VGLM
1.0.0


Ini adalah implementasi makalah:
Menjelajahi model bahasa generatif serbaguna melalui pembelajaran transfer yang efisien parameter . Zhaojiang Lin , Andrea Madotto , Pascale Fung Temuan EMNLP 2020 [PDF]
Jika Anda menggunakan kode sumber atau set data yang termasuk dalam toolkit ini dalam pekerjaan Anda, silakan kutip makalah berikut. Bibtex tercantum di bawah ini:
@Article {lin2020exploring,
title = {Menjelajahi model bahasa generatif serbaguna melalui pembelajaran transfer parameter-efisien},
penulis = {Lin, Zhaojiang dan Madotto, Andrea dan Fung, Pascale},
Journal = {arXiv preprint arxiv: 2004.03829},
tahun = {2020}
}
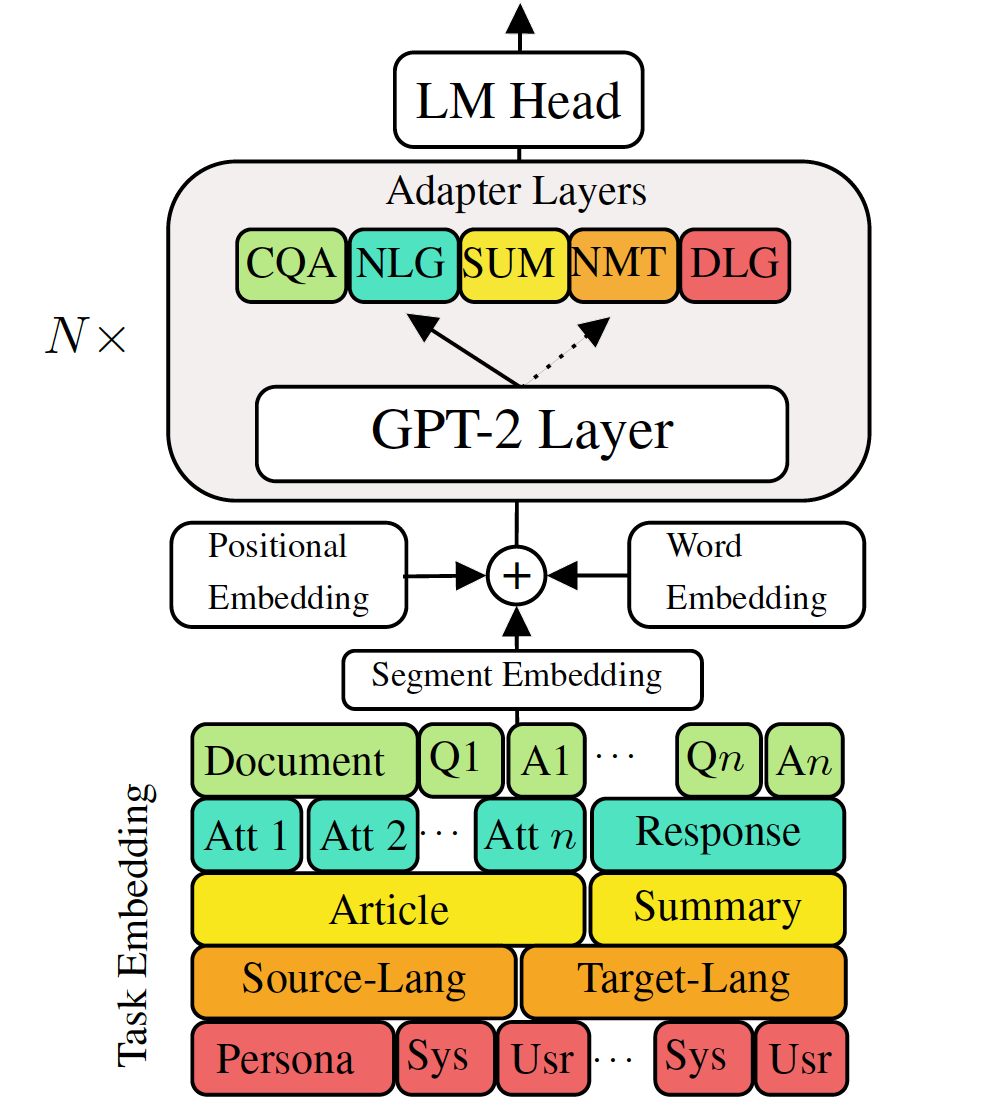
Model bahasa generatif pra-terlatih menyempurnakan untuk tugas-tugas pembuatan bahasa di bawah aliran telah menunjukkan hasil yang menjanjikan. Namun, ia datang dengan biaya memiliki model tunggal, besar, untuk setiap tugas, yang tidak ideal dalam skenario memori rendah/daya (misalnya, seluler). Dalam karya ini, kami mengusulkan cara yang efektif untuk menyempurnakan beberapa tugas generasi down-stream secara bersamaan menggunakan model pra-terlatih tunggal yang besar. Eksperimen dalam lima tugas pembuatan bahasa yang beragam menunjukkan bahwa dengan hanya menggunakan parameter 2-3% tambahan untuk setiap tugas, model kami dapat mempertahankan atau bahkan meningkatkan kinerja menyempurnakan seluruh model.
Periksa paket yang dibutuhkan atau cukup jalankan perintah
❱❱❱ pip install -r requirements.txt Dataset
Unduh set data preproses
Reproduktifitas
Kami memberikan pos pemeriksaan terlatih dari VLM kami.
Model Uji: Pilih satu tugas dari (MT, peringkasan, dialog, QA, NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathFine Tune GPT-2
Terjemahan mesin kereta api:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonTerjemahan mesin uji:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointPeriksa run.sh untuk menjalankan tugas lain
Adaptor dan Tugas Kereta VLM
Terjemahan mesin melatih tanpa distilasi pengetahuan
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005Terjemahan mesin kereta menggunakan Distilasi Pengetahuan Tingkat Kalimat:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationTRASLASI Mesin Uji:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointPeriksa run.sh untuk menjalankan tugas lain
Gabungkan semua adaptor dan tugas yang menanamkan ke dalam model tunggal
Baris 68 dari gabungan_all.py untuk memberikan daftar pos pemeriksaan
❱❱❱ python combine_all.pyTes untuk melihat apakah hasilnya sama
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathScript di atas menggambarkan cara melatih VLM terus menerus ketika tugas tiba secara berurutan.
VLM Pelatihan Multitask
Ketika semua tugas tersedia secara bersamaan.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 Repositori ini diimplementasikan sebagai basis pada permukaan pelukan


