multitask_text_and_chemistry_t5
1.0.0
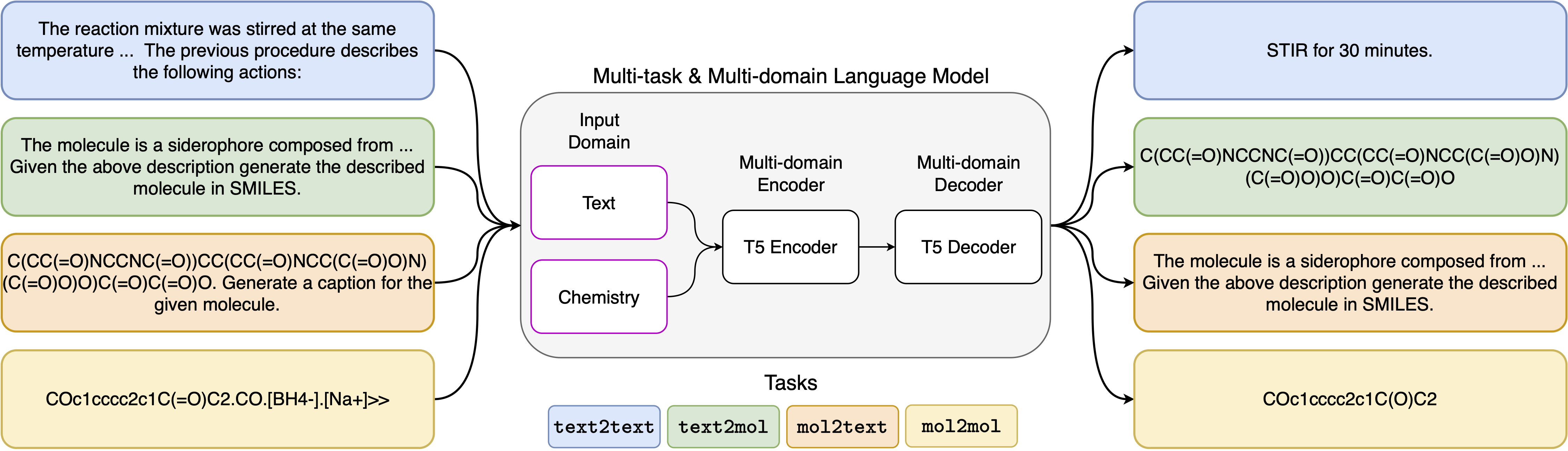
通过多任务语言建模统一分子和文本表示
Dimitrios Christofidellis*,Giorgio Giannone*,Jannis Born,Ole Winther,Teodoro Laino,Matteo Manica
国际机器学习会议(ICML),2023年
[Paper] [Gradio App] [代码]
神经语言模型的最新进展也已成功应用于化学领域,为分子设计和合成计划中的经典问题提供了生成解决方案。这些新方法有可能在科学发现中推动数据驱动自动化的新时代。但是,每个任务通常仍然需要专门的模型,从而导致需要特定问题的微调和忽略任务相互关系。该领域的主要障碍是自然语言和化学表现形式之间缺乏统一的代表,这使人相互作用变得复杂和限制。在这里,我们提出了第一个多域,多任务语言模型,该模型可以解决化学和自然语言领域的各种任务。我们的模型可以同时处理化学和自然语言,而无需在单个领域或特定于任务的模型上进行昂贵的预培训。有趣的是,当针对单域和跨域任务的最先进基准的基准测试时,跨领域的权重可以显着改善我们的模型。特别是,跨域和任务共享信息会导致跨域任务的大大改进,其大小随规模增加,这是由十几个相关指标衡量的。我们的工作表明,这样的模型可以通过取代特定问题的微调并增强人类模型相互作用来稳健有效地加速物理科学的发现。
安装要求:
pip install -r requirements.txt创建一个专用的内核:
python -m ipykernel install --name text_chem_t5_demo很好
训练过程是使用基于拥抱面孔变压器(Wolf等,2020)和Pytorch Lightning(Falcon and the Pytorch Lightning Team,2019)的语言建模培训师(Manica等人,2022年)进行的。要重现培训,您需要首先安装GT4SD库。有关GT4SD库的安装过程的更多信息,您可以访问其页面。安装GT4SD后,您可以使用以下命令来启动我们的培训。请注意, dataset-sample目录中提供的数据集拆分仅包含我们实际数据集拆分的一小部分。为了再生我们的完整培训数据集,我们将有兴趣的读者推荐给我们论文的各个部分以及那里提供的参考文献。
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
我们已用于5个不同任务的提示模板可以在下表中找到,其中<input>表示每个任务的实际输入。
| 任务 | 模板 |
|---|---|
| 正向预测 | 预测以下反应的乘积:<输入> |
| 反转合 | 预测产生以下产品的反应:<输入> |
| 段落到段落 | 在以下段落中描述了哪些动作:<input> |
| 描述至毫米 | 用微笑写上述分子:<输入> |
| 微笑到船上 | 字幕以下笑容:<输入> |
我们的模型的四个变体可通过以下链接通过Huggignface Hub获得:
在提供的笔记本(Demo.ipynb)中,我们介绍了如何将模型用于5个不同任务的示例。
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

