FindTheChatGPTer
1.0.0
Ringkasan chatgpt/gpt4 open source "penggantian polos", pembaruan berkelanjutan
ChatGPT telah menjadi populer, dan banyak universitas domestik, lembaga penelitian dan perusahaan telah mengeluarkan rencana rilis yang mirip dengan ChatGPT. Chatgpt bukan open source, dan sangat sulit untuk direproduksi. Bahkan sekarang, tidak ada unit atau perusahaan yang mereproduksi kemampuan penuh GPT3. Baru saja, Openai secara resmi mengumumkan rilis model GPT4 dengan grafik dan teks multimodal, dan kemampuannya telah sangat ditingkatkan dibandingkan dengan chatgpt. Tampaknya baunya revolusi industri keempat yang didominasi oleh kecerdasan buatan umum.
Apakah di luar negeri atau di rumah, kesenjangan antara Openai semakin besar, dan semua orang mengejar ketinggalan dengan cara yang sibuk, sehingga mereka berada dalam posisi menguntungkan tertentu dalam inovasi teknologi ini. Saat ini, penelitian dan pengembangan banyak perusahaan besar pada dasarnya mengambil rute sumber tertutup. Ada beberapa detail yang secara resmi dirilis oleh ChatGPT dan GPT4, dan tidak seperti perkenalan makalah sebelumnya yang memperkenalkan lusinan halaman, era komersialisasi Openai telah tiba. Tentu saja, beberapa organisasi atau individu telah mengeksplorasi penggantian sumber terbuka. Artikel ini dirangkum sebagai berikut. Saya akan terus melacaknya. Ada penggantian sumber terbuka yang diperbarui untuk memperbarui tempat ini secara tepat waktu.
Jenis metode ini terutama mengadopsi metode non-llama dan fine-tuning lainnya untuk merancang secara mandiri atau mengoptimalkan model GPT dan T5, dan mewujudkan proses siklus penuh seperti pra-pelatihan, penyesuaian yang diawasi, dan pembelajaran penguatan.
Chatyuan (Yuanyu AI) dikembangkan dan diterbitkan oleh Yuanyu Intelligent Development Team. Ini mengklaim sebagai model dialog fungsional pertama di Cina. Itu dapat menulis artikel, mengerjakan pekerjaan rumah, menulis puisi, dan menerjemahkan bahasa Mandarin dan Inggris; Beberapa bidang spesifik seperti undang -undang juga dapat memberikan informasi yang relevan. Model ini saat ini hanya mendukung bahasa Cina, dan tautan github adalah:
https://github.com/clue-ai/chatyuan
Dilihat dari rincian teknis yang diungkapkan, lapisan yang mendasarinya mengadopsi model T5 dengan skala 700 juta parameter, dan mengawasi dan mencari-cari berdasarkan promptclue untuk membentuk Chatyuan. Model ini pada dasarnya adalah langkah pertama dari rute teknis ChatGPT tiga langkah, dan tidak ada pelatihan model hadiah dan pelatihan pembelajaran penguatan PPO yang diimplementasikan.
Baru -baru ini, Colossalai open source implementasi chatgpt mereka. Bagikan strategi tiga langkah mereka dan terapkan sepenuhnya rute teknis inti chatgpt: github-nya adalah sebagai berikut:
https://github.com/hpcaitech/colossalai
Berdasarkan proyek ini, saya telah mengklarifikasi strategi tiga langkah dan membagikannya:
Tahap pertama (tahap1_sft.py): Tahap penyempurnaan pengawasan SFT, proyek open source tidak diimplementasikan, ini relatif sederhana karena Colossalai dengan mulus mendukung Huggingface. Saya langsung menggunakan beberapa baris fungsi Fungsi Pelatih HuggingFace untuk dengan mudah mengimplementasikannya. Di sini saya menggunakan model GPT2. Dari sudut pandang implementasinya, ia mendukung model GPT2, Opt dan Bloom;
Tahap Tahap Kedua (Tahap2_RM.Py): Tahap Pelatihan Model Hadiah (RM), yaitu, bagian train_reward_model.py dalam contoh proyek;
Tahap ketiga (tahap3_ppo.py): tahap pembelajaran penguatan (rlhf), yaitu, proyek train_prompts.py
Eksekusi dari tiga file perlu ditempatkan dalam proyek Colossalai, di mana inti dalam kode adalah chatgpt dalam proyek asli, dan core.nn menjadi chatgpt.models dalam proyek asli.
ChatGLM adalah model dialog dari seri GLM Zhipu AI, sebuah perusahaan yang mengubah pencapaian teknologi di Tsinghua, mendukung bahasa Cina dan Inggris, dan saat ini memiliki model parameter 6,2 miliar. Ini mewarisi keunggulan GLM dan mengoptimalkan arsitektur model, sehingga menurunkan ambang batas untuk penyebaran dan aplikasi, mewujudkan aplikasi inferensi model besar pada kartu grafis konsumen. Untuk teknik terperinci, silakan merujuk ke github -nya:
Alamat sumber terbuka chatglm-6b adalah: https://github.com/thudm/chatglm-6b
Dari perspektif teknis, ia telah mengimplementasikan chatgpt yang memperkuat pembelajaran strategi penyelarasan manusia, membuat efek generasi lebih baik dan lebih dekat dengan nilai manusia. Area kemampuannya saat ini terutama mencakup kognisi diri, penulisan garis besar, copywriting, asisten penulisan email, ekstraksi informasi, bermain peran, perbandingan komentar, nasihat perjalanan, dll. Ini telah mengembangkan 130 miliar model super besar di bawah pengujian internal, yang dianggap sebagai model dialog dengan skala parameter yang lebih besar dalam penggantian sumber terbuka saat ini.
VisualGLM-6B (diperbarui pada 19 Mei 2023)
Tim baru-baru ini membuka versi multimodal dari ChatGLM-6B, yang mendukung dialog multimodal dalam gambar, Cina dan Inggris. Bagian model bahasa menggunakan chatglm-6b, dan bagian gambar membangun jembatan antara model visual dan model bahasa dengan melatih blip2-qformer. Model keseluruhan memiliki total 7,8 miliar parameter. VisualGLM-6B mengandalkan 30m pasangan grafis Cina berkualitas tinggi dari dataset Cogview, dan pra-terlatih dengan pasangan grafis bahasa Inggris yang difilter 300m, dengan bobot yang sama dalam bahasa Cina dan Inggris. Metode pelatihan ini lebih baik menyelaraskan informasi visual ke ruang semantik chatglm; Pada tahap fine-tuning berikutnya, model ini dilatih pada data tanya jawab visual yang panjang untuk menghasilkan jawaban yang memenuhi preferensi manusia.
Visualglm-6b Alamat sumber terbuka adalah: https://github.com/thudm/visualglm-6b
Chatglm2-6b (diperbarui pada 27 Juni 2023)
Tim baru-baru ini membuka versi ChatGLM2-6B versi generasi kedua ChatGLM. Dibandingkan dengan versi generasi pertama, fitur utamanya termasuk penggunaan skala data yang lebih besar, dari 1T hingga 1.4T; Yang paling menonjol adalah dukungan konteksnya yang lebih panjang, yang telah diperluas dari 2k ke 32k, memungkinkan putaran input yang lebih lama dan lebih tinggi; Selain itu, kecepatan inferensi telah sangat dioptimalkan, peningkatan 42%, dan sumber daya memori video yang ditempati telah sangat berkurang.
ChatGLM2-6B Alamat sumber terbuka adalah: https://github.com/thudm/chatglm2-6b
Ini dikenal sebagai proyek penggantian chatgpt open source pertama, dan ide dasarnya didasarkan pada Google Language Big Model Arsitektur Palm dan Penggunaan Metode Pembelajaran Penguatan (RLHF) dari umpan balik manusia. Palm adalah model all-around parameter 540 miliar yang dirilis oleh Google pada bulan April tahun ini, berdasarkan pelatihan sistem jalur. Ini dapat menyelesaikan tugas seperti menulis kode, obrolan, pemahaman bahasa, dll., Dan memiliki kinerja pembelajaran sampel rendah yang kuat pada sebagian besar tugas. Pada saat yang sama, mekanisme pembelajaran penguatan seperti chatgpt diadopsi, yang dapat membuat jawaban AI lebih sesuai dengan persyaratan skenario dan mengurangi toksisitas model.
Alamat GitHub adalah: https://github.com/lucidrains/palm-rlhf-pytorch
Proyek ini dikenal sebagai model open source terbesar, hingga 1,5 triliun, dan merupakan model multimodal. Domain kemampuannya meliputi pemahaman bahasa alami, terjemahan mesin, pertanyaan dan jawaban cerdas, analisis sentimen dan pencocokan grafis, dll. Alamat sumber terbukanya adalah:
https://huggingface.co/banana-dev/gptrillion
(Pada 24 Mei 2023, proyek ini adalah program lelucon Hari April Mop. Proyek ini telah dihapus. Saya akan menjelaskannya dengan ini
OpenFlamingo adalah kerangka kerja yang menonjolkan GPT-4 dan mendukung pelatihan dan evaluasi model multimodal skala besar. Itu dirilis oleh Laion nirlaba dan merupakan reproduksi model flamingo DeepMind. Saat ini Open Source adalah model OpenFlamingo-9B yang berbasis di LLAMA. Model Flamingo dilatih pada corpus jaringan skala besar yang berisi teks dan gambar interlaced, dan memiliki kemampuan untuk mempelajari sampel terbatas konteks. OpenFlamingo mengimplementasikan arsitektur yang sama yang diusulkan dalam flamingo asli, dilatih pada sampel 5M dari dataset C4 multimodal baru dan sampel 10m dari Laion-2b. Alamat open source dari proyek ini adalah:
https://github.com/mlfoundations/open_flamingo
Pada 21 Februari tahun ini, Universitas Fudan merilis Moss dan membuka beta publik, yang menyebabkan beberapa kontroversi setelah beta publik runtuh. Sekarang proyek telah mengantarkan pembaruan penting dan open source. Lumut open source mendukung bahasa Cina dan Inggris, dan mendukung pluginisasi, seperti memecahkan persamaan, pencarian, dll. Parameternya adalah 16B, dan terlatih dalam sekitar 700 miliar kata-kata Cina dan Inggris dan kode. Instruksi dialog selanjutnya disesuaikan, pembelajaran plug-in yang disempurnakan dan pelatihan preferensi manusia memiliki beberapa putaran kemampuan dialog dan kemampuan untuk menggunakan beberapa plug-in. Alamat open source dari proyek ini adalah:
https://github.com/openlmlab/moss
Mirip dengan Minigpt-4 dan LLAVA, ini adalah model multimodal open source, Benchmarking GPT-4, yang melanjutkan ide pelatihan modular dari seri MPLUG. Saat ini membuka model kuantitas parameter 7B, dan pada saat yang sama, ia mengusulkan owereval tes yang komprehensif untuk pertama kalinya untuk pemahaman instruksi terkait visual. Melalui evaluasi manual, model yang ada, termasuk LLAVA, MINIGPT-4 dan pekerjaan lainnya, menunjukkan kemampuan multimodal yang lebih baik, terutama dalam kemampuan pemahaman instruksi multimodal, kemampuan dialog multi-putaran, kemampuan penalaran pengetahuan, dll. Ini disesalkan bahwa seperti model grafik dan teks lainnya, masih hanya mendukung bahasa Inggris, tetapi versi Tiongkok sudah ada dalam daftar opennya.
Alamat sumber terbuka dari proyek ini adalah: https://github.com/x-plug/mplug-owl
Pandalm adalah model evaluasi model yang bertujuan untuk secara otomatis mengevaluasi preferensi model skala besar lainnya untuk menghasilkan konten, menghemat biaya evaluasi manual. Pandalm dilengkapi dengan antarmuka web untuk analisis, dan juga mendukung panggilan kode Python. Ini dapat mengevaluasi teks yang dihasilkan oleh model dan data apa pun dengan hanya tiga baris kode, yang sangat nyaman untuk digunakan.
Alamat sumber terbuka dari proyek ini adalah: https://github.com/weopenml/pandalm
Pada Konferensi Zhiyuan yang diadakan baru -baru ini, Zhiyuan Research Institute membuka sumber model pencerahan dan Sky Eagle, yang memiliki pengetahuan bilingual tentang Cina dan Inggris. Parameter model dasar versi open source termasuk 7 miliar dan 33 miliar. Pada saat yang sama, ini membuka model dialog Aquilachat dan model pembuatan kode teks quilacode, dan keduanya telah dibuka untuk lisensi komersial. Aquila mengadopsi arsitektur decoder saja seperti GPT-3 dan Llama, dan juga memperbarui kosakata untuk bilingualisme Cina dan Inggris, dan mengadopsi metode pelatihan yang dipercepat. Jaminan kinerjanya tidak hanya tergantung pada optimasi dan peningkatan model, tetapi juga manfaat dari akumulasi data berkualitas tinggi Zhiyuan pada model besar dalam beberapa tahun terakhir.
Alamat sumber terbuka dari proyek ini adalah: https://github.com/flagai-open/flagai/tree/master/examples/aquila
Baru-baru ini, Microsoft telah menerbitkan kertas model besar multi-modal dan kode open source -codi, yang sepenuhnya menghubungkan teks-voice-image-video, mendukung input sewenang-wenang dan output modal sewenang-wenang. Untuk mencapai generasi modalitas sewenang -wenang, para peneliti membagi pelatihan menjadi dua tahap. Pada tahap pertama, penulis menggunakan strategi penyelarasan jembatan dan kondisi gabungan untuk berlatih, menciptakan model difusi potensial untuk setiap mode; Pada tahap kedua, modul perhatian persimpangan ditambahkan ke setiap model difusi potensial dan enkoder lingkungan, yang dapat memproyeksikan variabel laten dari model difusi potensial ke dalam ruang bersama, sehingga modalitas yang dihasilkan lebih beragam.
Alamat sumber terbuka dari proyek ini adalah: https://github.com/microsoft/i-code/tree/main/i-code-v3
Meta telah meluncurkan dan membuka bersumber dari Multimodal Big Model ImageBind, yang dapat mencapai 6 modalitas, termasuk gambar, video, audio, kedalaman, panas, dan gerakan spasial. ImageBind memecahkan masalah penyelarasan dengan menggunakan karakteristik pengikatan gambar, menggunakan model bahasa visual yang besar dan kemampuan sampel nol untuk memperluas ke modalitas baru. Data pemasangan gambar sudah cukup untuk mengikat keenam mode ini bersama -sama, memungkinkan berbagai mode untuk membuka pemisahan modal satu sama lain.
Alamat open source dari proyek ini adalah: https://github.com/facebookResearch/imagebind
Pada 10 April 2023, Wang Xiaochuan secara resmi mengumumkan pendirian perusahaan model besar AI "Baichuan Intelligence", yang bertujuan untuk membuat versi OpenAI versi Cina. Dua bulan setelah pendiriannya, Baichuan Intelligent telah membuat sumber utama model Baichuan-7B yang dikembangkan secara independen, mendukung bahasa Cina dan Inggris. Baichuan-7b tidak hanya melampaui model besar lainnya seperti ChatGLM-6B dengan keunggulan yang signifikan pada daftar evaluasi otoritatif C-eval, Ageval dan Gaokao, tetapi juga secara signifikan memimpin LLAMA-7B dalam daftar evaluasi otoritatif Bahasa Inggris MMLU. Model ini mencapai skala token triliun pada data berkualitas tinggi, dan mendukung kemampuan ekspansi puluhan ribu jendela dinamis yang sangat panjang berdasarkan optimasi operator perhatian yang efisien. Saat ini, open source mendukung kemampuan konteks 4K. Model open source ini tersedia secara komersial dan lebih ramah daripada Llama.
Alamat open source dari proyek ini adalah: https://github.com/baichuan-inc/baichuan-7b
Pada 6 Agustus 2023, tim Yuanxiang Xverse membuka model Xverse-13b. This model is a multilingual large model that supports up to 40+ languages and supports contextual length up to 8192. According to the team, the features of this model are: Model structure: XVERSE-13B uses the mainstream Decoder-only standard Transformer structure, supports 8K context length, which is the longest among the same size model, and can meet the needs of longer multi-round dialogue, knowledge Q&A and summary; Data pelatihan: 1,4 triliun token data berkualitas tinggi dan beragam dibangun untuk melatih sepenuhnya model, termasuk 40 Cina, Inggris, Rusia, dan Barat. Berbagai bahasa, dengan mengatur rasio pengambilan sampel dari berbagai jenis data, bahasa Cina dan Inggris berkinerja baik, dan juga dapat memperhitungkan efek bahasa lain; Segmentasi kata: Berdasarkan algoritma BPE, segmentasi kata dengan ukuran kosa kata 100.278 dilatih menggunakan ratusan corpus GB, yang dapat mendukung berbagai bahasa pada saat yang sama tanpa perluasan tambahan dari daftar kata; Kerangka Pelatihan: Mengembangkan secara independen sejumlah teknologi utama, termasuk operator yang efisien, optimasi memori video, strategi penjadwalan paralel, tumpang tindih komunikasi-komputasi data, kolaborasi platform dan kerangka kerja, dll., Membuat efisiensi pelatihan lebih tinggi dan stabilitas model kuat. Tingkat pemanfaatan daya komputasi puncak pada cluster kilocard dapat mencapai 58,5%, peringkat di antara yang terdepan dalam industri.
Alamat open source dari proyek ini adalah: https://github.com/xverse-ai/xverse-13b
Pada 3 Agustus 2023, model 7 miliar Alibaba Tongyi Qianwen adalah open source, termasuk model umum dan model dialog, dan merupakan open source, gratis dan tersedia secara komersial. Menurut laporan, QWEN-7B adalah model bahasa besar berdasarkan transformator dan dilatih pada data pra-pelatihan skala super besar. Jenis data pra-pelatihan beragam dan mencakup berbagai bidang, termasuk sejumlah besar teks online, buku profesional, kode, dll. Ini adalah model dermaga yang mendukung bahasa Cina dan Inggris, dilatih pada lebih dari 2 triliun set data token, dan panjang jendela konteks mencapai 8k. QWEN-7B-CHAT adalah model dialog Cina-Inggris berdasarkan model alas QWEN-7B. Model pra-terlatih Tongyi Qianwen 7B berkinerja baik dalam berbagai evaluasi tolok ukur otoritatif. Kemampuan Cina dan Inggrisnya jauh melebihi model open source dari skala yang sama di rumah dan di luar negeri, dan beberapa kemampuan bahkan melebihi model open source dari ukuran 12B dan 13B.
Alamat open source dari proyek ini adalah: https://github.com/qwenlm/qwen-7b
Llama adalah model bahasa kecerdasan buatan skala besar baru yang dirilis oleh Meta, yang berkinerja baik dalam tugas-tugas seperti menghasilkan teks, dialog, merangkum materi tertulis, membuktikan teorema matematika, atau memprediksi struktur protein. Model Llama mendukung 20 bahasa, termasuk bahasa alfabet Latin dan Cyrillic. Saat ini, model asli tidak mendukung orang Cina. Dapat dikatakan bahwa kebocoran epik Llama telah dengan kuat mempromosikan pengembangan open source seperti chatgpt.
(Diperbarui pada 22 April 2023) tetapi sayangnya, otorisasi Llama saat ini terbatas dan hanya dapat digunakan untuk penelitian ilmiah dan tidak diizinkan untuk penggunaan komersial. Untuk memecahkan masalah open source yang sepenuhnya komersial, proyek Redpajama muncul, bertujuan untuk membuat replika llama open source sepenuhnya yang dapat digunakan untuk aplikasi komersial dan memberikan proses yang lebih transparan untuk penelitian. Redpajama lengkap mencakup dataset token 1,2 triliun, dan langkah selanjutnya adalah memulai pelatihan skala besar. Pekerjaan ini masih layak dinanti -nantikan, dan alamat open source -nya adalah:
https://github.com/togethercomputer/redpajama-data
(Diperbarui pada 7 Mei 2023)
Redpajama memperbarui file model pelatihannya, termasuk dua parameter: 3b dan 7b, di mana 3B dapat berjalan di kartu grafis gaming RTX2070 yang dirilis 5 tahun yang lalu, menebus celah di llama di 3B. Alamat modelnya adalah:
https://huggingface.co/togetherComputer
Selain Redpajama, MosaiCML telah meluncurkan model seri MPT, dan data pelatihannya menggunakan data Redpajama. Dalam berbagai evaluasi kinerja, model 7B sebanding dengan llama asli. Alamat open source dari modelnya adalah:
https://huggingface.co/mosaicml
Apakah itu Redpajama atau MPT, itu juga open source model versi obrolan yang sesuai. Sumber terbuka dari kedua model ini telah membawa dorongan besar pada komersialisasi seperti chatgpt.
(Diperbarui pada 1 Juni 2023)
Falcon adalah basis model besar terbuka yang membandingkan Llama. Ini memiliki dua skala pengukuran parameter: 7b dan 40b. Kinerja 40B dikenal sebagai Llama 65B Ultra-High-High. Dapat dipahami bahwa Falcon masih menggunakan model dekoder Autoregressive GPT, tetapi telah berupaya keras dalam data. Setelah mengikis konten dari jaringan publik dan membangun set data awal pretrained, ia menggunakan dump CommonCrawl untuk melakukan penyaringan skala besar dan deduplikasi skala besar, dan akhirnya mendapatkan set data pretrained besar yang terdiri dari hampir 5 triliun token. Pada saat yang sama, banyak korpus yang dipilih telah ditambahkan, termasuk makalah penelitian dan percakapan media sosial. Namun, otorisasi proyek ini kontroversial, dan metode otorisasi "semi-komersial" diadopsi, dan 10% dari biaya komersial akan mulai terjadi setelah pendapatan mencapai 1 juta.
Alamat open source dari proyek ini adalah: https://huggingface.co/tiiuae
(Diperbarui pada 3 Juli 2023)
Falcon asli tidak memiliki kemampuan dukungan Cina seperti Llama. Tim proyek "Linly" membangun dan membuka versi Cina dari China-Falcon berdasarkan model Falcon. Model pertama kali memperluas dan memperluas daftar kosa kata, termasuk 8701 karakter Cina yang biasa digunakan, 20.000 kata-kata frekuensi tinggi Cina pertama dalam daftar kosa kata Jieba, dan 60 tanda baca Cina. Setelah deduplikasi, ukuran daftar kosa kata diperluas menjadi 90.046. Selama fase pelatihan, 50G corpus dan data skala 2T digunakan untuk pelatihan.
Alamat open source dari proyek ini adalah: https://github.com/cvi-szu/linly
(Diperbarui pada 24 Juli 2023)
Falcon asli tidak memiliki kemampuan dukungan Cina seperti Llama. Tim proyek "Linly" membangun dan membuka versi Cina dari China-Falcon berdasarkan model Falcon. Model pertama kali memperluas dan memperluas daftar kosa kata, termasuk 8701 karakter Cina yang biasa digunakan, 20.000 kata-kata frekuensi tinggi Cina pertama dalam daftar kosa kata Jieba, dan 60 tanda baca Cina. Setelah deduplikasi, ukuran daftar kosa kata diperluas menjadi 90.046. Selama fase pelatihan, 50G corpus dan data skala 2T digunakan untuk pelatihan.
Alamat open source dari proyek ini adalah: https://github.com/cvi-szu/linly
Alpaca (model Alpaca) yang dirilis oleh Stanford adalah model baru berdasarkan model LLAMA-7B. Prinsip dasarnya adalah untuk memungkinkan model Text-Davinci-003 Openai untuk menghasilkan sampel instruksi 52k dengan cara yang berstruktur diri untuk menyempurnakan llama. Proyek ini telah membuka data pelatihan sumber, kode untuk menghasilkan data pelatihan, dan hiperparameter. File model belum dibuka bersumber, mencapai lebih dari 5,6 ribu bintang dalam satu hari. Pekerjaan ini sangat populer karena akses data yang murah dan mudah, dan juga membuka jalan menuju meniru chatgpt berbiaya rendah. Alamat GitHubnya adalah:
https://github.com/tatsu-lab/stanford_alpaca
Ini adalah implementasi open source dari llama+ai chatbot berdasarkan pembelajaran penguatan umpan balik manusia yang diluncurkan oleh Nebuly+AI. Rute teknisnya mirip dengan chatgpt. Proyek ini baru saja diluncurkan selama 2 hari dan telah memenangkan 5,2K bintang. Alamat GitHubnya adalah:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
Algoritma Proses Pelatihan Chatllama terutama digunakan untuk mencapai pelatihan yang lebih cepat dan lebih murah daripada ChatGpt. Dikatakan hampir 15 kali lebih cepat. Fitur utamanya adalah:
Implementasi open source lengkap memungkinkan pengguna untuk membangun layanan gaya chatgpt berdasarkan model LLAMA yang sudah terlatih;
Arsitektur Llama lebih kecil, membuat proses pelatihan dan penalaran lebih cepat dan lebih murah;
Dukungan bawaan untuk Deep-Nol untuk mempercepat proses penyempurnaan;
Mendukung arsitektur model LLAMA dari berbagai ukuran, dan pengguna dapat menyempurnakan model sesuai dengan preferensi mereka sendiri.
OpenChatkit diciptakan bersama oleh tim Together, di mana mantan peneliti Openai berada, serta tim Laion dan Ontocord.ai. OpenChatKit berisi 20 miliar parameter dan disesuaikan dengan versi open source GPT-3 GPT-NOX-20B. Pada saat yang sama, pembelajaran penguatan yang berbeda dari chatgpts, OpenChatkit menggunakan model audit parameter 6 miliar untuk memfilter informasi yang tidak pantas atau berbahaya untuk memastikan keamanan dan kualitas konten yang dihasilkan. Alamat GitHubnya adalah:
https://github.com/togethercomputer/openchatkit
Berdasarkan Stanford Alpaca, fine-tuning yang diawasi direalisasikan berdasarkan Bloom dan Llama. Tugas benih Stanford Alpaca semuanya dalam bahasa Inggris, dan data yang dikumpulkan juga dalam bahasa Inggris. Proyek open source ini adalah untuk mempromosikan pengembangan komunitas open source dialog Big Dialog Tiongkok. Itu telah dioptimalkan untuk orang Cina. Model Tuning hanya menggunakan data yang diproduksi oleh ChatGPT (tidak termasuk data lain). Proyek berisi berikut ini:
175 Misi Benih Cina
Kode untuk menghasilkan data
Data yang dihasilkan oleh 10m saat ini bersumber dengan 1,5m, set data instruksi matematika 0,25m dan set data dialog tugas multi-putaran 0,8m.
Model dioptimalkan berdasarkan Bloomz-7b1-MT dan LLAMA-7B
Alamat GitHub adalah: https://github.com/lianjiatech/belle
Alpaca-Lora adalah mahakarya lain dari Universitas Stanford. Ini menggunakan teknologi LORA (adaptasi rendah) untuk mereproduksi hasil alpaca, menggunakan metode berbiaya lebih rendah, dan hanya dilatih pada kartu grafis RTX 4090 selama 5 jam untuk mendapatkan model dengan level alpaca. Selain itu, model dapat berjalan pada pi raspberry. Dalam proyek ini, ia menggunakan peft Hugging Face untuk penyempurnaan yang murah dan efisien. PEFT adalah perpustakaan (Lora adalah salah satu teknologi yang didukung) yang memungkinkan Anda untuk menggunakan berbagai model bahasa berbasis transformator dan menyempurnakannya dengan Lora, memungkinkan penyempurnaan model yang murah dan efisien pada perangkat keras umum. Alamat GitHub dari proyek ini adalah:
https://github.com/tloen/alpaca-lora
Meskipun Alpaca dan Alpaca-Lora telah membuat kemajuan besar, tugas benih mereka keduanya dalam bahasa Inggris dan tidak memiliki dukungan untuk orang Cina. Di satu sisi, di samping yang disebutkan di atas bahwa Belle telah mengumpulkan sejumlah besar korpus Cina, di sisi lain, berdasarkan karya para pendahulu seperti Alpaca-Lora, model bahasa Cina Luotuo (Luotuo) bersumber dari tiga pengembang individu dari Universitas Normal Tiongkok Tengah dan lembaga-lembaga lain, satu kartu dapat melengkapi pelatihan pelatihan. Saat ini, proyek ini merilis dua model Luotuo-Lora-7b-0.1, Luotuo-Lora-7b-0.3, dan satu model ada dalam rencana tersebut. Alamat GitHubnya adalah:
https://github.com/lc1332/chinese-alpaca-lora
Terinspirasi oleh Alpaca, Dolly menggunakan dataset Alpaca untuk mencapai penyempurnaan pada GPT-J-6B. Karena Dolly sendiri adalah "klon" model, tim akhirnya memutuskan untuk menamainya "Dolly". Terinspirasi oleh Alpaca, metode kloning ini menjadi semakin populer. Singkatnya, secara kasar diadopsi metode akuisisi data sumber terbuka Alpaca, dan instruksi fine-tune pada model lama ukuran 6B atau 7B untuk mencapai efek seperti chatgpt. Gagasan ini sangat ekonomis dan dapat dengan cepat meniru pesona chatgpt. Ini sangat populer dan begitu diluncurkan, penuh dengan bintang. Alamat GitHub dari proyek ini adalah:
https://github.com/databrickslabs/dolly
Setelah meluncurkan Alpaca, Stanford Scholars bekerja sama dengan CMU, UC Berkeley, dll. Untuk meluncurkan model baru - Vicuna dengan 13 miliar parameter (umumnya dikenal sebagai Alpaca dan Llama). Biayanya hanya $ 300 untuk mencapai 90% kinerja chatgpt. Vicuna digunakan untuk menyempurnakan llama pada dialog yang dibagikan pengguna yang dikumpulkan oleh Sharegpt. Proses pengujian menggunakan GPT-4 sebagai kriteria evaluasi. Hasilnya menunjukkan bahwa Vicuna-13b mencapai kemampuan yang cocok dengan chatgpt dan Bard di lebih dari 90% kasus.
UC Berkeley LMSys Org baru -baru ini merilis Vicuna dengan 7 miliar parameter. Ini tidak hanya berukuran kecil, efisiensi tinggi dan kemampuan yang kuat, tetapi juga dapat berjalan pada Mac dengan chip M1/M2 hanya dalam dua baris perintah, dan juga dapat memungkinkan akselerasi GPU!
Alamat sumber terbuka GitHub adalah: https://github.com/lm-sys/fastchat/
Versi Cina lainnya telah bersumber terbuka oleh Vicuna Cina, dengan alamat GitHub sebagai:
https://github.com/facico/chinese-vicuna
Setelah chatgpt menjadi populer, orang -orang mencari jalan cepat ke kuil. Beberapa penampilan seperti chatgpt mulai muncul, terutama mengikuti chatgpt dengan biaya rendah telah menjadi cara yang populer. LMFLOW adalah produk yang lahir dalam skenario permintaan ini, yang memungkinkan model besar disempurnakan pada kartu grafis biasa seperti 3090. Proyek ini diprakarsai oleh Universitas Sains dan Statistik Teknologi Hong Kong dan tim laboratorium pembelajaran mesin, dan berkomitmen untuk membangun platform yang ada di dalam platform penelitian yang ada di bawah berbagai eksperimen di bawah sumber daya mesin yang terbatas, dan meningkatkan data yang ada di dalam data yang ada. Sistem pelatihan model yang lebih besar yang lebih efisien daripada metode sebelumnya.
Dengan menggunakan proyek ini, bahkan sumber daya komputasi yang terbatas dapat memungkinkan pengguna untuk mendukung pelatihan yang dipersonalisasi untuk bidang kepemilikan. Misalnya, Llama-7b, 3090 membutuhkan waktu 5 jam untuk menyelesaikan pelatihan, yang sangat mengurangi biaya. Proyek ini juga membuka Layanan Tanya Jawab Pengalaman Instan Sisi Web (lmflow.com). Munculnya dan sumber terbuka LMFLOW memungkinkan sumber daya biasa untuk melatih berbagai tugas seperti T&J, persahabatan, penulisan, terjemahan, konsultasi lapangan ahli, dll. Banyak peneliti saat ini mencoba menggunakan proyek ini untuk melatih model besar dengan volume parameter 65 miliar atau bahkan lebih tinggi.
Alamat GitHub dari proyek ini adalah:
https://github.com/optimalscale/lmflow
Proyek ini mengusulkan metode untuk secara otomatis mengumpulkan percakapan chatgpt, memungkinkan chatgpt untuk berbicara sendiri, batch menghasilkan dataset dialog multi-putaran berkualitas tinggi, dan mengumpulkan sekitar 50.000 kitab tanya jawab berkualitas tinggi dari Quora, Stackoverflow dan Medqa, masing-masing, dan telah semuanya bersumber terbuka. Pada saat yang sama, itu meningkatkan model LLAMA dan efeknya cukup bagus. Bai Ze juga mengadopsi solusi penyempurnaan LORA berbiaya rendah saat ini untuk mendapatkan tiga skala yang berbeda: BAI ZE-7B, 13B dan 30B, serta model di bidang vertikal perawatan medis. Sayangnya, nama Cina dinamai dengan baik, tetapi masih tidak mendukung orang Cina. Model Bai Ze Cina dilaporkan di bawah rencana dan akan dirilis di masa depan. Alamat GitHub open source -nya adalah:
https://github.com/project-baize/baize
Penggantian datar ChatGPT yang berbasis di Llama terus fermentasi, Berkeley UC Berkeley telah merilis model percakapan Koala yang dapat berjalan pada GPU konsumen dengan parameter 13B. Dataset pelatihan Koala mencakup bagian -bagian berikut: data chatgpt dan data sumber terbuka (Open Instruction Generalis (OIG), dataset yang digunakan oleh Stanford Alpaca Model, Anthropic HH, OpenAI Webgpt, Openai Summarisasi). Model Koala diimplementasikan dalam EasyLM menggunakan Jax/Flax, menggunakan 8 A100 GPU, dan butuh 6 jam untuk menyelesaikan 2 iterasi. Efek evaluasi lebih baik dari alpaca, mencapai kinerja chatgpt 50%.
Alamat Sumber Terbuka: https://github.com/young-geng/easylm
Dengan munculnya Stanford Alpaca, sejumlah besar keluarga Alpaca yang berbasis di Llama dan keluarga hewan yang luas mulai muncul, dan akhirnya, memeluk para peneliti wajah baru-baru ini menerbitkan blog Stackllama: Panduan Praktis untuk Pelatihan Llama dengan RLHF. Pada saat yang sama, model parameter 7 miliar - Stackllama juga dirilis. Ini adalah model yang disempurnakan di LLAMA-7B melalui pembelajaran penguatan umpan balik manusia. Untuk detailnya, lihat alamat blognya:
https://huggingface.co/blog/stackllama
Proyek ini mengoptimalkan llama untuk Cina dan membuka sistem dialognya yang disesuaikan. Langkah -langkah spesifik dari proyek ini meliputi: 1. Perluas daftar kata, menggunakan kalimat untuk melatih dan membangun data Cina, dan digabungkan dengan daftar kata llama; 2. Pra-pelatihan, pada daftar kata baru, sekitar 20g corpus Cina umum dilatih, dan teknologi Lora digunakan dalam pelatihan; 3. Menggunakan Stanford Alpaca, pelatihan penyempurnaan dilakukan dengan data 51k untuk mendapatkan kemampuan dialog.
Alamat open source adalah: https://github.com/ymcui/chinese-llama-alpaca
Pada 12 April, DataBricks merilis Dolly 2.0, yang dikenal sebagai open source pertama di industri, LLM yang sesuai dengan arahan. Dataset dihasilkan oleh karyawan databricks dan bersumber terbuka dan tersedia untuk tujuan komersial. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
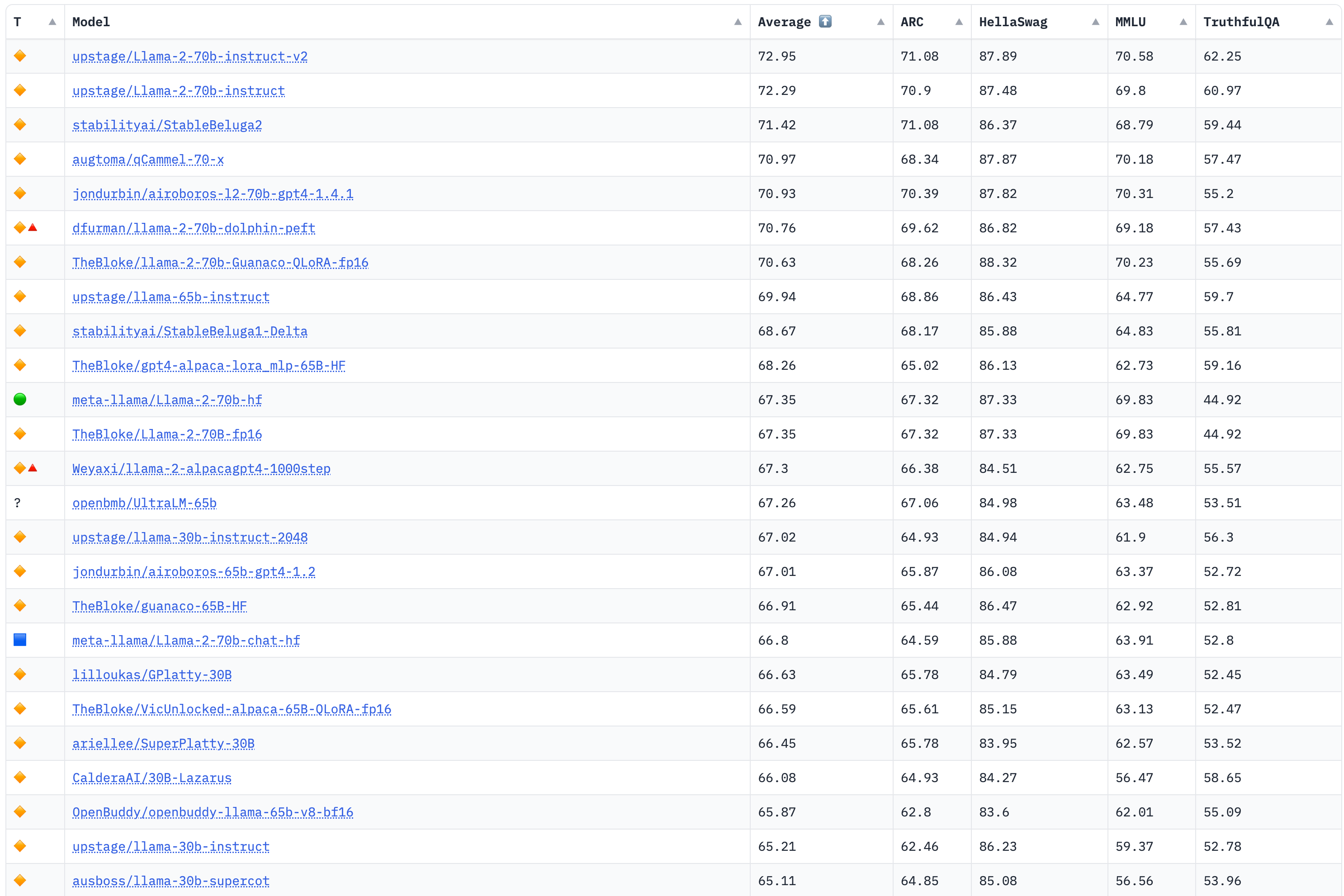
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
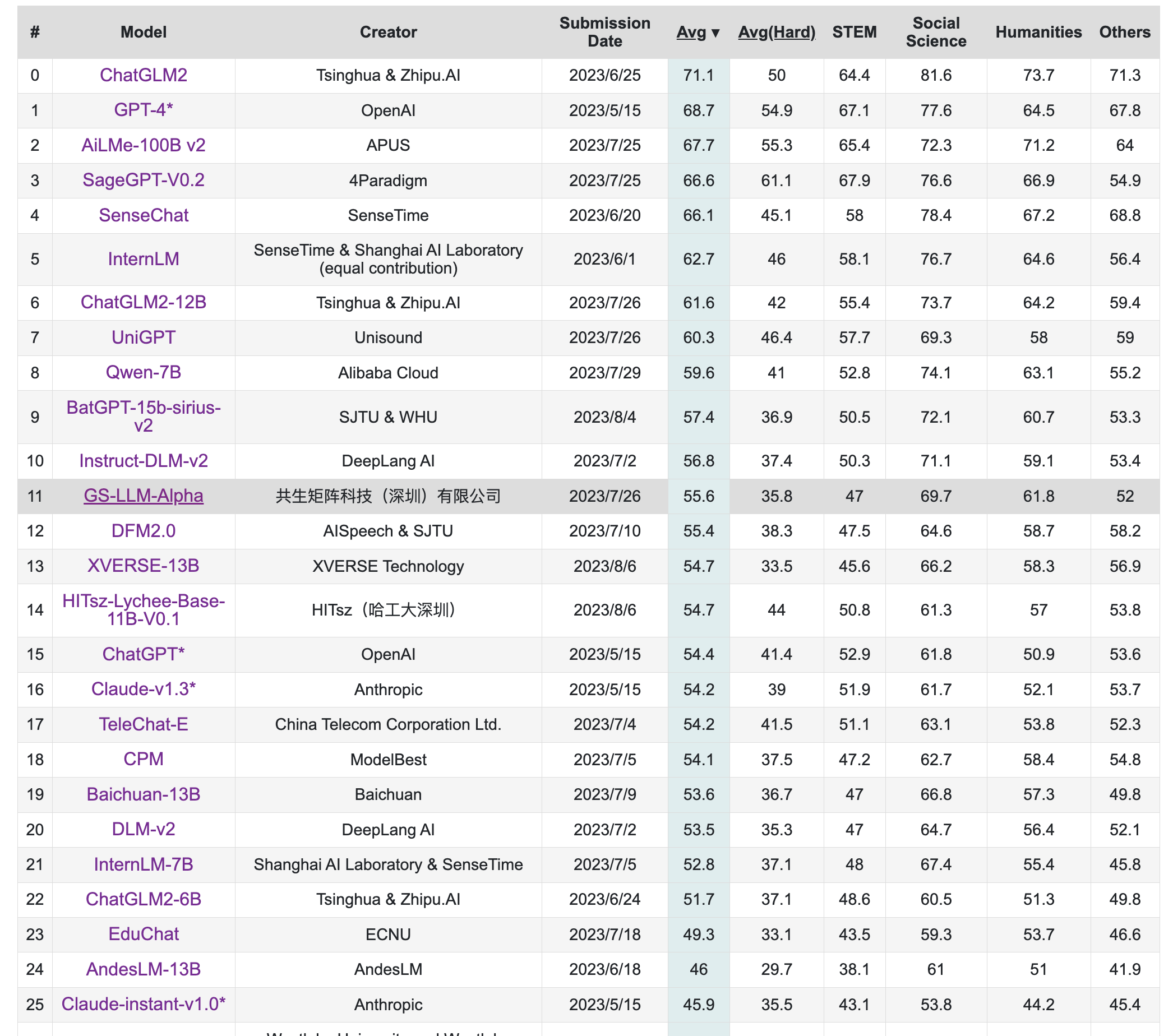
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

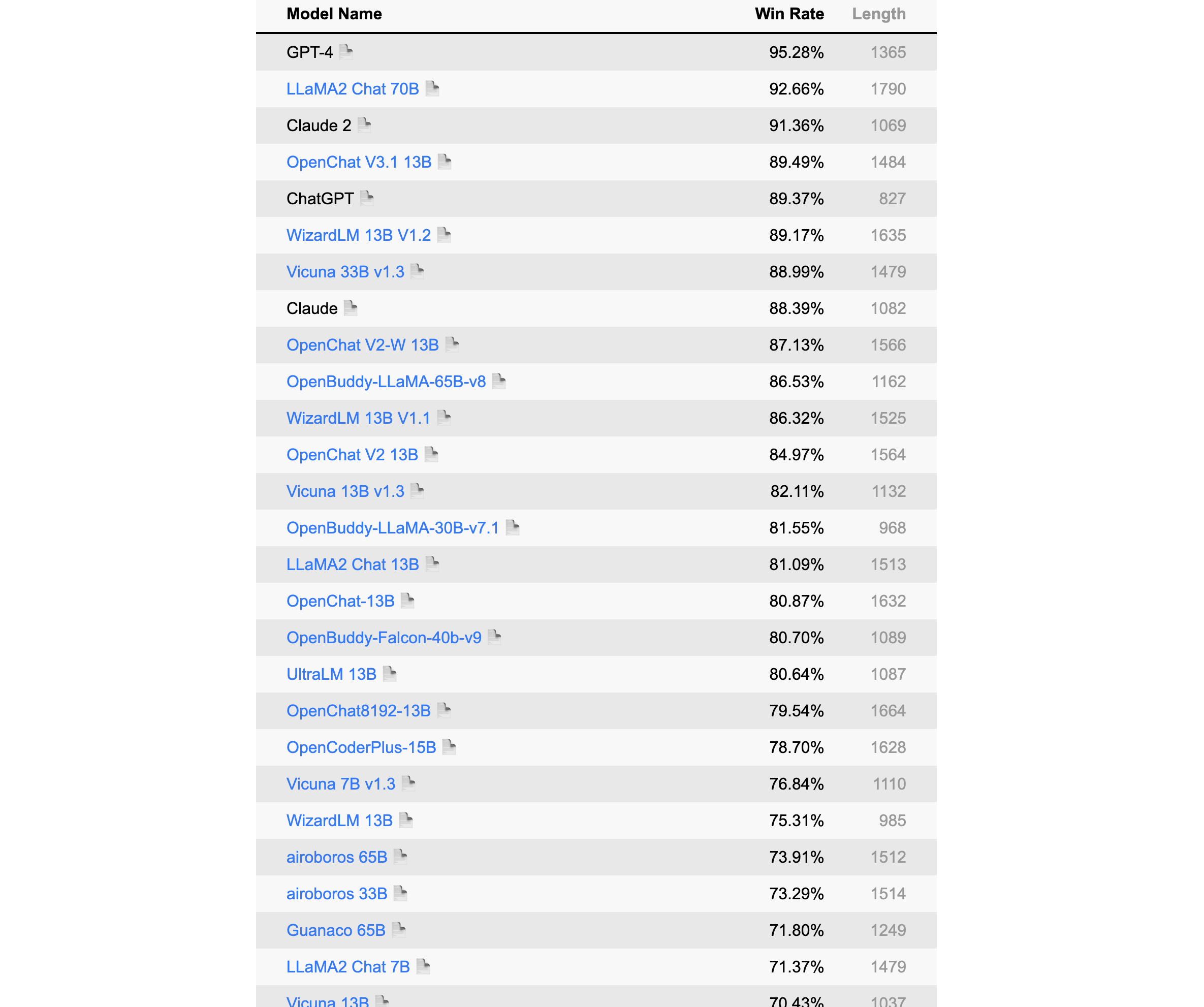
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


