multitask_text_and_chemistry_t5
1.0.0
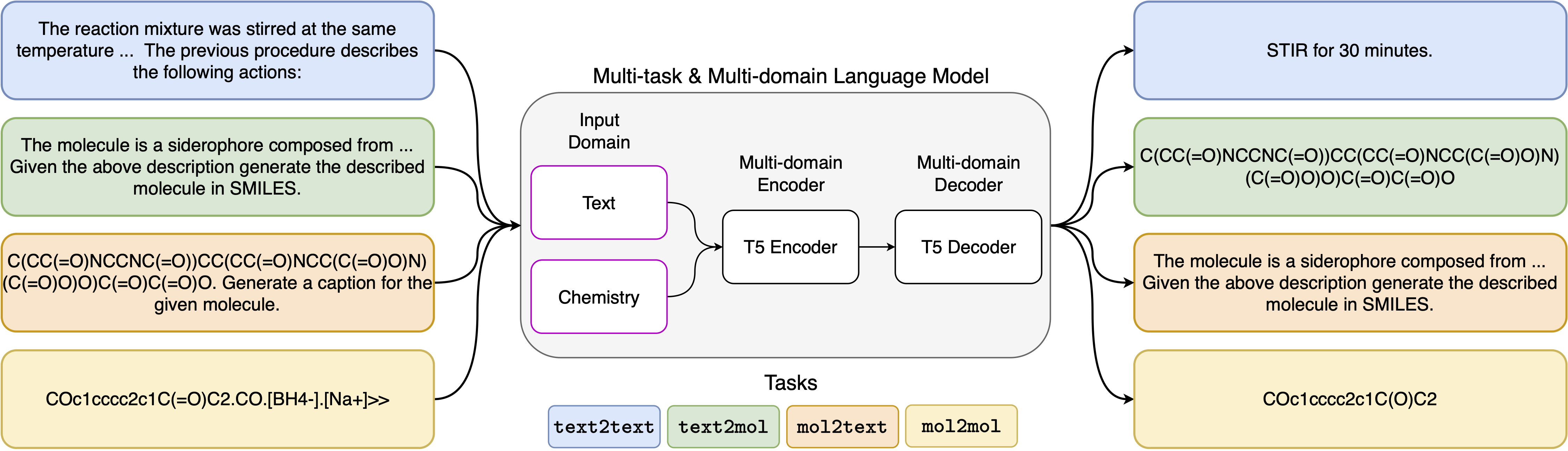
通過多任務語言建模統一分子和文本表示
Dimitrios Christofidellis*,Giorgio Giannone*,Jannis Born,Ole Winther,Teodoro Laino,Matteo Manica
國際機器學習會議(ICML),2023年
[Paper] [Gradio App] [代碼]
神經語言模型的最新進展也已成功應用於化學領域,為分子設計和合成計劃中的經典問題提供了生成解決方案。這些新方法有可能在科學發現中推動數據驅動自動化的新時代。但是,每個任務通常仍然需要專門的模型,從而導致需要特定問題的微調和忽略任務相互關係。該領域的主要障礙是自然語言和化學表現形式之間缺乏統一的代表,這使人相互作用變得複雜和限制。在這裡,我們提出了第一個多域,多任務語言模型,該模型可以解決化學和自然語言領域的各種任務。我們的模型可以同時處理化學和自然語言,而無需在單個領域或特定於任務的模型上進行昂貴的預培訓。有趣的是,當針對單域和跨域任務的最先進基準的基準測試時,跨領域的權重可以顯著改善我們的模型。特別是,跨域和任務共享信息會導致跨域任務的大大改進,其大小隨規模增加,這是由十幾個相關指標衡量的。我們的工作表明,這樣的模型可以通過取代特定問題的微調並增強人類模型相互作用來穩健有效地加速物理科學的發現。
安裝要求:
pip install -r requirements.txt創建一個專用的內核:
python -m ipykernel install --name text_chem_t5_demo很好
訓練過程是使用基於擁抱面孔變壓器(Wolf等,2020)和Pytorch Lightning(Falcon and the Pytorch Lightning Team,2019)的語言建模培訓師(Manica等人,2022年)進行的。要重現培訓,您需要首先安裝GT4SD庫。有關GT4SD庫的安裝過程的更多信息,您可以訪問其頁面。安裝GT4SD後,您可以使用以下命令來啟動我們的培訓。請注意, dataset-sample目錄中提供的數據集拆分僅包含我們實際數據集拆分的一小部分。為了再生我們的完整培訓數據集,我們將有興趣的讀者推薦給我們論文的各個部分以及那裡提供的參考文獻。
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
我們已用於5個不同任務的提示模板可以在下表中找到,其中<input>表示每個任務的實際輸入。
| 任務 | 模板 |
|---|---|
| 正向預測 | 預測以下反應的乘積:<輸入> |
| 反轉合 | 預測產生以下產品的反應:<輸入> |
| 段落到段落 | 在以下段落中描述了哪些動作:<input> |
| 描述至毫米 | 用微笑寫上述分子:<輸入> |
| 微笑到船上 | 字幕以下笑容:<輸入> |
我們的模型的四個變體可通過以下鏈接通過Huggignface Hub獲得:
在提供的筆記本(Demo.ipynb)中,我們介紹瞭如何將模型用於5個不同任務的示例。
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

