worldcuisines
1.0.0
Apresentando? O WorldCuisines , um benchmark VQA multilíngue e multicultural em escala maciça, que desafia os modelos de linguagem da visão (VLMs) a entender a diversidade cultural de alimentos em mais de 30 idiomas e dialetos , em 9 famílias de idiomas , com mais de 1 milhão de pontos disponíveis gerados a partir de 2,4 mil pratos com imagens de 6 mil . Como referência, temos três conjuntos:

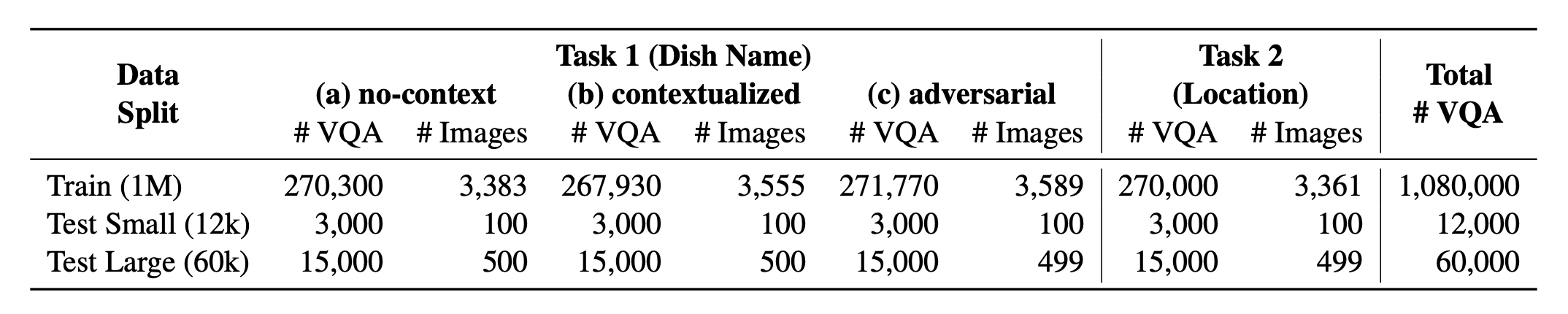
? Worldcuisines? compreende uma proporção equilibrada de suas duas tarefas suportadas . Fornecemos mais de 1M de dados de treinamento e dados de avaliação de 60k . Nosso benchmark avalia o VLMS em duas tarefas: previsão de nomes de prato e previsão de localização de pratos. As configurações incluem prompt infundido sem contexto , contextualizado e infundido como a entrada do modelo.
Nosso conjunto de dados está disponível? Abraçando o conjunto de dados do rosto. Os dados KB de suporte podem ser encontrados? Abraçando o conjunto de dados do rosto.
Este é o código -fonte do artigo [arxiv]. Este código foi escrito usando Python. Se você usar qualquer código ou conjunto de dados deste kit de ferramentas em sua pesquisa, cite o artigo associado.
@article { winata2024worldcuisines ,
title = { WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines } ,
author = { Winata, Genta Indra and Hudi, Frederikus and Irawan, Patrick Amadeus and Anugraha, David and Putri, Rifki Afina and Wang, Yutong and Nohejl, Adam and Prathama, Ubaidillah Ariq and Ousidhoum, Nedjma and Amriani, Afifa and others } ,
journal = { arXiv preprint arXiv:2410.12705 } ,
year = { 2024 }
} Se você deseja obter o resultado final para todos os VLLMs que avaliamos, consulte esta tabela de classificação para obter o resumo. Os resultados brutos são colocados no diretório evaluation/score/json .
Execute o seguinte comando para instalar as bibliotecas necessárias para reproduzir os resultados de referência.
pip pip install -r requirements.txt
conda conda env create -f env.yml
Para Pangea, execute o seguinte
pip install -e "git+https://github.com/gentaiscool/LLaVA-NeXT@79ef45a6d8b89b92d7a8525f077c3a3a9894a87d#egg=llava[train]"
Todos os resultados do experimento serão armazenados na evaluation/result/ diretório. Os resultados são avaliados usando a precisão de todas as tarefas, especificamente para tarefas abertas (OEQ), usamos a precisão calculada usando multi-referência . Você pode executar cada experimento usando os seguintes comandos:
cd evaluation/
python run.py --model_path {model_path} --task {task} --type {type}
| Argumento | Descrição | Exemplo / padrão |
|---|---|---|
--task | Número da tarefa para avaliar (1 ou 2) | 1 (padrão), 2 |
--type | Tipo de pergunta a serem avaliados ( oe ou mc ) | mc (padrão), oe |
--model_path | Caminho para o modelo | Qwen/Qwen2-VL-72B-Instruct (PADRÃO) + outros |
--fp32 | Use float32 em vez de float16 / bfloat16 | False (padrão) |
--multi_gpu | Use várias GPUs | False (padrão) |
-n , --chunk_num | Número de pedaços para dividir os dados | 1 (padrão) |
-k , --chunk_id | ID do pedaço (baseado em 0) | 0 (padrão) |
-s , --st_idx | Iniciar o índice para fatiar dados (inclusive) | None (padrão) |
-e , --ed_idx | ÍNDICE FINAL PARA DADOS DE FLIAÇÃO (EXCLUSIVO) | None (padrão) |
Apoiamos os seguintes modelos (você pode modificar nosso código para executar a avaliação com outros modelos).
rhymes-ai/Ariameta-llama/Llama-3.2-11B-Vision-Instructmeta-llama/Llama-3.2-90B-Vision-Instructllava-hf/llava-v1.6-vicuna-7b-hfllava-hf/llava-v1.6-vicuna-13b-hfallenai/MolmoE-1B-0924allenai/Molmo-7B-D-0924allenai/Molmo-7B-O-0924microsoft/Phi-3.5-vision-instructQwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-InstructQwen/Qwen2-VL-72B-Instructmistralai/Pixtral-12B-2409neulab/Pangea-7B (Instale a llava, conforme mencionado em ⚡ Setup Ambients Setup) Editar evaluation/score/score.yml para determinar o modo de pontuação, conjunto de avaliação e avaliou VLMs. Observe que mc significa múltipla escolha e oe significa aberto.
mode : all # {all, mc, oe} all = mc + oe
oe_mode : multi # {single, dual, multi}
subset : large # {large, small}
models :
- llava-1.6-7b
- llava-1.6-13b
- qwen-vl-2b
- qwen2-vl-7b-instruct
- qwen2-vl-72b
- llama-3.2-11b
- llama-3.2-90b
- molmoe-1b
- molmo-7b-d
- molmo-7b-o
- aria-25B-moe-4B
- Phi-3.5-vision-instruct
- pixtral-12b
- nvlm
- pangea-7b
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gemini-1.5-flash Além do modo multi para gerar a pontuação oe , que compara a resposta às etiquetas douradas em todos os idiomas, também apoiamos outras configurações de referência de etiqueta de ouro:
single : compara a resposta apenas à etiqueta dourada no idioma original.dual : compara a resposta à etiqueta dourada no idioma e inglês original.Uma vez definido, execute este comando:
cd evaluation/score/
python score.py Fornecemos gráficos de radar, dispersão e linha de dispersão para visualizar resultados de pontuação para todos os VLMs em evaluation/score/plot/ .
Para gerar todo o gráfico de radar , use:
python evaluation/score/plot/visualization.py
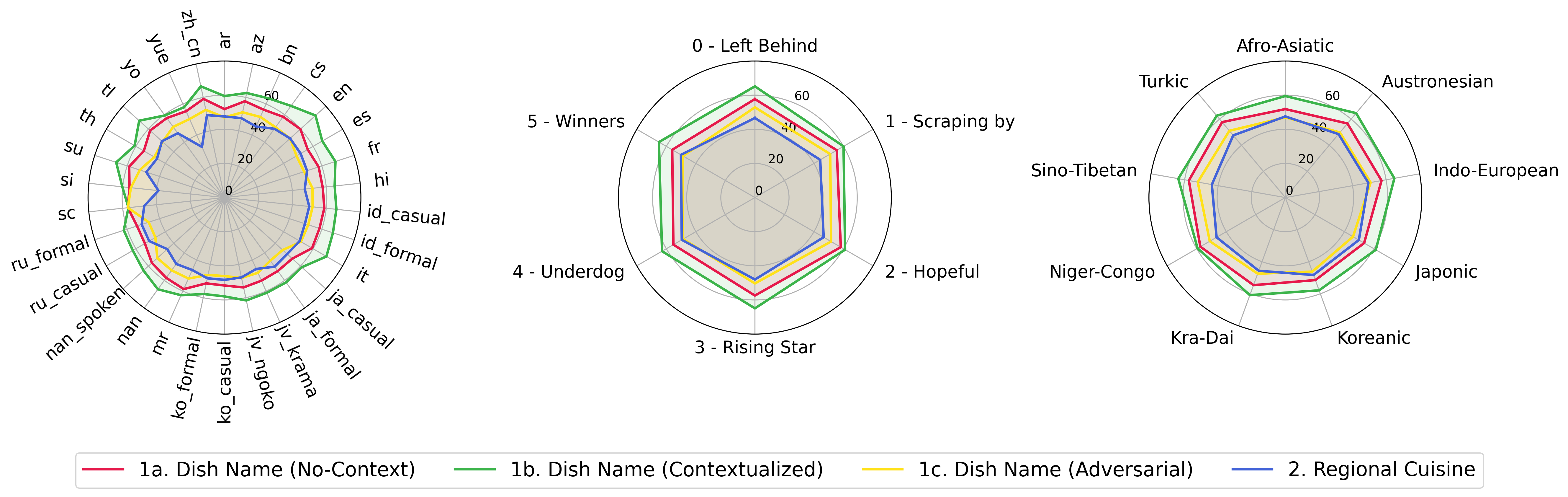
Você também pode modificar evaluation/score/score.yml para selecionar quais VLMs visualizar e ajustar os rótulos da plotagem em plot_mapper.yml .
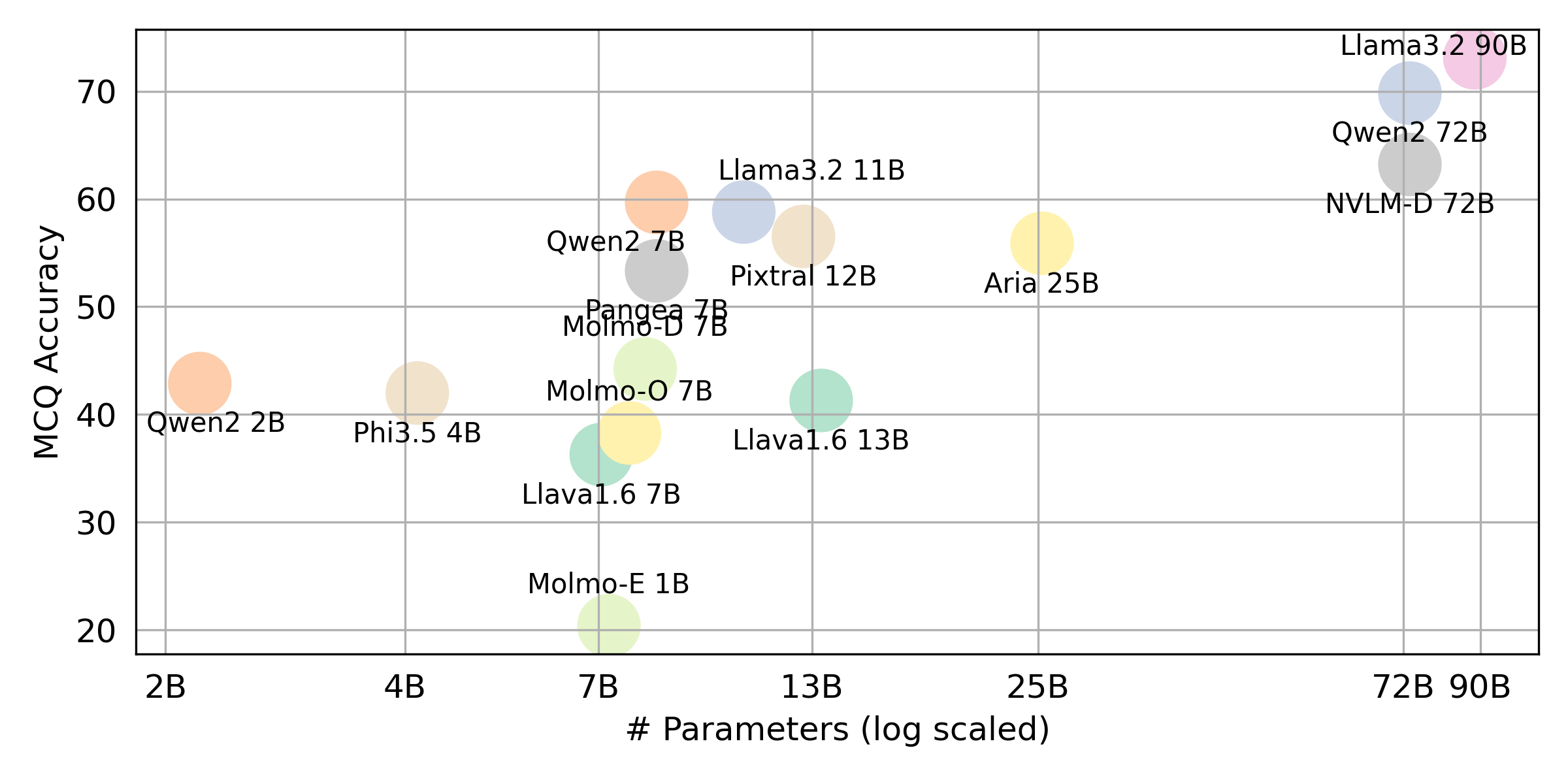
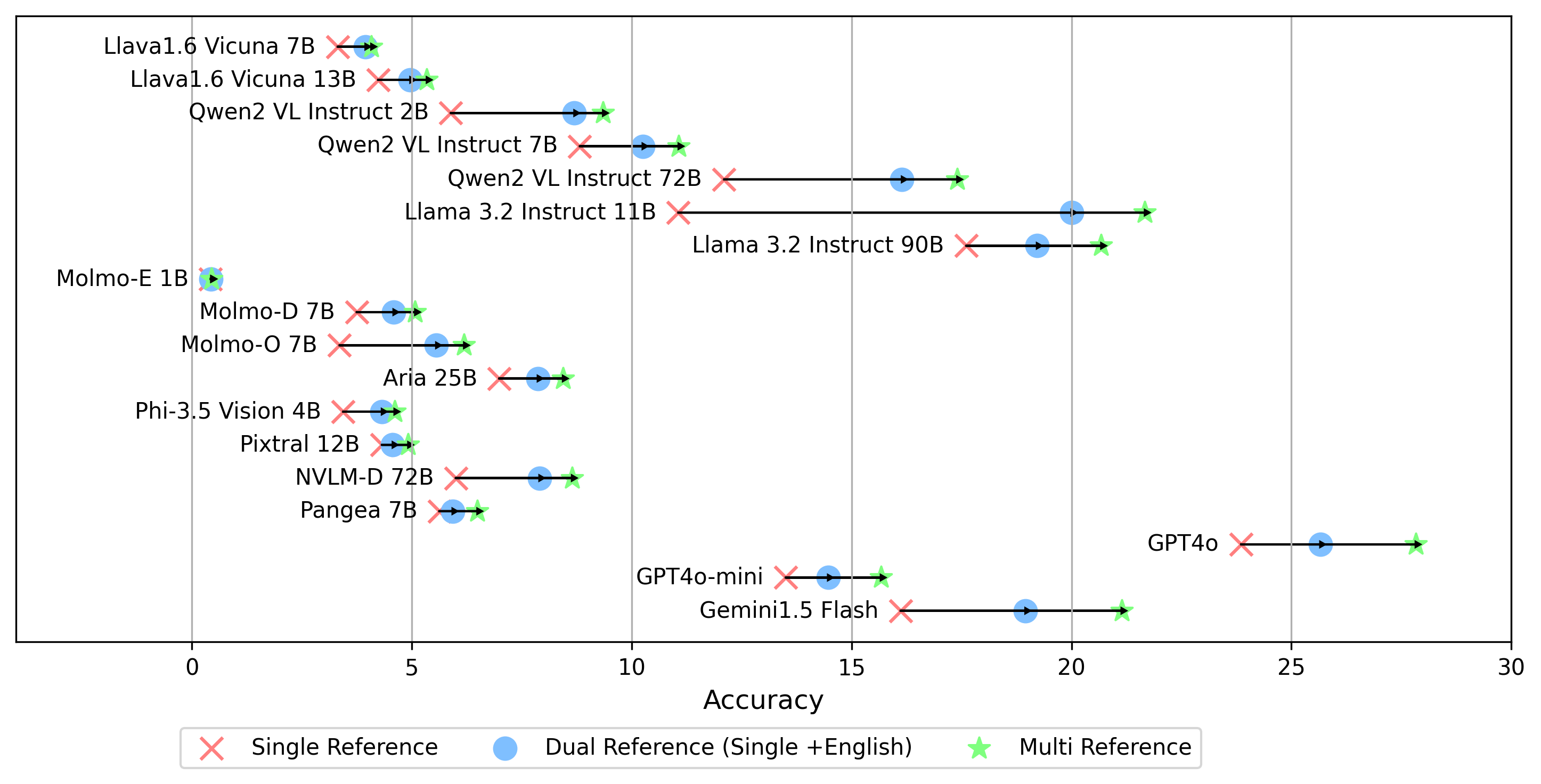
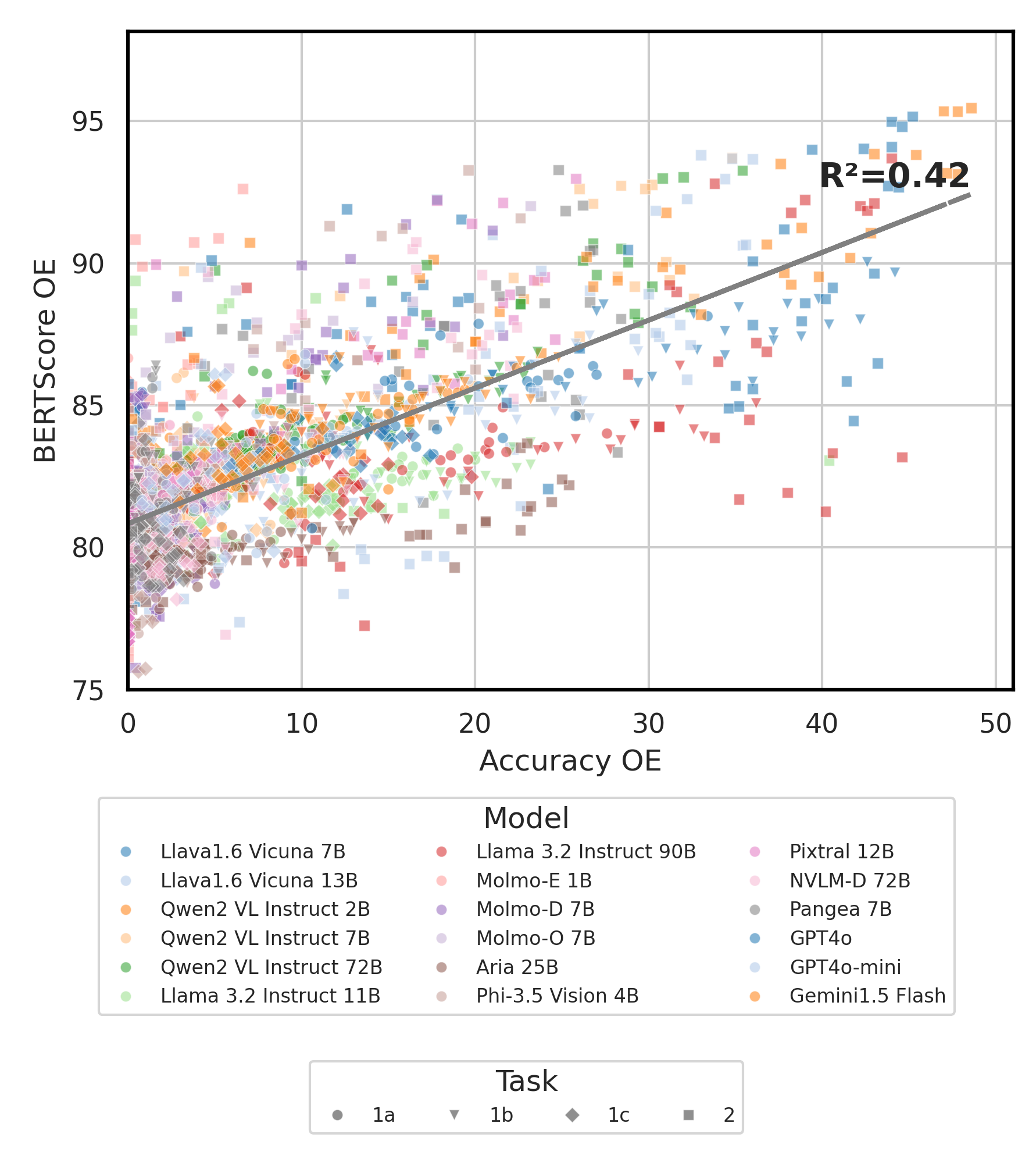
Outros scripts de geração de gráficos estão disponíveis nos arquivos *.ipynb no mesmo diretório.
Nossa base de código suporta o uso de vários modelos para os experimentos, fornecendo flexibilidade para a personalização da lista mostrada abaixo:
(Última testada em outubro de 2024)
Para gerar um conjunto de dados VQA a partir da base de conhecimento, você pode consultar o script generate_vqa/sampling.py . Este script gera o conjunto de dados para várias tarefas nos conjuntos de treinamento e teste.
Comandos de exemplo: Para gerar conjuntos de dados para testar pequenos , testar conjuntos grandes e de trens , execute os seguintes comandos:
cd generate_vqa
mkdir -p generated_data
# Test Small Task 1
python3 sampling.py -o " generated_data/test_small_task1.csv " -n 9000 -nd 100 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Small Task 2
python3 sampling.py -o " generated_data/test_small_task2.csv " -n 3000 -nd 100 -np1a 0 -np1b 1 -np1c 0 -npb 0 --is-eval
# Test Large Task 1
python3 sampling.py -o " generated_data/test_large_task1.csv " -n 45000 -nd 500 -np1a 1 -np1b 0 -np1c 1 -npb 1 --is-eval
# Test Large Task 2
python3 sampling.py -o " generated_data/test_large_task2.csv " -n 15000 -nd 500 -np1a 0 -np1b 1 -np1c 0 -npb 0 --i-eval
# Train Task 1
python3 sampling.py -o " generated_data/train_task1.csv " -n 810000 -nd 1800 -np1a 5 -np1b 0 -np1c 5 -npb 5 --no-is-eval
# Train Task 2
python3 sampling.py -o " generated_data/train_task2.csv " -n 270000 -nd 1800 -np1a 0 -np1b 5 -np1c 0 -npb 0 --no-is-eval| Argumento | Descrição | Exemplo |
|---|---|---|
-o , --output-csv | Caminho de saída CSV em que o conjunto de dados VQA gerado será salvo. | generated_data/test_small_task1.csv |
-n , --num-samples | Número máximo de instâncias a serem geradas. Se mais amostras forem solicitadas do que possível, o script será ajustado. | 9000 |
-nd , --n-dish-max | Número único máximo de pratos para provar. | 100 |
-np1a , --n-prompt-max-type1a | Prompts exclusivos máximos da Tarefa 1 (a) (sem contexto) para amostrar por prato em cada iteração. | 1 |
-np1b , --n-prompt-max-type1b | Prompts exclusivos máximos da Tarefa 1 (b) (contextualizada) para amostrar por prato em cada iteração. | 1 |
-np1c , --n-prompt-max-type1c | Prompts exclusivos máximos da Tarefa 1 (c) (adversário) para amostrar por prato em cada iteração. | 1 |
-np2 , --n-prompt-max-type2 | Prompts exclusivos máximos da Tarefa 2 para Amostra por Prato em cada iteração. | 1 |
--is-eval , --no-is-eval | Se deve gerar avaliação (teste) ou conjuntos de dados de treinamento. | --is-eval para teste, --no-is-eval para trem |
| Argumento | Descrição | Exemplo |
|---|---|---|
-fr , --food-raw-path | Caminho para os dados de alimentos crus CSV. | food_raw_6oct.csv |
-fc , --food-cleaned-path | Caminho para os dados alimentares limpos CSV. | food_cleaned.csv |
-q , --query-context-path | Caminho para o contexto de consulta CSV. | query_ctx.csv |
-l , --loc-cuis-path | Caminho para o local e a culinária CSV. | location_and_cuisine.csv |
-ll , --list-of-languages | Especifique os idiomas a serem usados como uma lista de strings. | '["en", "id_formal"]' |
-aw , --alias-aware | Ativar respostas adversárias com aliases paralelos em vez de substituir a louça sem tradução pelo inglês | --alias-aware do requisito de encontrar respostas que contenham tradução paralela em todos os idiomas, --no-alias-aware para relaxar os pratos paralelos requisitos de nome |
Sinta -se à vontade para criar um problema se tiver alguma dúvida. E, crie um PR para corrigir bugs ou adicionar melhorias.
Se você estiver interessado em criar uma extensão deste trabalho, sinta -se à vontade para nos alcançar!
Apoie nosso esforço de código aberto
Estamos melhorando o código, especialmente na parte de inferência para gerar evaluation/result e pontuar a unificação do código de visualização, para torná-lo mais amigável e personalizável.


