worldcuisines
1.0.0
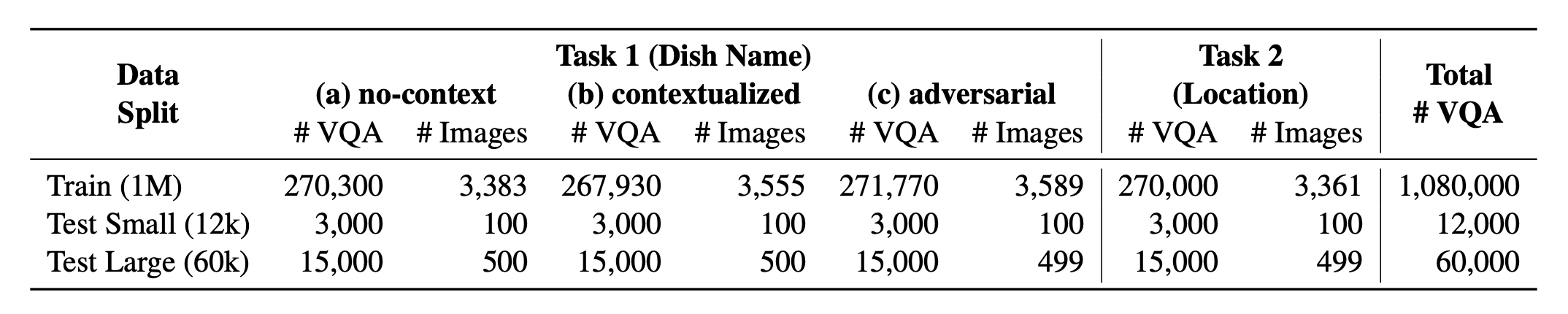
Einführung? Worldcuisines , ein massives mehrsprachiger und multikultureller VQA-Benchmark, der Vision-Sprache-Modelle (VLMs) herausfordert, um die kulturelle Lebensmittelvielfalt in über 30 Sprachen und Dialekten in 9 Sprachfamilien zu verstehen, wobei über 1 Million Datenpunkte aus 2,4K- Schalen mit 6K- Bildern erstellt wurden. Als Benchmark haben wir drei Sätze:

? Weltbauer? umfasst einen ausgewogenen Anteil seiner 2 unterstützten Aufgaben . Wir liefern über 1M Trainingsdaten und eine Bewertungsdaten von 60 km . Unser Benchmark bewertet VLMs an zwei Aufgaben: Vorhersage des Gerichtsnamens und der Gerichtsprüfung. Die Einstellungen umfassen No-Context , kontextualisierte und kontinuierliche infundierte Eingabeaufforderung als Eingabe des Modells.
Unser Datensatz ist bei verfügbar? Umarmung des Gesichtsdatensatzes. Die unterstützenden KB -Daten finden Sie bei? Umarmung des Gesichtsdatensatzes.
Dies ist der Quellcode des Papiers [ARXIV]. Dieser Code wurde mit Python geschrieben. Wenn Sie Code oder Datensätze aus diesem Toolkit in Ihrer Forschung verwenden, geben Sie bitte das zugehörige Papier an.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} Wenn Sie das Endergebnis für alle von uns bewerteten VLLMs erhalten möchten, finden Sie in dieser Rangliste für die Zusammenfassung. Die RAW -Ergebnisse werden in das Verzeichnis evaluation/score/json platziert.
Bitte führen Sie den folgenden Befehl aus, um die erforderlichen Bibliotheken zu installieren, um die Benchmark -Ergebnisse zu reproduzieren.
pip pip install -r requirements.txt
conda conda env create -f env.yml
Für Pangaea laufen Sie bitte Folgendes aus
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
Alle Experimentergebnisse werden in der evaluation/result/ des Verzeichnisses gespeichert. Die Ergebnisse werden mithilfe der Genauigkeit für alle Aufgaben bewertet, insbesondere für Open-End-Aufgaben (OEQ). Wir verwenden Genauigkeit, die mit Multi-Referenz berechnet wurde. Sie können jedes Experiment mit den folgenden Befehlen ausführen:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| Argument | Beschreibung | Beispiel / Standard |
|---|---|---|
--task | Aufgabenummer zu bewerten (1 oder 2) | 1 (Standard), 2 |
--type | Art der Frage zu bewerten ( oe oder mc ) | mc (Standard), oe |
--model_path | Pfad zum Modell | Qwen/Qwen2-VL-72B-Instruct (Standard) + andere |
--fp32 | Verwenden Sie float32 anstelle von float16 / bfloat16 | False (Standard) |
--multi_gpu | Verwenden Sie mehrere GPUs | False (Standard) |
-n , --chunk_num | Anzahl der Stücke, um die Daten in die Daten aufzuteilen | 1 (Standard) |
-k , --chunk_id | Chunk ID (0 basiert) | 0 (Standard) |
-s , --st_idx | Starten Sie den Index für das Schneiden von Daten (inklusive) | None (Standard) |
-e , --ed_idx | Endindex zum Schneiden von Daten (exklusiv) | None (Standard) |
Wir unterstützen die folgenden Modelle (Sie können unseren Code so ändern, dass Sie die Bewertung mit anderen Modellen ausführen).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (Bitte installieren Sie LLAVA, wie in ⚡ Umgebungs-Setup erwähnt) Bearbeiten Sie evaluation/score/score.yml um Bewertungsmodus, Bewertungssatz und Bewertung von VLMs zu bestimmen. Beachten Sie, dass mc Multiple-Choice bedeutet und oe offen geöffnet ist.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash Zusätzlich zum multi -Modus zur Erzeugung des oe -Scores, der die Antwort auf die goldenen Etiketten in allen Sprachen vergleicht, unterstützen wir auch andere Einstellungen für goldene Etiketten:
single : Vergleicht die Antwort nur mit dem Goldenen Label in der Originalsprache.dual Referenz : Vergleicht die Antwort auf das Goldene Label in der Originalsprache und Englisch.Sobald Sie eingestellt haben, führen Sie diesen Befehl aus:
cd evaluation/score/
python score.py Wir liefern Radar-, Streu- und Verbundene Streuzeilendiagramme, um die Bewertungsergebnisse für alle VLMs in evaluation/score/plot/ zu visualisieren.
Verwenden Sie, um alle Radardiagramme zu erzeugen:
python evaluation/score/plot/visualization.py
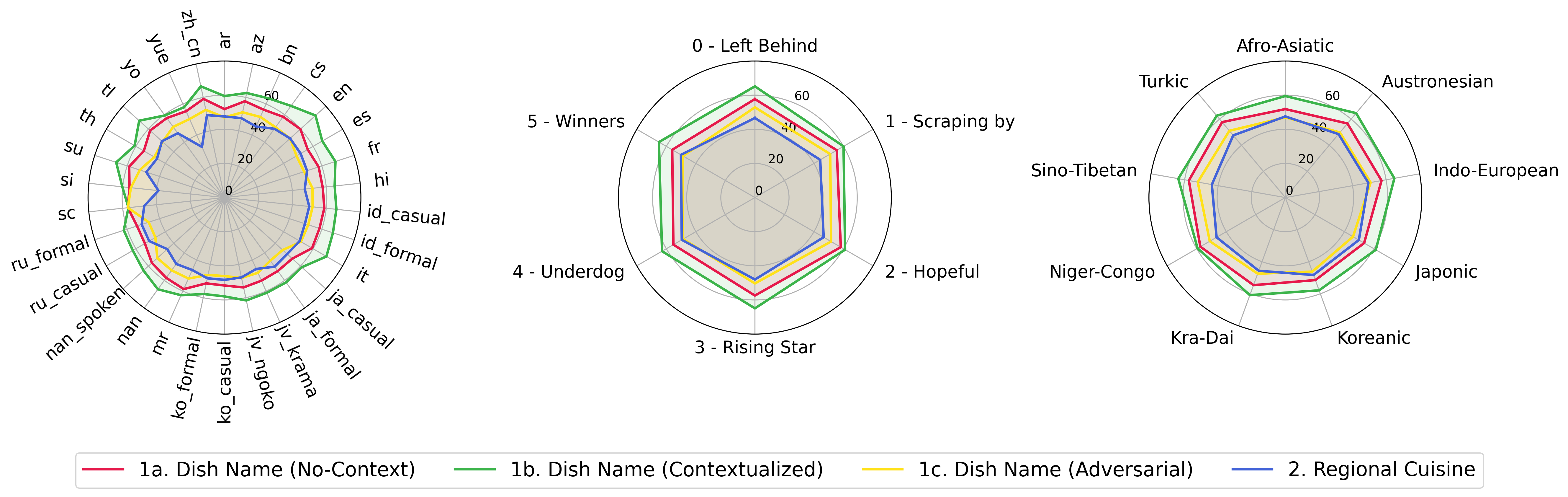
Sie können evaluation/score/score.yml auch ändern, um auszuwählen, welche VLMs die Diagrammbezeichnungen in plot_mapper.yml visualisieren und anpassen können.
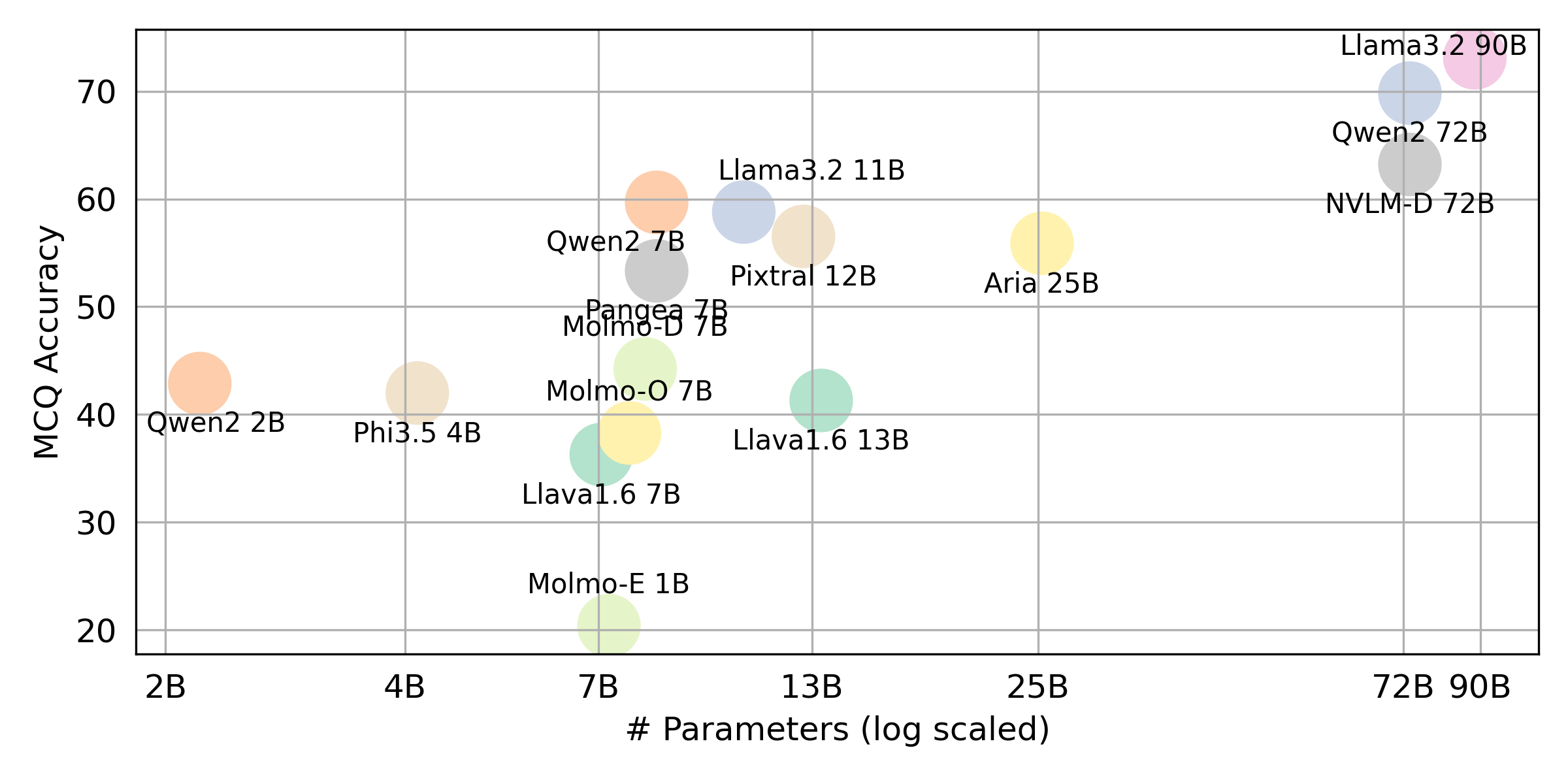
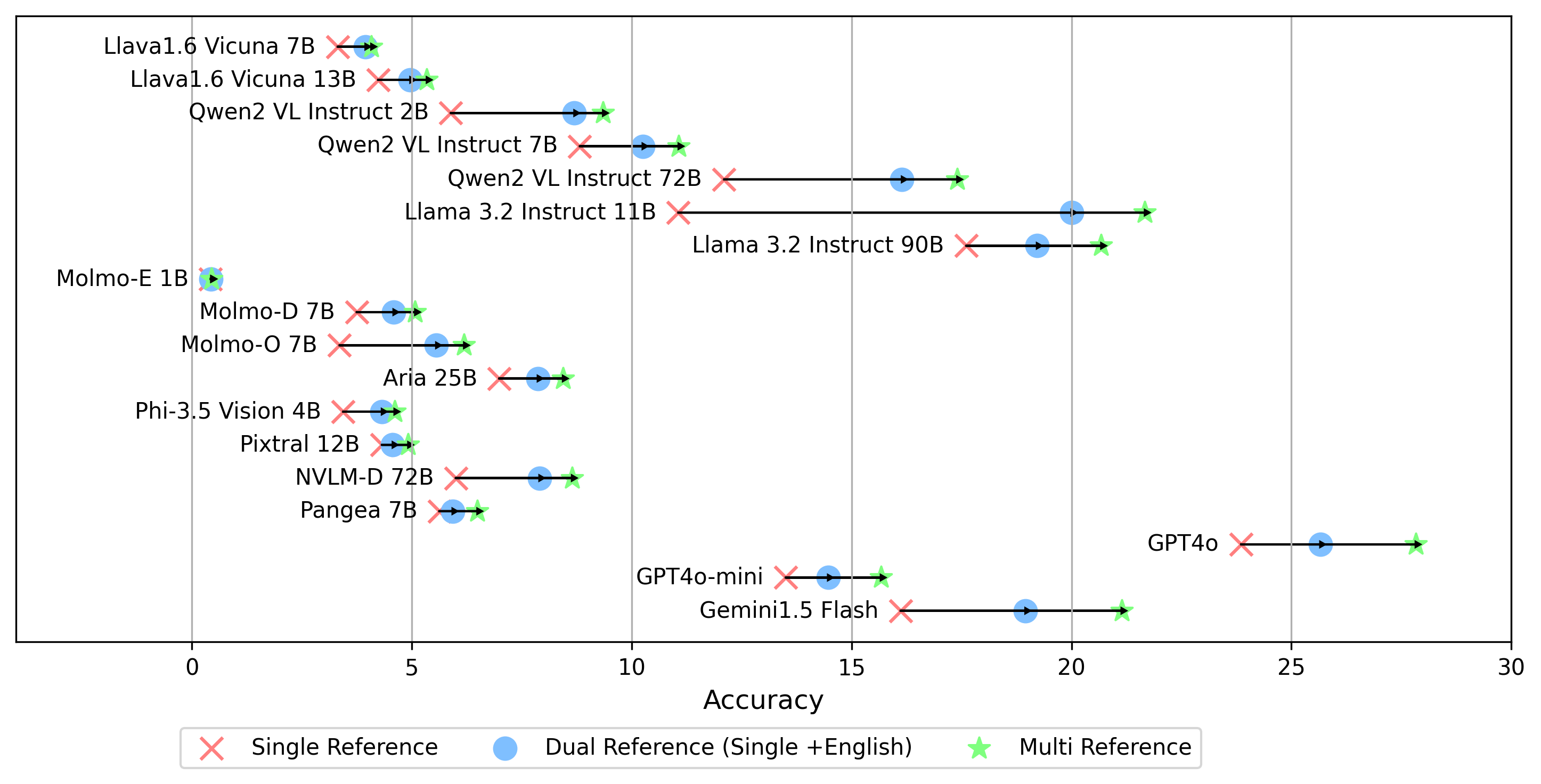
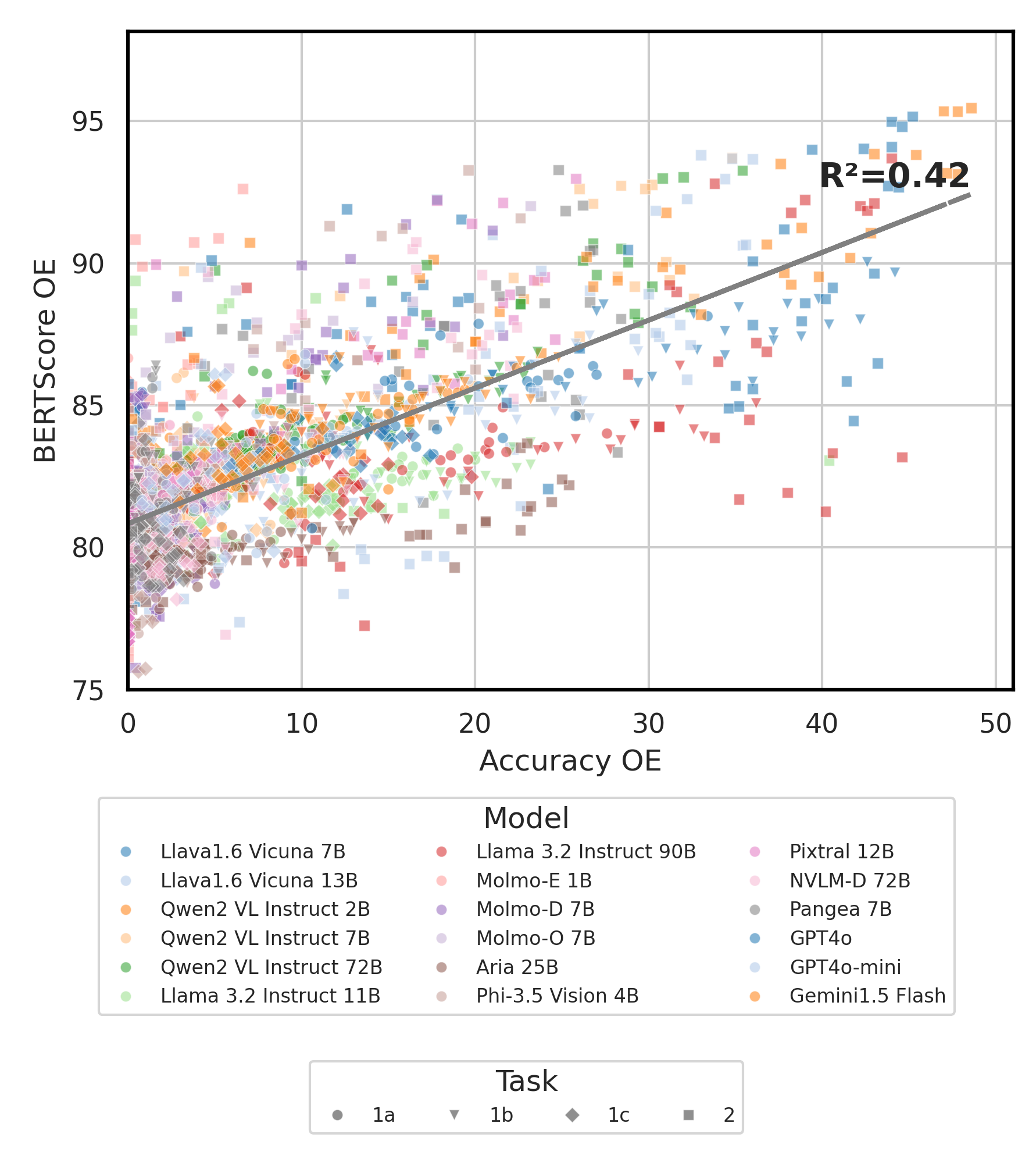
Andere Skripte zur Erzeugung von Handlungen sind in den *.ipynb -Dateien in demselben Verzeichnis verfügbar.
Unsere Codebasis unterstützt die Verwendung mehrerer Modelle für die Experimente und bietet Flexibilität für die Anpassung der unten gezeigten Liste:
(Zuletzt getestet im Oktober 2024)
Um einen VQA -Datensatz aus der Wissensbasis zu generieren, können Sie sich auf das Skript generate_vqa/sampling.py beziehen. Dieses Skript generiert den Datensatz für verschiedene Aufgaben sowohl in den Trainings- als auch in den Testsätzen.
Beispielbefehle: So generieren Datensätze zum Test kleiner , großer Testen und Zugsätzen , führen Sie die folgenden Befehle aus:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| Argument | Beschreibung | Beispiel |
|---|---|---|
-o , --output-csv | Ausgabe CSV -Pfad, auf dem der generierte VQA -Datensatz gespeichert wird. | generated_data/test_small_task1.csv |
-n , --num-samples | Maximale Anzahl von Instanzen zu generieren. Wenn mehr Beispiele als möglich angefordert werden, wird das Skript angepasst. | 9000 |
-nd , --n-dish-max | Maximale eindeutige Anzahl von Gerichten, aus denen man probieren kann. | 100 |
-np1a , --n-prompt-max-type1a | Maximale eindeutige Eingabeaufforderungen aus Aufgabe 1 (a) (Nicht-Kontext), um in jeder Iteration pro Gericht zu probieren. | 1 |
-np1b , --n-prompt-max-type1b | Maximale eindeutige Eingabeaufforderungen von Aufgabe 1 (b) (kontextualisiert) in jeder Iteration pro Gericht pro Gericht. | 1 |
-np1c , --n-prompt-max-type1c | Maximale eindeutige Eingabeaufforderungen von Aufgabe 1 (c) (kontrovers) in jeder Iteration probieren. | 1 |
-np2 , --n-prompt-max-type2 | Maximale eindeutige Eingabeaufforderungen von Aufgabe 2 bis Proben pro Gericht in jeder Iteration. | 1 |
--is-eval , --no-is-eval | Ob Sie Bewertung (Test) oder Schulungsdatensätze generieren. | --is-eval für Test, --no-is-eval für den Zug |
| Argument | Beschreibung | Beispiel |
|---|---|---|
-fr , --food-raw-path | Pfad zu den Rohfutterdaten CSV. | food_raw_6oct.csv |
-fc , --food-cleaned-path | Pfad zu den gereinigten Lebensmitteldaten CSV. | food_cleaned.csv |
-q , --query-context-path | Pfad zum Abfragekontext CSV. | query_ctx.csv |
-l , --loc-cuis-path | Pfad zum Ort und zur Küche CSV. | location_and_cuisine.csv |
-ll , --list-of-languages | Geben Sie Sprachen an, die als Liste von Zeichenfolgen verwendet werden sollen. | '["en", "id_formal"]' |
-aw , --alias-aware | Aktivieren Sie die kontroversen Antworten mit parallele Aliase, anstatt Gerichte ohne Übersetzung durch Englisch zu ersetzen | --alias-aware für die Anforderung, Antworten zu finden, die eine parallele Übersetzung in allen Sprachen enthalten, --no-alias-aware |
Fühlen Sie sich frei, ein Problem zu erstellen, wenn Sie Fragen haben. Erstellen Sie eine PR, um Fehler zu beheben oder Verbesserungen hinzuzufügen.
Wenn Sie daran interessiert sind, eine Erweiterung dieser Arbeit zu erstellen, können Sie sich gerne an uns wenden!
Unterstützen Sie unsere Open Source -Anstrengung
Wir verbessern den Code, insbesondere im Inferenzteil, um die Vereinigung evaluation/result und Bewertungsvisualisierungscode zu generieren, um benutzerfreundlicher und anpassbarer zu gestalten.


