worldcuisines
1.0.0
Представляем? WorldCuisines , масштабный многоязычный и многокультурный эталон VQA, который бросает вызов моделям языка (VLMS) для понимания культурного разнообразия пищевых продуктов на более чем 30 языках и диалектах на 9 языковых семействах , причем более 1 миллиона точек данных, полученные из 2,4K блюда с 6K -изображениями. Как эталон, у нас есть три набора:

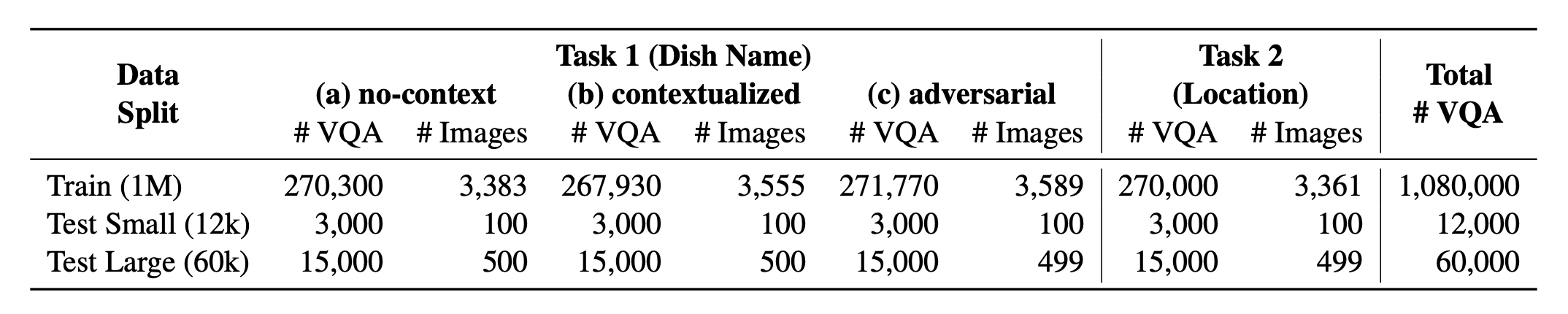
? Worldcuisines? содержит сбалансированную долю 2 -х поддерживаемых задач . Мы предоставляем более 1 млн обучающих данных и 60 тыс. Данные оценки . Наш эталон оценивает VLMS по двум задачам: прогноз названия блюд и прогноз места расположения блюда. Настройки включают в себя неконтексту , контекстуализированные и состязательные приглашения в качестве ввода модели.
Наш набор данных доступен? Объятие набора данных лица. Вспомогательные данные KB можно найти? Объятие набора данных лица.
Это исходный код статьи [arxiv]. Этот код был написан с использованием Python. Если вы используете какой -либо код или наборы данных из этого инструментария в своем исследовании, пожалуйста, укажите связанную статью.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} Если вы хотите получить окончательный результат для всех VLLM, которые мы оцениваем, пожалуйста, обратитесь к этому таблицу лидеров для резюме. Результаты необработанного в каталоге evaluation/score/json .
Пожалуйста, запустите следующую команду, чтобы установить необходимые библиотеки, чтобы воспроизвести результаты эталона.
pip pip install -r requirements.txt
conda conda env create -f env.yml
Для Pangea, пожалуйста, запустите следующее
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
Все результаты эксперимента будут храниться в evaluation/result/ каталоге. Результаты оцениваются с использованием точности для всех задач, в частности для открытой задачи (OEQ), мы используем точность, рассчитанную с использованием мульти-ссылки . Вы можете выполнить каждый эксперимент, используя следующие команды:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| Аргумент | Описание | Пример / по умолчанию |
|---|---|---|
--task | Номер задачи для оценки (1 или 2) | 1 (по умолчанию), 2 |
--type | Тип вопроса для оценки ( oe или mc ) | mc (по умолчанию), oe |
--model_path | Путь к модели | Qwen/Qwen2-VL-72B-Instruct (по умолчанию) + другие |
--fp32 | Используйте float32 вместо float16 / bfloat16 | False (по умолчанию) |
--multi_gpu | Используйте несколько графических процессоров | False (по умолчанию) |
-n , --chunk_num | Количество кусков, чтобы разделить данные на | 1 (по умолчанию) |
-k , --chunk_id | Идентификатор куски (на основе 0) | 0 (по умолчанию) |
-s , --st_idx | Начать индекс для нарезки данных (включительно) | None (по умолчанию) |
-e , --ed_idx | Конечный индекс для нарезки данных (эксклюзив) | None (по умолчанию) |
Мы поддерживаем следующие модели (вы можете изменить наш код для запуска оценки с другими моделями).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (пожалуйста, установите Llava, как указано в ⚡ Setup Environment) Редактировать evaluation/score/score.yml . Обратите внимание, что mc означает множественные выбора, а oe означает открытый.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash В дополнение к multi режимам для генерации оценки oe , который сравнивает ответ с золотыми этикетками на всех языках, мы также поддерживаем другие настройки ссылки на золотые этикетки:
single ссылка : сравнивает ответ только с золотым этикеткой на оригинальном языке.dual ссылка : сравнивает ответ с золотым лейблом на оригинальном языке и английском языке.После установки запустите эту команду:
cd evaluation/score/
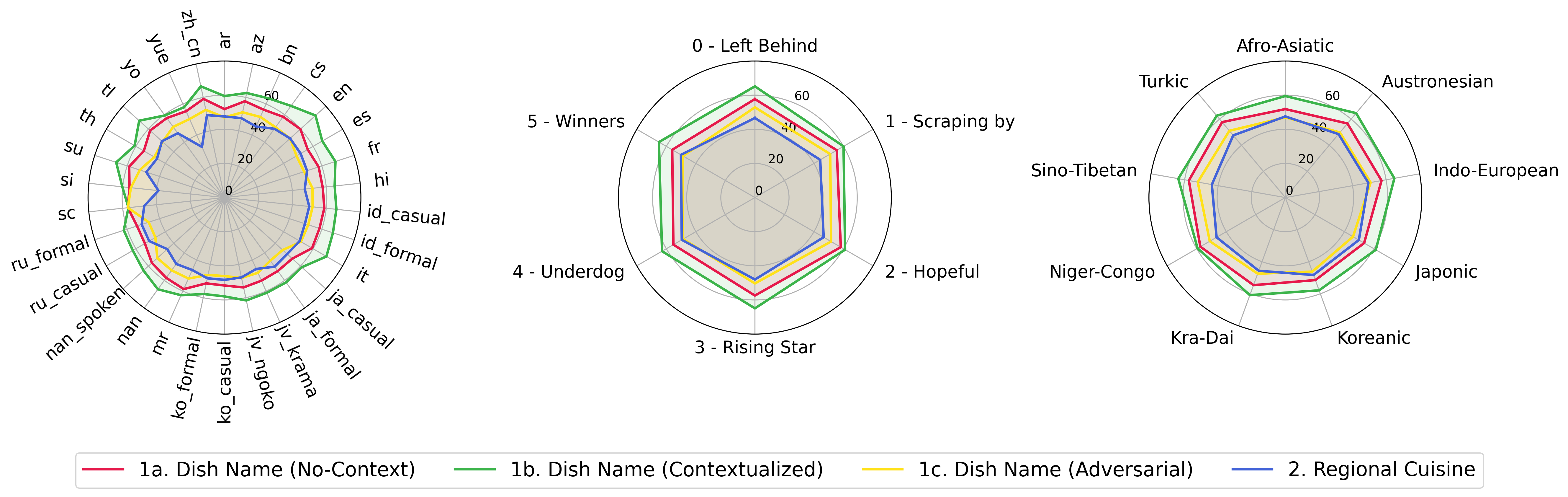
python score.py Мы предоставляем радар, рассеяние и подключенные графики рассеяния, чтобы визуализировать результаты оценки для всех VLM в evaluation/score/plot/ .
Чтобы генерировать весь радиолокационный график , используйте:
python evaluation/score/plot/visualization.py
plot_mapper.yml также можете изменить evaluation/score/score.yml .
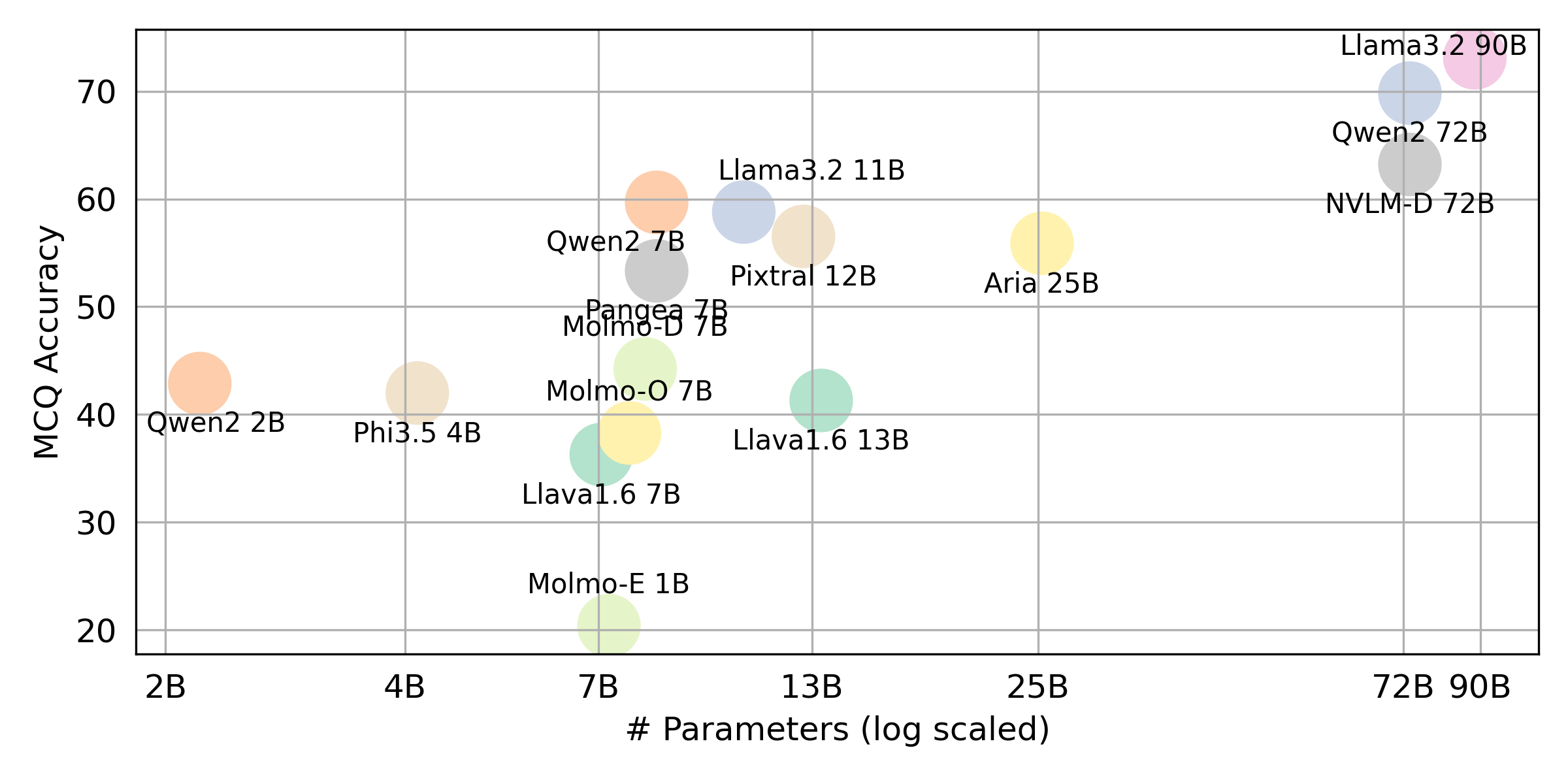
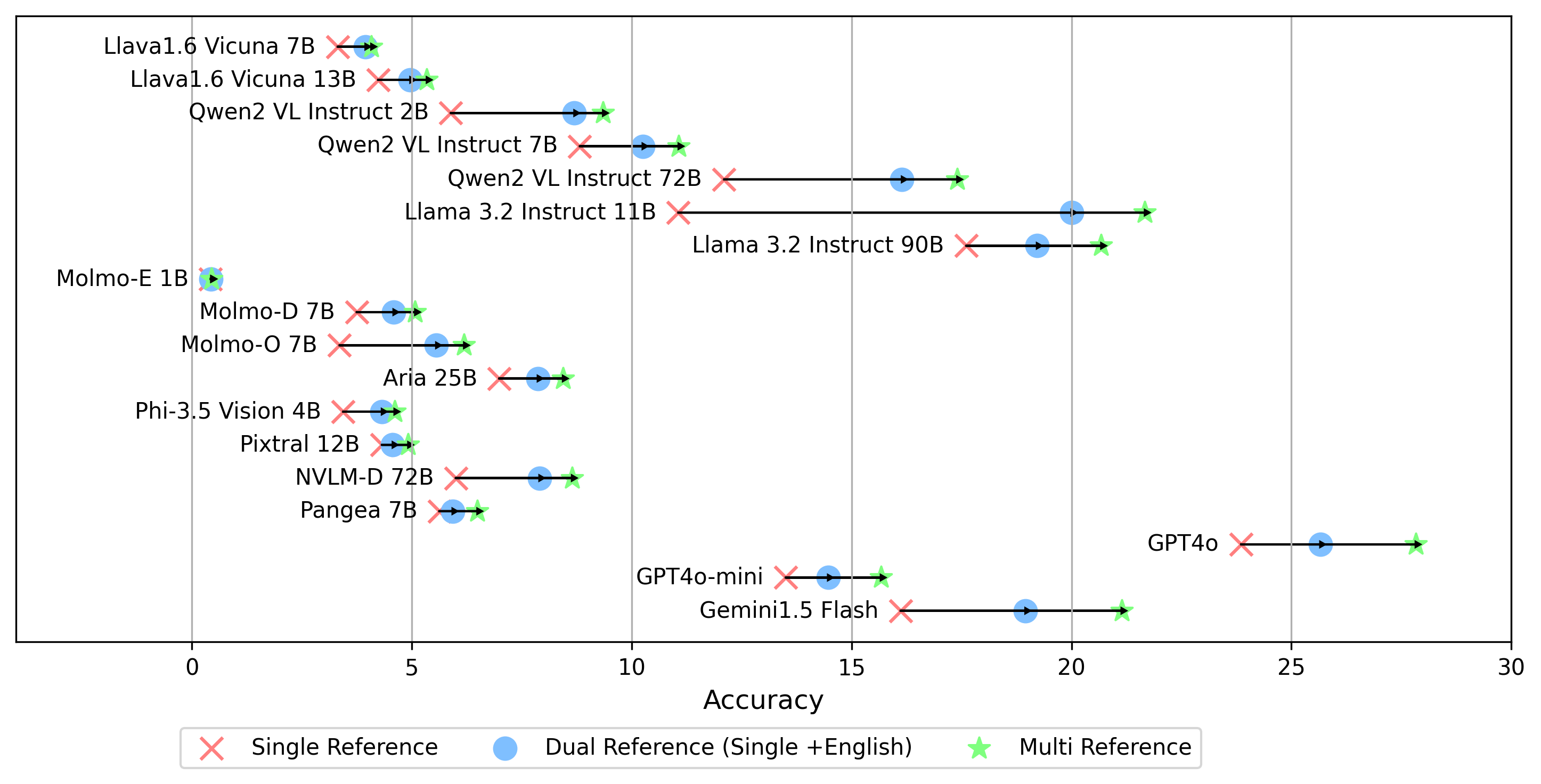
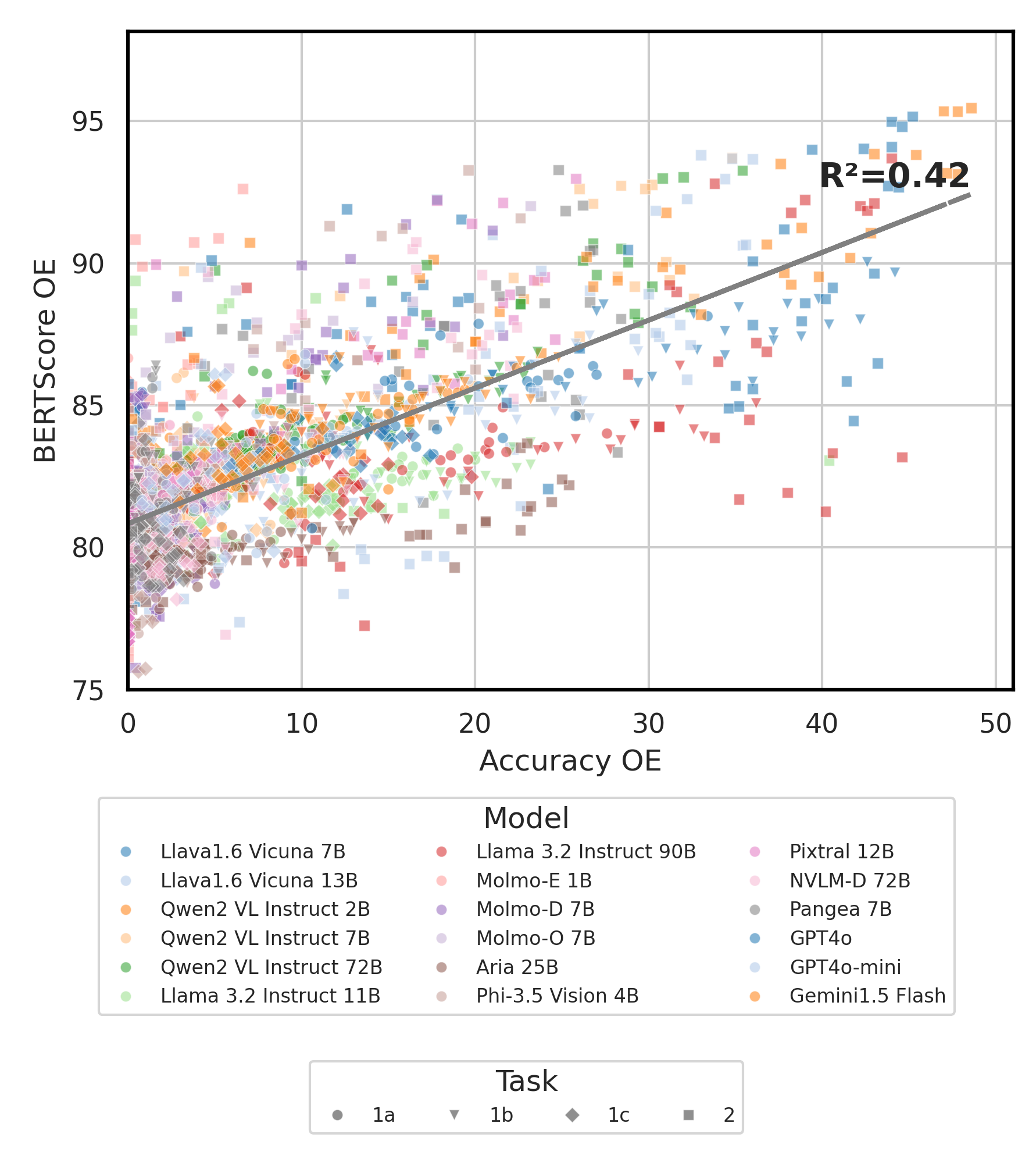
Другие сценарии генерации сюжета доступны в файлах *.ipynb в том же каталоге.
Наша кодовая база поддерживает использование нескольких моделей для экспериментов, обеспечивая гибкость для настройки списка, показанного ниже:
(Последнее тестирование по состоянию на октябрь 2024 г.)
Чтобы сгенерировать набор данных VQA из базы знаний, вы можете обратиться к сценарию generate_vqa/sampling.py . Этот скрипт генерирует набор данных для различных задач как в наборах обучения, так и в тестировании.
Примеры команд: Для создания наборов данных для тестирования маленьких , тестирования больших и наборов поездов , запустите следующие команды:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| Аргумент | Описание | Пример |
|---|---|---|
-o , --output-csv | Выходный путь CSV, где будет сохранен сгенерированный набор данных VQA. | generated_data/test_small_task1.csv |
-n , --num-samples | Максимальное количество экземпляров, которые будут сгенерированы. Если запрашивается больше образцов, чем возможно, сценарий скорректирует. | 9000 |
-nd , --n-dish-max | Максимальное уникальное количество блюд для образца. | 100 |
-np1a , --n-prompt-max-type1a | Максимальные уникальные подсказки от задачи 1 (a) (без контекста) до образца на блюдо в каждой итерации. | 1 |
-np1b , --n-prompt-max-type1b | Максимальные уникальные подсказки от задачи 1 (b) (контекстуализирован) до выборки на блюдо в каждой итерации. | 1 |
-np1c , --n-prompt-max-type1c | Максимальные уникальные подсказки от задачи 1 (c) (состязание) до образца на блюдо в каждой итерации. | 1 |
-np2 , --n-prompt-max-type2 | Максимальные уникальные подсказки от задачи 2 до образца на блюдо в каждой итерации. | 1 |
--is-eval , --no-is-eval | Создавать ли оценку (тест) или обучающие наборы данных. | --is-eval для тестирования, --no-is-eval для поезда |
| Аргумент | Описание | Пример |
|---|---|---|
-fr , --food-raw-path | Путь к данным сырой пищи CSV. | food_raw_6oct.csv |
-fc , --food-cleaned-path | Путь к данным очищенной пищи CSV. | food_cleaned.csv |
-q , --query-context-path | Путь к контексту запроса CSV. | query_ctx.csv |
-l , --loc-cuis-path | Путь к местоположению и кухни CSV. | location_and_cuisine.csv |
-ll , --list-of-languages | Укажите языки, которые будут использоваться в качестве списка строк. | '["en", "id_formal"]' |
-aw , --alias-aware | Включить состязательные ответы с параллельными псевдонимами вместо замены блюд без перевода на английский язык | --alias-aware для требования найти ответы, которые содержат параллельный перевод на всех языках, --no-alias-aware чтобы расслабить параллельное блюдо. |
Не стесняйтесь создавать проблему, если у вас есть какие -либо вопросы. И создайте пиар для исправления ошибок или добавления улучшений.
Если вы заинтересованы в создании расширения этой работы, не стесняйтесь обратиться к нам!
Поддержите наши усилия с открытым исходным кодом
Мы улучшаем код, особенно на части вывода, чтобы сгенерировать evaluation/result и оценку объединения кода визуализации, чтобы сделать его более удобным и настраиваемым.


