VGLM
1.0.0


Esta é a implementação do artigo:
Explorando o modelo de linguagem generativa versátil por meio de aprendizado de transferência eficiente em parâmetro . Zhaojiang Lin , Andrea Madotto , Pascale Fung Aschedings of EMNLP 2020 [PDF]
Se você usar qualquer código de origem ou conjuntos de dados incluído neste kit de ferramentas em seu trabalho, cite o documento a seguir. O Bibtex está listado abaixo:
@Article {lin2020Exploring,
title = {Explorando o modelo de linguagem generativa versátil por meio de aprendizado de transferência eficiente em parâmetro},
autor = {Lin, Zhaojiang e Madotto, Andrea and Fung, Pascale},
Journal = {arxiv pré -impressão arxiv: 2004.03829},
ano = {2020}
}
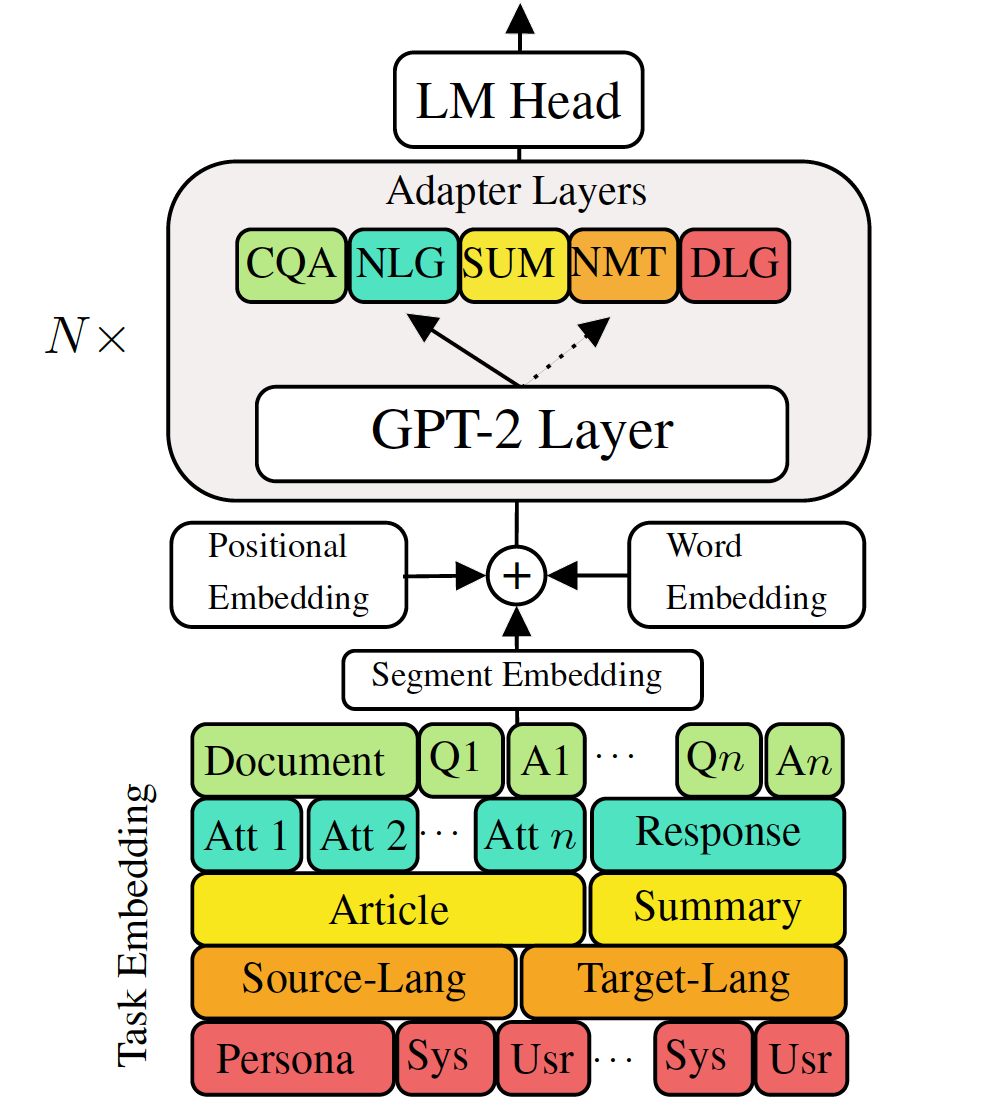
Modelos de linguagem generativa pré-treinada de ajuste fino para tarefas de geração de idiomas a baixo de fluxo mostraram resultados promissores. No entanto, ele tem o custo de ter um modelo único, grande para cada tarefa, que não é ideal em cenários de baixa memória/potência (por exemplo, móvel). Neste trabalho, propomos uma maneira eficaz de ajustar várias tarefas de geração de fluxo inferior usando simultaneamente um único modelo pré-treinado grande. As experiências em cinco tarefas diversas de geração de idiomas mostram que, apenas usando 2-3% de parâmetros adicionais para cada tarefa, nosso modelo pode manter ou até melhorar o desempenho de ajustar o modelo inteiro.
Verifique os pacotes necessários ou simplesmente execute o comando
❱❱❱ pip install -r requirements.txt Conjunto de dados
Baixe os conjuntos de dados pré -processados
Reprodutibilidade
Fornecemos o ponto de verificação treinado do nosso VLM.
Modelo de teste: escolha uma tarefa em (MT, Summarization, Diálogo, QA, NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathTune fina GPT-2
Tradução da máquina de trem:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonTradução da máquina de teste:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointVerifique o run.sh para executar outras tarefas
Adaptadores de trem VLM e incorporações de tarefas
Tradução da máquina de trem sem destilação de conhecimento
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005Tradução da máquina de trem usando o nível de frase Destilação de conhecimento:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationTraslatação da máquina de teste:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointVerifique o run.sh para executar outras tarefas
Combine todos os adaptadores e tarefas incorporando em modelo único
Linha 68 de Combine_all.py para fornecer a lista de ponto de verificação
❱❱❱ python combine_all.pyTeste para ver se o resultado é o mesmo
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathOs scripts acima ilustram como treinar VLM continuamente quando as tarefas chegam sequencialmente.
Treinamento multitarefa VLM
Quando todas as tarefas disponíveis ao mesmo tempo.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 Este repositório é implementado base em huggingface


