VGLM
1.0.0


Dies ist die Implementierung des Papiers:
Erforschung eines vielseitigen Generativsprachenmodells über parametereffizientes Transferlernen . Zhaojiang Lin , Andrea Madotto , Pascale Fungergebnisse von EMNLP 2020 [PDF]
Wenn Sie Quellcodes oder Datensätze verwenden, die in diesem Toolkit in Ihrer Arbeit enthalten sind, geben Sie bitte das folgende Papier an. Das Bibtex ist unten aufgeführt:
@Article {lin2020ExPloring,
title = {vielseitiges generatives Sprachmodell über parametereffizientes Transferlernen},
Autor = {Lin, Zhaojiang und Madotto, Andrea und Pilg, Pascale},
Journal = {Arxiv Preprint Arxiv: 2004.03829},
Jahr = {2020}
}
Feinabstimmige vorgebrachte generative Sprachmodelle zu Aufgaben der Spracherzeugung im Ablauf der Sprache haben vielversprechende Ergebnisse gezeigt. Es wird jedoch die Kosten für ein einzelnes, großes Modell für jede Aufgabe geliefert, das in niedrigen Memory-/Power-Szenarien (z. B. mobile) nicht ideal ist. In dieser Arbeit schlagen wir eine effektive Möglichkeit vor, mehrere Aufgaben mit der Herunterstromgenerierung gleichzeitig mit einem einzelnen, großen vorgeborenen Modell zu finanzieren. Die Experimente in fünf verschiedenen Aufgaben der Sprachgenerierung zeigen, dass unser Modell durch nur zusätzliche 2-3% -Parameter für jede Aufgabe die Leistung der Feinabstimmung des gesamten Modells aufrechterhalten oder sogar verbessern kann.
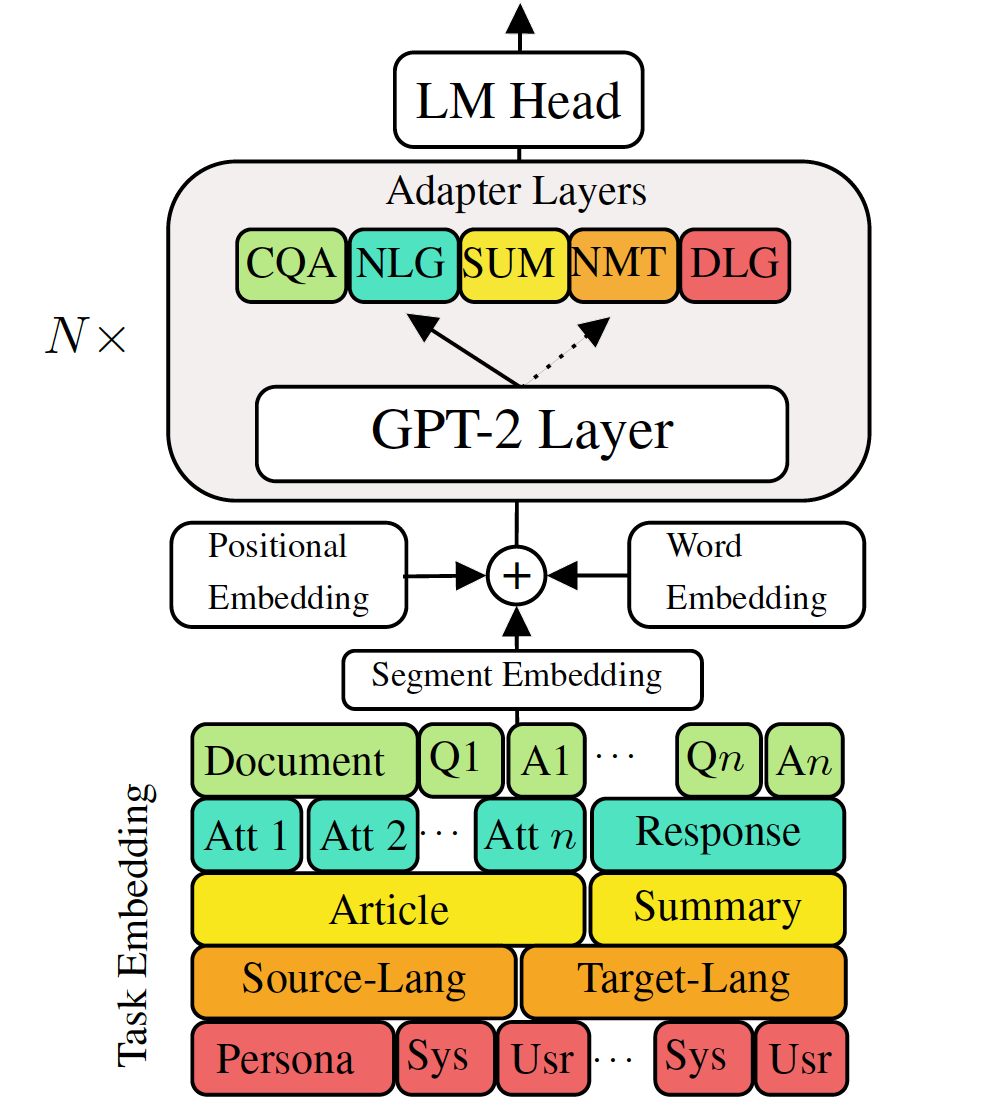
Überprüfen Sie die benötigten Pakete oder führen Sie einfach den Befehl aus
❱❱❱ pip install -r requirements.txt Datensatz
Laden Sie die vorverarbeiteten Datensätze herunter
Reproduzierbarkeit
Wir bieten den ausgebildeten Kontrollpunkt unserer VLM.
Testmodell: Wählen Sie eine Aufgabe aus (MT, Zusammenfassung, Dialog, QA, NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathFeine Melodie GPT-2
Zugmaschinenübersetzung:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonTestmaschinenübersetzung:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointÜberprüfen Sie run.sh, um andere Aufgaben auszuführen
VLM -Zugadapter und Aufgabeneinbettungen
Training maschinelle Übersetzung ohne Wissensdestillation
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005Zugübersetzung mit der Destillation der Satzebene mit der Wissensebene:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationTestmaschinen -Traslation:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointÜberprüfen Sie run.sh, um andere Aufgaben auszuführen
Kombinieren Sie alle Adapter und Aufgaben, die sich in ein einzelnes Modell einbetten
Zeile 68 von combine_all.py, um die Liste des Kontrollpunkts anzugeben
❱❱❱ python combine_all.pyTest, um festzustellen, ob das Ergebnis gleich ist
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathDie obigen Skripte veranschaulichen, wie VLM kontinuierlich trainiert, wenn Aufgaben nacheinander eintreffen.
Multitasking Training VLM
Wenn alle Aufgaben gleichzeitig verfügbar sind.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 Dieses Repository wird auf der Basis auf dem Umarmungen implementiert


