VGLM
1.0.0


这是本文的实施:
通过参数效率转移学习探索多功能生成语言模型。 Zhaojiang Lin , Andrea Madotto , EMNLP 2020的Pascale Fung发现[PDF]
如果您使用此工具包中包含的任何源代码或数据集,请引用以下论文。 Bibtex在下面列出:
@Article {lin2020 exploring,
title = {通过参数效率转移学习探索多功能生成语言模型},
作者= {lin,Zhaojiang和Madotto,Andrea and Fung,Pascale},
journal = {arxiv preprint arxiv:2004.03829},,
年= {2020}
}
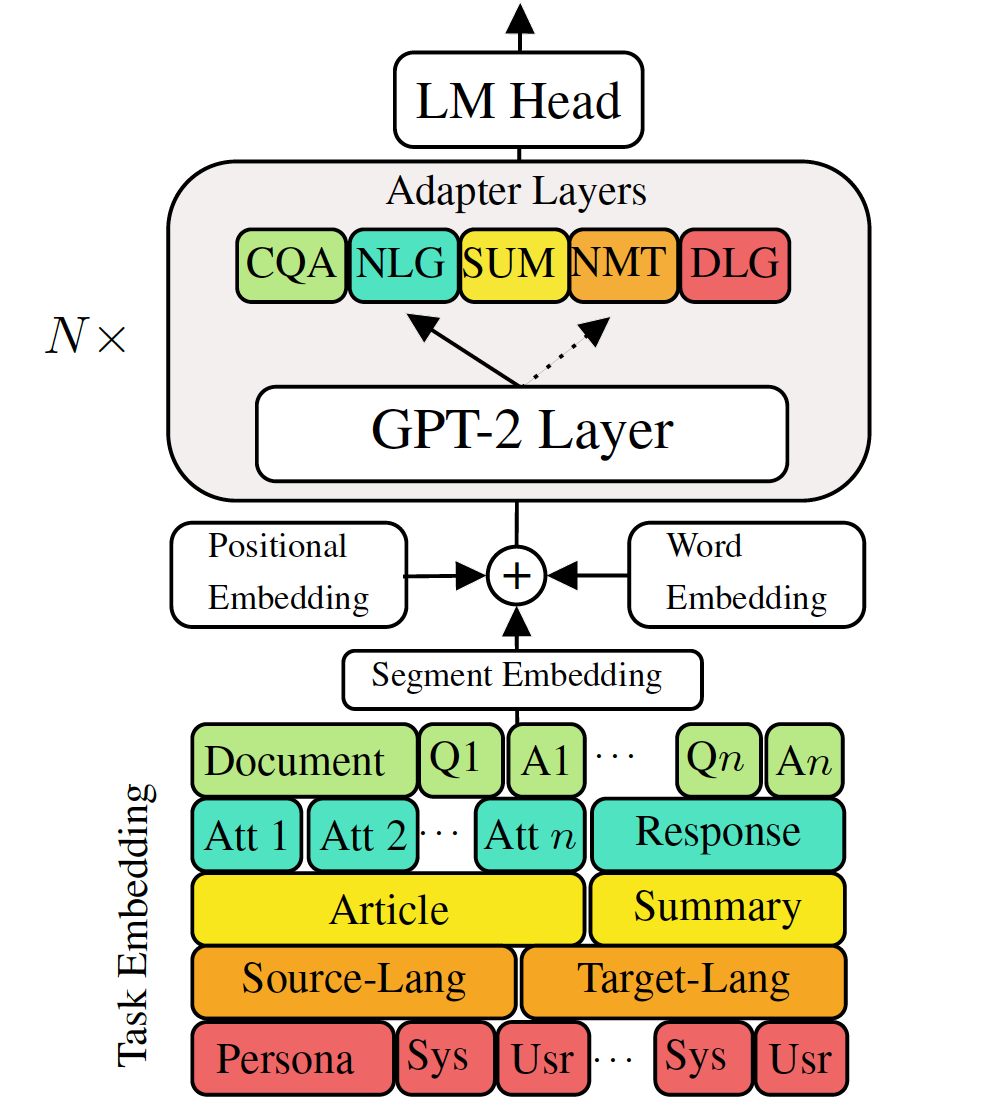
对下游语言生成任务进行微调预训练的生成语言模型已显示出令人鼓舞的结果。但是,它具有为每个任务拥有一个单一的大型模型的成本,这在低内存/功率方案(例如移动设备)中并不理想。在这项工作中,我们提出了一种使用单个大型预训练模型同时微调多个下游生成任务的有效方法。五种不同语言生成任务的实验表明,通过为每个任务使用额外的2-3%参数,我们的模型可以维护甚至可以提高整个模型的微调性能。
检查所需的软件包或简单地运行命令
❱❱❱ pip install -r requirements.txt 数据集
下载预处理数据集
可重复性
我们提供VLM的训练有素的检查站。
测试模型:从(MT,Summarization,对话,QA,NLG)中选择一个任务。
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path微调GPT-2
火车机翻译:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json测试机译:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpoint检查run.sh以运行其他任务
VLM火车适配器和任务嵌入
没有知识蒸馏的训练机译
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005使用句子级别知识蒸馏的火车计算机翻译:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillation测试机traslation:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpoint检查run.sh以运行其他任务
将所有适配器和任务嵌入到单个模型中
combine_all.py的第68行以提供检查点的列表
❱❱❱ python combine_all.py测试以查看结果是否相同
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path上面的脚本说明了在任务依次到达时如何连续训练VLM。
多任务培训VLM
同时可用的所有任务。
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 该存储库是在HuggingFace上实现的


