VGLM
1.0.0


這是本文的實施:
通過參數效率轉移學習探索多功能生成語言模型。 Zhaojiang Lin , Andrea Madotto , EMNLP 2020的Pascale Fung發現[PDF]
如果您使用此工具包中包含的任何源代碼或數據集,請引用以下論文。 Bibtex在下面列出:
@Article {lin2020 exploring,
title = {通過參數效率轉移學習探索多功能生成語言模型},
作者= {lin,Zhaojiang和Madotto,Andrea and Fung,Pascale},
journal = {arxiv preprint arxiv:2004.03829},,
年= {2020}
}
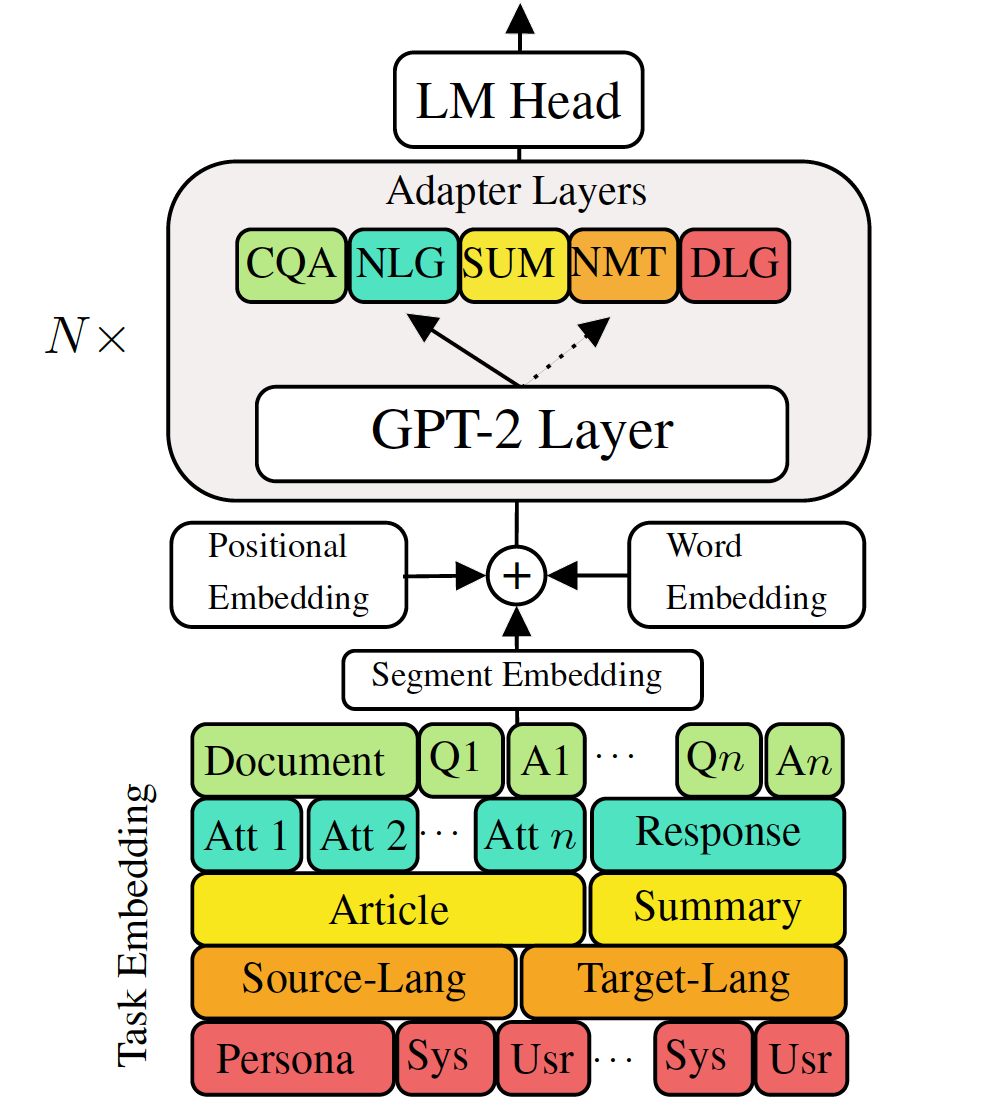
對下游語言生成任務進行微調預訓練的生成語言模型已顯示出令人鼓舞的結果。但是,它具有為每個任務擁有一個單一的大型模型的成本,這在低內存/功率方案(例如移動設備)中並不理想。在這項工作中,我們提出了一種使用單個大型預訓練模型同時微調多個下游生成任務的有效方法。五種不同語言生成任務的實驗表明,通過為每個任務使用額外的2-3%參數,我們的模型可以維護甚至可以提高整個模型的微調性能。
檢查所需的軟件包或簡單地運行命令
❱❱❱ pip install -r requirements.txt 數據集
下載預處理數據集
可重複性
我們提供VLM的訓練有素的檢查站。
測試模型:從(MT,Summarization,對話,QA,NLG)中選擇一個任務。
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path微調GPT-2
火車機翻譯:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json測試機譯:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpoint檢查run.sh以運行其他任務
VLM火車適配器和任務嵌入
沒有知識蒸餾的訓練機譯
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005使用句子級別知識蒸餾的火車計算機翻譯:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillation測試機traslation:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpoint檢查run.sh以運行其他任務
將所有適配器和任務嵌入到單個模型中
combine_all.py的第68行以提供檢查點的列表
❱❱❱ python combine_all.py測試以查看結果是否相同
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path上面的腳本說明了在任務依次到達時如何連續訓練VLM。
多任務培訓VLM
同時可用的所有任務。
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 該存儲庫是在HuggingFace上實現的


