FindTheChatGPTer
1.0.0
Resumo do Chatgpt/GPT4 de código aberto "Substituição simples", atualização contínua
O ChatGPT se tornou popular e muitas universidades domésticas, instituições de pesquisa e empresas emitiram planos de liberação semelhantes ao ChatGPT. O ChatGPT não é de código aberto e é extremamente difícil de reproduzir. Mesmo agora, nenhuma unidade ou empresa reproduziu todos os recursos do GPT3. Agora, o OpenAI anunciou oficialmente o lançamento do modelo GPT4 com gráficos e texto multimodais, e seus recursos foram bastante aprimorados em comparação com o ChatGPT. Parece que cheira a quarta revolução industrial dominada pela inteligência artificial geral.
Seja no exterior ou em casa, a lacuna entre o Openai está ficando cada vez maior, e todo mundo está alcançando de uma maneira ocupada, então eles estão em uma certa posição vantajosa nessa inovação tecnológica. Atualmente, a pesquisa e o desenvolvimento de muitas grandes empresas estão basicamente seguindo a rota de código fechado. Existem poucos detalhes divulgados oficialmente pelo ChatGPT e GPT4, e não é como a introdução anterior do artigo que introduziu dezenas de páginas, chegou a era da comercialização do OpenAI. Obviamente, algumas organizações ou indivíduos exploraram substituições de código aberto. Este artigo está resumido da seguinte forma. Vou continuar a rastreá -los. Existem substituições atualizadas de código aberto para atualizar este local em tempo hábil.
Esse tipo de método adota principalmente o não-LLAMA e outros métodos de ajuste fino para projetar ou otimizar independentemente os modelos GPT e T5 e realiza processos de ciclo total, como aprendizado de pré-treinamento, ajuste fino e reforço.
Chatyuan (Yuanyu AI) é desenvolvido e publicado pela equipe de desenvolvimento inteligente de Yuanyu. Ele afirma ser o primeiro modelo de diálogo funcional na China. Pode escrever artigos, fazer lição de casa, escrever poesia e traduzir chinês e inglês; Algumas áreas específicas, como leis, também podem fornecer informações relevantes. Atualmente, este modelo suporta apenas chinês, e o link do GitHub é:
https://github.com/clue-ai/chatyuan
A julgar pelos detalhes técnicos divulgados, a camada subjacente adota um modelo T5 com uma escala de 700 milhões de parâmetros e supervisiona e tunes fina com base no PromptClue para formar o Chatyuan. Esse modelo é basicamente a primeira etapa da rota técnica ChatGPT em três etapas, e nenhum treinamento de modelo de recompensa e treinamento de aprendizado de reforço de PPO são implementados.
Recentemente, o Colossalai Open Source sua implementação do ChatGPT. Compartilhe sua estratégia em três etapas e implemente totalmente a rota técnica do ChatGPT Core: seu github é o seguinte:
https://github.com/hpcaitech/colossalai
Com base neste projeto, esclareci a estratégia de três etapas e o compartilhei:
A primeira etapa (STAGE1_SFT.PY): O estágio de ajuste fino de supervisão da SFT, o projeto de código aberto não foi implementado, isso é relativamente simples porque Colossalai suporta perfeitamente o HuggingFace. Eu uso diretamente algumas linhas de código de função de treinador do Huggingface para implementá -la facilmente. Aqui usei um modelo GPT2. Do seu ponto de vista da implementação, ele suporta modelos GPT2, OPT e Bloom;
O segundo estágio (STAPE2_RM.PY): o estágio de treinamento do Modelo de Recompensa (RM), ou seja, a parte de Train_reward_model.py nos exemplos do projeto;
O terceiro estágio (STAPE3_PPO.PY): estágio de aprendizado de reforço (RLHF), ou seja, Project Train_prompts.py
A execução dos três arquivos precisa ser colocada no projeto Colossalai, onde os núcleos do código são chatgpt no projeto original, e núcleos.nn se torna chatgpt.models no projeto original.
O ChatGlm é um modelo de diálogo da série GLM de Zhipu AI, uma empresa que transforma as realizações tecnológicas em Tsinghua, suporta idiomas chineses e ingleses e atualmente possui seu modelo de parâmetros de 6,2 bilhões. Ele herda as vantagens do GLM e otimiza a arquitetura do modelo, reduzindo assim o limite para implantação e aplicação, realizando a aplicação de inferência de grandes modelos em placas de gráficos de consumo. Para técnicas detalhadas, consulte o seu github:
O endereço de código aberto do ChatGlm-6b é: https://github.com/thudm/chatglm-6b
Do ponto de vista técnico, implementou a aprendizagem reforçada do ChatGPT sobre a estratégia de alinhamento humano, tornando o efeito da geração melhor e mais próximo do valor humano. Suas áreas de habilidade atuais incluem principalmente autoconhor, redação, redação, assistente de escrita por email, extração de informações, interpretação de papéis, comparação de comentários, conselhos de viagem etc. Ele desenvolveu um modelo de 130 bilhões de super grande porte em teste interno, que é considerado um modelo de diálogo com uma escala de parâmetros maior na atual substituição de código aberto.
VisualGLM-6B (atualizado em 19 de maio de 2023)
A equipe abriu recentemente a versão multimodal do ChatGLM-6B, que suporta diálogo multimodal em imagens, chinês e inglês. A parte do modelo de idioma usa o ChatGLM-6b, e a parte da imagem constrói uma ponte entre o modelo visual e o modelo de idioma, treinando o blip2-Qformer. O modelo geral possui um total de 7,8 bilhões de parâmetros. O VisualGLM-6B depende de pares gráficos chineses de 30m de alta qualidade do conjunto de dados do CogView e é pré-treinado com pares gráficos ingleses filtrados de 300 m, com o mesmo peso em chinês e inglês. Esse método de treinamento alinha melhor as informações visuais ao espaço semântico do ChatGLM; No estágio subsequente de ajuste fino, o modelo é treinado em longos dados visuais de perguntas e respostas para gerar respostas que atendem às preferências humanas.
O endereço de código aberto do VisualGLM-6B é: https://github.com/thudm/visualglm-6b
Chatglm2-6b (atualizado em 27 de junho de 2023)
A equipe abriu recentemente a versão de segunda geração do ChatGlm, Chatglm2-6b. Comparado com a versão de primeira geração, seus principais recursos incluem o uso de uma escala de dados maior, de 1T a 1.4T; O mais proeminente é seu suporte de contexto mais longo, que se expandiu de 2k para 32k, permitindo rodadas mais longas e mais altas de entradas; Além disso, a velocidade de inferência foi bastante otimizada, um aumento de 42%e os recursos de memória de vídeo ocupados foram bastante reduzidos.
O endereço de código aberto ChatGlm2-6b é: https://github.com/thudm/chatglm2-6b
É conhecido como o primeiro projeto de substituição de chatgpt de código aberto, e sua idéia básica é baseada na arquitetura do Big Model Palm do Google Language e no uso de métodos de aprendizado de reforço (RLHF) do feedback humano. O Palm é um modelo de parâmetro de 540 bilhões de parâmetros lançado pelo Google em abril deste ano, com base no treinamento do sistema de caminhos. Ele pode concluir tarefas como escrever código, bate-papo, entendimento do idioma etc. e possui um poderoso desempenho de aprendizado de baixa amostra na maioria das tarefas. Ao mesmo tempo, é adotado o mecanismo de aprendizado de reforço do tipo ChatGPT, o que pode tornar as respostas da IA mais alinhadas com os requisitos de cenário e reduzir a toxicidade do modelo.
O endereço do github é: https://github.com/lucidrains/palm-rlhf-pytorch
O projeto é conhecido como o maior modelo de código aberto, até 1,5 trilhão, e é um modelo multimodal. Seus domínios de habilidade incluem entendimento da linguagem natural, tradução da máquina, perguntas e respostas inteligentes, análise de sentimentos e correspondência gráfica, etc. Seu endereço de código aberto é:
https://huggingface.co/banana-dev/gptrillion
(Em 24 de maio de 2023, este projeto é um programa de piada do April Fools. O projeto foi excluído. Vou explicar isso por meio deste
O OpenFlamingo é uma estrutura que compara o GPT-4 e suporta treinamento e avaliação de modelos multimodais em larga escala. Foi lançado por Laion sem fins lucrativos e é uma reprodução do modelo Flamingo de DeepMind. Atualmente, o Open Source é seu modelo OpenFlamingo-9B baseado em LLAMA. O modelo Flamingo é treinado em um corpus de rede em larga escala, contendo texto e imagens entrelaçados e tem a capacidade de aprender amostras limitadas por contexto. O OpenFlamingo implementa a mesma arquitetura proposta no Flamingo original, treinada em amostras de 5m de um novo conjunto de dados C4 multimodal e amostras de 10m do laion-2b. O endereço de código aberto deste projeto é:
https://github.com/mlfoundations/open_flamingo
Em 21 de fevereiro deste ano, a Fudan University lançou Moss e abriu a beta pública, o que causou alguma controvérsia após o colapso do beta público. Agora, o projeto inaugurou atualizações importantes e código aberto. O musgo de código aberto suporta idiomas chineses e ingleses e suporta a inalização de plug, como resolver equações, pesquisa etc. Os parâmetros são 16b e pré-treinados em cerca de 700 bilhões de palavras chinesas e inglesas e código. As instruções de diálogo subsequentes são ajustadas, aprendizado aprimorado e treinamento de preferência humana, com várias rodadas de recursos de diálogo e a capacidade de usar vários plug-ins. O endereço de código aberto deste projeto é:
https://github.com/openlmlab/moss
Semelhante ao Minigpt-4 e LLAVA, é um modelo multimodal de código aberto benchmarking GPT-4, que continua a idéia de treinamento modular da série MPLUG. Atualmente, ele abre o modelo de quantidade de parâmetros 7B e, ao mesmo tempo, propõe um conjunto de testes abrangente Owleval pela primeira vez para o entendimento da instrução relacionada ao visual. Através da avaliação manual, os modelos existentes, incluindo LLAV, Minigpt-4 e outros trabalhos, demonstram melhores recursos multimodais, especialmente na capacidade de compreensão de instruções multimodais, capacidade de diálogo multi-rodada, capacidade de raciocínio de conhecimento, etc. É lamentável que outros modelos de origem e textos ainda suportem o inglês, mas a versão chinesa já está na lista de fontes abertas.
O endereço de código aberto deste projeto é: https://github.com/x-plug/mplug-owl
O Pandalm é um modelo de avaliação de modelo que visa avaliar automaticamente as preferências de outros modelos de larga escala para gerar conteúdo, economizando custos de avaliação manual. O Pandalm vem com uma interface da Web para análise e também suporta chamadas de código Python. Ele pode avaliar o texto gerado por qualquer modelo e dados com apenas três linhas de código, o que é muito conveniente de usar.
O endereço de código aberto do projeto é: https://github.com/weopenml/pandalm
Na conferência Zhiyuan, realizada recentemente, o Zhiyuan Research Institute abriu a fonte de seu modelo Iluminismo e Sky Eagle, que possui conhecimento bilíngue de chinês e inglês. Os parâmetros do modelo básico da versão de código aberto incluem 7 bilhões e 33 bilhões. Ao mesmo tempo, abre o modelo de diálogo Aquilachat e o modelo de geração de código de texto de quilacode, e ambos foram abertos para licenças comerciais. Aquila adota arquiteturas somente para decodificadores, como GPT-3 e Llama, e também atualiza o vocabulário do bilinguismo chinês e inglês e adota seu método de treinamento acelerado. Sua garantia de desempenho não depende apenas da otimização e melhoria do modelo, mas também se beneficia do acúmulo de dados de alta qualidade por Zhiyuan em modelos grandes nos últimos anos.
O endereço de código aberto do projeto é: https://github.com/flagai-open/flagai/tree/master/examples/aquila
Recentemente, a Microsoft publicou um grande papel modelo multimodal e o código-fonte aberto -Codi, que conecta completamente o texto-voz-video-video, suporta entrada arbitrária e saída modal arbitrária. Para alcançar a geração de modalidades arbitrárias, os pesquisadores dividiram o treinamento em dois estágios. Na primeira etapa, o autor usou a estratégia de alinhamento da ponte e condições combinadas para treinar, criando um potencial modelo de difusão para cada modo; No segundo estágio, um módulo de atenção de interseção foi adicionado a cada modelo de difusão potencial e ao codificador ambiental, o que poderia projetar as variáveis latentes do modelo de difusão potencial no espaço compartilhado, para que as modalidades geradas fossem ainda mais diversificadas.
O endereço de código aberto deste projeto é: https://github.com/microsoft/i-code/tree/main/i-code-v3
A Meta lançou e o Open de seu Big Model multimodal ImageBind, que pode obter cruzamento de 6 modalidades, incluindo imagem, vídeo, áudio, profundidade, calor e movimento espacial. O ImageBind resolve o problema de alinhamento usando as características de ligação das imagens, usando grandes modelos de linguagem visual e recursos de amostra zero para expandir para novas modalidades. Os dados de emparelhamento de imagens são suficientes para unir esses seis modos, permitindo que diferentes modos abrem divisões modais uma da outra.
O endereço de código aberto do projeto é: https://github.com/facebookresearch/imagebind
Em 10 de abril de 2023, a Wang Xiaochuan anunciou oficialmente o estabelecimento da empresa de modelos da AI Big "Baichuan Intelligence", com o objetivo de criar uma versão chinesa do OpenAI. Dois meses após o seu estabelecimento, a Baichuan Intelligent criou uma importante fonte de seu modelo Baichuan-7b desenvolvido independentemente, apoiando chinês e inglês. O Baichuan-7b não apenas supera outros grandes modelos, como o ChatGLM-6B, com vantagens significativas na lista de avaliação de autorização chinesa C-Eval, Agieval e Gaokao, mas também leva significativamente o LLAMA-7B na lista de avaliação autoritativa do MMLU em inglês. Este modelo atinge uma escala de trilhões de token em dados de alta qualidade e suporta a capacidade de expansão de dezenas de milhares de janelas dinâmicas ultra-longas com base em otimização eficiente do operador de atenção. Atualmente, o código aberto suporta recursos de contexto 4K. Este modelo de código aberto está disponível comercialmente e é mais amigável que a lhama.
O endereço de código aberto do projeto é: https://github.com/baichuan-inc/baichuan-7b
Em 6 de agosto de 2023, a equipe Yuanxiang Xverse abriu o modelo Xverse-13B. Este modelo é um modelo grande multilíngue que suporta até 40 idiomas e suporta comprimento contextual de até 8192. Segundo a equipe, os recursos deste modelo são: estrutura do modelo: Xverse-13b usa o mainstream decodificador e pode atender às necessidades de necessidades, suporta 8K de comprimento de contexto, que é o mais longo, e pode atender às necessidades; Dados de treinamento: 1,4 trilhão de tokens de dados de alta qualidade e diversos são construídos para treinar completamente o modelo, incluindo 40 chinês, inglês, russo e oeste. Vários idiomas, definindo finamente a taxa de amostragem de diferentes tipos de dados, os idiomas chineses e ingleses têm um bom desempenho e também podem levar em consideração os efeitos de outros idiomas; Segmentação de palavras: Com base no algoritmo BPE, uma segmentação de palavras com um tamanho de vocabulário de 100.278 foi treinada usando centenas de corpus GB, que podem suportar vários idiomas ao mesmo tempo sem expansão adicional da lista de palavras; Estrutura de treinamento: desenvolveu independentemente várias tecnologias-chave, incluindo operadores eficientes, otimização de memória de vídeo, estratégias de agendamento paralelo, sobreposição de dados de computação de dados, colaboração de plataforma e estrutura, etc., tornando a eficiência do treinamento mais alta e a estabilidade do modelo forte. A taxa de utilização de potência de pico de computação no cluster Kilocard pode atingir 58,5%, classificando -se entre a vanguarda do setor.
O endereço de código aberto deste projeto é: https://github.com/xverse-ai/xverse-13b
Em 3 de agosto de 2023, o modelo de 7 bilhões de 7 bilhões de Alibaba Tongyi Qianwen era de código aberto, incluindo modelos gerais e modelos de diálogo, e é de código aberto, gratuito e comercialmente disponível. Segundo relatos, o QWEN-7B é um modelo de idioma grande baseado no transformador e é treinado em dados de pré-treinamento em escala super grande. Os tipos de dados de pré-treinamento são diversos e cobrem uma ampla gama de áreas, incluindo um grande número de textos on-line, livros profissionais, códigos etc. É um modelo de dock que suporta os idiomas chineses e ingleses, treinados em mais de 2 trilhões de dados de token, e o comprimento da janela de contexto atinge 8k. QWEN-7B-CHAT é um modelo de diálogo chinês-inglês baseado no modelo de pedestal QWEN-7B. O modelo pré-treinado de Tongyi Qianwen 7B teve um bom desempenho em várias avaliações de referência autorizadas. Suas capacidades chinesas e inglesas excedem em muito os modelos de código aberto da mesma escala em casa e no exterior, e alguns recursos excederam os modelos de código aberto de tamanhos 12B e 13B.
O endereço de código aberto do projeto é: https://github.com/qwenlm/qwen-7b
A LLAMA é um novo modelo de linguagem de inteligência artificial em larga escala lançado pela Meta, que tem um bom desempenho em tarefas como gerar texto, diálogo, resumir materiais escritos, provando teoremas matemáticos ou previsão de estruturas proteicas. O modelo LLAMA suporta 20 idiomas, incluindo idiomas alfabéticos latinos e cirílicos. Atualmente, o modelo original não suporta chinês. Pode-se dizer que o vazamento épico de lhama promoveu vigorosamente o desenvolvimento de código aberto do tipo ChatGPT.
(Atualizado em 22 de abril de 2023) Mas, infelizmente, a autorização da LLAMA é atualmente limitada e só pode ser usada para pesquisa científica e não é permitida para uso comercial. Para resolver o problema comercial de código aberto totalmente, o projeto Redpajama surgiu, com o objetivo de criar uma réplica de llama totalmente aberta que possa ser usada para aplicações comerciais e fornecer um processo mais transparente para a pesquisa. O Redpajama completo inclui um conjunto de dados de 1,2 trilhão de token, e seu próximo passo será iniciar o treinamento em larga escala. Este trabalho ainda vale a pena esperar, e seu endereço de código aberto é:
https://github.com/togethercomputer/redpajama-data
(Atualizado em 7 de maio de 2023)
A Redpajama atualizou seu arquivo de modelo de treinamento, incluindo dois parâmetros: 3b e 7b, onde 3b pode ser executado na placa gráfica RTX2070 Gaming lançada há 5 anos, compensando a lacuna no llama no 3B. Seu endereço de modelo é:
https://huggingface.co/togethercomputer
Além do Redpajama, o MosaicML lançou o modelo da série MPT, e seus dados de treinamento usam dados Redpajama. Em várias avaliações de desempenho, o modelo 7B é comparável à llama original. O endereço de código aberto de seu modelo é:
https://huggingface.co/mosaicml
Seja Redpajama ou MPT, também de código aberto o modelo de versão de bate -papo correspondente. O código aberto desses dois modelos trouxe um grande impulso à comercialização do ChatGPT.
(Atualizado em 1 de junho de 2023)
O Falcon é uma grande base de modelos abertos que compara Llama. Possui duas escalas de medição de parâmetros: 7b e 40b. O desempenho de 40b é conhecido como a llama ultra-alta de 65b. Entende -se que o Falcon ainda usa o modelo de decodificador autoregressivo GPT, mas se esforçou muito nos dados. Depois de raspar o conteúdo da rede pública e criar o conjunto de dados pré-elaborado inicial, ele usa o CommonCrawl Dump para executar filtragem em larga escala e desduplicação em larga escala e, finalmente, obtém um enorme conjunto de dados pré-traido composto por quase 5 trilhões de tokens. Ao mesmo tempo, muitos corpus selecionados foram adicionados, incluindo documentos de pesquisa e conversas de mídia social. No entanto, a autorização do projeto tem sido controversa, e o método de autorização "semi-comercial" é adotado e 10% das despesas comerciais começarão a ocorrer após a renda atingir 1 milhão.
O endereço de código aberto do projeto é: https://huggingface.co/tiiuae
(Atualizado em 3 de julho de 2023)
O Falcon original não possui recursos de apoio chineses como a LLAMA. A equipe do projeto "Linly" construiu e abriu a versão chinesa do Falcon chinês com base no modelo Falcon. O modelo expandiu e expandiu bastante a lista de vocabulários, incluindo 8701 caracteres chineses comumente usados, as primeiras 20.000 palavras chinesas de alta frequência na lista de vocabulário de Jieba e 60 marcas de pontuação chinesa. Após a desduplicação, o tamanho da lista de vocabulário foi expandido para 90.046. Durante a fase de treinamento, foram utilizados 50G corpus e 2T dados em larga escala para treinamento.
O endereço de código aberto do projeto é: https://github.com/cvi-szu/linly
(Atualizado em 24 de julho de 2023)
O Falcon original não possui recursos de apoio chineses como a LLAMA. A equipe do projeto "Linly" construiu e abriu a versão chinesa do Falcon chinês com base no modelo Falcon. O modelo expandiu e expandiu bastante a lista de vocabulários, incluindo 8701 caracteres chineses comumente usados, as primeiras 20.000 palavras chinesas de alta frequência na lista de vocabulário de Jieba e 60 marcas de pontuação chinesa. Após a desduplicação, o tamanho da lista de vocabulário foi expandido para 90.046. Durante a fase de treinamento, foram utilizados 50G corpus e 2T dados em larga escala para treinamento.
O endereço de código aberto do projeto é: https://github.com/cvi-szu/linly
O Alpaca (modelo Alpaca) lançado por Stanford é um novo modelo baseado no modelo LLAMA-7B. O princípio básico é permitir que o modelo de texto-davinci-003 do OpenAI seja gerar amostras de instrução de 52 mil de maneira auto-estruturada para ajustar a lhama. O projeto abriu dados de treinamento de origem, código para gerar dados de treinamento e hiperparâmetros. O arquivo de modelo ainda não foi aberto, atingindo mais de 5,6 mil estrelas em um dia. Este trabalho é muito popular devido ao seu baixo custo e fácil acesso de dados e também abriu o caminho para a imitação do chatgpt de baixo custo. Seu endereço do GitHub é:
https://github.com/tatsu-lab/stanford_alpaca
É uma implementação de código aberto do llama+ai chatbot com base no aprendizado de reforço de feedback humano lançado pelo Nebuly+AI. Sua rota técnica é semelhante ao chatgpt. O projeto acaba de ser lançado por 2 dias e venceu 5,2 mil estrelas. Seu endereço do GitHub é:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/acceleate/chatllama
O algoritmo do processo de treinamento de chatllama é usado principalmente para obter treinamento mais rápido e mais barato que o chatgpt. Diz -se que é quase 15 vezes mais rápido. Os principais recursos são:
Uma implementação completa de código aberto permite que os usuários criem serviços de estilo ChatGPT com base em modelos de llama pré-treinados;
A arquitetura de llama é menor, tornando o processo de treinamento e raciocínio mais rápido e menos onero;
Suporte interno para o DeepSpeed Zero para acelerar o processo de ajuste fino;
Suporta arquiteturas de modelos de llama de vários tamanhos, e os usuários podem ajustar o modelo de acordo com suas próprias preferências.
O OpenChatkit é criado em conjunto pela equipe de juntas, onde estão localizados ex -pesquisadores do Openai, bem como as equipes de Laion e Ontocord.ai. O OpenChatkit contém 20 bilhões de parâmetros e é ajustado com a versão de código aberto do GPT-3 GPT-NOX-20B. Ao mesmo tempo, aprendizado de reforço diferente dos ChatGPTs, o OpenChatkit usa um modelo de auditoria de parâmetros de 6 bilhões para filtrar informações inadequadas ou prejudiciais para garantir a segurança e a qualidade do conteúdo gerado. Seu endereço do GitHub é:
https://github.com/togethercomputer/openchatkit
Com base em Stanford Alpaca, o ajuste fino supervisionado é realizado com base em Bloom e Llama. As tarefas de sementes de Stanford Alpaca são todas em inglês e os dados coletados também estão em inglês. Este projeto de código aberto é promover o desenvolvimento da comunidade de código aberto de diálogo chinês. Foi otimizado para chinês. O ajuste do modelo usa apenas dados produzidos pelo ChatGPT (sem incluir outros dados). O projeto contém o seguinte:
175 missões de sementes chinesas
Código para gerar dados
Atualmente, os dados gerados por 10m são de origem aberta com 1,5 m e 0,25 milhões de dados de instruções matemáticas e conjuntos de dados de diálogo de tarefas de várias rodadas.
Modelo otimizado com base no Bloomz-7B1-MT e LLAMA-7B
O endereço do github é: https://github.com/lianjiatech/belle
Alpaca-Lora é outra obra-prima da Universidade de Stanford. Ele usa a tecnologia LORA (adaptação de baixo rank) para reproduzir os resultados da ALPACA, usando um método de menor custo, e treinado apenas em uma placa de gráfico RTX 4090 por 5 horas para obter um modelo com um nível de ALPACA. Além disso, o modelo pode ser executado em um Raspberry Pi. Neste projeto, ele usa o Peft do Hugging Face para um ajuste fino barato e eficiente. A PEFT é uma biblioteca (a Lora é uma de suas tecnologias suportadas) que permite usar uma variedade de modelos de idiomas baseados em transformadores e ajustá-los a Lora, permitindo um ajuste fino barato e eficiente do modelo em hardware geral. O endereço do GitHub deste projeto é:
https://github.com/tloen/alpaca-lora
Embora a Alpaca e a Alpaca-Lora tenham feito um grande progresso, suas tarefas de sementes estão em inglês e não têm apoio aos chineses. Por um lado, além do mencionado acima, a Belle coletou uma grande quantidade de corpus chinês, por outro lado, com base no trabalho de antecessores como o Alpaca-Lora, o modelo de língua chinesa Luotuo (Luotuo), aberto por três desenvolvedores individuais da Universidade Normal da China Central e outras instituições, um único cartão pode concluir o treinamento de treinamento. Atualmente, o projeto libera dois modelos Luotuo-Lora-7b-0.1, Luotuo-Lora-7b-0.3, e um modelo está no plano. Seu endereço do GitHub é:
https://github.com/lc1332/chinese-alpaca-lora
Inspirado na Alpaca, a Dolly usou o conjunto de dados da ALPACA para obter ajuste fino no GPT-J-6B. Como Dolly em si é um "clone" de um modelo, a equipe finalmente decidiu nomeá -lo "Dolly". Inspirado na Alpaca, esse método de clonagem está se tornando cada vez mais popular. Em resumo, é adotado aproximadamente o método de aquisição de dados de código aberto da ALPACA e instruções ajustadas sobre modelos antigos de tamanho 6B ou 7B para obter efeitos semelhantes a chatgptos. Essa idéia é muito econômica e pode imitar rapidamente o charme do chatgpt. É muito popular e, uma vez lançado, está cheio de estrelas. O endereço do GitHub deste projeto é:
https://github.com/databrickslabs/dolly
Depois de lançar a Alpaca, os estudiosos de Stanford se uniram à CMU, UC Berkeley, etc. para lançar um novo modelo - Vicuna com 13 bilhões de parâmetros (comumente conhecidos como Alpaca e Llama). Custa apenas US $ 300 para obter 90% de desempenho do ChatGPT. Vicuna é usada para ajustar o LLAMA no diálogo compartilhado pelo usuário coletado pelo ShareGPT. O processo de teste usa o GPT-4 como critérios de avaliação. Os resultados mostram que a Vicuna-13b atinge recursos que correspondem ao chatgpt e ao bardo em mais de 90% dos casos.
A UC Berkeley Lmsys Org lançou recentemente Vicuna com 7 bilhões de parâmetros. Não é apenas de tamanho pequeno, de alta eficiência e habilidade forte, mas também pode ser executado em um Mac com chip M1/M2 em apenas duas linhas de comando e também pode permitir a aceleração da GPU!
O endereço de código aberto do Github é: https://github.com/lm-sys/fastchat/
Outra versão chinesa foi de origem aberta por chinês-vicuna, com o endereço do github como:
https://github.com/facico/chinese-vicuna
Depois que o Chatgpt se tornou popular, as pessoas estavam procurando um caminho rápido para o templo. Algumas aparições do tipo ChatGPT começaram a aparecer, especialmente após o chatgpt a um baixo custo, se tornou uma maneira popular. LMFlow is a product born in this demand scenario, which enables large models to be refined on ordinary graphics cards like 3090. The project was initiated by the Hong Kong University of Science and Technology Statistics and Machine Learning Laboratory team, and is committed to establishing a fully open large model research platform that supports various experiments under limited machine resources, and improves the existing data utilization methods and optimization algorithm efficiency on the platform, so that the platform can develop into Um sistema de treinamento de modelo maior que é mais eficiente que os métodos anteriores.
Usando este projeto, mesmo recursos limitados de computação podem permitir que os usuários suportem treinamento personalizado para campos proprietários. Por exemplo, LLAMA-7B, um 3090 leva 5 horas para concluir o treinamento, o que reduz bastante o custo. O projeto também abre a experiência instantânea do lado da Web Service (lmflow.com). O surgimento e o código aberto do LMFlow permitem que recursos comuns treinem várias tarefas, como perguntas e respostas, companheirismo, redação, tradução, consulta de campo especializada, etc. Muitos pesquisadores estão atualmente tentando usar esse projeto para treinar grandes modelos com um volume de parâmetros de 65 bilhões ou até mais.
O endereço do GitHub deste projeto é:
https://github.com/optimalscale/lmflow
O projeto propõe um método para coletar automaticamente conversas ChatGPT, permitindo que o ChatGPT para conversar com os conjuntos de dados de diálogo multi-rodada de alta qualidade e coletar cerca de 50.000 perguntas e perguntas e respostas de alta qualidade de Quora, Stackoverflow e MedQA, respectivamente, e tem sido de origem aberta. Ao mesmo tempo, melhorou o modelo de llama e o efeito é muito bom. A Bai Ze também adotou a atual solução de ajuste fino Lora de baixo custo para obter três escalas diferentes: Bai Ze-7b, 13b e 30b, bem como um modelo no campo vertical dos cuidados médicos. Infelizmente, o nome chinês é bem nomeado, mas ainda não suporta chinês. O modelo chinês Bai Ze está sob o plano e será lançado no futuro. Seu endereço GitHub de código aberto é:
https://github.com/project-baiize/baize
A substituição plana do ChatGpt, com sede em lhama, continua a fermentar, o Berkeley, da UC Berkeley, lançou um modelo de conversa Koala que pode ser executado em GPUs de consumo com parâmetros de 13b. O conjunto de dados de treinamento da Koala inclui as seguintes peças: Dados do ChatGPT e dados de código aberto (generalista de instrução aberta (OIG), conjunto de dados usado pelo modelo Stanford Alpaca, Anthrópico HH, OpenAI WebGPT, OpenAI Summarization). O modelo KOALA é implementado em Easylm usando JAX/FLAX, usando 8 GPUs A100, e leva 6 horas para concluir 2 iterações. O efeito da avaliação é melhor que o ALPACA, alcançando 50% de desempenho do chatGPT.
Endereço de código aberto: https://github.com/young-geng/easylm
Com o advento de Stanford Alpaca, um grande número de famílias de alpaca com sede em lhama e famílias de animais extensos começou a surgir e, finalmente, abraçando os pesquisadores de rosto publicou recentemente um blog Stackllama: um guia prático para treinar llama com o RLHF. Ao mesmo tempo, um modelo de 7 bilhões de parâmetros - Stackllama também foi lançado. Este é um modelo ajustado no llama-7b através do aprendizado de reforço de feedback humano. Para detalhes, consulte o endereço do blog:
https://huggingface.co/blog/stackllama
O projeto otimiza a lhama para chinês e abre seu sistema de diálogo ajustado. As etapas específicas deste projeto incluem: 1. Expanda a lista de palavras, usando a peça de frase para treinar e construir dados chineses e se fundir com a lista de palavras llama; 2. Pré-treinamento, na nova lista de palavras, cerca de 20g do corpus chinês em geral foi treinado, e a tecnologia Lora foi usada no treinamento; 3. Usando Stanford Alpaca, o treinamento de ajuste fino foi realizado com dados de 51 mil para obter capacidade de diálogo.
O endereço de código aberto é: https://github.com/ymcui/chinese-llama-alpaca
Em 12 de abril, o Databricks lançou o Dolly 2.0, conhecido como o primeiro código aberto do setor, LLM compatível com diretiva. O conjunto de dados foi gerado pelos funcionários do Databricks e foi de origem aberta e disponível para fins comerciais. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
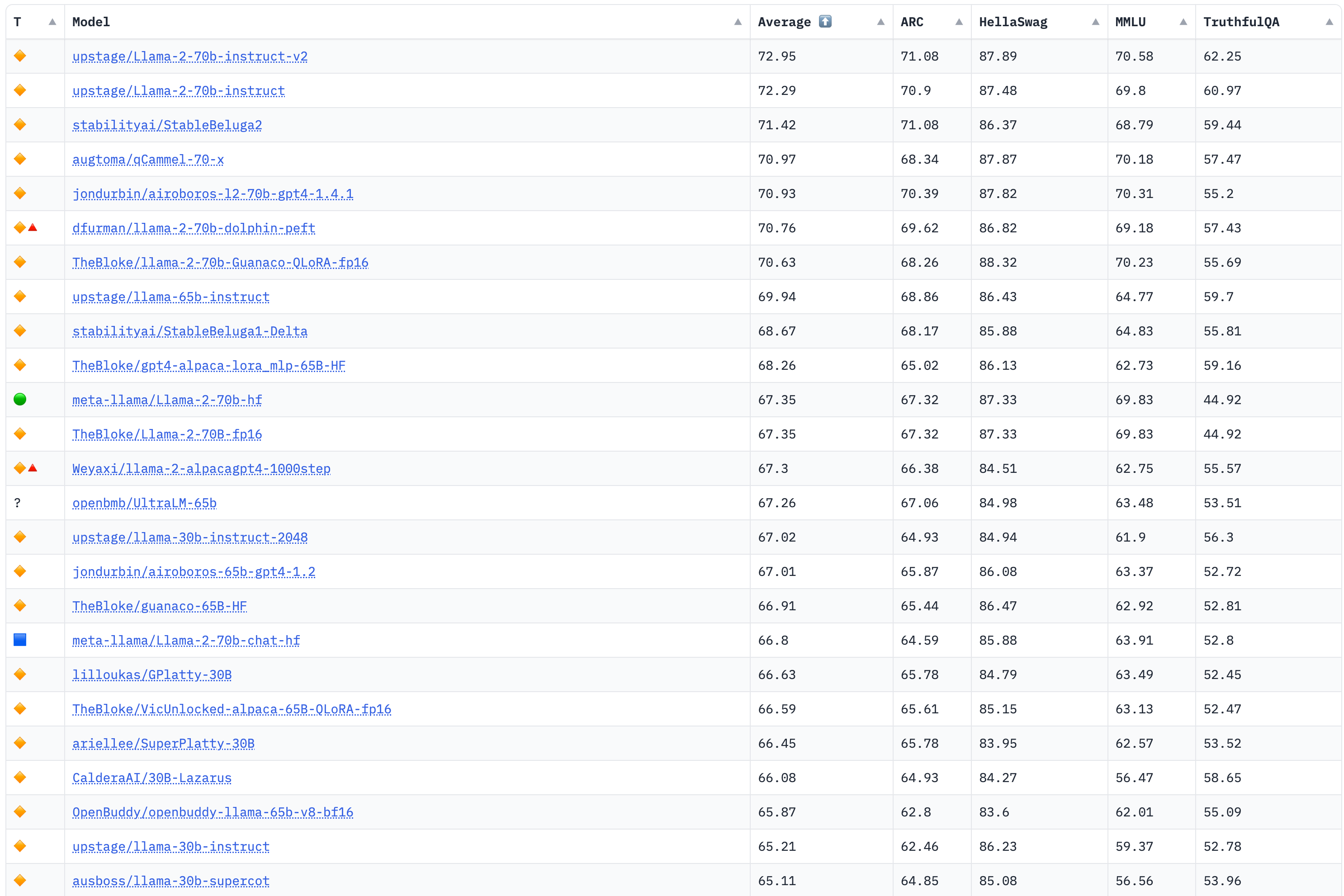
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
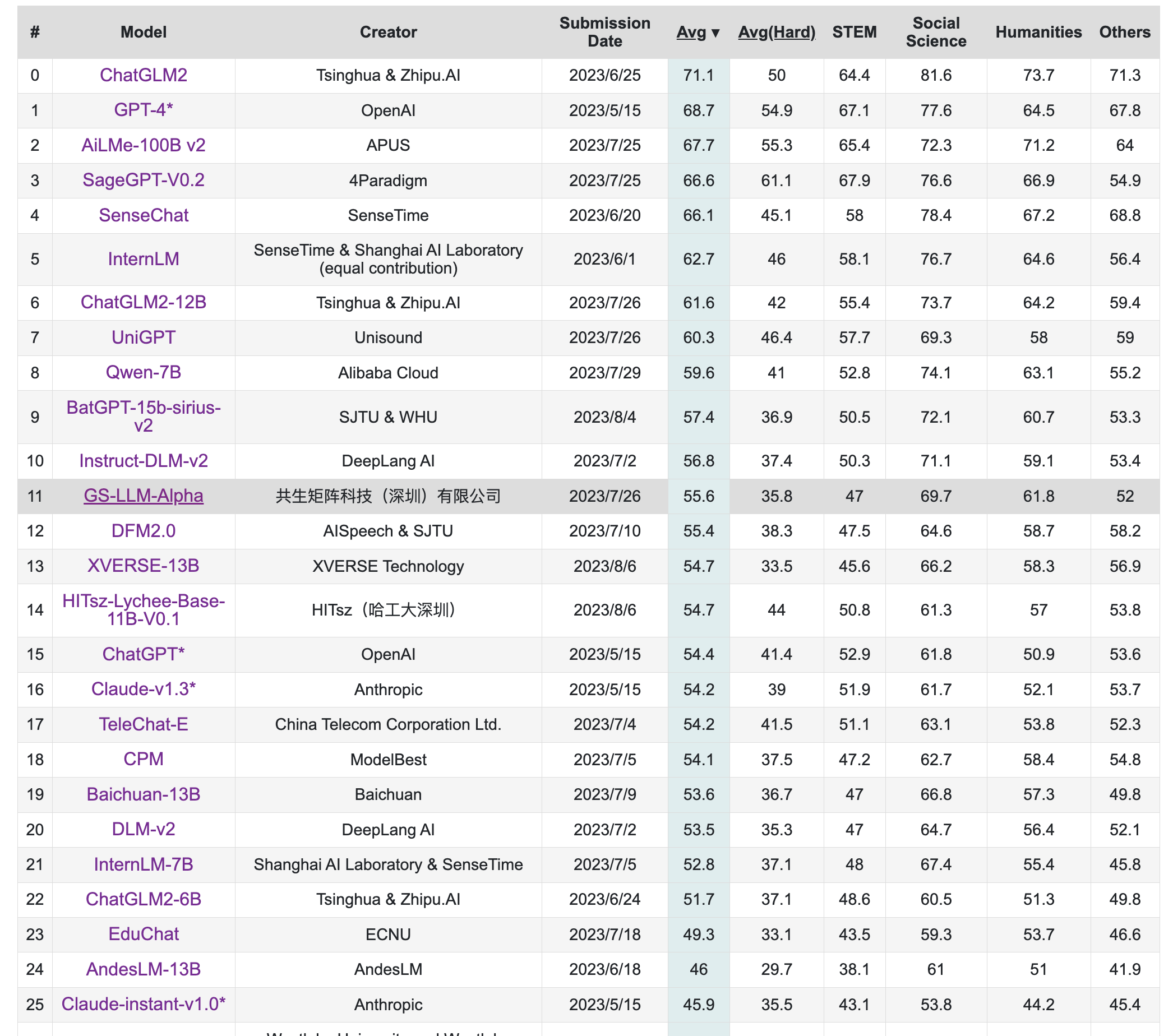
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

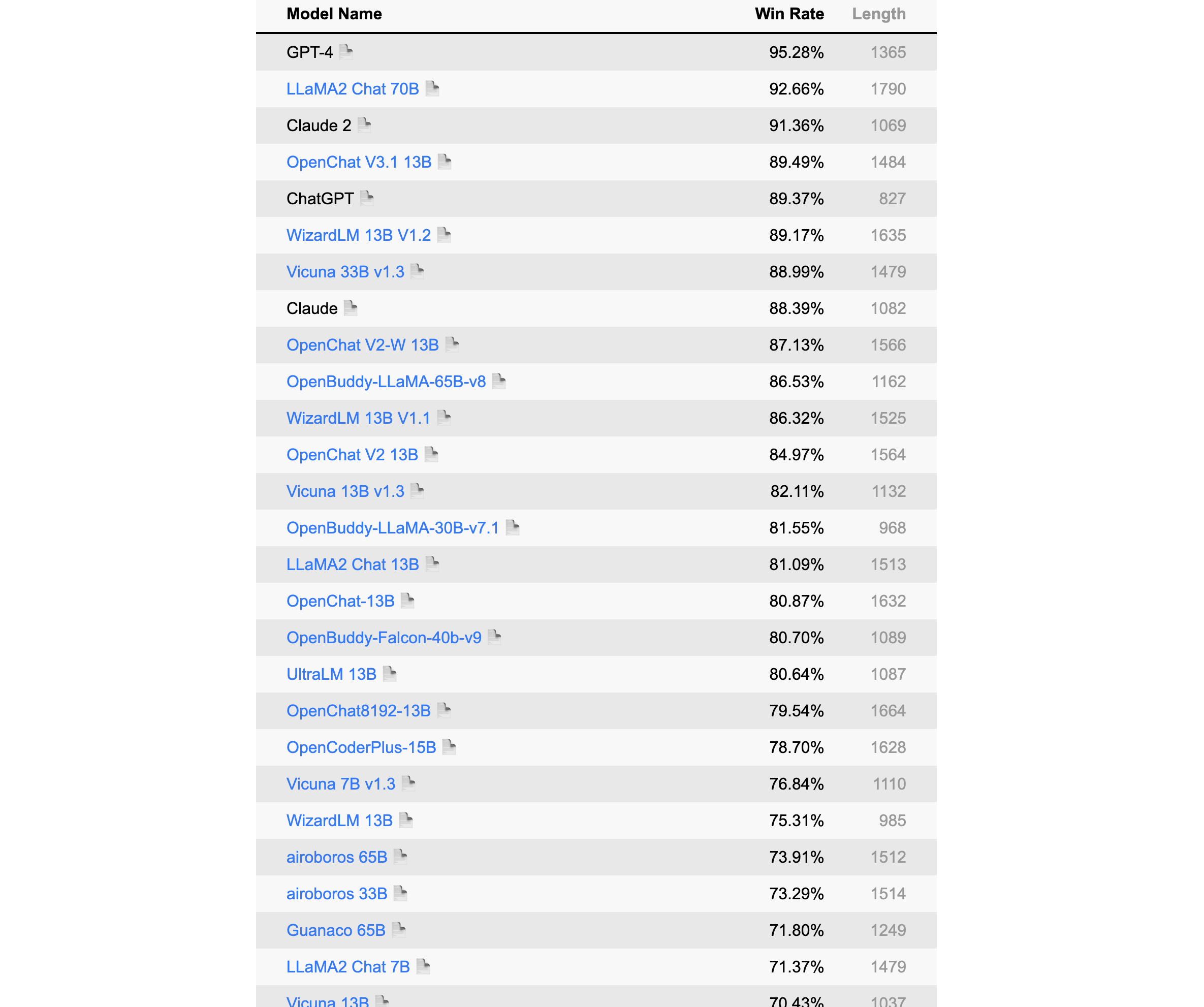
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


