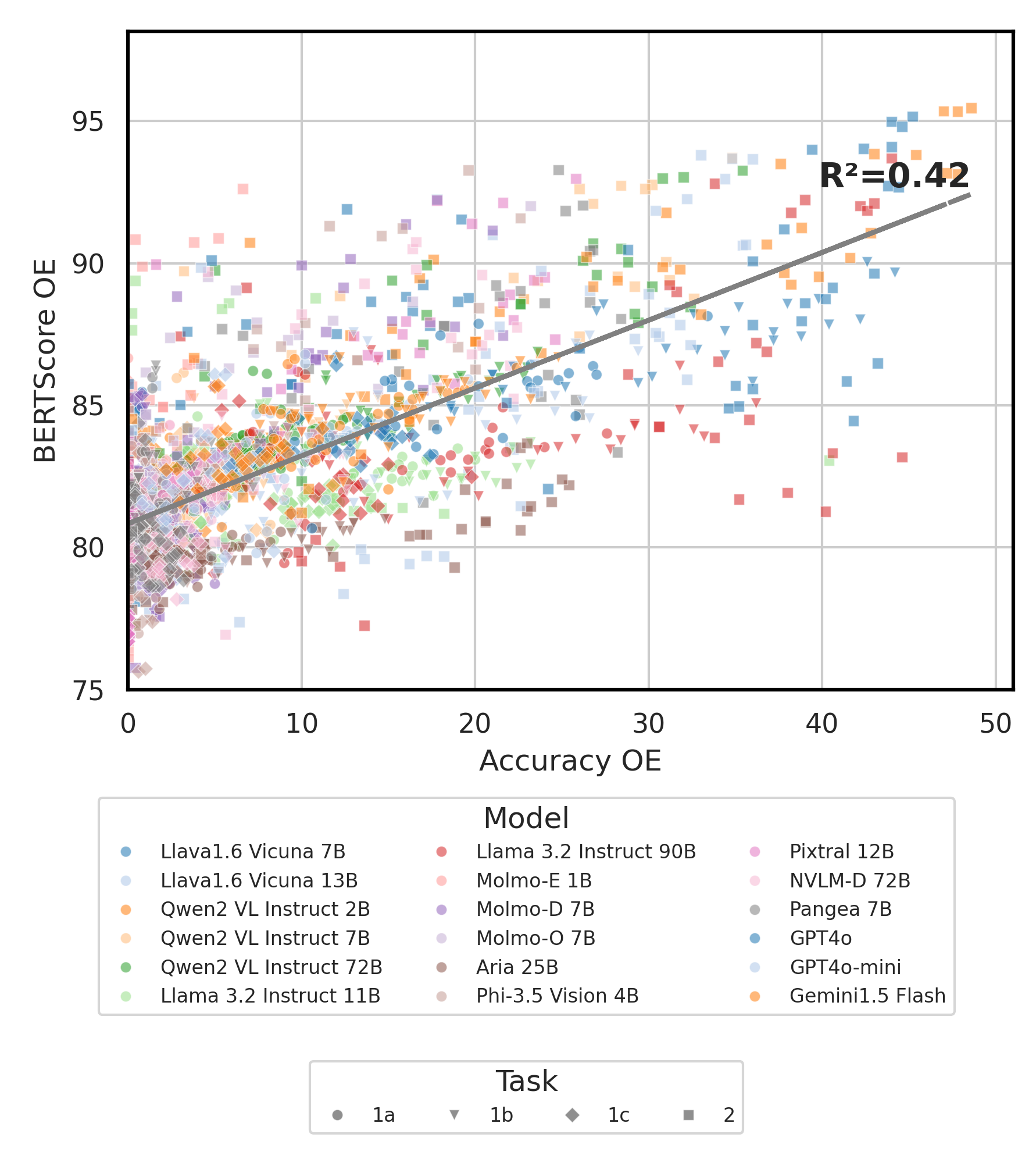
تتوفر نصوص توليد مؤامرة أخرى في ملفات *.ipynb ضمن نفس الدليل.
تدعم قاعدة كودنا استخدام نماذج متعددة للتجارب ، مما يوفر مرونة لتخصيص القائمة الموضحة أدناه:
(آخر اختبار اعتبارًا من أكتوبر 2024)
لإنشاء مجموعة بيانات VQA من قاعدة المعرفة ، يمكنك الرجوع إلى البرنامج النصي generate_vqa/sampling.py . يقوم هذا البرنامج النصي بإنشاء مجموعة البيانات لمختلف المهام في كل من مجموعات التدريب والاختبار.
أوامر مثال: لإنشاء مجموعات بيانات لاختبار مجموعات صغيرة واختبار كبيرة ، قم بتشغيل الأوامر التالية:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| دعوى | وصف | مثال |
|---|---|---|
-o ، --output-csv | إخراج مسار CSV حيث سيتم حفظ مجموعة بيانات VQA التي تم إنشاؤها. | generated_data/test_small_task1.csv |
-n ، --num-samples | الحد الأقصى لعدد الحالات التي سيتم إنشاؤها. إذا تم طلب المزيد من العينات أكثر من الإمكان ، فسيتم ضبط البرنامج النصي. | 9000 |
-nd ، --n-dish-max | الحد الأقصى لعدد فريد من الأطباق لعينة من. | 100 |
-np1a ، --n-prompt-max-type1a | أقصى مطالبات فريدة من المهمة 1 (أ) (عدم السياق) إلى عينة لكل طبق في كل تكرار. | 1 |
-np1b ، --n-prompt-max-type1b | أقصى مطالبات فريدة من المهمة 1 (ب) (سياق) إلى عينة لكل طبق في كل تكرار. | 1 |
-np1c ، --n-prompt-max-type1c | أقصى مطالبات فريدة من المهمة 1 (ج) (خصوم) إلى عينة لكل طبق في كل تكرار. | 1 |
-np2 ، --n-prompt-max-type2 | أقصى مطالبات فريدة من المهمة 2 إلى عينة لكل طبق في كل تكرار. | 1 |
--is-eval ، --no-is-eval | سواء كنت لإنشاء التقييم (اختبار) أو مجموعات بيانات التدريب. | --is-eval للاختبار ، --no-is-eval للقطار |
| دعوى | وصف | مثال |
|---|---|---|
-fr ، --food-raw-path | مسار إلى بيانات الطعام الخام CSV. | food_raw_6oct.csv |
-fc ، --food-cleaned-path | مسار إلى بيانات الغذاء التي تم تنظيفها CSV. | food_cleaned.csv |
-q ، --query-context-path | مسار إلى سياق الاستعلام CSV. | query_ctx.csv |
-l ، --loc-cuis-path | الطريق إلى الموقع والمطبخ CSV. | location_and_cuisine.csv |
-ll ، --list-of-languages | حدد اللغات لاستخدامها كقائمة من السلاسل. | '["en", "id_formal"]' |
-aw ، --alias-aware | تمكين إجابات الخصومة مع أسماء مستعارة متوازية بدلاً من استبدال الأطباق دون ترجمة باللغة الإنجليزية | --alias-aware بمتطلبات إيجاد إجابات تحتوي على ترجمة متوازية عبر جميع اللغات ، --no-alias-aware للاسترخاء متطلبات الأطباق المتوازية |
لا تتردد في إنشاء مشكلة إذا كان لديك أي أسئلة. وإنشاء العلاقات العامة لإصلاح الأخطاء أو إضافة تحسينات.
إذا كنت مهتمًا بإنشاء تمديد لهذا العمل ، فلا تتردد في التواصل معنا!
دعم جهدنا مفتوح المصدر
نقوم بتحسين الكود ، وخاصة على جزء الاستدلال لإنشاء evaluation/result وتسجيل توحيد رمز التصور ، لجعله أكثر سهولة في الاستخدام وقابلة للتخصيص.


