worldcuisines
1.0.0
Memperkenalkan? Worldcuisine , sebuah tolok ukur VQA multibahasa dan multikultural skala besar yang menantang model bahasa penglihatan (VLM) untuk memahami keragaman makanan budaya dalam lebih dari 30 bahasa dan dialek , di 9 keluarga bahasa , dengan lebih dari 1 juta poin data yang tersedia dihasilkan dari 2,4K hidangan dengan gambar 6K . Sebagai patokan, kami memiliki tiga set:

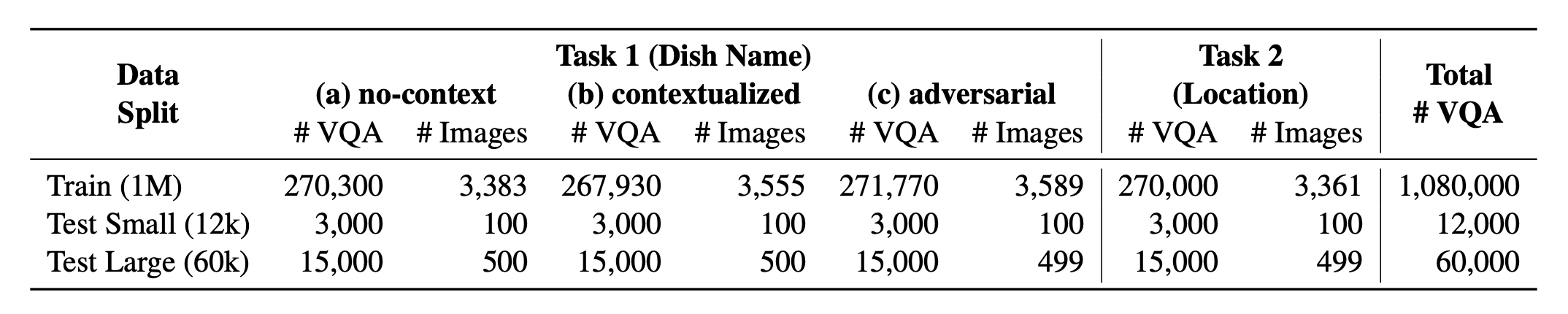
? Worldcuisine? terdiri dari proporsi yang seimbang dari 2 tugas yang didukungnya . Kami menyediakan lebih dari 1 juta data pelatihan dan data evaluasi 60K . Benchmark kami mengevaluasi VLM pada dua tugas: prediksi nama hidangan dan prediksi lokasi hidangan. Pengaturan termasuk no-context , contextualed , dan prompt yang diinfuskan sebagai input model.
Dataset kami tersedia di? Memeluk dataset wajah. Data KB pendukung dapat ditemukan di? Memeluk dataset wajah.
Ini adalah kode sumber dari makalah [arxiv]. Kode ini telah ditulis menggunakan Python. Jika Anda menggunakan kode atau set data dari toolkit ini dalam penelitian Anda, silakan kutip kertas terkait.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} Jika Anda ingin mendapatkan hasil akhir untuk semua VLLM yang kami evaluasi, silakan merujuk ke papan peringkat ini untuk ringkasan. Hasil mentah ditempatkan di direktori evaluation/score/json .
Silakan jalankan perintah berikut untuk menginstal pustaka yang diperlukan untuk mereproduksi hasil patokan.
pip pip install -r requirements.txt
conda conda env create -f env.yml
Untuk Pangea, silakan jalankan berikut ini
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
Semua hasil percobaan akan disimpan dalam evaluation/result/ direktori. Hasilnya dievaluasi menggunakan akurasi untuk semua tugas, khususnya untuk tugas terbuka (OEQ), kami menggunakan akurasi yang dihitung menggunakan multi-referensi . Anda dapat menjalankan setiap percobaan menggunakan perintah berikut:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| Argumen | Keterangan | Contoh / default |
|---|---|---|
--task | Nomor tugas untuk dievaluasi (1 atau 2) | 1 (default), 2 |
--type | Jenis pertanyaan untuk dievaluasi ( oe atau mc ) | mc (default), oe |
--model_path | Jalur ke model | Qwen/Qwen2-VL-72B-Instruct (default) + Lainnya |
--fp32 | Gunakan float32 bukan float16 / bfloat16 | False (default) |
--multi_gpu | Gunakan beberapa GPU | False (default) |
-n , --chunk_num | Jumlah potongan untuk membagi data menjadi | 1 (default) |
-k , --chunk_id | ID Chunk (berbasis 0) | 0 (default) |
-s , --st_idx | Mulai Indeks untuk Mengiris Data (Inklusif) | None (default) |
-e , --ed_idx | Indeks Akhir untuk Mengiris Data (Eksklusif) | None (default) |
Kami mendukung model -model berikut (Anda dapat memodifikasi kode kami untuk menjalankan evaluasi dengan model lain).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (silakan instal LLAVA seperti yang disebutkan dalam ⚡ Pengaturan Lingkungan) Edit evaluation/score/score.yml untuk menentukan mode penilaian, set evaluasi, dan mengevaluasi VLM. Perhatikan bahwa mc berarti pilihan ganda dan oe berarti terbuka.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash Selain mode multi untuk menghasilkan skor oe , yang membandingkan jawaban untuk label emas di semua bahasa, kami juga mendukung pengaturan referensi label emas lainnya:
single : membandingkan jawaban hanya dengan label emas dalam bahasa asli.dual : Membandingkan jawaban label emas dalam bahasa asli dan bahasa Inggris.Setelah diatur, jalankan perintah ini:
cd evaluation/score/
python score.py Kami menyediakan plot radar, hamburan, dan terhubung garis sebar untuk memvisualisasikan hasil penilaian untuk semua VLM dalam evaluation/score/plot/ .
Untuk menghasilkan semua plot radar , gunakan:
python evaluation/score/plot/visualization.py
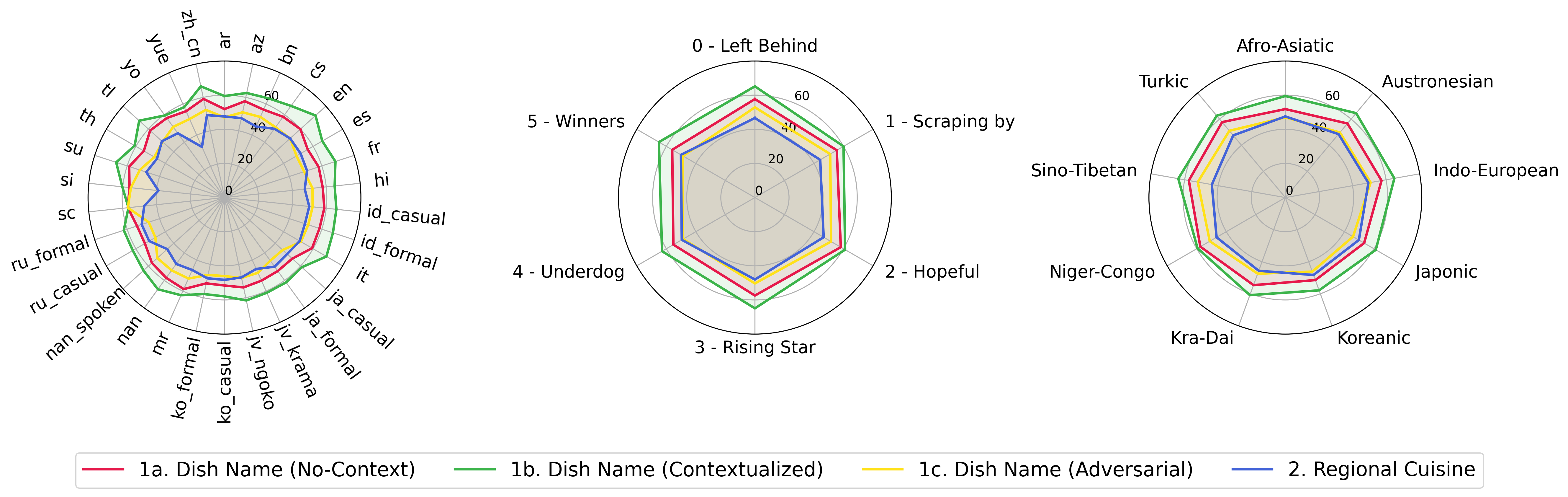
Anda juga dapat memodifikasi evaluation/score/score.yml untuk memilih VLM mana yang akan memvisualisasikan dan menyesuaikan label plot di plot_mapper.yml .
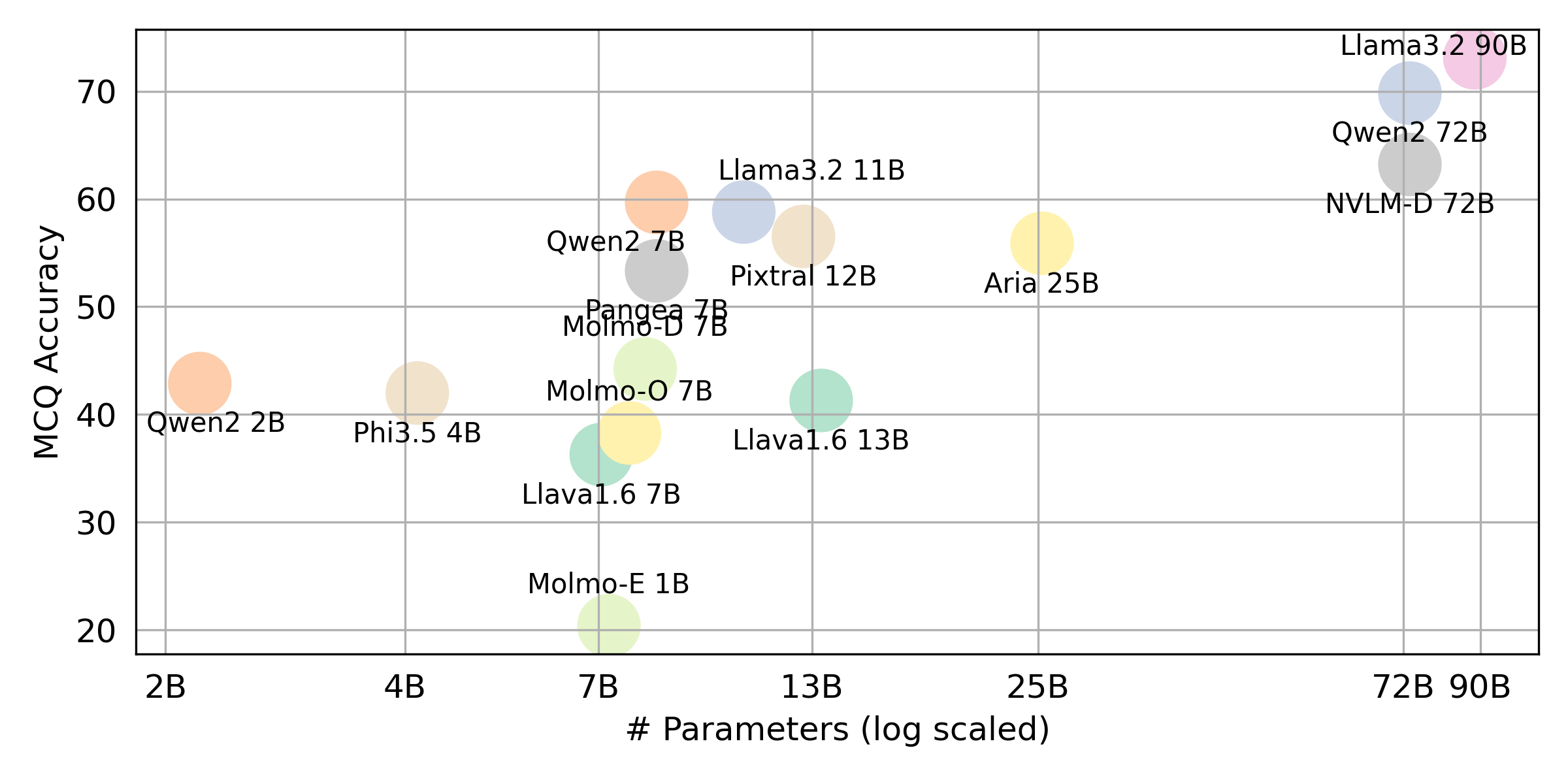
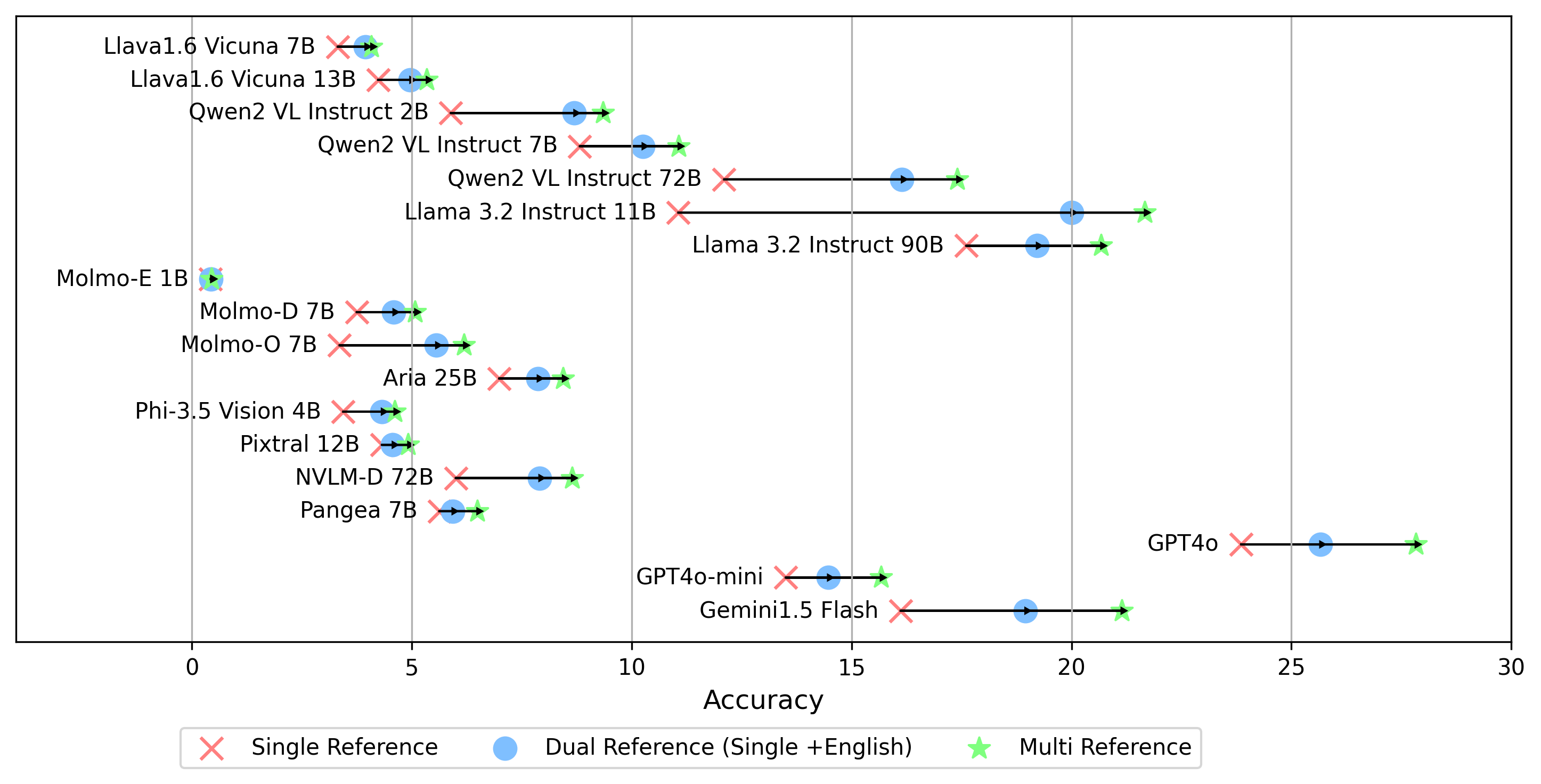
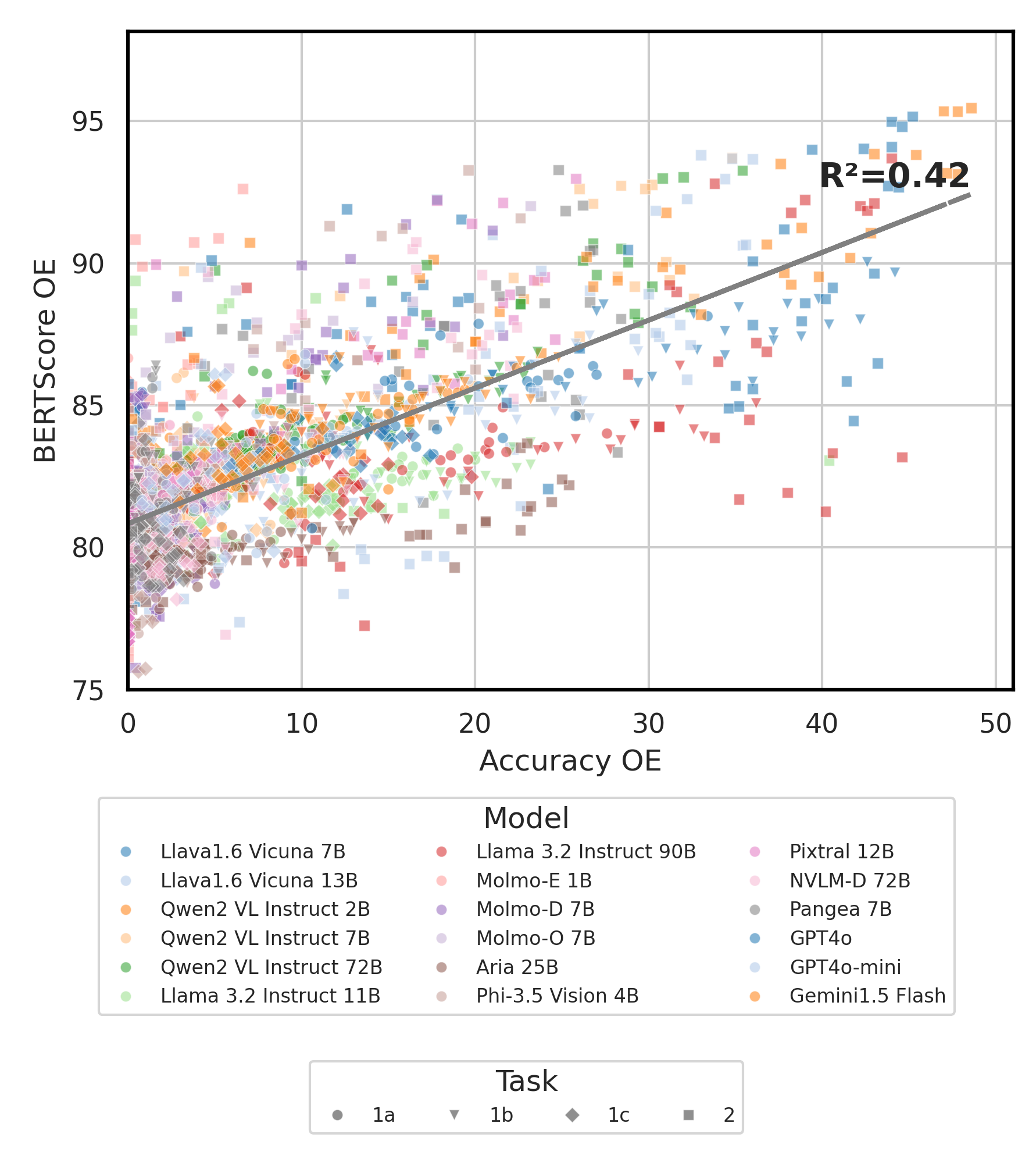
Skrip pembuatan plot lainnya tersedia di file *.ipynb dalam direktori yang sama.
Basis kode kami mendukung penggunaan beberapa model untuk percobaan, memberikan fleksibilitas untuk kustomisasi daftar yang ditunjukkan di bawah ini:
(Terakhir diuji pada Oktober 2024)
Untuk menghasilkan dataset VQA dari basis pengetahuan, Anda dapat merujuk ke skrip generate_vqa/sampling.py . Skrip ini menghasilkan dataset untuk berbagai tugas di kedua set pelatihan dan pengujian.
Contoh Perintah: Untuk menghasilkan set data untuk tes kecil , uji besar , dan set kereta , jalankan perintah berikut:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| Argumen | Keterangan | Contoh |
|---|---|---|
-o , --output-csv | Output jalur CSV di mana dataset VQA yang dihasilkan akan disimpan. | generated_data/test_small_task1.csv |
-n , --num-samples | Jumlah maksimum instance yang akan dihasilkan. Jika lebih banyak sampel diminta daripada yang mungkin, skrip akan menyesuaikan. | 9000 |
-nd , --n-dish-max | Jumlah hidangan unik maksimum untuk sampel dari. | 100 |
-np1a , --n-prompt-max-type1a | Permintaan unik maksimum dari Tugas 1 (a) (NO-Context) untuk sampel per piringan di setiap iterasi. | 1 |
-np1b , --n-prompt-max-type1b | Perkumpulan unik maksimum dari tugas 1 (b) (kontekstual) untuk sampel per piringan di setiap iterasi. | 1 |
-np1c , --n-prompt-max-type1c | Permintaan unik maksimum dari Tugas 1 (c) (permusuhan) untuk sampel per piringan di setiap iterasi. | 1 |
-np2 , --n-prompt-max-type2 | Permintaan unik maksimum dari tugas 2 ke sampel per hidangan di setiap iterasi. | 1 |
--is-eval , --no-is-eval | Apakah akan menghasilkan evaluasi (tes) atau kumpulan data pelatihan. | --is-eval untuk tes, --no-is-eval for train |
| Argumen | Keterangan | Contoh |
|---|---|---|
-fr , --food-raw-path | Jalur ke data makanan mentah CSV. | food_raw_6oct.csv |
-fc , --food-cleaned-path | Jalur ke data makanan yang dibersihkan CSV. | food_cleaned.csv |
-q , --query-context-path | Jalur ke konteks kueri CSV. | query_ctx.csv |
-l , --loc-cuis-path | Jalur ke lokasi dan masakan CSV. | location_and_cuisine.csv |
-ll , --list-of-languages | Tentukan bahasa yang akan digunakan sebagai daftar string. | '["en", "id_formal"]' |
-aw , --alias-aware | Aktifkan jawaban permusuhan dengan alias paralel alih -alih mengganti hidangan tanpa terjemahan dengan bahasa Inggris | --alias-aware untuk persyaratan untuk menemukan jawaban yang berisi terjemahan paralel di semua bahasa, --no-alias-aware untuk melonggarkan persyaratan nama hidangan paralel |
Jangan ragu untuk membuat masalah jika Anda memiliki pertanyaan. Dan, buat PR untuk memperbaiki bug atau menambahkan perbaikan.
Jika Anda tertarik untuk membuat perpanjangan dari pekerjaan ini, jangan ragu untuk menjangkau kami!
Dukung upaya open source kami
Kami meningkatkan kode, terutama pada bagian inferensi untuk menghasilkan evaluation/result dan mencetak penyatuan kode visualisasi, untuk membuatnya lebih ramah pengguna dan dapat disesuaikan.


