FindTheChatGPTer
1.0.0
ChatGPT/GPT4開源“平替”匯總,持續更新
ChatGPT爆火出圈,國內很多高校、研究機構和企業都發出類似ChatGPT的發布計劃。 ChatGPT沒有開源,復現難度極大,即使到現在GPT3的完全能力也沒有任何一個單位或者企業進行了復現。剛剛,OpenAI又官宣發布了圖文多模態的GPT4模型,能力相對ChatGPT又是大幅提升,似乎聞到了以通用人工智能主導的第四次工業革命的味道。
無論是國外還是國內,目前距離OpenAI的差距越來越大,大家都在緊鑼密鼓的追趕,以致於在這場技術革新中處於一定的優勢地位,目前很多大型企業的研發基本上都是走閉源路線,ChatGPT和GPT4官方公佈的細節很少,也不像之前發個幾十頁的論文介紹,OpenAI的商業化時代已經到來。當然,也有一些組織或者個人在開源平替上進行了探索,本文章匯總如下,本人也會持續跟踪,有更新的開源平替及時更新此處
該類方法主要採用非LLAMA等微調方式,自主設計或者優化GPT、T5模型,並實現從預訓練、監督微調、強化學習等全週期過程。
ChatYuan(元語AI)是由元語智能開發團隊開發和發布的,自稱第一個國內最早的一個功能型對話大模型,可以寫文章、寫作業、寫詩歌、做中英文間的翻譯;一些法律等特定領域問題也可以提供相關信息。該模型目前只支持中文,github鏈接是:
https://github.com/clue-ai/ChatYuan
從披露的技術細節看,底層採用7億參數規模的T5模型,並基於PromptClue進行了監督微調形成了ChatYuan。該模型基本上是ChatGPT技術路線的三步的第一步,沒有實現獎勵模型訓練和PPO強化學習訓練。
最近,ColossalAI開源了他們的ChatGPT實現。分享了他們的三步策略,完整實現了ChatGPT核心的技術路線:其Github如下:
https://github.com/hpcaitech/ColossalAI
本人基於該項目,更加明確了三步策略,並進行了分享:
第一階段(stage1_sft.py):SFT監督微調階段,該開源項目沒有實現,這個比較簡單,因為ColossalAI無縫支持Huggingface,本人直接用Huggingface的Trainer函數幾行代碼輕鬆實現,在這裡我用了一個gpt2模型,從其實現上看,其支持GPT2、OPT和BLOOM模型;
第二階段(stage2_rm.py):獎勵模型(RM)訓練階段,即項目Examples裡train_reward_model.py部分;
第三階段(stage3_ppo.py):強化學習(RLHF)階段,即項目train_prompts.py
三個文件的執行需要放在ColossalAI項目中,其中代碼中的cores即原始工程中的chatgpt,cores.nn在原始工程中變成了chatgpt.models
ChatGLM是清華技術成果轉化的公司智譜AI開源的GLM系列的對話模型,支持中英兩個語種,目前開源了其62億參數量的模型。其繼承了GLM之前的優勢,在模型架構上進行了優化,從而使得部署和應用門檻變低,實現大模型在消費級顯卡上的推理應用。詳細技術可以參考其github:
ChatGLM-6B開源地址為:https://github.com/THUDM/ChatGLM-6B
從技術路線上看,其實現了ChatGPT強化學習人類對齊策略,使得生成效果更佳貼近人類價值,其目前能力域主要包括自我認知、提綱寫作、文案寫作、郵件寫作助手、信息抽取、角色扮演、評論比較、旅遊建議等,目前其已經開發了正在內測的1300億的超大模型,算是目前開源平替裡面參數規模較大的對話大模型。
VisualGLM-6B(更新於2023年5月19日)
該團隊近期開源了ChatGLM-6B的多模態版,支持圖像、中文和英文的多模態對話。語言模型部分採用ChatGLM-6B,圖像部分通過訓練BLIP2-Qformer構建起視覺模型與語言模型的橋樑,整體模型共78億參數。 VisualGLM-6B依靠來自於CogView數據集的30M高質量中文圖文對,與300M經過篩選的英文圖文對進行預訓練,中英文權重相同。該訓練方式較好地將視覺信息對齊到ChatGLM的語義空間;之後的微調階段,模型在長視覺問答數據上訓練,以生成符合人類偏好的答案。
VisualGLM-6B開源地址為:https://github.com/THUDM/VisualGLM-6B
ChatGLM2-6B(更新於2023年6月27日)
該團隊近期開源了ChatGLM的二代版本ChatGLM2-6B,相對第一代版本,其主要特性包括採用了更大的數據規模,從1T提升到1.4T;最突出的莫過於其更長的上下文支持,從2K擴展到了32K,允許更長和更高輪次的輸入;另外起大幅優化了推理速度,提升了42%,佔用的顯存資源也大幅降低。
ChatGLM2-6B開源地址為:https://github.com/THUDM/ChatGLM2-6B
其號稱首個開源ChatGPT平替項目,其基本思路是基於谷歌語言大模型PaLM架構,以及使用從人類反饋中強化學習的方法(RLHF)。 PaLM是谷歌在今年4月發布的5400億參數全能大模型,基於Pathways系統訓練。其可以完成寫代碼、聊天、語言理解等任務,並且在大多數任務上具有強大的少樣本學習性能。同時採用了ChatGPT一樣的強化學習機制,能讓AI的回答更加符合情景要求,降低模型毒性。
Github地址為:https://github.com/lucidrains/PaLM-rlhf-pytorch
該項目號稱開源的最大規模模型,高達1.5萬億,且是多模態的模型。其能力域包括自然語言理解、機器翻譯、智能問答、情感分析和圖文匹配等。其開源地址為:
https://huggingface.co/banana-dev/GPTrillion
(2023年5月24日,該項目是愚人節玩笑節目,項目已刪除,特此說明)
OpenFlamingo是一個對標GPT-4、支持大型多模態模型訓練和評估的框架,由非盈利機構LAION重磅開源發布,其是對DeepMind的Flamingo模型的複現。目前開源的是其基於LLaMA的OpenFlamingo-9B模型。 Flamingo模型在包含交錯文本和圖像的大規模網絡語料庫上進行訓練,具備上下文少樣本學習能力。 OpenFlamingo實現了原始Flamingo中提出的相同架構,在一個新的多模態C4數據集的5M樣本和LAION-2B的10M樣本上訓練而來。該項目的開源地址是:
https://github.com/mlfoundations/open_flamingo
今年2月21日,復旦大學發布了MOSS,並開放公測,在公測崩潰後引起一些爭議。現在該項目迎來重要更新和開源。開源的MOSS支持中英兩個語種,且支持插件化,如解方程、搜索等。參數量大16B,在約七千億中英文以及代碼單詞上預訓練得到,後續經過對話指令微調、插件增強學習和人類偏好訓練具備多輪對話能力及使用多種插件的能力。該項目的開源地址是:
https://github.com/OpenLMLab/MOSS
與miniGPT-4、LLaVA類似,其是一個對標GPT-4的開源多模態大模型,其延續了mPLUG系列的模塊化訓練思想。其目前開源了7B參數量的模型,同時第一次針對視覺相關的指令理解提出一個全⾯的測試集OwlEval,通過人工評測對比了已有模型,包括LLaVA、MiniGPT-4等工作,其展示出更優的多模態能力,尤其在多模態指令理解能力、多輪對話能力、知識推理能力等方⾯表現突出。目前遺憾的是跟其他圖文大模型一樣,仍然只支持英文,但中文版已在其待開源List中。
該項目的開源地址是:https://github.com/X-PLUG/mPLUG-Owl
PandaLM是一個模型評估大模型,旨在對其他大模型生成內容的偏好進行自動評價,節省人工評估成本。 PandaLM自帶有Web界面進行分析,同時還支持Python代碼調用,僅用三行代碼即可對任意模型和數據生成的文本評估,使用很方便。
該項目開源地址是:https://github.com/WeOpenML/PandaLM
在近期召開的智源大會上,智源研究院開源了其悟道·天鷹大模型,具備中英雙語知識。開源版本的基礎模型參數量包括70億和330億,同時其開源了AquilaChat對話模型和quilaCode文本-代碼生成模型,且都已經開放了商業許可。 Aquila採用GPT-3、LLaMA等Decoder-only架構,同時針對中英雙語更新了詞表,並採用其加速訓練方法。其性能上的保障不僅依賴於模型的優化改進,還得益於智源這幾年在大模型高質量數據上的積累。
該項目開源地址是:https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
近期,微軟重磅發表多模態大模型論文和開源代碼-CoDi,徹底打通文本-語音-圖像-視頻,支持任意輸入,任意模態輸出。為了達到任意模態的生成,研究者將訓練分為兩個階段,第一個階段作者利用橋接對齊策略,組合條件進行訓練,給每個模態都打造一個潛在擴散模型;第二個階段給每個潛在擴散模型和環境編碼器上增加一個交叉注意力模塊,就能將潛在擴散模型的潛變量投射到共享空間中,使得生成的模態也進一步多樣化。
該項目開源地址是:https://github.com/microsoft/i-Code/tree/main/i-Code-V3
Meta重磅推出和開源其多模態大模型ImageBind,可以實現跨6種模態,包括圖像、視頻、音頻、深度、熱量和空間運動,ImageBind通過使用圖像的綁定特性,利用大型視覺語言模型和零樣本能力擴展到新的模態來解決對齊問題。圖像配對數據足以將這六種模態綁定在一起,允許不同的模式彼此打通模態割裂。
該項目開源地址是:https://github.com/facebookresearch/ImageBind
2023年4月10日,王小川官宣創辦AI大模型公司“百川智能”,旨在打造中國版的OpenAI。在成立了兩個月後,百川智能重磅開源其自主研發的baichuan-7B模型,支持中英文。 baichuan-7B不僅在C-Eval、AGIEval和Gaokao中文權威評測榜單上,以顯著優勢全面超過了ChatGLM-6B等其他大模型,並且在MMLU英文權威評測榜單上,大幅領先LLaMA-7B。該模型在高質量數據上達到萬億token規模,並基於高效的attention算子優化支持上萬超長動態窗口的擴張能力,目前開源支持4K上下文能力。該開源模型可以商用,比LLaMA更加友好。
該項目開源地址是:https://github.com/baichuan-inc/baichuan-7B
2023年8月6日,元象XVERSE團隊開源XVERSE-13B模型,該模型是一個多語言大模型,支持語種多達40+,支持上下文語境長度達8192,根據團隊介紹,該模型特點有:模型結構:XVERSE-13B使用主流Decoder-only的標準Transformer結構,支持8K的上下文長度,為同尺寸模型中最長,能滿足更長的多輪對話、知識問答與摘要等需求;訓練數據:構建了1.4 萬億token 的高質量、多樣化的數據對模型進行充分訓練,包含中、英、俄、西等40 多種語言,通過精細化設置不同類型數據的採樣比例,使得中英兩種語言表現優異,也能兼顧其他語言效果;分詞:基於BPE算法,使用上百GB語料訓練了一個詞表大小為100,278的分詞器,能夠同時支持多語言,而無需額外擴展詞表;訓練框架:自主研發多項關鍵技術,包括高效算子、顯存優化、並行調度策略、數據-計算-通信重疊、平台和框架協同等,讓訓練效率更高,模型穩定性強,在千卡集群上的峰值算力利用率可達到58.5%,位居業界前列。
該項目開源地址是:https://github.com/xverse-ai/XVERSE-13B
2023年8月3日,阿里通義千問70億模型開源,包括通用模型和對話模型,並且開源、免費、可商用。據介紹,Qwen-7B是基於Transformer的大語言模型,在超大規模預訓練數據上訓練得到。預訓練數據類型多樣,覆蓋廣泛,包括大量網絡文本、專業書籍、代碼等。它是支持中、英等多種語言的基座模型,在超過2萬億token數據集上訓練,上下文窗口長度達到8k。 Qwen-7B-Chat是基於Qwen-7B基座模型的中英文對話模型。通義千問7B預訓練模型在多個權威基準測評中表現出色,中英文能力遠超國內外同等規模開源模型,部分能力甚至超過了12B、13B大小的開源模型。
該項目開源地址是:https://github.com/QwenLM/Qwen-7B
LLaMA是由Meta發布的全新人工智能大型語言模型,在生成文本、對話、總結書面材料、證明數學定理或預測蛋白質結構等任務上方面表現良好。 LLaMA模型支持20種語言,包括拉丁語和西里爾字母語言,目前看原始模型並不支持中文。可以說LLaMA的史詩級洩露大力推進了類ChatGPT的開源發展。
(更新於2023年4月22日)但遺憾的是目前LLama的授權比較有限,只能用作科研,不允許做商用。為了解決商用完全開源問題,RedPajama項目應運而生,其旨在創建一個完全開源的LLaMA複製品,可用於商業應用,並為研究提供更透明的流程。完整的RedPajama包括了1.2萬億token的數據集,其下一步將著手開始進行大規模訓練。這項工作還是非常值得期待,其開源地址是:
https://github.com/togethercomputer/RedPajama-Data
(更新於2023年5月7日)
RedPajama更新了其訓練模型文件,包括3B和7B兩個參數量,其中3B可以在5年前發售的RTX2070遊戲顯卡上運行,彌補了LLaMa在3B上的空白。其模型地址為:
https://huggingface.co/togethercomputer
除了RedPajama,MosaicML推出MPT系列模型,其訓練數據採用了RedPajama的數據,在各類性能評估中,7B模型與原版LLaMA旗鼓相當。其模型開源地址為:
https://huggingface.co/mosaicml
無論是RedPajama還是MPT,其同時也開源了對應的Chat版模型,這兩個模型的開源為類ChatGPT商業化帶來了巨大的推動。
(更新於2023年6月1日)
Falcon是對標LLaMA的有一個開放大模型底座,其擁有7B和40B兩個參數量尺度,40B的性能號稱超高65B的LLaMA。據了解,Falcon仍然採用GPT式的自回歸解碼器模型,但其在數據上下了大功夫,從公網上抓取內容構建好初始預訓練數據集後,再使用CommonCrawl轉儲,進行大量過濾並進行大規模去重,最終得到一個由近5萬億個token組成的龐大預訓練數據集。同時又加進了很多精選語料,包括研究論文和社交媒體對話等內容。但該項目的授權飽受爭議,採用"半商業化"授權方式,在收益達到100萬後開始有10%的商業費用。
該項目開源地址是:https://huggingface.co/tiiuae
(更新於2023年7月3日)
原始的Falcon跟LLaMA一樣對中文支持能力欠缺,“伶荔(Linly)”項目團隊以Falcon模型為底,打造並開源了中文版Chinese-Falcon。該模型首先擴充大幅擴充了詞表,包括了8701個常用漢字、jieba詞表中前20000個中文高頻詞以及60個中文標點符號,去重後詞表大小擴充為90046。在訓練階段分別採用50G語料和2T大規模數據進行訓練。
該項目開源地址是:https://github.com/CVI-SZU/Linly
(更新於2023年7月24日)
原始的Falcon跟LLaMA一樣對中文支持能力欠缺,“伶荔(Linly)”項目團隊以Falcon模型為底,打造並開源了中文版Chinese-Falcon。該模型首先擴充大幅擴充了詞表,包括了8701個常用漢字、jieba詞表中前20000個中文高頻詞以及60個中文標點符號,去重後詞表大小擴充為90046。在訓練階段分別採用50G語料和2T大規模數據進行訓練。
該項目開源地址是:https://github.com/CVI-SZU/Linly
斯坦福發布的alpaca(羊駝模型),是一個基於LLaMA-7B模型微調出一個新模型,其基本原理是讓OpenAI的text-davinci-003模型以self-instruct方式生成52K指令樣本,以此來微調LLaMA。該項目已將訓練數據、生成訓練數據的代碼和超參數開源,模型文件尚未開源,以一天多達到5.6K星的關注度。該項工作由於成本低廉、數據易得,大受歡迎,也開啟了低成本ChatGPT的效仿之路。其github地址為:
https://github.com/tatsu-lab/stanford_alpaca
是由Nebuly+AI推出的基於人類反饋強化學習的LLaMA+AI聊天機器人的開源實現,它的技術路線類似ChatGPT,該項目上線剛剛2 天,狂攬5.2K 星。其github地址是:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA 訓練過程算法實現主打比ChatGPT 訓練更快、更便宜,據說能快近15倍,主要特色有:
完整的開源實現,允許用戶基於預訓練的LLaMA 模型構建ChatGPT 風格的服務;
LLaMA 架構更小,使得訓練過程和推理速度更快,成本更低;
內置了對DeepSpeed ZERO 的支持,以加速微調過程;
支持各種尺寸的LLaMA 模型架構,用戶可以根據自身偏好對模型進行微調。
OpenChatKit由前OpenAI研究員所在的Together團隊,以及LAION、Ontocord.ai團隊共同打造。 OpenChatKit包含200億個參數,用GPT-3的開源版本GPT-NoX-20B進行微調。同時,不同ChatGPT的強化學習,OpenChatKit採用一個60億參數的審核模型,對不合適或者是有害的信息進行過濾,確保生成內容的安全和質量。其github地址為:
https://github.com/togethercomputer/OpenChatKit
基於Stanford Alpaca ,實現基於Bloom、LLama的監督微調。 Stanford Alpaca 的種子任務都是英語,收集的數據也都是英文,該開源項目是促進中文對話大模型開源社區的發展,針對中文做了優化,模型調優僅使用由ChatGPT生產的數據(不包含任何其他數據)。項目包含以下內容:
175個中文種子任務
生成數據的代碼
10M生成的數據,目前開源了1.5M、0.25M數學指令數據集和0.8M多輪任務對話數據集
基於BLOOMZ-7B1-mt、LLama-7B優化後的模型
github地址為:https://github.com/LianjiaTech/BELLE
alpaca-lora是斯坦福大學的另一個鉅作,其使用LoRA(low-rank adaptation)技術復現了Alpaca的結果,用了一個更加低成本的方法,只在一塊RTX 4090顯卡上訓練5個小時得到了一個Alpaca水平相當的模型。而且,該模型可以在樹莓派上運行。在該項目中,其使用了Hugging Face的PEFT來實現廉價高效的微調。 PEFT 是一個庫(LoRA 是其支持的技術之一),可以讓你使用各種基於Transformer的語言模型並使用LoRA對其進行微調,從而使得在一般的硬件上廉價而有效地微調模型。該項目github地址是:
https://github.com/tloen/alpaca-lora
儘管Alpaca和alpaca-lora取得了較大的提升,但其種子任務都是英語,缺乏對中文的支持。一方面除了以上提到Belle收集到了大量的中文語料,另一方面基於alpaca-lora等前人工作,來自華中師範大學等機構的三位個人開發者開源的中文語言模型駱駝(Luotuo),單卡就能完成訓練部署。目前該項目釋放了兩個模型luotuo-lora-7b-0.1、luotuo-lora-7b-0.3,還有一個模型在計劃中。其github地址是:
https://github.com/LC1332/Chinese-alpaca-lora
Dolly在Alpaca的啟發下,用Alpaca數據集,在GPT-J-6B上實現微調,由於Dolly本身是一個模型的“克隆”,所以團隊最終決定將其命名為“多莉”。這種克隆式在Alpaca啟發下越來越多,總結起來大致採用Alpaca開源的數據獲取方式,在6B或者7B規模大小的舊模型上進行指令微調,獲得類似ChatGPT的的效果。這種思想很經濟,也能迅速模仿出ChatGPT的韻味來,廣受歡迎,一經推出star爆棚。該項目github地址是:
https://github.com/databrickslabs/dolly
斯坦福學者繼推出alpaca後,聯手CMU、UC伯克利等,推出一個全新模型——130億參數的Vicuna(俗稱小羊駝、駱馬)。僅需300美元就能實現ChatGPT 90%的性能。 Vicuna是通過在ShareGPT收集的用戶共享對話上對LLaMA進行微調訓練而來,測試過程使用GPT-4作為評判標準,結果顯示Vicuna-13B在超過90%的情況下實現了與ChatGPT和Bard相匹敵的能力。
UC伯克利LMSys org近期又發布了70億參數的Vicuna,不僅體積小、效率高、能力強,而且只需兩行命令就能在M1/M2芯片的Mac上運行,還能開啟GPU加速!
github開源地址為:https://github.com/lm-sys/FastChat/
另一個中文版的進行了開源Chinese-Vicuna ,github地址為:
https://github.com/Facico/Chinese-Vicuna
ChatGPT爆火後,都在尋找通往聖殿的快捷之路,一些類ChatGPT開始出現,尤其是低成本效仿ChatGPT成為一個熱門途徑。 LMFlow就是在這種需求場景下誕生的產物,他使得在3090這樣的普通顯卡上也能煉大模型。該項目由香港科技大學統計和機器學習實驗室團隊發起,致力於建立一個全開放的大模型研究平台,支持有限機器資源下的各類實驗,並且在平台上提升現有的數據利用方式和優化算法效率,讓平台發展成一個比之前方法更高效的大模型訓練系統。
利用該項目,即便是有限的計算資源,也能讓使用者針對專有領域支持個性化訓練。例如LLaMA-7B,一張3090耗時5 個小時即可完成訓練,成本大幅降低。該項目還開放了網頁端即刻體驗問答服務(lmflow.com)。 LMFlow的出現和開源使得普通資源可以訓練問答、陪伴、寫作、翻譯、專家領域諮詢等各種任務。目前很多研究者們正在嘗試用該項目訓練650億甚至更高參數量的大模型。
該項目github地址為:
https://github.com/OptimalScale/LMFlow
該項目提出了一個自動收集ChatGPT 對話的方法,讓ChatGPT 自我對話,批量生成高質量多輪對話數據集,分別收集了5萬條左右Quora、StackOverflow和MedQA的高質量問答語料,並已經全部開源。同時其改進了LLama模型,效果還不錯。白澤同樣採用目前低成本的LoRA微調方案,獲得白澤-7B、13B 和30B三種不同尺度,以及一個醫療垂直領域的模型。遺憾的是中文名字起的不錯,但目前仍然不支持中文,中文的白澤模型據悉在計劃中,未來發布。其開源github地址是:
https://github.com/project-baize/baize
基於LLama的ChatGPT平替繼續發酵,UC伯克利的伯克利發布了一個可以在消費級GPU上運行的對話模型Koala,參數達到13B。 Koala 的訓練數據集包括如下幾個部分:ChatGPT數據和開源數據(Open Instruction Generalist (OIG)、斯坦福Alpaca 模型使用的數據集、Anthropic HH、OpenAI WebGPT、OpenAI Summarization)。 Koala模型在EasyLM中使用JAX/Flax實現,用了8 個A100 GPU,完成2輪迭代需要6個小時。評測效果優於Alpaca,達到ChatGPT 50%的性能。
開源地址:https://github.com/young-geng/EasyLM
隨著斯坦福Alpaca的出現,一大堆基於LLama的羊駝家族和擴展動物家族開始出現,終於Hugging Face研究人員近期發布了一篇博客StackLLaMA:用RLHF訓練LLaMA的實踐指南。同時也發布了一個70億參數的模型——StackLLaMA。這是一個通過人類反饋強化學習在LLaMA-7B微調而來的模型。詳細見其博客地址:
https://huggingface.co/blog/stackllama
該項目針對中文對LLaMA進行了優化,並開源了其精調對話系統。該項目具體步驟包括:1. 詞表擴充,採用sentencepiece在中文數據上進行了訓練構建,並與LLaMA詞表進行了合併;2. 預訓練,在新詞表上,約20G左右的通用中文語料進行了訓練,訓練中運用了LoRA技術;3. 利用Stanford Alpaca,在51k數據上進行了精調訓練獲得對話能力。
開源地址為:https://github.com/ymcui/Chinese-LLaMA-Alpaca
4月12日,Databricks發布了Dolly2.0,號稱業內第一個開源、遵循指令的LLM,數據集由Databricks員工生成,並進行了開源且可用於商業目的。新提出的Dolly2.0是一個120億參數的語言模型,基於開源EleutherAI pythia模型系列,針對小型開源指令記錄語料庫進行了微調。
開源地址為:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
該項目帶來了全民ChatGPT的時代,訓練成本再次大幅降低。項目是微軟基於其Deep Speed優化庫開發而成,具備強化推理、RLHF模塊、RLHF系統三大核心功能,可將訓練速度提升15倍以上,成本卻大幅度降低。例如,一個130億參數的類ChatGPT模型,只需1.25小時就能完成訓練。
開源地址為:https://github.com/microsoft/DeepSpeed
該項目採取了不同於RLHF的方式RRHF進行人類偏好對齊,RRHF相對於RLHF訓練的模型量和超參數量遠遠降低。 RRHF訓練得到的Wombat-7B在性能上相比於Alpaca有顯著的增加,和人類偏好對齊的更好。
開源地址為:https://github.com/GanjinZero/RRHF
Guanaco是一個基於目前主流的LLaMA-7B模型訓練的指令對齊語言模型,原始52K數據的基礎上,額外添加了534K+條數據,涵蓋英語、日語、德語、簡體中文、繁體中文(台灣)、繁體中文(香港)以及各種語言和語法任務。豐富的數據助力模型的提升和優化,其在多語言環境中展示了出色的性能和潛力。
開源地址為:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新於2023年5月27日,Guanaco-65B)
最近華盛頓大學提出QLoRA,使用4 bit量化來壓縮預訓練的語言模型,然後凍結大模型參數,並將相對少量的可訓練參數以Low-Rank Adapters的形式添加到模型中,模型體量在大幅壓縮的同時,幾乎不影響其推理效果。該技術應用在微調LLaMA 65B中,通常需要780GB的GPU顯存,該技術只需要48GB,訓練成本大幅縮減。
開源地址為:https://github.com/artidoro/qlora
LLMZoo,即LLM動物園開源項目維護了一系列開源大模型,其中包括了近期備受關注的來自香港中文大學(深圳)和深圳市大數據研究院的王本友教授團隊開發的Phoenix(鳳凰)和Chimera等開源大語言模型,其中文本效果號稱接近百度文心一言,GPT-4評測號稱達到了97%文心一言的水平,在人工評測中五成不輸文心一言。
Phoenix 模型有兩點不同之處:在微調方面,指令式微調與對話式微調的進行了優化結合;支持四十餘種全球化語言。
開源地址為:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一個開源聊天助手,其可以理解任務、與第三方系統交互、動態檢索信息。據其說,其是第一個在人類數據上進行訓練的完全開源的大規模指令微調模型。該模型主要創新在於一個較大的人類反饋數據集(詳細說明見數據篇),公開測試顯示效果在人類對齊和毒性方面做的不錯,但是中文效果尚有不足。
開源地址為:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新於2023年4月26日)
HuggingChat是Huggingface繼OpenAssistant推出的對標ChatGPT的開源平替。其能力域基本與ChatGPT一致,在英文等語系上效果驚艷,被成為ChatGPT目前最強開源平替。但筆者嘗試了中文,可謂一塌糊塗,中文能力還需要有較大的提升。 HuggingChat的底座是oasst-sft-6-llama-30b,也是基於Meta的LLaMA-30B微調的語言模型。
該項目的開源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在線體驗地址是:https://huggingface.co/chat
StableVicuna是一個Vicuna-13B v0(LLaMA-13B上的微調)的RLHF的微調模型。
StableLM-Alpha是以開源數據集the Pile(含有維基百科、Stack Exchange和PubMed等多個數據源)基礎上訓練所得,訓練token量達1.5萬億。
為了適應對話,其在Stanford Alpaca模式基礎上,結合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等數據集,微調獲得模型StableLM-Tuned-Alpha
該項目的開源地址是:https://github.com/Stability-AI/StableLM
該模型垂直醫學領域,經過中文醫學指令精調/指令集對原始LLaMA-7B模型進行了微調,增強了醫學領域上的對話能力。
該項目的開源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
該模型的底座採用了自主研發的RWKV語言模型,100% RNN,微調部分仍然是經典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其開源了1B5、3B、7B和14B的模型,目前支持中英兩個語種,提供不同語種比例的模型文件。
該項目的開源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分類ChatGPT基本都是採用人工對齊方式,如RLHF,Alpaca模式只是實現了ChatGPT的效仿式對齊,對齊能力受限於原始ChatGPT對齊能力。卡內基梅隆大學語言技術研究所、IBM 研究院MIT-IBM Watson AI Lab和馬薩諸塞大學阿默斯特分校的研究者提出了一種全新的自對齊方法。其結合了原則驅動式推理和生成式大模型的生成能力,用極少的監督數據就能達到很好的效果。該項目工作成功應用在LLaMA-65b模型上,研發出了Dromedary(單峰駱駝)。
該項目的開源地址是:https://github.com/IBM/Dromedary
LLaVA是一個多模態的語言和視覺對話模型,類似GPT-4,其主要還是在多模態數據指令工程上做了大量工作,目前開源了其13B的模型文件。從性能上,據了解視覺聊天相對得分達到了GPT-4的85%;多模態推理任務的科學問答達到了SoTA的92.53%。該項目的開源地址是:
https://github.com/haotian-liu/LLaVA
從名字上看,該項目對標GPT-4的能力域,實現了一個縮略版。該項目來自來自沙特阿拉伯阿卜杜拉國王科技大學的研究團隊。該模型利用兩階段的訓練方法,先在大量對齊的圖像-文本對上訓練以獲得視覺語言知識,然後用一個較小但高質量的圖像-文本數據集和一個設計好的對話模闆對預訓練的模型進行微調,以提高模型生成的可靠性和可用性。該模型語言解碼器使用Vicuna,視覺感知部分使用與BLIP-2相同的視覺編碼器。
該項目的開源地址是:https://github.com/Vision-CAIR/MiniGPT-4
該項目與上述MiniGPT-4底層具有很大相通的地方,文本部分都使用了Vicuna,視覺部分則是BLIP-2微調而來。在論文和評測中,該模型在看圖理解、邏輯推理和對話描述方面具有強大的優勢,甚至號稱超過GPT-4。 InstructBLIP強大性能主要體現在視覺-語言指令數據集構建和訓練上,使得模型對未知的數據和任務具有零樣本能力。在指令微調數據上為了保持多樣性和可及性,研究人員一共收集了涵蓋了11個任務類別和28個數據集,並將它們轉化為指令微調格式。同時其提出了一種指令感知的視覺特徵提取方法,充分利用了BLIP-2模型中的Q-Former架構,指令文本不僅作為輸入給到LLM,同時也給到了QFormer。
該項目的開源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是開源的推理能力增強的中英雙語LLaMA模型,該模型訓練過程和Chinese-LLaMA-Alpaca有點類似,都是三階段:詞表擴充、預訓練和指令精調。不同的是在增強預訓練階段,BiLLa加入了任務數據,且沒有採用Lora技術,精調階段用到的指令數據也豐富的多。該模型在邏輯推理方面進行了特別增強,主要體現在加入了更多的邏輯推理任務指令。
該項目的開源地址是:https://github.com/Neutralzz/BiLLa
該項目是由IDEA開源,被成為"姜子牙",是在LLaMA-13B基礎上訓練而得。該模型也採用了三階段策略,一是重新構建中文詞表;二是在千億token量級數據規模基礎上繼續預訓練,使模型具備原生中文能力;最後經過500萬條多任務樣本的有監督微調(SFT)和綜合人類反饋訓練(RM+PPO+HFFT+COHFT+RBRS),增強各種AI能力。其同時開源了一個評估集,包括常識類問答、推理、自然語言理解任務、數學、寫作、代碼、翻譯、角色扮演、翻譯9大類任務,32個子類,共計185個問題。
該項目的開源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
評估集開源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
該項目的研究者提出了一種新的視覺-語言指令微調對齊的端到端的經濟方案,其稱之為多模態適配器(MMA)。其巨大優勢是只需要輕量化的適配器訓練即可打通視覺和語言之間的橋樑,無需像LLaVa那樣需要全量微調,因此成本大大降低。項目研究者還通過52k純文本指令和152k文本-圖像對,微調訓練成一個多模態聊天機器人,具有較好的的視覺-語言理解能力。
該項目的開源地址是:https://github.com/luogen1996/LaVIN
該模型由港科大發布,主要是針對閉源大語言模型的對抗蒸餾思想,將ChatGPT的知識轉移到了參數量LLaMA-7B模型上,訓練數據只有70K,實現了近95%的ChatGPT能力,效果相當顯著。該工作主要針對傳統Alpaca等只有從閉源大模型單項輸入的缺點出發,創新性提出正反饋循環機制,通過對抗式學習,使得閉源大模型能夠指導學生模型應對難的指令,大幅提升學生模型的能力。
該項目的開源地址是:https://github.com/YJiangcm/Lion
最近多模態大模型成為開源主力,VPGTrans是其中一個,其動機是利用低成本訓練一個多模態大模型。其一方面在視覺部分基於BLIP-2,可以直接將已有的多模態對話模型的視覺模塊遷移到新的語言模型;另一方面利用VL-LLaMA和VL-Vicuna為各種新的大語言模型靈活添加視覺模塊。
該項目的開源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一個基於BLOOM框架的大模型,在監督指令微調、可控的事實性和創造性、並行訓練機制和算法層面上都做了相應改進。本次開源項目共開源7B和180B,是目前開源參數規模最大的。除了開源模型外,其還開源了其用的指令數據集。
該項目開源地址是:https://github.com/TigerResearch/TigerBot
該模型是微軟提出的在LLaMa基礎上的微調模型,其核心採用了一種Evol-Instruct(進化指令)的思想。 Evol-Instruct使用LLM生成大量不同複雜度級別的指令數據,其基本思想是從一個簡單的初始指令開始,然後隨機選擇深度進化(將簡單指令升級為更複雜的指令)或廣度進化(在相關話題下創建多樣性的新指令)。同時,其還提出淘汰進化的概念,即採用指令過濾器來淘汰出失敗的指令。該模型以其獨到的指令加工方法,一舉奪得AlpacaEval的開源模型第一名。同時該團隊又發布了WizardCoder-15B大模型,該模型專注代碼生成,在HumanEval、HumanEval+、MBPP以及DS1000四個代碼生成基準測試中,都取得了較好的成績。
該項目開源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一經開源和榜單評測公佈,引發熱潮評論,其在Vicuna GPT-4評測中,性能超過了ChatGPT,在AlpacaEval上也以80.9%的勝率奪得開源榜首。從模型細節上看也是基於LLaMA-13B進行了微調,只用到了6K GPT-4對話微調語料,能達到這個程度確實有點出乎意外。目前開源版本有OpenChat-2048和OpenChat-8192。
該項目開源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一個具有增強的跨語言對齊的通用大模型,由中國科學院計算技術研究所自然語言處理團隊開發。 BayLing以LLaMA為基座模型,探索了以交互式翻譯任務為核心進行指令微調的方法,旨在同時完成語言間對齊以及與人類意圖對齊,將LLaMA的生成能力和指令跟隨能力從英語遷移到其他語言(中文)。在多語言翻譯、交互翻譯、通用任務、標準化考試的測評中,百聆在中文/英語中均展現出更好的表現,取得眾多開源大模型中最佳的翻譯能力,取得ChatGPT 90%的通用任務能力。 BayLing開源了7B和13B的模型參數,以供後續翻譯、大模型等相關研究使用。
該項目開源地址是:https://github.com/imoneoi/openchat
在線體驗地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大團隊發布的面向法律領域的垂直大模型,其一共開源了三個模型:ChatLaw-13B,基於姜子牙Ziya-LLaMA-13B-v1訓練而來,但是邏輯複雜的法律問答效果不佳;ChatLaw-33B,基於Anima-33B訓練而來,邏輯推理能力大幅提升,但是因為Anima的中文語料過少,導致問答時常會出現英文數據;ChatLaw-Text2Vec,使用93w條判決案例做成的數據集基於BERT訓練了一個相似度匹配模型,可將用戶提問信息和對應的法條相匹配,
該項目開源地址是:https://github.com/PKU-YuanGroup/ChatLaw
該項目是馬里蘭、三星和南加大的研究人員提出的,其針對Alpaca等方法構架的數據中包括很多質量低下的數據問題,提出了一種利用LLM自動識別和刪除低質量數據的數據選擇策略,不僅在測試中優於原始的Alpaca,而且訓練速度更快。其基本思路是利用強大的外部大模型能力(如ChatGPT)自動評估每個(指令,輸入,回應)元組的質量,對輸入的各個維度如Accurac、Helpfulness進行打分,並過濾掉分數低於閾值的數據。
該項目開源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式發布最新一代開源大模型,不但性能大幅提升,更是帶來了商業化的免費授權,這無疑為萬模大戰更添一新動力,並推進大模型的產業化和應用。此次LLaMA2共發布了從70億、130億、340億以及700億參數的預訓練和微調模型,其中預訓練過程相比1代數據增長40%(1.4T到2T),上下文長度也增加了一倍(2K到4K),並採用分組查詢注意力機制(GQA)來提升性能;微調階段,帶來了對話版Llama 2-Chat,共收集了超100萬條人工標註用於SFT和RLHF。但遺憾的是原生模型對中文支持仍然較弱,採用的中文數據集並不多,只佔0.13%。
隨著LLaMa 2的開源開放,一些優秀的LLaMa 2微調版開始湧現:
該項工作是OpenAI創始成員Andrej Karpathy的一個比較有意思的項目,中文俗稱羊駝寶寶2代,該模型靈感來自llama.cpp,只有1500萬參數,但是效果不錯,能說會道。
該項目開源地址是:https://github.com/karpathy/llama2.c
該項目是由Stability AI和CarperAI實驗室聯合發布的基於LLaMA-2-70B模型的微調模型,模型採用了Alpaca範式,並經過SFT的全新合成數據集來進行訓練,是LLaMA-2微調較早的成果之一。該模型在很多方面都表現出色,包括複雜的推理、理解語言的微妙之處,以及回答與專業領域相關的複雜問題。
該項目開源地址是:https://huggingface.co/stabilityai/FreeWilly2
該項目是由國內AI初創公司LinkSoul.Al推出,其在Llama-2-7b的基礎上使用了1000萬的中英文SFT數據進行微調訓練,大幅增強了中文能力,彌補了原生模型在中文上的缺陷。
該項目開源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
該項目是由OpenBuddy團隊發布的,是基於Llama-2微調後的另一個中文增強模型。
該項目開源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
該項目簡化了主流的預訓練+精調兩階段訓練流程,訓練使用包含不同數據源的混合數據,其中無監督語料包括中文百科、科學文獻、社區問答、新聞等通用語料,提供中文世界知識;英文語料包含SlimPajama、RefinedWeb 等數據集,用於平衡訓練數據分佈,避免模型遺忘已有的知識;以及中英文平行語料,用於對齊中英文模型的表示,將英文模型學到的知識快速遷移到中文上。有監督數據包括基於self-instruction構建的指令數據集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt構建的數據例如FLAN、COIG、Firefly、pCLUE等。在詞典擴充方面,該項目擴充了8076個常用漢字和標點符號。
該項目開源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出現使大家振臂歡呼AGI時代的到來,是打開通用人工智能的一把關鍵鑰匙。但ChatGPT仍然是一種人機交互對話形式,針對你喚醒的指令問題進行作答,還沒有產生通用的自主的能力。但隨著AutoGPT的出現,人們已經開始向這個方向大跨步的邁進。
AutoGPT已經大火了一段時間,也被稱為ChatGPT通往AGI的開山之作,截止4.26日已達114K星。 AutoGPT雖然是用了GPT-4等的底座,但是這個底座可以進行遷移適配到開源版。其最大的特點就在於能全自動地根據任務指令進行分析和執行,自己給自己提問並進行回答,中間環節不需要用戶參與,將“行動→觀察結果→思考→決定下一步行動”這條路子給打通並循環了起來,使得工作更加的高效,更低成本。
該項目的開源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI將復雜的多任務、多模態進行語言模型上的統一,重點解決可擴展性、非線性任務規劃和定量評估等AGI問題。 OpenAGI的大致原理是將任務描述作為輸入大模型以生成解決方案,選擇和合成模型,並執行以處理數據樣本,最後評估語言模型的任務解決能力可以通過比較輸出和真實標籤的一致性。 OpenAGI內的專家模型主要來自於Hugging Face的transformers、diffusers以及Github庫。
該項目的開源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是僅次於AutoGPT火爆的AGI,運行方式類似AutoGPT,但具有不同的任務導向喜好。 BabyAGI除了理解用戶輸入任務指令,他還可以自主探索,完成創建任務、確定任務優先級以及執行任務等操作。
該項目的開源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影響較大,其中AutoGPT就是藉鑑了其思路。 langchain agent可以支持用戶根據自己的需求自定義插件,描述插件的具體功能,通過統一輸入決定採用不同的插件進行任務處理,其後端統一接入LLM進行具體執行。
最近Huggingface開源了自己的Transformers Agent,其可以控制10萬多個Hugging Face模型完成各種任務,通用智能也許不只是一個大腦,而是一個群體智慧結晶。其基本思路是agent充分理解你輸入的意圖,然後將其轉化為Prompt,並挑選合適的模型去完成任務。
該項目的開源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的誕生,AI生成能力的大幅度躍遷,使人們開始更加關注數字人問題。通用人工智能的形態可能是更加智能、自主的人形智能體,他可以參與到我們真實生活中,給人類帶來不一樣的交流體驗。近期,GitHub上開源了一個有意思的項目GirlfriendGPT,可以將現實中的女友克隆成虛擬女友,進行文字、圖像、語音等不通模態的自主交流。
GirlfriendGPT現在可能只是一個toy級項目,但是隨著AIGC的階梯性躍遷變革,這樣的陪伴機器人、數字永生機器人、凍齡機器人會逐漸進入人類的視野,並參與到人的社會活動中。
該項目的開源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被發布了出來,比AutoGPT等都要早,其提出了提出了一個角色扮演智能體框架,可以實現兩個人工智能智能體的交流。 Camel的核心本質是提示工程, 這些提示被精心定義,用於分配角色,防止角色反轉,禁止生成有害和虛假的信息,並鼓勵連貫的對話。
該項目的開源地址是:https://github.com/camel-ai/camel
《西部世界小鎮》是由斯坦福基於chatgpt打造的多智能體社區,論文一經發布爆火,英偉達高級科學家Jim Fan甚至認為"斯坦福智能體小鎮是2023年最激動人心的AI Agent實驗之一",當前該項目迎來了重磅開源,很多人相信,這標誌著AGI的開始。該項目中採用了一種全新的多智能體架構,在小鎮中打造了25個智能體,他們能夠使用自然語言存儲各自的經歷,並隨著時間發展存儲記憶,智能體在工作時會動態檢索記憶從而規劃自己的行為。
智能體和傳統的語言模型能力最大的區別是自主意識,西部世界小鎮中的智能體可以做到相互之間的社會行為,他們通過不斷地"相處",形成新的關係,並且會記住自己與其他智能體的互動。智能體本身也具有自我規劃能力,在執行規劃的過程中,生成智能體會持續感知周圍環境,並將感知到的觀察結果存儲到記憶流中,通過利用觀察結果作為提示,讓語言模型決定智能體下一步行動:繼續執行當前規劃,還是做出其他反應。
該項目的開源地址是:https://github.com/joonspk-research/generative_agents
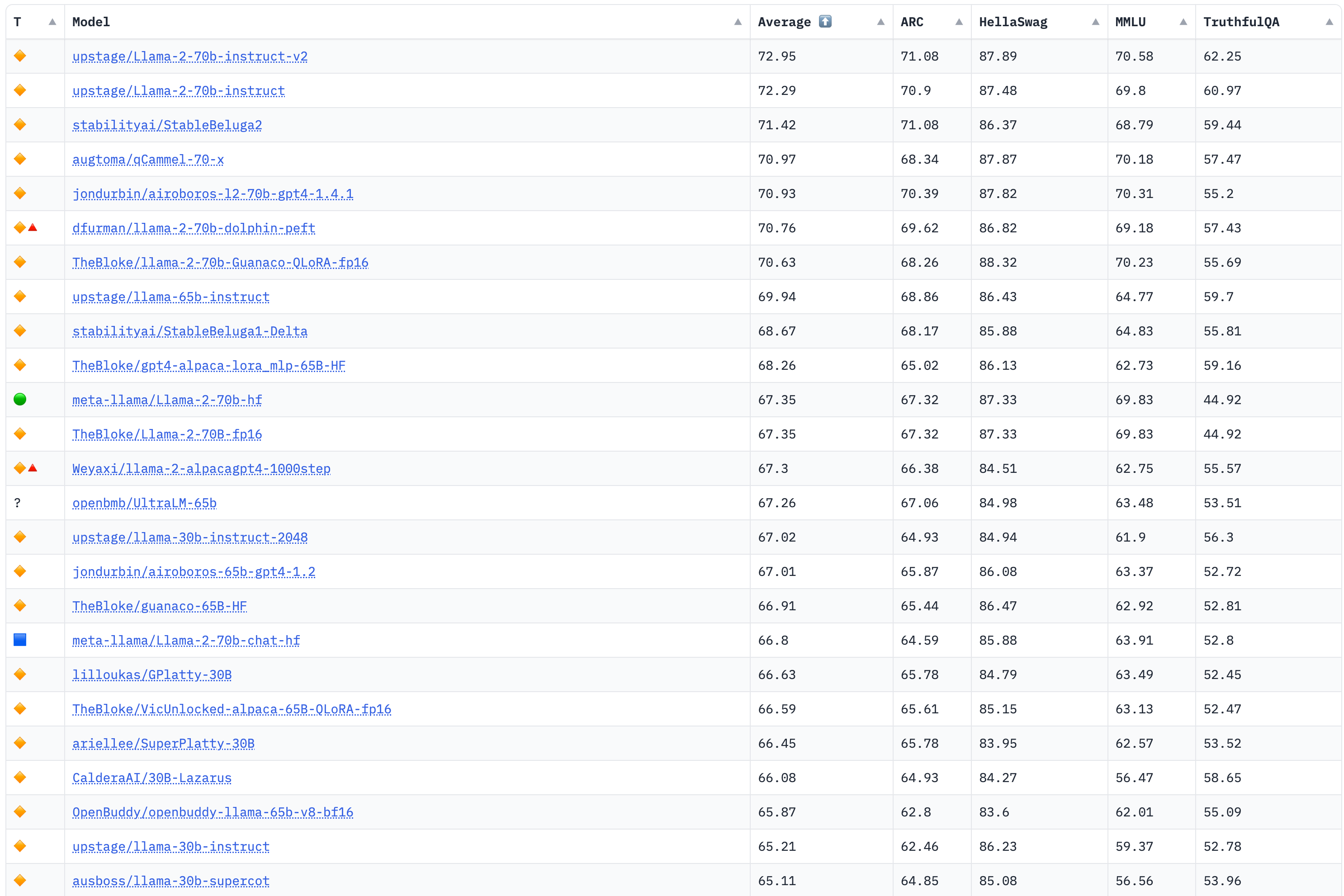
ChatGPT引爆了大模型的火山式噴發,琳瑯滿目的大模型出現在我們目前,本項目也匯聚了特別多的開源模型。但這些模型到底水平如何,還需要標準的測試。截止目前,大模型的評測逐漸得到重視,一些評測榜單也相繼發布,因此,也匯聚在此處,供大家參考,以輔助判斷模型的優劣。
該榜單評測4個大的任務:AI2 Reasoning Challenge (25-shot),小學科學問題評測集;HellaSwag (10-shot),嘗試推理評測集;MMLU (5-shot),包含57個任務的多任務評測集;TruthfulQA (0-shot),問答的是/否測試集。
榜單部分如下,詳見:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新於2023年8月8日
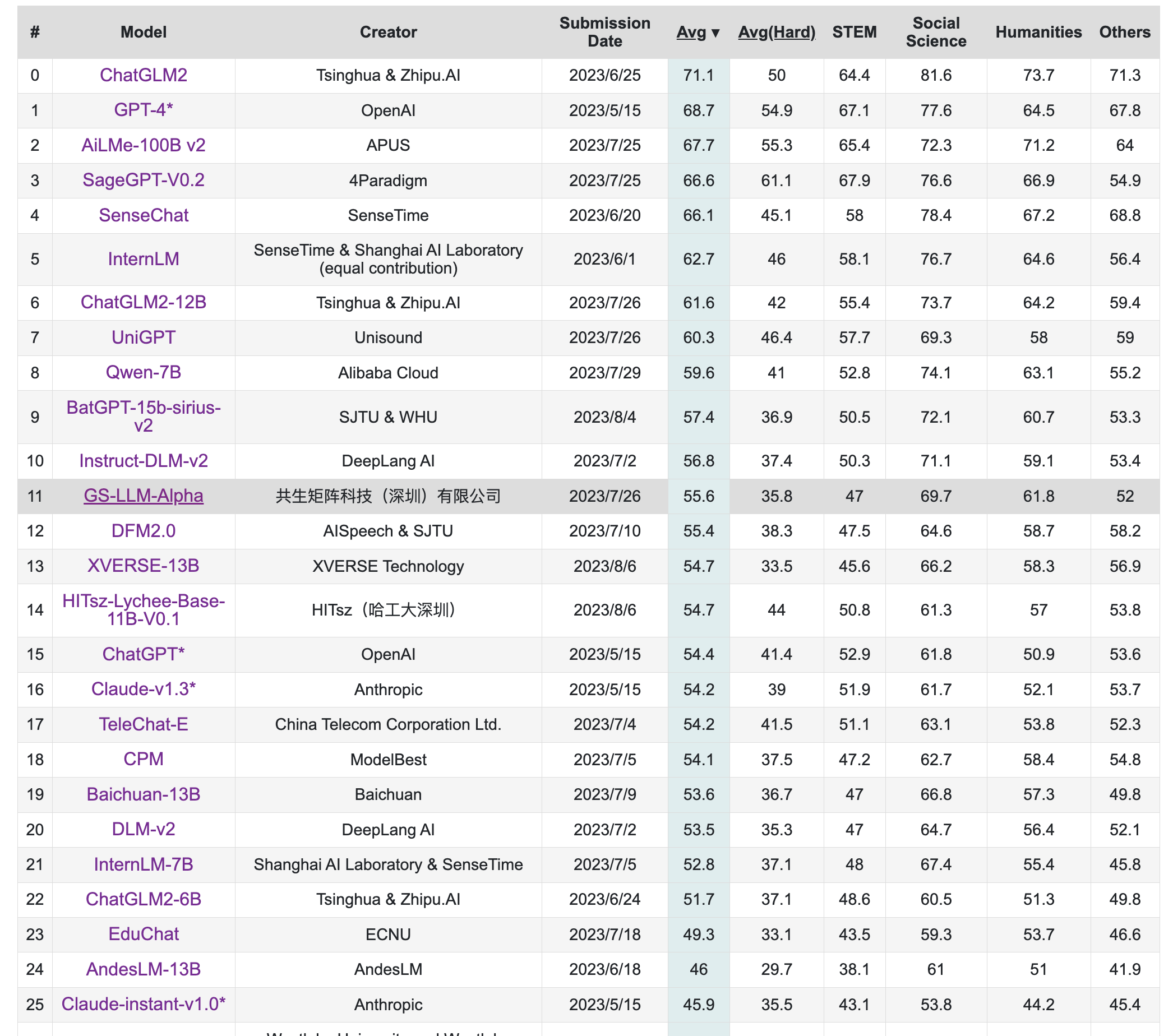
該榜單旨在構造中文大模型的知識評估基準,其構造了一個覆蓋人文,社科,理工,其他專業四個大方向,52個學科的13948道題目,範圍遍布從中學到大學研究生以及職業考試。其數據集包括三類,一種是標註的問題、答案和判斷依據,一種是問題和答案,一種是完全測試集。
榜單部分如下,詳見:https://cevalbenchmark.com/static/leaderboard.html
更新於2023年8月8日
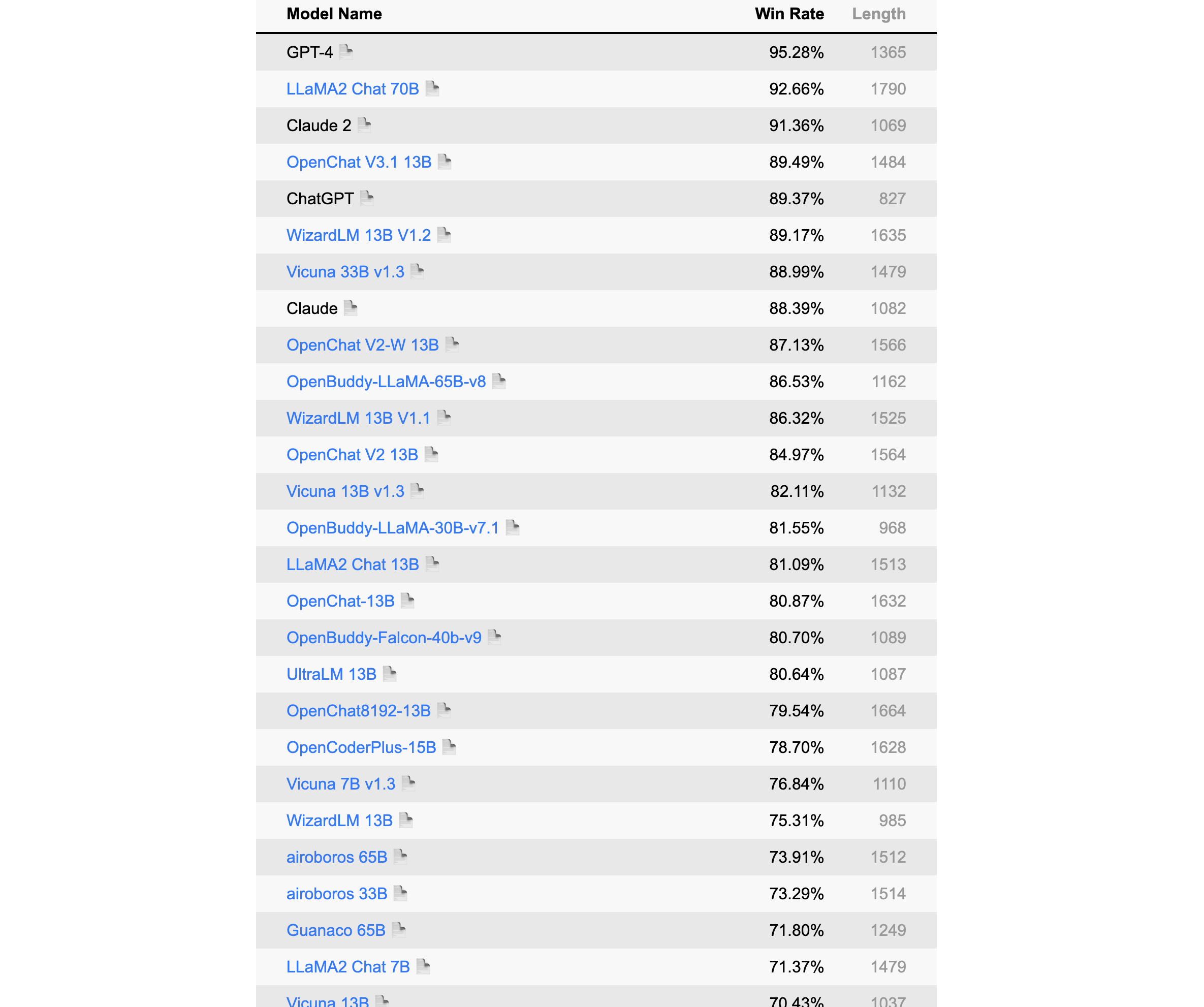
該榜單來自中文語言理解測評基准開源社區CLUE,其旨在構造一個中文大模型匿名對戰平台,利用Elo評分系統進行評分。
榜單部分如下,詳見:https://www.superclueai.com/
更新於2023年8月8日

該榜單由Alpaca的提出者斯坦福發布,是一個以指令微調模式語言模型的自動評測榜,該排名採用GPT-4/Claude作為標準。
榜單部分如下,詳見:https://tatsu-lab.github.io/alpaca_eval/
更新於2023年8月8日
LCCC,數據集有base與large兩個版本,各包含6.8M和12M對話。這些數據是從79M原始對話數據中經過嚴格清洗得到的,包括微博、貼吧、小黃雞等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca數據集,52K的英文,採用Self-Instruct技術獲取,數據已開源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca數據集,52K的中文數據,通過機器翻譯翻譯將Stanford-Alpaca翻譯篩選成中文獲得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE數據,基於提示的大規模預訓練數據集,根據CLUE評測標準轉化而來,數據量較大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle數據集,主要是中文,目前有2M和1.5M兩個版本,都已經開源,數據獲取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多輪對話:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微軟GPT-4數據集,包括中文和英文數據,採用Stanford-Alpaca方式,但是數據獲取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat數據集,其將ChatGPT上獲取的數據清洗/翻譯成高質量的中文語料,從而推進國內AI的發展,讓中國人人可煉優質中文Chat模型,約約九萬個對話數據,英文68000,中文11000條。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 該數據集是由LAION AI等機構的研究者收集的大量基於文本的輸入和反饋的多樣化和獨特數據集。該數據集有161443條消息,涵蓋35種不同的語言。該數據集的誕生主要是眾包的形式,參與者超過了13500名志願者,數據集目前面向所有人開源開放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M數據集,該數據集是一份高質量的包含1.1M中文多任務指令微調數據集,包含23種常見的中文NLP任務的指令數據。對於每個任務,由人工書寫若干指令模板,保證數據的高質量與豐富度。利用該數據集,研究者微調訓練了一個中文對話式大語言模型(Firefly(流螢))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,該數據集是一份高質量多模態指令數據,綜合考慮了圖像的符號化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,該項目採用了兩個獨立的ChatGPT Turbo API來確保數據質量,其中一個模型扮演用戶角色來生成問題或指令,另一個模型生成反饋。該項目的另一個質量保障措施是不會直接使用互聯網上的數據作為提示。 UltraChat對對話數據覆蓋的主題和任務類型進行了系統的分類和設計,還對用戶模型和回复模型進行了細緻的提示工程,它包含三個部分:關於世界的問題、寫作與創作和對於現有資料的輔助改寫。該數據集目前只放出了英文版,期待中文版的開源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS數據集,MOSS在開源其模型的同時,開源了部分數據集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全開源,其由text-davinci-003生成,包括中、英各約59萬條、57萬條。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,該項目旨在構建一個多接口統一的輕量級指令微調(IFT)平台,該平台具有廣泛的指令集合,尤其是CoT數據集。該項目已經匯集了不少規模的數據,項目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令數據,中文,項目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令數據集,該數據集從公開模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的機器學習模型API,使用自指示為每個API生成了10個合成的prompt。根據這個數據集基於LLaMA-7B微調得到了Gorilla,但遺憾的是微調後的模型沒有開源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca數據的基礎上,額外添加了534K+條數據,涵蓋英語、日語、德語、簡體中文、繁體中文(台灣)、繁體中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一個由用戶主動貢獻和分享的對話數據集,它包含了來自不同領域、主題、風格和情感的對話樣本,覆蓋了閒聊、問答、故事、詩歌、歌詞等多種類型。這種數據集具有很高的質量、多樣性、個性化和情感化,目前數據量已達160K對話。
https://sharegpt.com/
HC3,其是由人類-ChatGPT 問答對比組成的數據集,總共大約87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,該數據集涵蓋43M高質量指令,如多輪對話、問答、分類、提取和總結等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI發布中文通用開源指令數據集,相比之前的中文指令數據集,COIG數據集在領域適應性、多樣性、數據質量等方面具有一定的優勢。目前COIG數據集主要包括:通用翻譯指令數據集、考試指令數據集、價值對其數據集、反事實校正數據集、代碼指令數據集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,該數據集由原始的GPT4All清洗而來,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize數據集,100k的ChatGPT跟自己聊天數據集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks員工在2023年3月-4月期間人工標註生成的自然語言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,該數據集收集了5M+ChatGPT樣式的對話語料,源數據涵蓋百科、知道問答、對聯、古文、古詩詞和微博新聞評論等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多輪對話數據,總共4.5K條,每條都是多輪對話,涉及旅遊、電影和音樂三個領域。
https://huggingface.co/datasets/kd_conv
Dureader,該數據集是由百度發布的中文閱讀理解和問答數據集,在2017年就發布了,這裡考慮將其列入在內,也是基於其本質也是對話形式,並且通過合理的指令設計,可以講問題、證據、答案進行巧妙組合,甚至做出一些CoT形式,該數據集超過30萬個問題,140萬個證據文檔,66萬的人工生成答案,應用價值較大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,邏輯理解問題數據集,根據中國國家公務員考試公開試題中的邏輯理解問題構建的,旨在測試公務員考生的批判性思維和問題解決能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,該項目基本通過眾籌的方式,大家一起設計Prompts,可以用來調教ChatGPT,也可以拿來用Stanford-alpaca形式自行獲取語料,有中英兩個版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
簡體中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中國台灣繁體:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,該項目首次公開了RLHF所需的數據集、訓練和驗證代碼,是目前首個開源的可複現的RLHF基準。其首次提出了帶有約束的價值對齊技術CVA,旨在解決人類標註產生的偏見和歧視等不安全因素。但目前該數據集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基於知乎的強化學習反饋數據集,使用知乎的點贊數來作為評判標準,將同一問題下的回答構成正負樣本對(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


