multitask_text_and_chemistry_t5
1.0.0
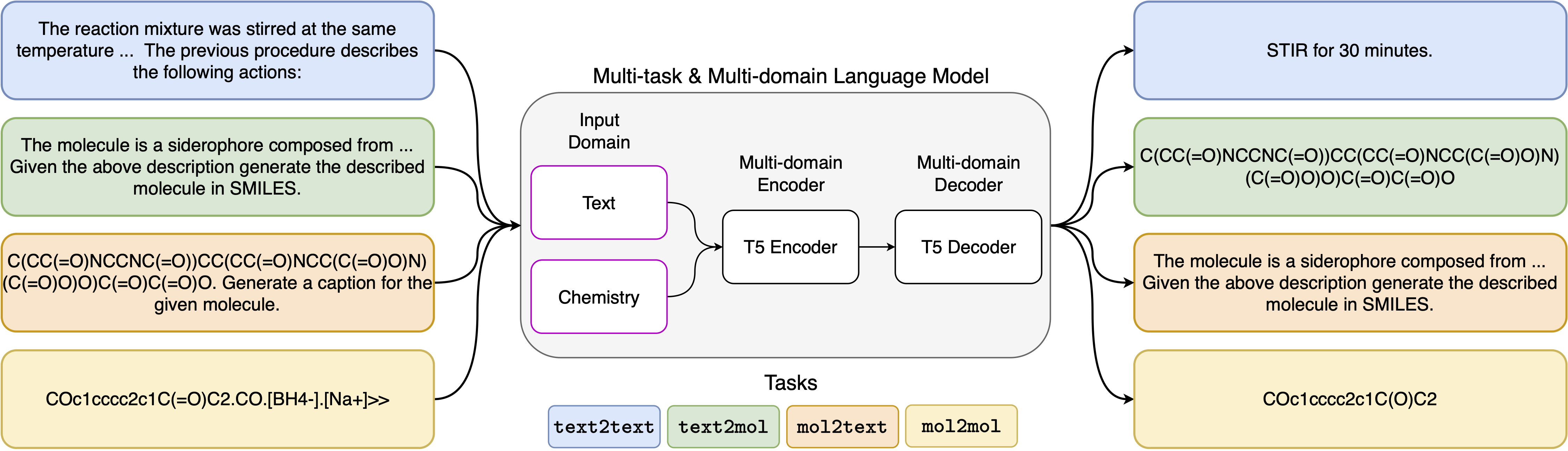
Menyatukan representasi molekuler dan tekstual melalui pemodelan bahasa multi-tugas
Dimitrios Christofidellis*, Giorgio Giannone*, Jannis Born, Ole Winther, Teodoro Laino, Matteo Manica
Konferensi Internasional tentang Pembelajaran Mesin (ICML), 2023
[kertas] [Aplikasi Gradio] [Kode]
Kemajuan terbaru dalam model bahasa saraf juga telah berhasil diterapkan pada bidang kimia, menawarkan solusi generatif untuk masalah klasik dalam desain molekuler dan perencanaan sintesis. Metode-metode baru ini memiliki potensi untuk memicu era baru otomatisasi berbasis data dalam penemuan ilmiah. Namun, model khusus biasanya masih diperlukan untuk setiap tugas, yang mengarah pada kebutuhan untuk menyempurnakan masalah-spesifik dan mengabaikan keterkaitan tugas. Hambatan utama dalam bidang ini adalah kurangnya representasi terpadu antara bahasa alami dan representasi kimia, memperumit dan membatasi interaksi mesin manusia. Di sini, kami mengusulkan model bahasa multi-domain, multi-tugas pertama yang dapat menyelesaikan berbagai tugas di domain bahasa kimia dan bahasa alami. Model kami dapat menangani bahasa kimia dan alami secara bersamaan, tanpa memerlukan pra-pelatihan yang mahal pada domain tunggal atau model khusus tugas. Menariknya, berbagi bobot di seluruh domain sangat meningkatkan model kami ketika membandingkan terhadap baseline canggih pada tugas domain tunggal dan domain silang. Secara khusus, berbagi informasi di seluruh domain dan tugas menimbulkan peningkatan besar dalam tugas lintas domain, besarnya meningkat dengan skala, yang diukur dengan lebih dari selusin metrik yang relevan. Pekerjaan kami menunjukkan bahwa model semacam itu dapat mempercepat penemuan dalam ilmu fisik dengan menggantikan fine-tuning spesifik masalah dan meningkatkan interaksi model manusia .
Instal Persyaratan:
pip install -r requirements.txtBuat kernel khusus:
python -m ipykernel install --name text_chem_t5_demoBagus untuk pergi
Proses pelatihan dilakukan dengan menggunakan pelatih pemodelan bahasa berdasarkan memeluk transformator wajah (Wolf et al., 2020) dan Pytorch Lightning (Falcon dan Pytorch Lightning Team, 2019) dari Perpustakaan GT4SD (Manica et al., 2022). Untuk mereproduksi pelatihan, Anda perlu pertama kali menginstal perpustakaan GT4SD. Untuk informasi lebih lanjut mengenai proses instalasi perpustakaan GT4SD, Anda dapat mengunjungi halamannya. Setelah GT4SD diinstal, Anda dapat menggunakan perintah berikut untuk meluncurkan pelatihan kami. Perhatikan bahwa dataset yang disediakan membagi dalam direktori dataset-sample hanya berisi sebagian kecil dari perpecahan dataset kami yang sebenarnya. Untuk meregenerasi dataset pelatihan penuh kami, kami merujuk pembaca yang tertarik ke bagian masing -masing dari makalah kami dan referensi yang disediakan di sana.
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
Template prompt yang telah kami gunakan untuk 5 tugas yang berbeda dapat ditemukan di tabel berikut, di mana <sput> mewakili input aktual untuk setiap tugas.
| Tugas | Templat |
|---|---|
| Prediksi ke depan | Memprediksi produk dari reaksi berikut: <sput> |
| Retrosintesis | Memprediksi reaksi yang menghasilkan produk berikut: <sput> |
| Paragraf-ke-aksi | Tindakan mana yang dijelaskan dalam paragraf berikut: <sput> |
| Deskripsi-ke-Smiles | Tulis dengan senyum molekul yang dijelaskan: <sput> |
| Smiles-to-caption | Keterangan senyum berikut: <Tinput> |
Empat varian model kami tersedia melalui hub HugGignface di tautan berikut:
Dalam notebook yang disediakan (demo.ipynb), kami menyajikan contoh bagaimana model dapat digunakan untuk 5 tugas yang berbeda.
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

