VGLM
1.0.0


هذا هو تنفيذ الورقة:
استكشاف نموذج اللغة التنظيمية متعددة الاستخدامات عبر التعلم النقل الفعال للمعلمة . Zhaojiang Lin ، Andrea Madotto ، Pascale Fung نتائج EMNLP 2020 [PDF]
إذا كنت تستخدم أي رموز مصدر أو مجموعات بيانات مدرجة في مجموعة الأدوات هذه في عملك ، فيرجى الاستشهاد بالورقة التالية. bibtex مدرج أدناه:
article {lin202020exploring ،
العنوان = {استكشاف نموذج لغة توليدي متعددة الاستخدامات عبر التعلم الناقل الفعال للمعلمة} ،
المؤلف = {Lin ، Zhaojiang و Madotto ، Andrea and Fung ، Pascale} ،
Journal = {arxiv preprint arxiv: 2004.03829} ،
السنة = {2020}
}
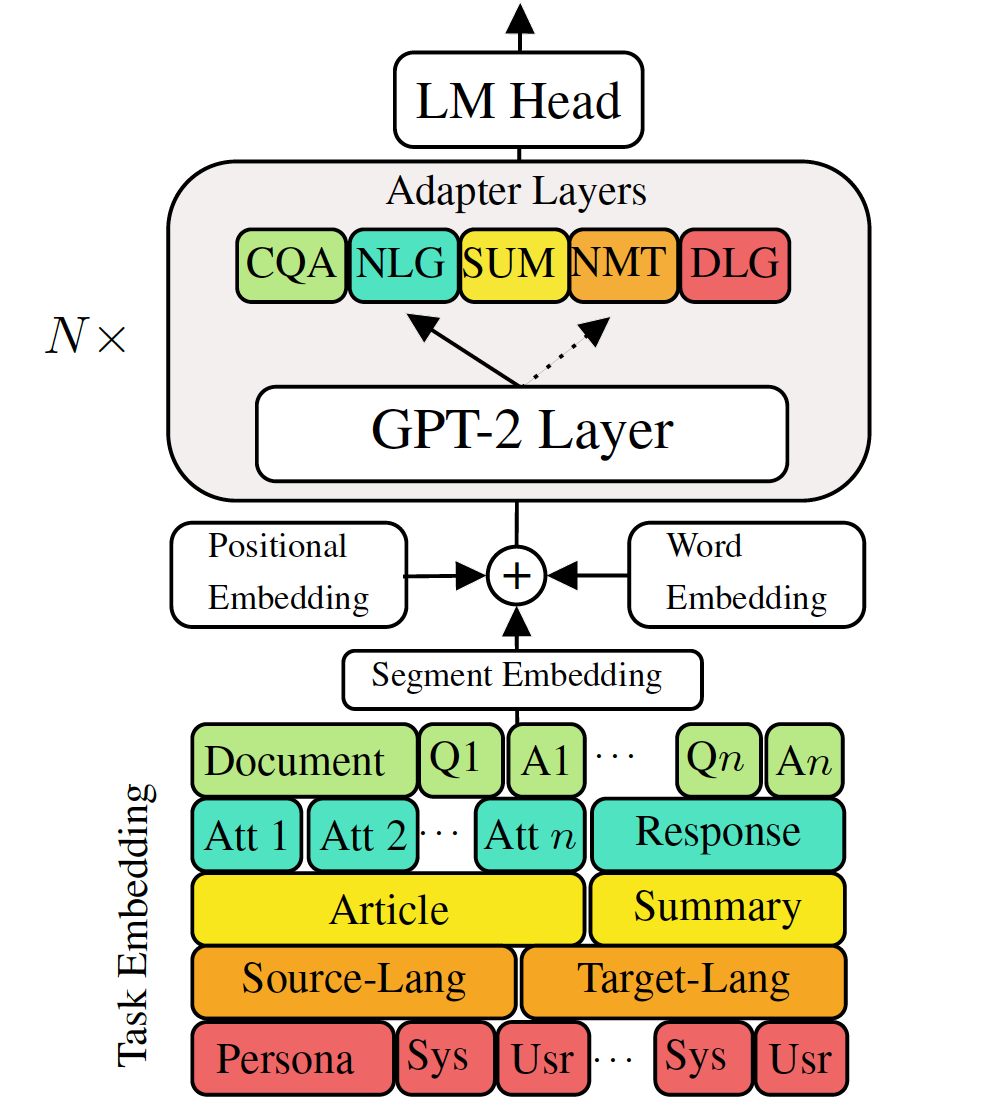
أظهرت نماذج اللغة التوليدية المسبقة التي تم تدريبها على مدار مهام توليد اللغة لأسفل نتائج واعدة. ومع ذلك ، فإنه يأتي مع تكلفة وجود نموذج واحد ، كبير ، لكل مهمة ، وهو ليس مثاليًا في سيناريوهات الذاكرة المنخفضة/الطاقة (على سبيل المثال ، الهاتف المحمول). في هذا العمل ، نقترح طريقة فعالة لضبط مهام التوليد المتعددة لأسفل في وقت واحد باستخدام نموذج واحد مدرب مسبقًا. تُظهر التجارب في خمس مهام توليد اللغة المتنوعة أنه من خلال استخدام معلمات إضافية من 2 إلى 3 ٪ لكل مهمة ، يمكن أن يحافظ نموذجنا أو حتى تحسين أداء صياغة النموذج بأكمله.
تحقق من الحزم المطلوبة أو قم بتشغيل الأمر ببساطة
❱❱❱ pip install -r requirements.txt مجموعة البيانات
قم بتنزيل مجموعات البيانات المعالجة مسبقًا
استنساخ
نحن نقدم نقطة تفتيش مدربة من VLM لدينا.
نموذج الاختبار: اختر مهمة واحدة من (MT ، تلخيص ، حوار ، QA ، NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathلحن GPT-2
الترجمة الآلية للقطار:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonاختبار الترجمة الآلية:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointتحقق من Run.sh لتشغيل مهام أخرى
محولات قطار VLM وتضمينات المهام
تدريب الترجمة الآلية بدون تقطير المعرفة
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005تدريب الترجمة الآلية باستخدام تقطير المعرفة مستوى الجملة:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationاختبار الجهاز traslation:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointتحقق من Run.sh لتشغيل مهام أخرى
الجمع بين جميع المحولات وتضمين المهام في نموذج واحد
السطر 68 من combine_all.py لتوفير قائمة نقطة التفتيش
❱❱❱ python combine_all.pyاختبار لمعرفة ما إذا كانت النتيجة هي نفسها
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathتوضح البرامج النصية أعلاه كيفية تدريب VLM بشكل مستمر عندما تصل المهام بالتتابع.
التدريب متعدد المهام VLM
عندما تتوفر جميع المهام في نفس الوقت.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 يتم تنفيذ هذا المستودع قاعدة على luggingface


