VGLM
1.0.0


Esta es la implementación del documento:
Explorando el modelo de lenguaje generativo versátil a través del aprendizaje de transferencia de parámetros y eficientes . Zhaojiang Lin , Andrea Madotto , Pascale Fung Hallazgos de EMNLP 2020 [PDF]
Si usa algún código fuente o conjunto de datos incluidos en este conjunto de herramientas en su trabajo, cite el siguiente documento. El bibtex se enumera a continuación:
@article {Lin20202Sploring,
Title = {Explorando el modelo de lenguaje generativo versátil a través de un aprendizaje de transferencia de parámetros-eficiente},
Autor = {Lin, Zhaojiang y Madotto, Andrea y Fung, Pascale},
Journal = {arxiv preprint arxiv: 2004.03829},
año = {2020}
}
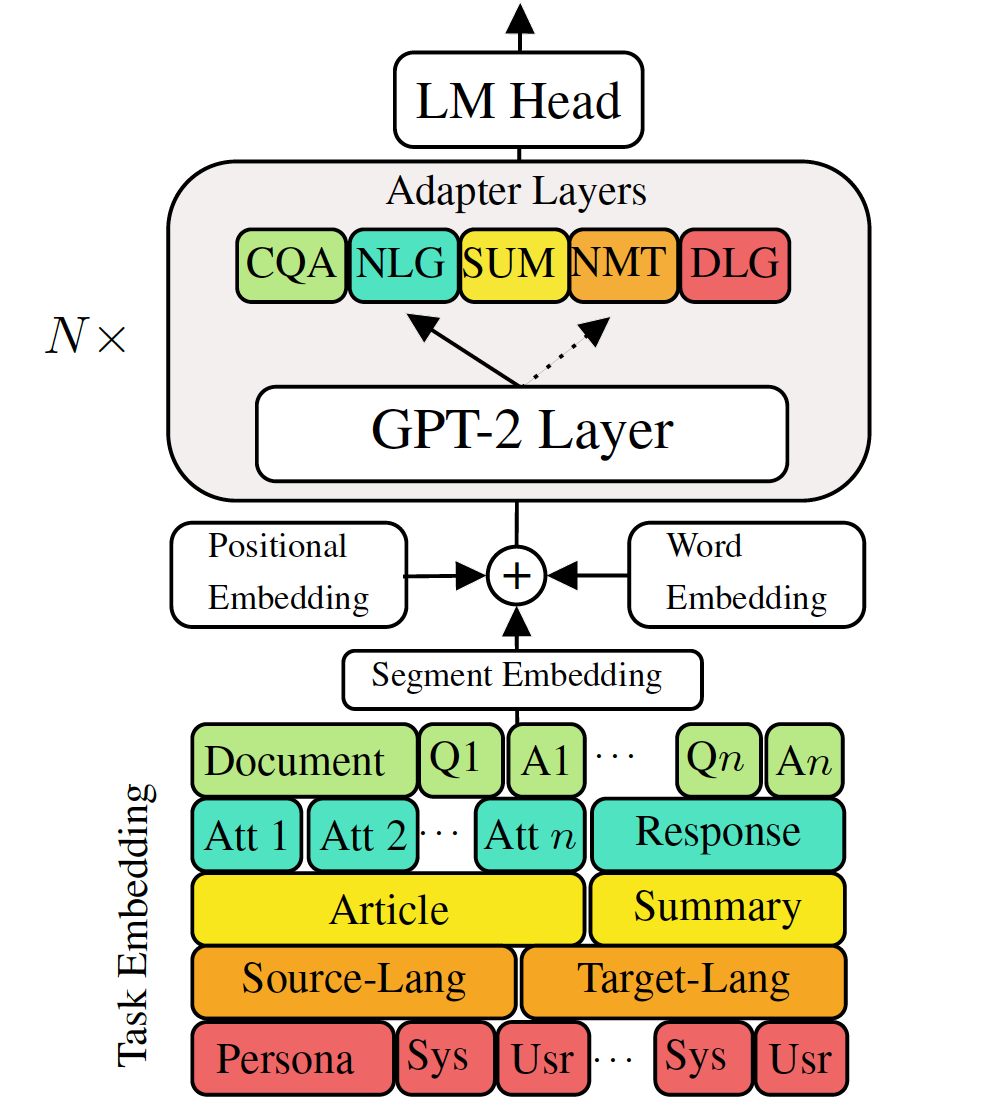
Los modelos de lenguaje generativo previamente capacitado para ajustar a las tareas de generación de lenguaje descendente han mostrado resultados prometedores. Sin embargo, viene con el costo de tener un modelo único y grande para cada tarea, que no es ideal en escenarios de baja memoria/potencia (por ejemplo, móvil). En este trabajo, proponemos una forma efectiva para ajustar múltiples tareas de generación de transmisión descendente simultáneamente utilizando un solo modelo previamente priorizado. Los experimentos en cinco tareas diversas de generación de idiomas muestran que simplemente utilizando un 2-3% de parámetros adicionales para cada tarea, nuestro modelo puede mantener o incluso mejorar el rendimiento de ajustar todo el modelo.
Verifique los paquetes necesarios o simplemente ejecute el comando
❱❱❱ pip install -r requirements.txt Conjunto de datos
Descargue los conjuntos de datos preprocesados
Reproducibilidad
Proporcionamos el punto de control capacitado de nuestro VLM.
Modelo de prueba: elija una tarea de (MT, resumen, diálogo, QA, NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathFINE TUNE GPT-2
Traducción del tren de tren:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonTraducción a máquina de prueba:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointCheque run.sh para ejecutar otras tareas
Adaptadores de trenes VLM e incrustaciones de tareas
Traducción automática de tren sin destilación de conocimiento
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005Traducción automática de trenes utilizando la destilación de conocimiento del nivel de oración:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationTraslación de la máquina de prueba:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointCheque run.sh para ejecutar otras tareas
Combine todos los adaptadores y la incrustación de tareas en un modelo único
Línea 68 de combine_all.py para proporcionar la lista de punto de control
❱❱❱ python combine_all.pyPrueba para ver si el resultado es el mismo
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathLos scripts anteriores ilustran cómo entrenar VLM continuamente cuando las tareas llegan secuencialmente.
Entrenamiento multitarea VLM
Cuando todas las tareas disponibles al mismo tiempo.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 Este repositorio se implementa base en Huggingface


