VGLM
1.0.0


Ceci est la mise en œuvre du document:
Exploration du modèle de langage génératif polyvalent via un apprentissage transfert par les paramètres . Zhaojiang Lin , Andrea Madotto , Pascale Fung Résultats de l'EMNLP 2020 [PDF]
Si vous utilisez des codes source ou des ensembles de données inclus dans cette boîte à outils dans votre travail, veuillez citer l'article suivant. Le bibtex est répertorié ci-dessous:
@Article {lin2020explorat,
title = {Exploration du modèle de langage génératif polyvalent via l'apprentissage transféré par les paramètres},
auteur = {Lin, Zhaojiang et Madotto, Andrea et Fung, Pascale},
journal = {arXiv Preprint Arxiv: 2004.03829},
année = {2020}
}
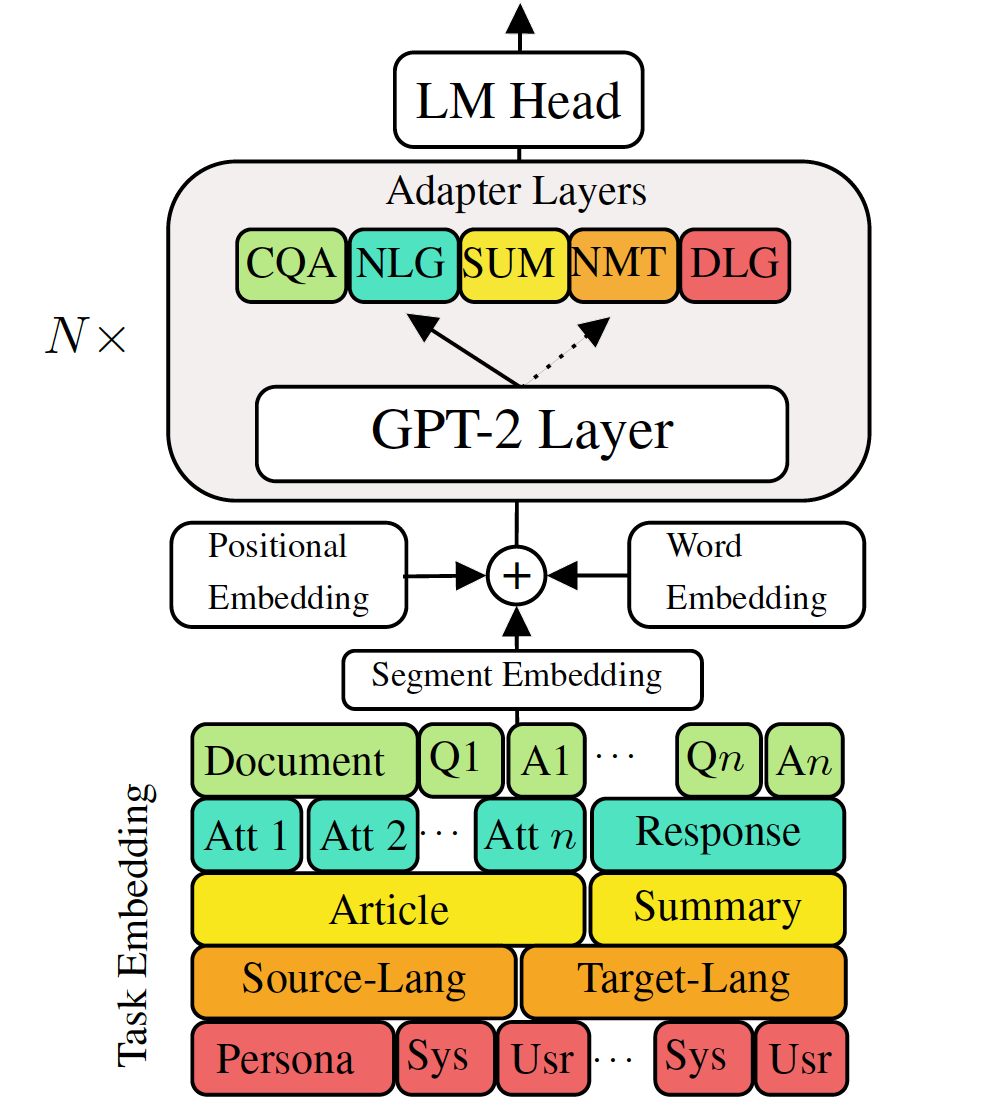
Les modèles de langage génératif pré-formé à réglage fin aux tâches de génération de langage en baisse ont montré des résultats prometteurs. Cependant, il est livré avec le coût d'avoir un modèle unique, grand pour chaque tâche, ce qui n'est pas idéal dans les scénarios basse mémoire / puissance (par exemple, mobile). Dans ce travail, nous proposons un moyen efficace de régler simultanément les tâches de génération en basse du flux en utilisant un seul modèle pré-formé. Les expériences de cinq tâches de génération de langues diverses montrent qu'en utilisant simplement des paramètres supplémentaires de 2 à 3% pour chaque tâche, notre modèle peut maintenir ou même améliorer les performances de l'ensemble du modèle entier.
Vérifiez les packages nécessaires ou exécutez simplement la commande
❱❱❱ pip install -r requirements.txt Ensemble de données
Télécharger les ensembles de données prétraités
Reproductibilité
Nous fournissons le point de contrôle qualifié de notre VLM.
Modèle de test: choisissez une tâche parmi (MT, résumé, dialogue, QA, NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathFine méloger gpt-2
Translation machine du train:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonTessage de la traduction de la machine:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointVérifiez Run.sh pour exécuter d'autres tâches
Adaptateurs de train VLM et incorporations de tâches
Traduction de machine à la formation sans distillation
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005Traduction machine du train utilisant la distillation des connaissances au niveau de la phrase:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationTraslation de la machine de test:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointVérifiez Run.sh pour exécuter d'autres tâches
Combinez tous les adaptateurs et l'intégration des tâches dans un modèle unique
Ligne 68 de Combine_all.py pour fournir la liste du point de contrôle
❱❱❱ python combine_all.pyTester pour voir si le résultat est le même
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathLes scripts ci-dessus illustrent comment entraîner le VLM en continu lorsque les tâches arrivent séquentiellement.
VLM de formation multitâche
Lorsque toutes les tâches disponibles en même temps.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 Ce référentiel est implémenté à base sur HuggingFace


