multitask_text_and_chemistry_t5
1.0.0
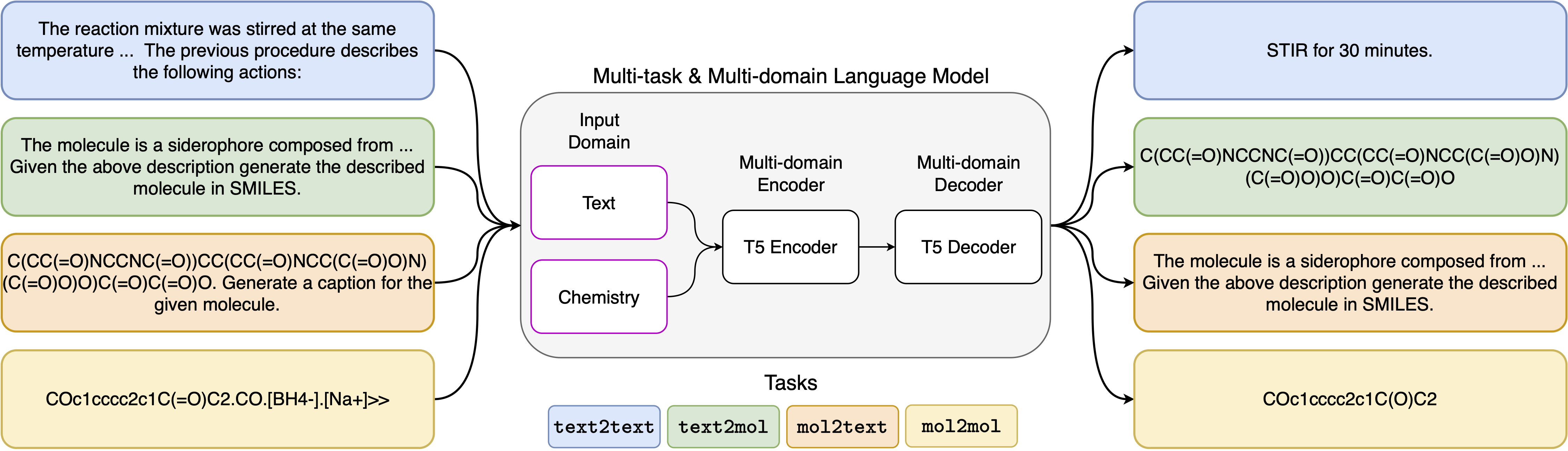
マルチタスク言語モデリングを介した分子およびテキスト表現の統一
Dimitrios Christofidellis*、Giorgio Giannone*、Jannis Born、Ole Winther、Teodoro Laino、Matteo Manica
機械学習に関する国際会議(ICML)、2023
[Paper] [Gradio App] [コード]
神経言語モデルの最近の進歩は、化学の分野にもうまく適用されており、分子設計と合成計画における古典的な問題のための生成ソリューションを提供しています。これらの新しい方法は、科学的発見におけるデータ駆動型の自動化の新しい時代を促進する可能性があります。ただし、通常、各タスクに特殊なモデルが必要であり、問題固有の微調整とタスクの相互関係を無視する必要性につながります。この分野の主な障害は、自然言語と化学的表現の間に統一された表現がないことであり、人間の相互作用を複雑にし、制限することです。ここでは、化学言語と自然言語の両方のドメインの両方で幅広いタスクを解決できる最初のマルチドメイン、マルチタスク言語モデルを提案します。私たちのモデルは、単一のドメインやタスク固有のモデルでの高価な事前トレーニングを必要とせずに、化学物質と自然言語を同時に処理できます。興味深いことに、ドメイン全体のウェイトを共有すると、単一ドメインおよびドメインクロスタスクの最先端のベースラインに対抗すると、モデルが著しく改善されます。特に、ドメインとタスク間で情報を共有すると、ドメインクロスドメインタスクの大幅な改善が生じます。私たちの研究は、そのようなモデルが、問題固有の微調整と人的モデルの相互作用を強化することにより、物理科学の発見を堅牢かつ効率的に加速できることを示唆しています。
要件をインストールする:
pip install -r requirements.txt専用のカーネルを作成します:
python -m ipykernel install --name text_chem_t5_demo行ってもいい
トレーニングプロセスは、GT4SDライブラリ(Manica et al。、2022)のフェイストランス(Wolf et al。、2020)とPytorch Lightning(Falcon and Pytorch Lightning Team、2019)に基づいて、言語モデリングトレーナーを使用して実行されます。トレーニングを再現するには、最初にGT4SDライブラリをインストールする必要があります。 GT4SDライブラリのインストールプロセスに関する詳細については、そのページにアクセスできます。 GT4SDがインストールされたら、次のコマンドを使用してトレーニングを開始できます。 dataset-sampleディレクトリの提供されたデータセットの分割には、実際のデータセットスプリットの小さなサブセットのみが含まれていることに注意してください。完全なトレーニングデータセットを再生するために、関心のある読者を、私たちの論文のそれぞれのセクションとそこに提供される参照を紹介します。
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
5つの異なるタスクに使用したプロンプトテンプレートは、次の表にあります。<inupt>は、各タスクの実際の入力を表します。
| タスク | テンプレート |
|---|---|
| フォワード予測 | 次の反応の積を予測します:<inupt> |
| レトロシンセシス | 次の製品を生成する反応を予測します:<inupt> |
| パラグラフからアクション | 次の段落で説明されているアクション:<inupt> |
| 説明 | 記載されている分子:<inupt>を笑顔で書きます |
| 笑顔からキャプション | キャプション次の笑顔:<inupt> |
モデルの4つのバリアントは、次のリンクでHuggignfaceハブから入手できます。
提供されたノートブック(demo.ipynb)では、5つの異なるタスクにモデルを使用する方法の例を示します。
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

