VGLM
1.0.0


Это реализация статьи:
Изучение универсального генеративного языкового языка с помощью параметров-эффективного переноса обучения . Чжаоцзян Лин , Андреа Мадотто , Паскаль Фунг Результаты EMNLP 2020 [PDF]
Если вы используете какие -либо исходные коды или наборы данных, включенные в этот инструментарий в вашей работе, укажите следующую статью. Bibtex перечислен ниже:
@Article {lin2020Exploring,
title = {Изучение универсальной генеративной языковой модели с помощью параметра-эффективного переноса обучения},
Автор = {Лин, Чжаоцзян и Мадотто, Андреа и Фунг, Паскале},
Journal = {arxiv preprint arxiv: 2004.03829},
Год = {2020}
}
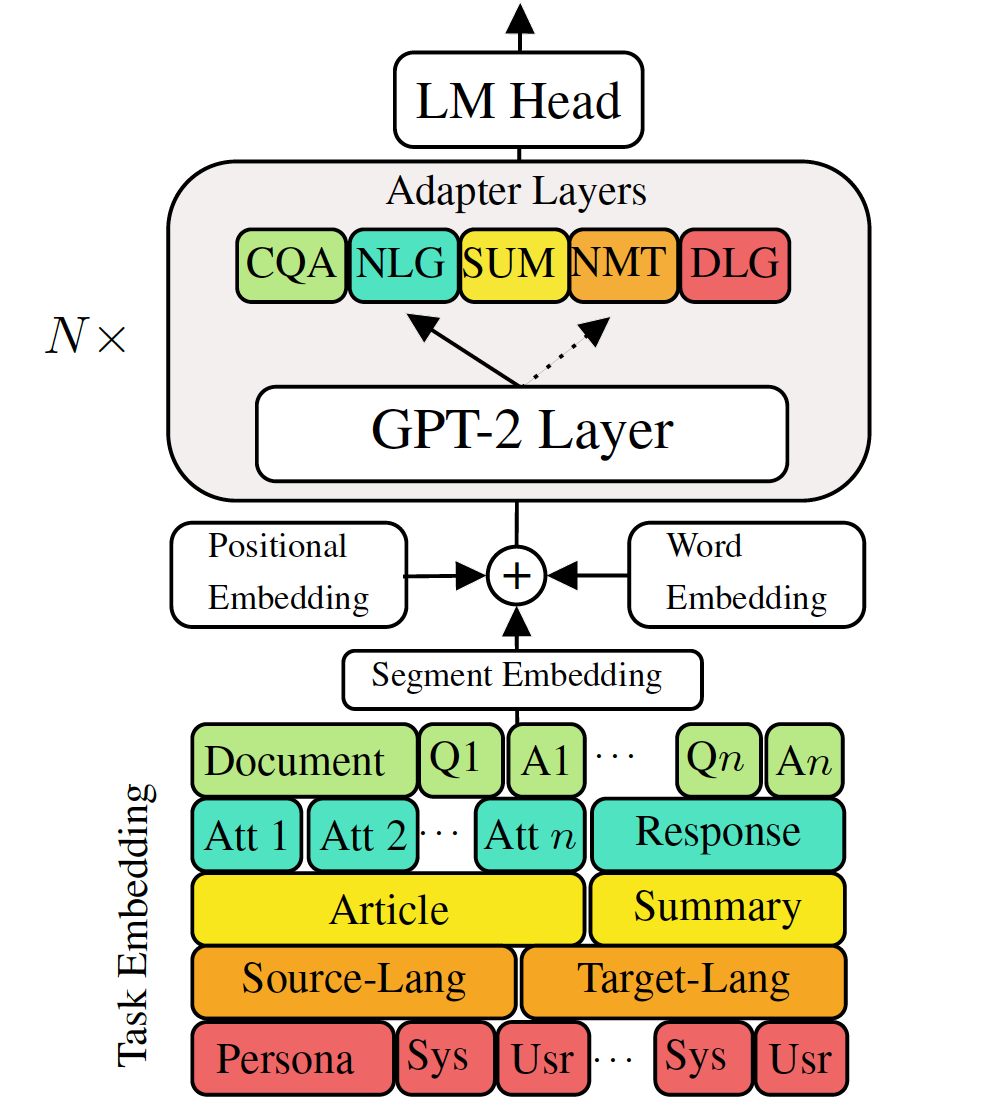
Прекрасная настройка предварительно обученных генеративных языковых моделей для задач генерации языка в нисходящем потоке показала многообещающие результаты. Тем не менее, это связано с стоимостью наличия единой, большой модели для каждой задачи, которая не идеальна в сценариях с низкой памяти/мощностью (например, мобильный). В этой работе мы предлагаем эффективный способ одновременно тонкой настройки нескольких задач генерации вниз по потоку с использованием одной большой предварительно обученной модели. Эксперименты в пяти разнообразных задачах генерации языка показывают, что, просто используя дополнительные 2-3% параметров для каждой задачи, наша модель может поддерживать или даже улучшить производительность точной настройки всей модели.
Проверьте необходимые пакеты или просто запустите команду
❱❱❱ pip install -r requirements.txt Набор данных
Загрузите предварительные наборы данных
Воспроизводимость
Мы предоставляем обученную контрольную точку нашего VLM.
Тестовая модель: выберите одну задачу из (MT, Summarization, Dialoge, QA, NLG].
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathFine Tune GPT-2
Трансферный перевод машины:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonТестовая машина перевод:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointПроверьте run.sh для выполнения других задач
VLM адаптеры поездов и встроения задач
Трансферат по машине без знаний о перегородке
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005Перевод машины поезда с использованием дистилляции знаний на уровне предложений:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationТестовая машина Traslation:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointПроверьте run.sh для выполнения других задач
Объедините все адаптеры и задачи, внедряющие в одну модель
Строка 68 Combine_all.py, чтобы предоставить список контрольных точек
❱❱❱ python combine_all.pyТест, чтобы увидеть, такой же результат
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathПриведенные выше сценарии иллюстрируют, как непрерывно обучать VLM, когда задачи поступают последовательно.
Многозадачный обучение VLM
Когда все задачи доступны одновременно.
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 Этот репозиторий реализован базой на Huggingface


