multitask_text_and_chemistry_t5
1.0.0
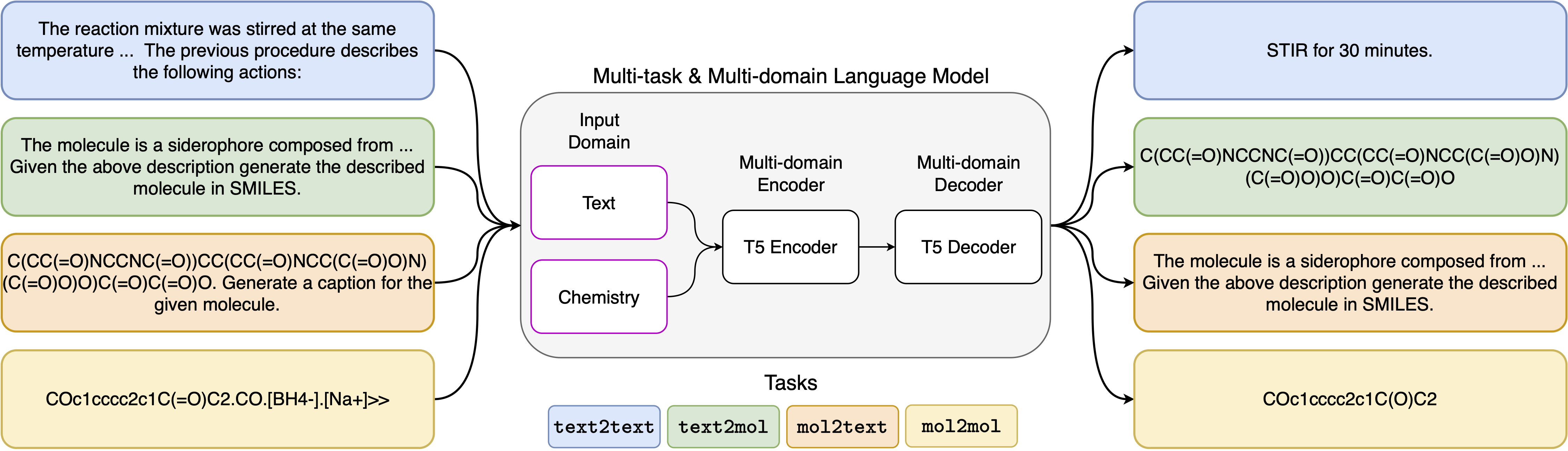
멀티 태스킹 언어 모델링을 통해 분자 및 텍스트 표현을 통합합니다
Dimitrios Christofidellis*, Giorgio Giannone*, Jannis Born, Ole Winther, Teodoro Laino, Matteo Manica
머신 러닝에 관한 국제 회의 (ICML), 2023
[종이] [Gradio 앱] [코드]
신경 언어 모델의 최근 발전은 화학 분야에 성공적으로 적용되어 분자 설계 및 합성 계획의 고전적인 문제에 대한 생성 솔루션을 제공했습니다. 이러한 새로운 방법은 과학적 발견에서 새로운 데이터 중심의 자동화 시대를 촉진 할 수있는 잠재력을 가지고 있습니다. 그러나 특수 모델은 일반적으로 각 작업에 여전히 필요하므로 문제 별 미세 조정 및 무시하는 작업 상호 관계가 필요합니다. 이 분야의 주요 장애물은 자연 언어와 화학적 표현 사이의 통일 된 표현이 부족하여 인간-기계 상호 작용을 복잡하게하고 제한한다는 것입니다. 여기서는 화학적 및 자연어 영역 모두에서 광범위한 작업을 해결할 수있는 최초의 멀티 도메인 멀티 태스킹 언어 모델을 제안합니다. 우리의 모델은 단일 도메인 또는 작업 별 모델에서 고가의 사전 훈련을 필요로하지 않고 동시에 화학 및 자연 언어를 동시에 처리 할 수 있습니다. 흥미롭게도, 도메인 간의 가중치를 공유하면 단일 도메인 및 크로스 도메인 작업에 대한 최첨단 기준선에 대해 벤치마킹 될 때 모델이 크게 향상됩니다. 특히, 도메인 및 작업에서 정보를 공유하면 교차 도메인 작업이 크게 개선되며, 수십 개 이상의 관련 메트릭으로 측정 된 규모에 따라 크기가 증가합니다. 우리의 연구는 이러한 모델이 문제 별 미세 조정을 대체하고 인간 모델 상호 작용을 향상시켜 물리 과학의 발견을 강력하고 효율적으로 가속화 할 수 있음을 시사합니다 .
요구 사항 설치 :
pip install -r requirements.txt전용 커널 생성 :
python -m ipykernel install --name text_chem_t5_demo가서 다행
교육 과정은 GT4SD 라이브러리 (Manica et al., 2022)의 포옹 페이스 트랜스포머 (Wolf et al., 2020) 및 Pytorch Lightning (Falcon and The Pytorch Lightning Team, 2019)을 기반으로 한 언어 모델링 트레이너를 사용하여 수행됩니다. 교육을 재현하려면 먼저 GT4SD 라이브러리를 설치해야합니다. GT4SD 라이브러리의 설치 프로세스에 대한 자세한 내용은 해당 페이지를 방문 할 수 있습니다. GT4SD가 설치되면 다음 명령을 사용하여 교육을 시작할 수 있습니다. dataset-sample 디렉토리의 제공된 데이터 세트 분할에는 실제 데이터 세트 분할의 작은 부분 집합이 포함되어 있습니다. 전체 교육 데이터 세트를 재생하기 위해 관심있는 독자를 논문의 각 섹션과 그곳에 제공 한 참조를 참조하십시오.
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
5 가지 다른 작업에 사용한 프롬프트 템플릿은 다음 표에서 찾을 수 있으며, 여기서 <input>는 각 작업의 실제 입력을 나타냅니다.
| 일 | 주형 |
|---|---|
| 전진 예측 | 다음 반응의 산물을 예측하십시오. <input> |
| 회고 합성 | 다음 제품을 생성하는 반응을 예측하십시오. <input> |
| 단락 간 요소 | 다음 단락에 설명되는 조치 : <input> |
| 설명 대 마시일 | 설명 된 분자 : <입력>을 미소로 작성하십시오 |
| 미소-마감 | 캡션 다음 미소 : <입력> |
우리 모델의 4 가지 변형은 다음 링크에서 Huggignface 허브를 통해 사용할 수 있습니다.
제공된 노트 (demo.ipynb)에서는 모델이 5 가지 다른 작업에 어떻게 사용되는지에 대한 예를 제시합니다.
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

