VGLM
1.0.0


これは論文の実装です。
パラメーター効率の高い転送学習を介して、汎用性のある生成言語モデルの調査。 Zhaojiang Lin 、 Andrea Madotto 、Pascale FungのEMNLP 2020 [PDF]の調査結果
このツールキットに含まれるソースコードまたはデータセットを使用している場合は、次の論文を引用してください。 bibtexは以下にリストされています。
@article {lin2020exploring、
title = {パラメーター効率の高い転送学習を介して多目的生成言語モデルの探索}、
著者= {lin、Zhaojiang and Madotto、Andrea and Fung、Pascale}、
journal = {arxiv preprint arxiv:2004.03829}、
年= {2020}
}
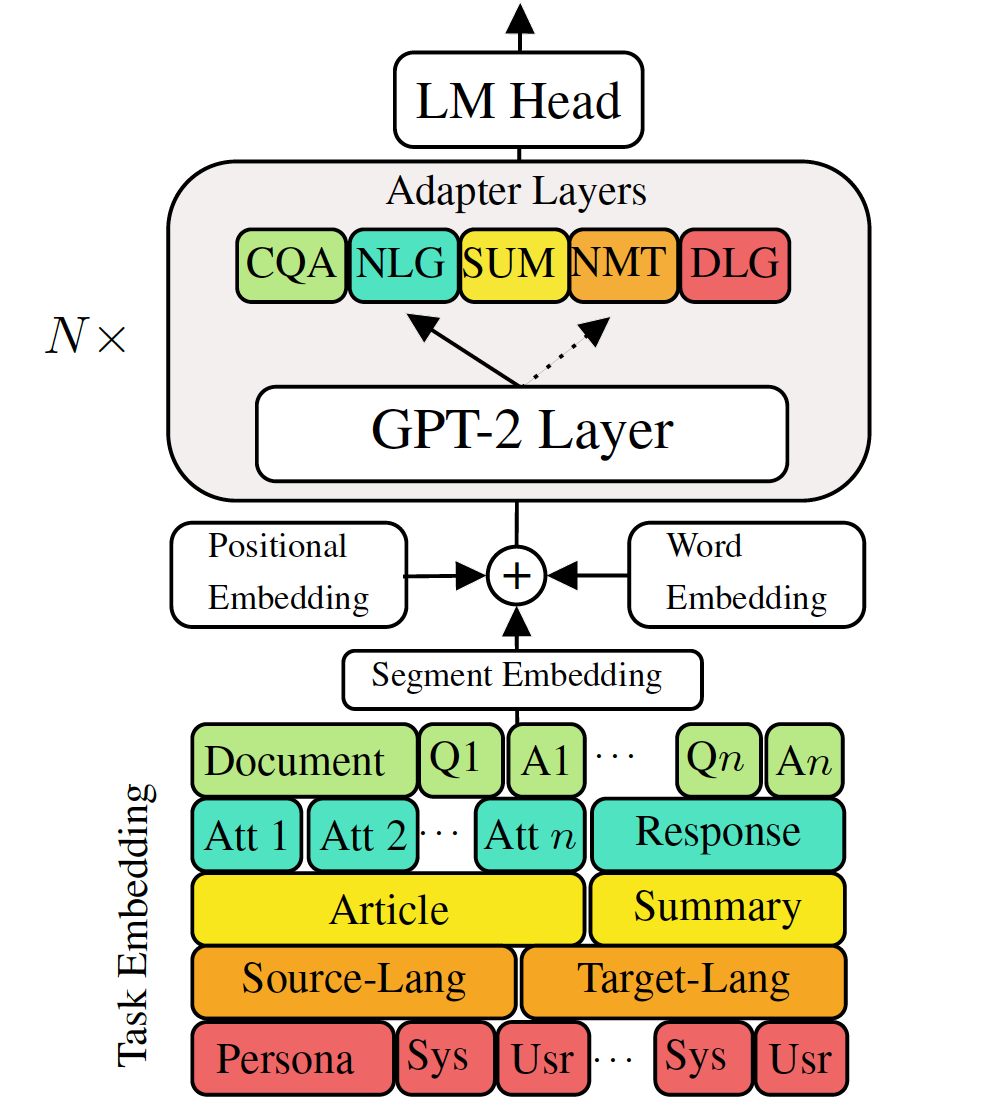
ダウンストリーム言語生成タスクに対する事前に訓練された生成言語モデルを微調整すると、有望な結果が示されています。ただし、低メモリ/パワーシナリオ(モバイルなど)では理想的ではない、各タスクに単一の大規模なモデルを持っているというコストが伴います。この作業では、単一の大規模な事前訓練モデルを使用して、複数のダウンストリーム生成タスクを同時に微調整するための効果的な方法を提案します。 5つの多様な言語生成タスクの実験は、各タスクに追加の2〜3%パラメーターを使用するだけで、モデルがモデル全体を微調整することのパフォーマンスを維持または改善できることを示しています。
必要なパッケージを確認するか、単にコマンドを実行します
❱❱❱ pip install -r requirements.txt データセット
プリプロセッシングされたデータセットをダウンロードします
再現性
VLMの訓練されたチェックポイントを提供します。
テストモデル:(MT、要約、対話、QA、NLG)から1つのタスクを選択します。
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path微調整GPT-2
列車の機械翻訳:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonマシンの翻訳をテスト:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointrun.shをチェックして、他のタスクを実行します
VLMトレインアダプターとタスクの埋め込み
知識の蒸留なしに機械の翻訳を列車に翻訳します
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005文レベルの知識蒸留を使用した機械翻訳を列車
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationテストマシンのトラスル化:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointrun.shをチェックして、他のタスクを実行します
すべてのアダプターとタスクの埋め込みを単一モデルに組み合わせる
Combine_all.pyの68行目はチェックポイントのリストを提供します
❱❱❱ python combine_all.py結果が同じかどうかを確認するためにテストします
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_path上記のスクリプトは、タスクが順番に到着したときにVLMを継続的にトレーニングする方法を示しています。
マルチタスクトレーニングVLM
すべてのタスクが同時に利用可能な場合。
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 このリポジトリは、 Huggingfaceに基づいて実装されています


