VGLM
1.0.0


นี่คือการดำเนินการของกระดาษ:
การสำรวจแบบจำลองภาษากำเนิดที่หลากหลายผ่านการเรียนรู้การถ่ายโอนพารามิเตอร์ที่มีประสิทธิภาพ Zhaojiang Lin , Andrea Madotto , Pascale Fung ผลการวิจัยของ EMNLP 2020 [PDF]
หากคุณใช้ซอร์สโค้ดหรือชุดข้อมูลใด ๆ ที่รวมอยู่ในชุดเครื่องมือนี้ในงานของคุณโปรดอ้างอิงกระดาษต่อไปนี้ bibtex แสดงอยู่ด้านล่าง:
@article {lin2020Exploring
title = {การสำรวจแบบจำลองภาษาที่หลากหลายผ่านการเรียนรู้การถ่ายโอนพารามิเตอร์-ประสิทธิภาพ}
ผู้แต่ง = {Lin, Zhaojiang และ Madotto, Andrea และ Fung, Pascale},
journal = {arxiv preprint arxiv: 2004.03829},
ปี = {2020}
-
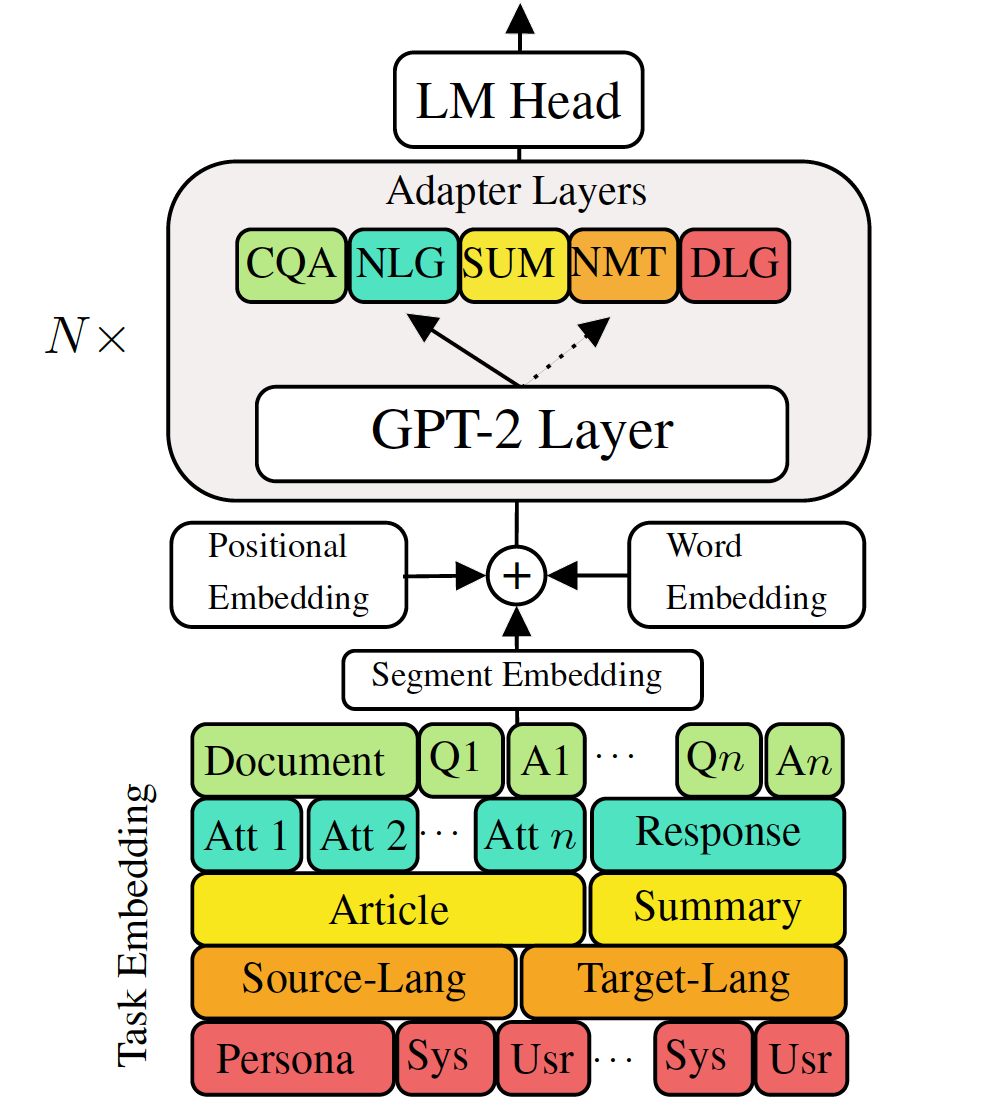
การปรับแต่งแบบจำลองภาษาที่ผ่านการฝึกอบรมล่วงหน้าไปยังงานการสร้างภาษาแบบดาวน์สตรีมได้แสดงผลลัพธ์ที่มีแนวโน้ม อย่างไรก็ตามมันมาพร้อมกับค่าใช้จ่ายในการมีแบบจำลองขนาดใหญ่ขนาดใหญ่สำหรับแต่ละงานซึ่งไม่เหมาะในสถานการณ์หน่วยความจำต่ำ/พลังงาน (เช่นมือถือ) ในงานนี้เราเสนอวิธีที่มีประสิทธิภาพสำหรับการปรับแต่งการสร้างงานหลายครั้งพร้อมกันโดยใช้แบบจำลองที่ผ่านการฝึกอบรมล่วงหน้าขนาดใหญ่ การทดลองในงานการสร้างภาษาที่หลากหลายห้างานแสดงให้เห็นว่าเพียงแค่ใช้พารามิเตอร์เพิ่มเติม 2-3% สำหรับแต่ละงานโมเดลของเราสามารถรักษาหรือปรับปรุงประสิทธิภาพของการปรับแต่งทั้งแบบจำลองทั้งหมด
ตรวจสอบแพ็คเกจที่จำเป็นหรือเพียงเรียกใช้คำสั่ง
❱❱❱ pip install -r requirements.txt ชุดข้อมูล
ดาวน์โหลด ชุดข้อมูล ที่ประมวลผลล่วงหน้า
การทำซ้ำได้
เราให้ จุดตรวจ ที่ผ่านการฝึกอบรมของ VLM ของเรา
แบบจำลองการทดสอบ: เลือกหนึ่งงานจาก (MT, การสรุป, บทสนทนา, QA, NLG]
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathปรับแต่ง GPT-2
การแปลเครื่องรถไฟ:
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.jsonการแปลเครื่องทดสอบ:
❱❱❱ python ./evaluate.py --task mt --no_sample --max_history=2 --model_checkpoint runs/$model_checkpointตรวจสอบ run.sh เพื่อเรียกใช้งานอื่น ๆ
VLM รถไฟอะแดปเตอร์และการฝังงาน
การแปลเครื่องรถไฟโดยไม่มีการกลั่นความรู้
❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005การแปลเครื่องรถไฟโดยใช้การกลั่นความรู้ระดับประโยค:
❱❱❱ python ./sentence_distiller.py --task mt --max_history=2 --model_checkpoint runs/$fully_finetuned_gpt2_checkpoint --no_sample ❱❱❱ python ./train.py --gradient_accumulation_steps=4 --max_history=2 --train_batch_size=8 --valid_batch_size=8 --n_epochs 8 --task mt --dataset_path data/NMT/data_en_ge.json --adapter_bottleneck 300 --lr 0.0005 --distillationเครื่องทดสอบ traslation:
❱❱❱ python ./evaluate.py --task mt --no_sample --adapter_bottleneck 300 --model_checkpoint runs/$model_checkpointตรวจสอบ run.sh เพื่อเรียกใช้งานอื่น ๆ
รวมอะแดปเตอร์และงานที่ฝังอยู่ในรุ่นเดียวทั้งหมด
บรรทัดที่ 68 ของ combine_all.py เพื่อให้รายการจุดตรวจสอบ
❱❱❱ python combine_all.pyทดสอบเพื่อดูว่าผลลัพธ์เหมือนกันหรือไม่
❱❱❱ python ./evaluate_vlm.py --task mt --no_sample --model_checkpoint $model_pathสคริปต์ข้างต้นแสดงวิธีการฝึกอบรม VLM อย่างต่อเนื่องเมื่องานมาถึงตามลำดับ
การฝึกอบรมมัลติทาสก์ VLM
เมื่องานทั้งหมดที่มีอยู่ในเวลาเดียวกัน
❱❱❱ python ./train_vlm.py --gradient_accumulation_steps=16 --train_batch_size=1 --valid_batch_size=1 --n_epochs 3 ที่เก็บนี้ถูกนำไปใช้กับฐานบน HuggingFace


