multitask_text_and_chemistry_t5
1.0.0
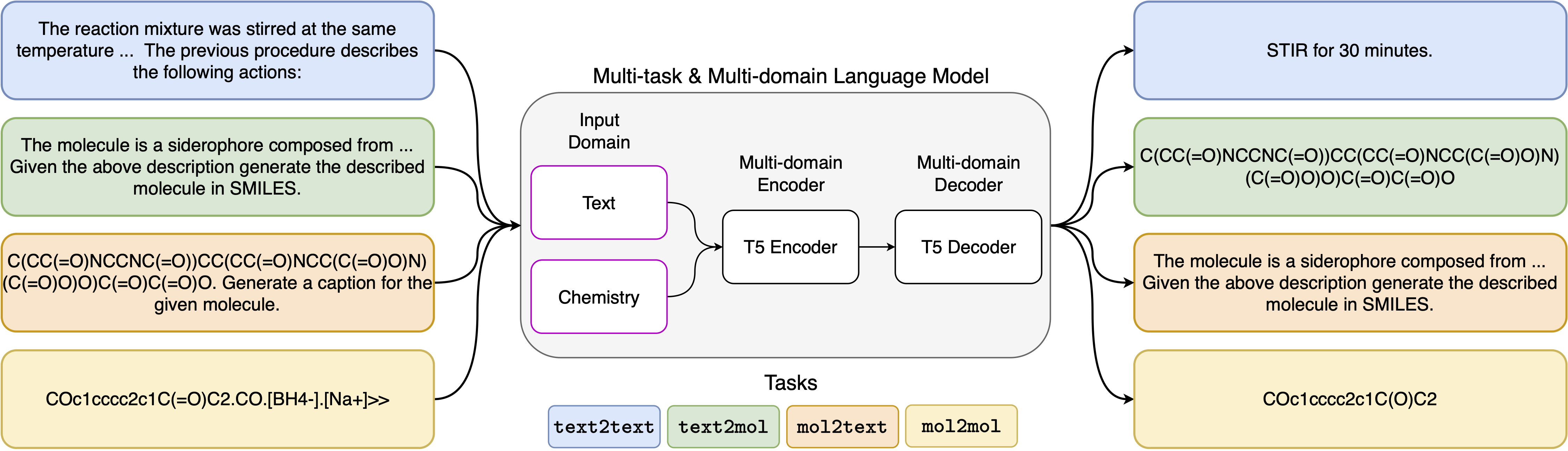
Vereinheitliche molekulare und textuelle Darstellungen über Multi-Task-Sprachmodellierung
Dimitrios Christofidellis*, Giorgio Giannone*, Jannis Born, Ole Winther, Teodoro Laino, Matteo Manica
Internationale Konferenz über maschinelles Lernen (ICML), 2023
[Papier] [Gradio App] [Code]
Die jüngsten Fortschritte in den Modellen mit neuronalen Sprachmodellen wurden auch erfolgreich auf den Bereich der Chemie angewendet und bieten generative Lösungen für klassische Probleme in der molekularen Design und der Syntheseplanung. Diese neuen Methoden haben das Potenzial, eine neue Ära der datengesteuerten Automatisierung in der wissenschaftlichen Entdeckung zu befeuern. Für jede Aufgabe sind jedoch noch spezielle Modelle erforderlich, was dazu führt, dass problemspezifische Feinabstimmungen und Vernachlässigen von Aufgabenabwicklungen erforderlich sind. Das Haupthindernis in diesem Bereich ist das Fehlen einer einheitlichen Darstellung zwischen natürlicher Sprache und chemischen Darstellungen, die die Wechselwirkung zwischen Menschenmaschine komplizieren und begrenzt. Hier schlagen wir das erste Multi-Domänen-Multitasking-Sprachmodell vor, das eine Vielzahl von Aufgaben sowohl im chemischen als auch im natürlichen Sprachbereich lösen kann. Unser Modell kann gleichzeitig mit chemischer und natürlicher Sprache umgehen, ohne dass ein teures Vorbild für einzelne Domänen oder aufgabenspezifische Modelle erforderlich ist. Interessanterweise verbessert das Teilen von Gewichten über Domänen unser Modell bemerkenswerterweise, wenn sie gegen hochmoderne Baselines bei Ein-Domänen- und Cross-Domänen-Aufgaben bewertet werden. Insbesondere das Austausch von Informationen über Bereiche und Aufgaben hinweg führt zu großen Verbesserungen der Cross-Domänen-Aufgaben, deren Größe mit einer Skalierung zunimmt, gemessen an mehr als einem Dutzend relevanter Metriken. Unsere Arbeit legt nahe, dass solche Modelle die Entdeckung in den physischen Wissenschaften robust und effizient beschleunigen können, indem sie problemspezifische Feinabstimmungen ersetzt und die Wechselwirkungen zwischen Menschenmodell verbessert .
Anforderungen installieren:
pip install -r requirements.txtErstellen Sie einen dedizierten Kernel:
python -m ipykernel install --name text_chem_t5_demoGut zu gehen
Der Trainingsprozess wird unter Verwendung des Sprachmodellentrainers durchgeführt, der auf umarmenden Gesichtstransformatoren (Wolf et al., 2020) und Pytorch Lightning (Falcon und dem Pytorch Lightning Team, 2019) aus der GT4SD -Bibliothek (Manica et al., 2022) basiert. Um das Training zu reproduzieren, müssen Sie zunächst die GT4SD -Bibliothek installieren. Weitere Informationen zum Installationsprozess der GT4SD -Bibliothek können die Seite besuchen. Sobald GT4SD installiert ist, können Sie den folgenden Befehl verwenden, um unser Training zu starten. Beachten Sie, dass die bereitgestellten Datensatzaufteilung im Verzeichnis der dataset-sample nur eine kleine Teilmenge unserer tatsächlichen Datensatzaufteilungen enthalten. Um unseren vollständigen Schulungsdatensatz zu regenerieren, verweisen wir den interessierten Leser auf den jeweiligen Abschnitt unseres Papiers und die dort bereitgestellten Referenzen.
gt4sd-trainer --training_pipeline_name language-modeling-trainer
--model_name_or_path t5-base
--lr 6e-4
--lr_decay 0.99
--batch_size 8
--train_file dataset-sample/train.jsonl
--validation_file dataset-sample/valid.jsonl
--default_root_dir text_chem_t5_base
--type cgm
--val_check_interval 20000
--max_epochs 1
--limit_val_batches 500
--accumulate_grad_batches 4
--log_every_n_steps 5000
--monitor val_loss
--save_top_k 1
--mode min
--every_n_train_steps 20000
--accelerator 'ddp'
Die Eingabeaufforderungsvorlagen, die wir für die 5 verschiedenen Aufgaben verwendet haben, finden Sie in der folgenden Tabelle, in der <eingabe> die tatsächliche Eingabe für jede Aufgabe darstellt.
| Aufgabe | Vorlage |
|---|---|
| Vorhersage | Vorhersage das Produkt der folgenden Reaktion: <eingabe> |
| Retrosynthese | Prognose die Reaktion, die das folgende Produkt erzeugt: <eingabe> |
| Absatz-zu-Optionen | Welche Aktionen sind in den folgenden Absätzen beschrieben: <eingabe> |
| Beschreibung zu Smiles | Schreiben Sie in Lächeln das beschriebene Molekül: <eingabe> |
| Lächeln zu Kapion | Bildunterschrift Das folgende Lächeln: <eingabe> |
Die vier Varianten unseres Modells sind in den folgenden Links über den Huggignface -Hub erhältlich:
Im bereitgestellten Notebook (Demo.IPynb) präsentieren wir Beispiele dafür, wie das Modell für die 5 verschiedenen Aufgaben verwendet werden kann.
@inproceedings { christofidellis2023unifying ,
title = { Unifying Molecular and Textual Representations via Multi-task Language Modelling } ,
author = { Christofidellis, Dimitrios and Giannone, Giorgio and Born, Jannis and Winther, Ole and Laino, Teodoro and Manica, Matteo } ,
booktitle = { Proceedings of the 40th International Conference on Machine Learning } ,
pages = { 6140--6157 } ,
year = { 2023 } ,
volume = { 202 } ,
series = { Proceedings of Machine Learning Research } ,
publisher = { PMLR } ,
pdf = { https://proceedings.mlr.press/v202/christofidellis23a/christofidellis23a.pdf } ,
url = { https://proceedings.mlr.press/v202/christofidellis23a.html } ,
}

