VGLM
1.0.0


이것은 논문의 구현입니다.
매개 변수 효율적인 전송 학습을 통해 다목적 생성 언어 모델 탐색 . Zhaojiang Lin , Andrea Madotto , Pascale 곰팡이 EMNLP 2020 [PDF]
작업 에서이 툴킷에 포함 된 소스 코드 또는 데이터 세트를 사용하는 경우 다음 논문을 인용하십시오. Bibtex는 다음과 같습니다.
@article {lin2020exploring,
title = {매개 변수 효율적인 전송 학습을 통한 다목적 생성 언어 모델 탐색},
저자 = {Lin, Zhaojiang 및 Madotto, Andrea and Fung, Pascale},
저널 = {arxiv preprint arxiv : 2004.03829},
연도 = {2020}
}
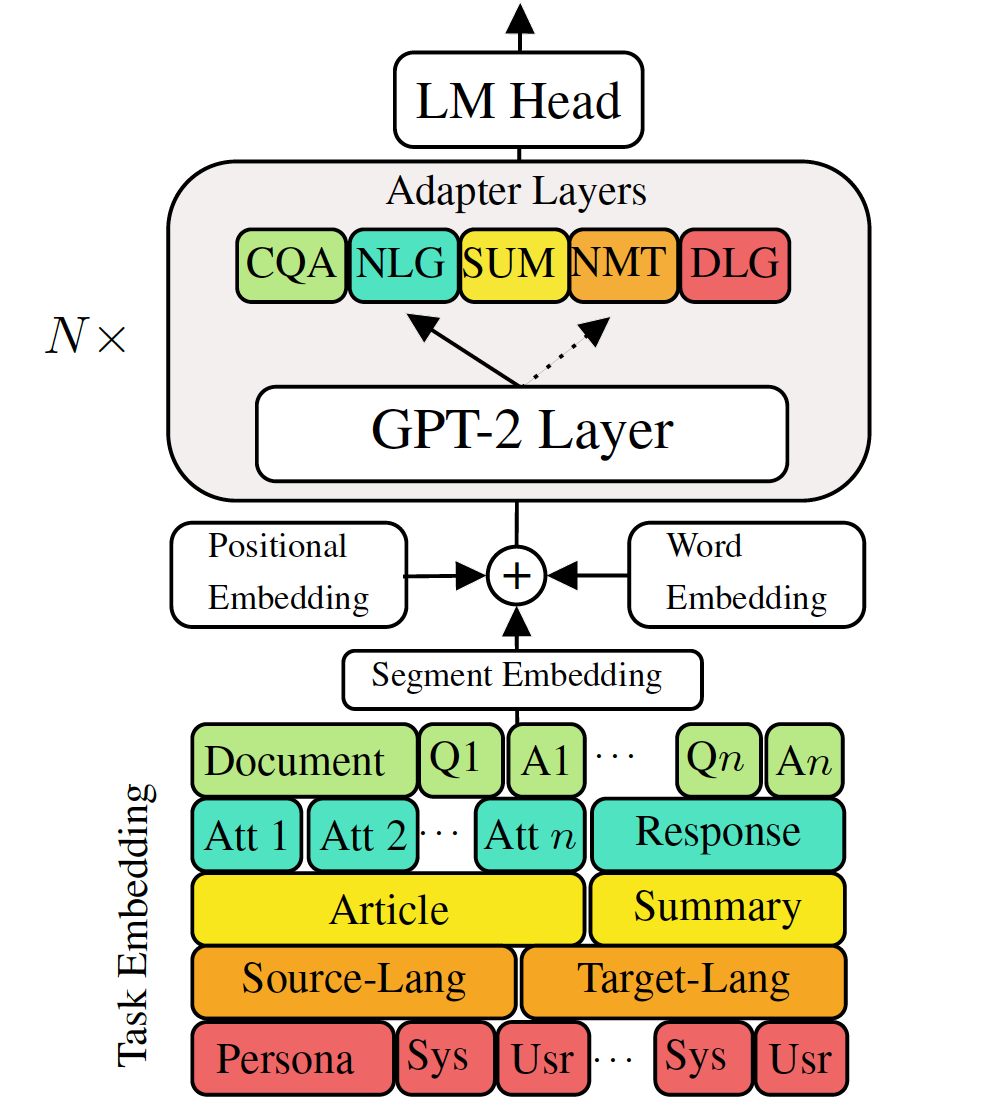
다운 스트림 언어 생성 작업에 미세 조정 사전 훈련 된 생성 언어 모델을 미세 조정하면 유망한 결과가 나타났습니다. 그러나 각 작업에 대해 단일의 큰 모델을 갖는 비용이 제공되며, 이는 저 메모리/전력 시나리오 (예 : 모바일)에서는 이상적이지 않습니다. 이 작업에서 우리는 단일의 대형 미리 훈련 된 모델을 사용하여 다중 다운 스트림 생성 작업을 동시에 미세 조정하는 효과적인 방법을 제안합니다. 5 가지 다양한 언어 생성 작업의 실험에 따르면 각 작업에 대해 추가 2-3% 매개 변수 만 사용하면 모델이 전체 모델을 미세 조정하는 성능을 유지하거나 향상시킬 수 있습니다.
필요한 패키지를 확인하거나 간단히 명령을 실행하십시오
❱❱❱ pip install -r requirements.txt 데이터 세트
전처리 데이터 세트 를 다운로드하십시오
재현성
우리는 VLM의 훈련 된 검문소를 제공합니다.
테스트 모델 : (MT, 요약, 대화, QA, NLG] 중 하나를 선택하십시오.
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path미세 조정 GPT-2
기차 기계 번역 :
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json테스트 기계 번역 :
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointrun.sh를 확인하여 다른 작업을 실행하십시오
VLM 열차 어댑터 및 작업 임베딩
지식 증류없이 기차 기계 번역
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005문장 수준 지식 증류를 사용한 기차 기계 번역 :
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillation테스트 기계 트라 슬레이션 :
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointrun.sh를 확인하여 다른 작업을 실행하십시오
모든 어댑터와 작업을 단일 모델로 결합하십시오.
체크 포인트 목록을 제공하려면 Combine_all.py의 68 행
❱❱❱ python combine_all.py결과가 동일한 지 확인하십시오
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path위의 스크립트는 작업이 순차적으로 도착할 때 VLM을 지속적으로 훈련시키는 방법을 보여줍니다.
멀티 태스킹 교육 VLM
모든 작업을 동시에 사용할 수있는 경우.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 이 저장소는 Huggingface 에서 기본으로 구현됩니다


