multitask_text_and_chemistry_t5
1.0.0
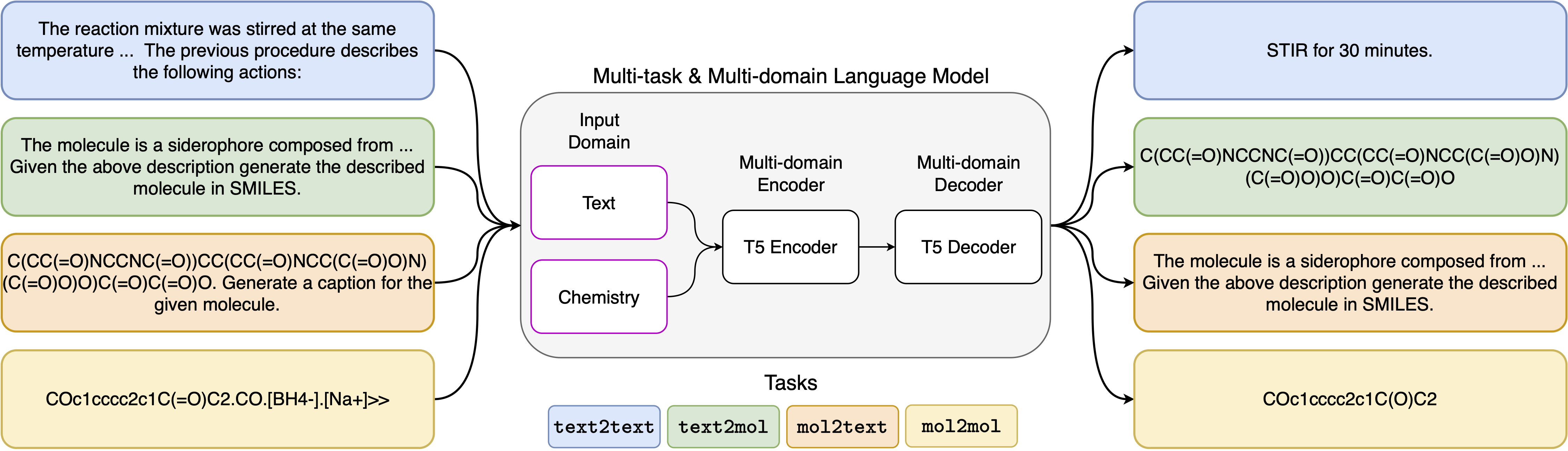
Объединение молекулярных и текстовых представлений с помощью многозадачного языкового моделирования
Dimitrios Christofidellis*, Giorgio Jiannone*, Jannis Born, Ole Winther, Teodoro Laino, Matteo Manica
Международная конференция по машинному обучению (ICML), 2023
[Paper] [gradio app] [code]
Недавние достижения в моделях нейронного языка также были успешно применены в области химии, предлагая генеративные решения для классических проблем в молекулярном дизайне и планировании синтеза. Эти новые методы могут создать новую эру автоматизации, управляемой данными, в научном обнаружении. Тем не менее, специализированные модели все еще обычно требуются для каждой задачи, что приводит к необходимости точной настройки конкретной проблемы и пренебрежениям взаимосвязи задач. Основным препятствием в этой области является отсутствие единого представления между естественным языком и химическими представлениями, усложняя и ограничивая взаимодействие человека с имин. Здесь мы предлагаем первую многодоменную, многозадачную языковую модель, которая может решить широкий спектр задач как в областях химического, так и в области естественного языка. Наша модель может одновременно обрабатывать химический и естественный язык, не требуя дорогостоящего предварительного обучения на отдельных доменах или моделях, специфичных для задач. Интересно, что распределение весов между доменами удивительно улучшает нашу модель, когда она сравнивается с самыми современными базовыми показателями по однодоменным и междоменным задачам. В частности, совместное использование информации по доменам и задачам приводит к значительному улучшению в междоменных задачах, величина которого увеличивается с масштабами, измеряемые более чем дюжиной соответствующих показателей. Наша работа предполагает, что такие модели могут надежно и эффективно ускорить обнаружение в физических науках, заменяя специфическую настройку проблемы и улучшая взаимодействие человека-модели .
Установить требования:
pip install -r requirements.txtСоздайте выделенное ядро:
python -m ipykernel install --name text_chem_t5_demoХорошо идти
Процесс обучения проводится с использованием тренера по моделированию языка, основанного на обнимающих трансформаторах лица (Wolf et al., 2020) и Pytorch Lightning (Falcon и The Pytorch Lightning Team, 2019) из библиотеки GT4SD (Manica et al., 2022). Чтобы воспроизвести обучение, вам нужно сначала установить библиотеку GT4SD. Для получения дополнительной информации о процессе установки библиотеки GT4SD вы можете посетить его страницу. После установки GT4SD вы можете использовать следующую команду для запуска нашего обучения. Обратите внимание, что предоставленный набор данных в каталоге dataset-sample содержит лишь небольшую подмножество наших фактических сплит для набора данных. Чтобы восстановить наш полный набор данных обучения, мы передаем заинтересованного читателя в соответствующий раздел нашей статьи и ссылки, которые там предоставляются.
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
Шаблоны приглашения, которые мы использовали для 5 различных задач, можно найти в следующей таблице, где <Input> представляет фактический вход для каждой задачи.
| Задача | Шаблон |
|---|---|
| Вперед прогноз | Прогнозируйте продукт следующей реакции: <Input> |
| Ретросинтез | Прогнозируйте реакцию, которая производит следующий продукт: <Input> |
| Параграф-действий | Какие действия описаны в следующем параграфе: <Input> |
| Описание-с мили | Напишите в улыбках описанная молекула: <вход> |
| Улыбки к Каплению | Подпись Следующие улыбки: <Input> |
Четыре варианта нашей модели доступны через Hugignface Hub в следующих ссылках:
В предоставленной записной книжке (demo.ipynb) мы представляем примеры того, как модель можно использовать для 5 различных задач.
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

