FindTheChatGPTer
1.0.0
CHATGPT/GPT4 с открытым исходным кодом «простая замена», непрерывное обновление
CHATGPT стал популярным, и многие внутренние университеты, исследовательские институты и предприятия выпустили планы выпуска, аналогичные CHATGPT. CHATGPT не является открытым исходным кодом, и его чрезвычайно трудно воспроизвести. Даже сейчас ни одно подразделение или предприятие не воспроизводило полные возможности GPT3. Только сейчас, Openai официально объявил о выпуске модели GPT4 с мультимодальной графикой и текстом, и ее возможности были значительно улучшены по сравнению с CHATGPT. Кажется, что он пахнет четвертой промышленной революцией, в которой доминирует общий искусственный интеллект.
Будь то за границей или дома, разрыв между Openai становится больше и больше, и все догоняют занятым образом, поэтому они находятся в определенной выгодной позиции в этом технологическом инновациях. В настоящее время исследования и разработки многих крупных предприятий в основном выходят по маршруту с закрытым исходным кодом. У официально опубликовано несколько деталей, опубликованных CHATGPT и GPT4, и это не похоже на предыдущее введение в статье, в котором появилась десятки страниц, появилась эпоха коммерциализации OpenAI. Конечно, некоторые организации или отдельные лица изучили замены с открытым исходным кодом. Эта статья суммирована следующим образом. Я буду продолжать отслеживать их. Существуют обновленные замены с открытым исходным кодом, чтобы своевременно обновлять это место.
Этот тип метода в основном принимает нелама и другие методы тонкой настройки для независимого проектирования или оптимизации моделей GPT и T5, а также реализует процессы полного цикла, такие как предварительное обучение, контролируемая тонкая настройка и обучение подкреплению.
Chatyuan (Yuanyu AI) разрабатывается и опубликован командой Unyanyu Intelligent Development. Он утверждает, что является первой функциональной моделью диалога в Китае. Он может писать статьи, делать домашнее задание, писать стихи и переводить китайский и английский; Некоторые конкретные области, такие как законы, также могут предоставить соответствующую информацию. Эта модель в настоящее время поддерживает только китайский язык, а ссылка Github:
https://github.com/clue-ai/chatyuan
Судя по раскрытым техническим деталям, базовый уровень принимает модель T5 с масштабами 700 миллионов параметров, а также контролирует и тонкие находы на основе rackclclue для формирования Chatyuan. Эта модель в основном является первым шагом трехступенчатого технического маршрута CHATGPT, и никакого обучения модели вознаграждения и обучения подкрепления PPO не выполнено.
Недавно Colossalai Open Source их реализация CHATGPT. Поделитесь своей трехэтапной стратегией и полностью реализуйте технический маршрут Catgpt Core: его GitHub выглядит следующим образом:
https://github.com/hpcaitech/colossalai
Основываясь на этом проекте, я разъяснил трехэтапную стратегию и поделился им:
Первый этап (stare1_sft.py): этап точной настройки SFT, проект с открытым исходным кодом не был реализован, это относительно просто, потому что Colossalai плавно поддерживает объятие. Я напрямую использую несколько строк функции тренажера Code of HuggingFace, чтобы легко ее реализовать. Здесь я использовал модель GPT2. С своей точки зрения реализации он поддерживает модели GPT2, OPT и Bloom;
Второй этап (stear2_rm.py): тренировочный этап модели вознаграждения (RM), то есть часть Train_Reward_Model.py в примерах проекта;
Третий этап (stare3_ppo.py): этап подкрепления (RLHF), то есть Project Train_prompts.py
Выполнение трех файлов должно быть размещено в проекте Colossalai, где ядра в коде представляют собой CHATGPT в оригинальном проекте, а cores.nn становится Chatgpt.Models в оригинальном проекте.
Chatglm - это диалога серии GLM серии Zhipu AI, компании, которая преобразует технологические достижения в Tsinghua, поддерживает китайские и английские языки и в настоящее время имеет модель параметров 6,2 миллиарда. Он унаследовал преимущества GLM и оптимизирует архитектуру модели, тем самым снижая порог для развертывания и применения, реализуя применение логирования крупных моделей на потребительских видеокартах. Для получения подробных методов, пожалуйста, обратитесь к его GitHub:
Адрес с открытым исходным кодом Chatglm-6b: https://github.com/thudm/chatglm-6b
С технической точки зрения, он внедрил CHATGPT, усиленное изучением стратегии выравнивания человека, что делает эффект генерации лучше и ближе к человеческой ценности. Его текущие области способностей в основном включают в себя самообзнавание, написание наброска, копирайтинг, помощник по написанию электронной почты, извлечение информации, ролевое воспроизведение, сравнение комментариев, консультации по путешествиям и т. Д. Он разработал модель супер-широкого уровня 130 миллиардов под внутренним тестированием, которая считается моделью диалога с большей шкалой параметров в текущей замене с открытым исходным кодом.
VisualGlm-6B (обновлен 19 мая 2023 г.)
Команда недавно открыла мультимодальную версию Chatglm-6B, которая поддерживает мультимодальный диалог на изображениях, китайском и английском языке. В детали языковой модели используется Chatglm-6b, а часть изображения строит мост между визуальной моделью и языковой моделью путем обучения Blip2-Qformer. Общая модель имеет в общей сложности 7,8 миллиарда параметров. VisualGLM-6B опирается на 30-метровые высококачественные китайские графические пары из набора данных Cogview и предварительно обучен с 300-метровым фильтрованным английским графическими парами, с таким же весом на китайском и английском языке. Этот метод обучения лучше выравнивает визуальную информацию в семантическое пространство Чатглма; На последующей стадии тонкой настройки модель обучается длинным визуальным данным вопросов и ответов, чтобы генерировать ответы, которые соответствуют человеческим предпочтениям.
VisualGlmGlm-6b Адрес открытого исходного кода: https://github.com/thudm/visualglm-6b
Chatglm2-6b (обновляется 27 июня 2023 г.)
Команда недавно открыла версию второго поколения в Chatglm Sourced Chatglm Chatglm2-6b. По сравнению с версией первого поколения, ее основные функции включают использование более крупной шкалы данных, от 1t до 1,4t; Наиболее заметным является его более длинная контекстная поддержка, которая расширилась с 2K до 32K, что позволило более длинные и более высокие раунды входов; Кроме того, скорость вывода была значительно оптимизирована, увеличение на 42%, а ресурсы видео памяти были значительно сокращены.
Чатглм2-6B Адрес с открытым исходным кодом: https://github.com/thudm/chatglm2-6b
Он известен как первый проект замены CHATGPT с открытым исходным кодом, и его основная идея основана на архитектуре большой модели Google Language Big Model Palm и использовании методов обучения подкреплению (RLHF) из обратной связи человека. PALM-это 540 миллиарда параметров, всеобъемлющая модель, выпущенная Google в апреле этого года, на основе обучения системы Pathways. Он может выполнять такие задачи, как написание кода, чат, понимание языка и т. Д., И обладает мощной эффективностью обучения с низкой выборкой по большинству задач. В то же время принимается механизм обучения, подобный CATGPT, который может сделать ответы AI больше в соответствии с требованиями сценариев и уменьшить токсичность модели.
Адрес GitHub: https://github.com/lucidrains/palm-rlhf-pytorch
Проект известен как крупнейшая модель с открытым исходным кодом, до 1,5 триллиона и является мультимодальной моделью. Его домены способностей включают понимание естественного языка, машинный перевод, интеллектуальный вопрос и ответ, анализ настроений и графическое сопоставление и т. Д. Его адрес с открытым исходным кодом:
https://huggingface.co/banana-dev/gptrillion
(24 мая 2023 года этот проект - апрельская программа шутки на день дураков. Проект был удален. Я объясню это настоящим
OpenFlamingo-это структура, которая сравнивает GPT-4 и поддерживает обучение и оценку крупномасштабных мультимодальных моделей. Он был выпущен некоммерческим Laion и является воспроизведением модели Flamingo DeepMind. В настоящее время открытым исходным кодом является его модель OpenFlaming-9B на основе Llama. Модель Flamingo обучается крупномасштабному сетевому корпусу, содержащему межполосный текст и изображения, и обладает способностью изучать образцы ограниченных контекстами. OpenFlamingo реализует ту же архитектуру, предложенную в исходном фламинго, обученном 5-метровым образцам из нового мультимодального набора данных C4 и 10-метровых образцов из Laion-2B. Адрес с открытым исходным кодом этого проекта:
https://github.com/mlfoundations/open_flamingo
21 февраля этого года Университет Фудана выпустил Мосс и открыл публичную бета -версию, что вызвало некоторые противоречия после публичного бета -краха. Теперь проект открыл важные обновления и открытый исходный код. Мосс с открытым исходным кодом поддерживает как китайские, так и английские языки, и поддерживает интеллектуальную интеллектуальную подключаемость, такую как решение уравнений, поиск и т. Д. Параметры составляют 16b, и предварительно обучен примерно в 700 миллиардах китайских и английских слов и кодовых слов. Последующие инструкции по диалогу являются тонкими настройками, подключаемые усовершенствованные обучения и тренировки для человеческих предпочтений имеют несколько раундов диалоговых возможностей и возможность использовать несколько плагинов. Адрес с открытым исходным кодом этого проекта:
https://github.com/openlmlab/moss
Подобно Minigpt-4 и Llava, это мультимодальная модель с открытым исходным кодом с открытым исходным кодом GPT-4, которая продолжает модульную тренировочную идею серии MPLUG. В настоящее время он открывает модель количества параметров 7b, и в то же время он впервые предлагает всесторонний тестовый набор «Овлевал» для понимания визуальных инструкций. Благодаря ручной оценке существующие модели, включая Llava, Minigpt-4 и другую работу, демонстрируют лучшие мультимодальные возможности, особенно в области мультимодальных инструкций по пониманию инструкций, способностям мульти круглых диалогов, способности рассуждать знания и т. Д. Столетно, что, как и другие графические и текстовые модели, все равно поддерживает только английский, но китайская версия уже находится в списке с открытым исходным исходным исходным.
Адрес с открытым исходным кодом этого проекта: https://github.com/x-plug/mplug-owl
Pandalm-это модель модели оценки, которая направлена на автоматическую оценку предпочтений других крупномасштабных моделей для создания контента, экономии затрат на оценку ручной оценки. Pandalm поставляется с веб -интерфейсом для анализа, а также поддерживает кодовые вызовы Python. Он может оценить текст, сгенерированный любой моделью и данных только с тремя строками кода, которые очень удобны в использовании.
Адрес проекта с открытым исходным кодом: https://github.com/weopenml/pandalm
На конференции Чжиюанна, состоявшейся недавно, Научно -исследовательский институт Чжийюан открыл источник своей модели Просвещения и Sky Eagle, которая обладает двуязычными знаниями о китайском и английском языке. Основные параметры модели версии с открытым исходным кодом включают 7 миллиардов и 33 миллиарда. В то же время он открывает модель диалога Aquilachat и модель генерации текстовых кодов Quilacode, и оба были открыты для коммерческих лицензий. Аквила принимает архитектуры только для декодеров, такие как GPT-3 и Llama, а также обновляет словарный запас для китайского и английского двуязычия, и принимает свой метод ускоренного обучения. Его гарантия производительности зависит не только от оптимизации и улучшения модели, но также выигрывает от накопления высококачественных данных о крупных моделях в больших моделях.
Адрес проекта с открытым исходным кодом: https://github.com/flagai-open/flagai/tree/master/examples/aquila
Недавно Microsoft опубликовала многомодальную большую модельную бумагу и открытый исходный код -коди, который полностью соединяет текстовый голос-видео, поддерживает произвольный ввод и произвольный модальный выход. Чтобы достичь генерации произвольных методов, исследователи разделили обучение на два этапа. На первом этапе автор использовал стратегию выравнивания моста и комбинированные условия для обучения, создавая потенциальную модель диффузии для каждого режима; На втором этапе к каждой потенциальной диффузионной модели и экологическому экологическому экологическому модулю был добавлен модуль внимания пересечения, что могло бы проецировать скрытые переменные потенциальной диффузионной модели в общее пространство, чтобы сгенерированные методы были еще более диверсифицированы.
Адрес с открытым исходным кодом этого проекта: https://github.com/microsoft/i-code/tree/main/i-code-v3
Meta запустила и открыл свой мультимодальный Big Model -Bind, который может достичь 6 модальностей, включая изображение, видео, аудио, глубину, тепло и пространственное движение. ImageBind решает проблему выравнивания, используя характеристики привязки изображений, используя большие модели визуального языка и возможности с нулевым образцом для расширения до новых методов. Данные пары изображений достаточно, чтобы связать эти шесть режимов вместе, позволяя различным режимам открывать модальные расколы друг от друга.
Адрес проекта с открытым исходным кодом: https://github.com/facebookresearch/imagebind
10 апреля 2023 года Ван Сяочуань официально объявил о создании компании AI Big Model Company "Baichuan Intelligence", стремясь создать китайскую версию Openai. Через два месяца после его создания Baichuan Intelligent стала основным источником своей независимо разработанной модели Baichuan-7B, поддерживающей китайский и английский язык. Baichuan-7b не только превосходит другие крупные модели, такие как Chatglm-6b, со значительными преимуществами в списке авторитетных оценки C-Eval, Agieval и Gaokao, но также значительно возглавляет Llama-7B в списке авторитетных оценки MMLU. Эта модель достигает масштаба токенов триллиона в высококачественных данных и поддерживает возможность расширения десятков тысяч сверхпрочных динамических окон на основе эффективной оптимизации оператора внимания. В настоящее время открытый исходный код поддерживает контекстные возможности 4K. Эта модель с открытым исходным кодом является коммерчески доступной и более дружелюбна, чем лама.
Адрес проекта с открытым исходным кодом: https://github.com/baichuan-inc/baichuan-7b
6 августа 2023 года команда Yuanxiang Xverse открыла модель Xverse-13b. Эта модель представляет собой многоязычную большую модель, которая поддерживает до 40+ языков и поддерживает контекстуальную длину до 8192. Согласно команде, особенности этой модели: Структура модели: xverse-13b использует основную стандартную структуру трансформатора только для декодера, поддерживает длину 8K контекста, которая является самой длинной из одной и той же размера и может соответствовать потребностям более длительного многоуровневого диалога, знаний, и а также и самая настоящая; Данные обучения: 1,4 триллиона токенов высококачественных и разнообразных данных созданы для полного обучения модели, в том числе 40 китайских, английских, русских и западных. Несколько языков, мелко устанавливая коэффициент выборки различных типов данных, китайские и английские языки работают хорошо, а также могут учитывать влияние других языков; Сегментация слов: на основе алгоритма BPE, сегментации слов с размер словарного запаса 100 278 была обучена с использованием сотен корпуса ГБ, который может поддерживать несколько языков одновременно без дополнительного расширения списка слов; Обучающая структура: независимо разработана ряд ключевых технологий, включая эффективные операторы, оптимизация видео памяти, стратегии параллельного планирования, совпадение с коммуникацией данных, совместное сотрудничество платформы и каркас и т. Д., Став эффективность обучения и стабильность модели. Пиковая скорость использования вычислительной мощности в кластере килокард может достигать 58,5%, ранжируя среди переднего фонда в отрасли.
Адрес с открытым исходным кодом этого проекта: https://github.com/xverse-ai/xverse-13b
3 августа 2023 года 7 миллиардов модели Alibaba Tongyi Qianwen была открытым исходным кодом, включая общие модели и модели диалога, а также открытый, бесплатный и коммерчески доступный. Согласно отчетам, QWEN-7B представляет собой большую языковую модель, основанную на трансформаторе, и обучается на данных предварительного обучения в супер-широких масштабах. Типы данных предварительного обучения разнообразны и охватывают широкий спектр областей, включая большое количество онлайн-текстов, профессиональных книг, кодов и т. Д. Это модель док-станции, которая поддерживает китайские и английские языки, обученные более 2 триллионам токенов, а длина окна контекста достигает 8K. QWEN-7B-Chat-это модель диалога китайского английского языка, основанная на модели пьедестала QWEN-7B. Предварительно обученная модель Tongyi Qianwen 7B хорошо выполнялась в нескольких авторитетных эталонных оценках. Его китайские и английские возможности намного превышают модели с открытым исходным кодом того же масштаба в домашних условиях и за рубежом, и некоторые возможности даже превысили модели с открытым исходным кодом 12B и 13B.
Адрес проекта с открытым исходным кодом: https://github.com/qwenlm/qwen-7b
Llama-это совершенно новая крупномасштабная модель языка искусственного интеллекта, выпущенная Meta, которая хорошо выполняет такие задачи, как генерирование текста, диалог, суммирование письменных материалов, доказывание математических теорем или прогнозирование белковых структур. Модель Llama поддерживает 20 языков, включая латинские и кириллические алфавитные языки. В настоящее время оригинальная модель не поддерживает китайский. Можно сказать, что эпическая утечка ламы энергично продвигала развитие с открытым исходным кодом Chatgpt.
(Обновлено 22 апреля 2023 года), но, к сожалению, разрешение Llama в настоящее время ограничено и может использоваться только для научных исследований и не разрешено для коммерческого использования. Чтобы решить коммерческую проблему с полным открытым исходным кодом, проект Redpajama возник, стремясь создать полностью реплику Llama с открытым исходным кодом, которую можно использовать для коммерческих применений и обеспечить более прозрачный процесс для исследований. Полный Redpajama включает в себя набор данных токенов 1,2 триллиона, и его следующим шагом будет начало крупномасштабного обучения. Эта работа по -прежнему стоит с нетерпением ждать, и ее адрес с открытым исходным кодом:
https://github.com/togethercomputer/redpajama-data
(Обновлено 7 мая 2023 г.)
Redpajama обновил свой файл обучающей модели, включая два параметра: 3B и 7B, где 3B может работать на игровой карте RTX2070, выпущенной 5 лет назад, компенсируя разрыв в ламе на 3B. Его модельный адрес:
https://huggingface.co/togethercomputer
В дополнение к Redpajama, Mosaicml запустила модель серии MPT, а в ее обучающих данных используются данные Redpajama. При различных оценках производительности модель 7b сопоставима с исходной ламой. Адрес с открытым исходным кодом его модели:
https://huggingface.co/mosaicml
Будь то Redpajama или MPT, это также открывает соответствующую модель версии чата. Открытый источник этих двух моделей принес огромный импульс для коммерциализации Chatgpt.
(Обновлено 1 июня 2023 г.)
Falcon - это открытая большая модельная база, которая сравнивает ламу. Он имеет две шкалы измерения параметров: 7b и 40b. Производительность 40b известна как ультра-высокая 65b llama. Понятно, что Falcon по -прежнему использует модель Autoregressive Decoder GPT, но он приложил много усилий в данные. После очистки контента из общедоступной сети и создания первоначального набора данных предварительно предопределяется, он использует дамп CommonCrawl для выполнения крупномасштабной фильтрации и крупномасштабной дедупликации и, наконец, получает огромный набор данных, состоящий из почти 5 триллионов жетонов. В то же время были добавлены многие избранные корпусы, включая исследовательские работы и разговоры в социальных сетях. Тем не менее, разрешение проекта было спорным, и принят «полукоммерческий» метод авторизации, и 10% коммерческих расходов начнут произойти после того, как доход достиг 1 миллиона.
Адрес проекта с открытым исходным кодом: https://huggingface.co/tiiuae
(Обновлено 3 июля 2023 г.)
Первоначальному соколу не хватает китайских возможностей поддержки, таких как Llama. Проектная команда «Linly» построила и открыла китайскую версию китайского фалькона на основе модели Falcon. Модель впервые расширила и значительно расширила список словарного запаса, в том числе 8701 обычно используемые китайские иероглифы, первые 20 000 китайских высокочастотных слов в списке словарного запаса Цзиба и 60 китайских знаков пунктуации. После дедупликации размер списка словаря был расширен до 90 046. На этапе обучения для обучения использовались 50G Corpus и 2T крупномасштабные данные.
Адрес проекта с открытым исходным кодом: https://github.com/cvi-szu/linly
(Обновлено 24 июля 2023 г.)
Первоначальному соколу не хватает китайских возможностей поддержки, таких как Llama. Проектная команда «Linly» построила и открыла китайскую версию китайского фалькона на основе модели Falcon. Модель впервые расширила и значительно расширила список словарного запаса, в том числе 8701 обычно используемые китайские иероглифы, первые 20 000 китайских высокочастотных слов в списке словарного запаса Цзиба и 60 китайских знаков пунктуации. После дедупликации размер списка словаря был расширен до 90 046. На этапе обучения для обучения использовались 50G Corpus и 2T крупномасштабные данные.
Адрес проекта с открытым исходным кодом: https://github.com/cvi-szu/linly
Alpaca (модель Alpaca), выпущенная Стэнфордом, представляет собой новую модель, основанную на модели Llama-7B. Основной принцип состоит в том, чтобы позволить модели Openai Text-Davinci-003 для создания 52-километровых образцов в самостоятельной настройке ламы. Проект открыл данные обучения источника, код для генерации данных обучения и гиперпараметры. Модельный файл еще не был открыт, достигнув более 5,6 тыс. Звезд за один день. Эта работа очень популярна благодаря своей низкой стоимости и легком доступе к данным, а также открыла путь к имитации недорогих CHATGPT. Его адрес GitHub:
https://github.com/tatsu-lab/stanford_alpaca
Это реализация с открытым исходным кодом чат -бота LLAMA+AI, основанная на обучении подкреплению обратной связи человека, запущенным Nebuly+AI. Его технический маршрут похож на CHATGPT. Проект только что был запущен в течение 2 дней и выиграл 5,2 тыс. Звезд. Его адрес GitHub:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
Алгоритм процесса обучения Chatllama в основном используется для достижения более быстрого и более дешевого обучения, чем CHATGPT. Говорят, что это почти в 15 раз быстрее. Основные особенности:
Полная реализация с открытым исходным кодом позволяет пользователям создавать услуги в стиле CHATGPT на основе предварительно обученных моделей LLAMA;
Архитектура ламы меньше, что делает учебный процесс и рассуждает быстрее и дешевле;
Встроенная поддержка DeepSpeed Zero, чтобы ускорить процесс тонкой настройки;
Поддерживает Llama Model Architectures различных размеров, и пользователи могут точно настроить модель в соответствии с их собственными предпочтениями.
OpenChatkit совместно создана командой вместе, где расположены бывшие исследователи Openai, а также команды Laion и Ontocord.ai. OpenChatkit содержит 20 миллиардов параметров и точно настроен с версией GPT-3 с открытым исходным кодом GPT-NOX-20B. В то же время, различное обучение подкреплению чатгптов, OpenChatkit использует модель аудита параметров 6 миллиардов для фильтрации неподходящей или вредной информации для обеспечения безопасности и качества сгенерированного контента. Его адрес GitHub:
https://github.com/togethercomputer/openchatkit
Основываясь на Стэнфордской Альпаке, контролируемая точная настройка реализуется на основе Блума и Ламы. Задачи Стэнфордской Альпаки все на английском языке, а собранные данные также на английском языке. Этот проект с открытым исходным кодом состоит в том, чтобы продвигать развитие китайского диалога Big Model Community с открытым исходным кодом. Он был оптимизирован для китайца. Настройка модели использует только данные, созданные CHATGPT (не включая какие -либо другие данные). Проект содержит следующее:
175 китайских миссий семян
Код для генерации данных
Данные, сгенерированные 10 млн. В настоящее время открыты с 1,5 млн., 0,25 млн. Математических наборов данных и наборов данных с несколькими раундами 0,8 м.
Оптимизированная модель на основе Bloomz-7B1-MT и Llama-7B
Адрес Github: https://github.com/lianjiatech/belle
Alpaca-Lora-еще один шедевр в Стэнфордском университете. Он использует технологию LORA (низкодовольная адаптация) для воспроизведения результатов Alpaca, используя более дешевый метод, и обучался только на графической карте RTX 4090 в течение 5 часов, чтобы получить модель с уровнем альпаки. Кроме того, модель может работать на Raspberry Pi. В этом проекте он использует печать Huging Face для дешевой и эффективной точной настройки. PEFT-это библиотека (LORA-одна из ее поддерживаемых технологий), которая позволяет вам использовать различные языковые модели на основе трансформатора и тонко настраивать их с LORA, что позволяет получить недорогую и эффективную точную настройку модели на общем оборудовании. Адрес GitHub этого проекта:
https://github.com/tloen/alpaca-lora
Хотя Альпака и Альпака-Лора добились значительных успехов, их семенные задачи находятся на английском языке и не имеют поддержки китайца. С одной стороны, в дополнение к вышеупомянутым, что Belle собрала большое количество китайского корпуса, с другой стороны, на основе работы предшественников, таких как Alpaca-Lora, модель китайского языка Luotuo (luotuo), открытые тремя отдельными разработчиками из центрального китайского университета и других учреждений, одна карта может завершить обучение. В настоящее время проект выпускает две модели Luotuo-Lora-7b-0.1, Luotuo-Lora-7b-0.3, и одна модель находится в плане. Его адрес GitHub:
https://github.com/lc1332/chinese-alpaca-lora
Вдохновленная Alpaca, Долли использовала набор данных Alpaca для достижения точной настройки на GPT-J-6B. Поскольку сама Долли является «клоном» модели, команда наконец решила назвать это «Долли». Вдохновленный Alpaca, этот метод клонирования становится все более популярным. Таким образом, это примерно принятый метод сбора данных с открытым исходным кодом Alpaca и инструкции с тонкой настройкой на старых моделях размера 6B или 7B для достижения эффектов, подобных ChatGPT. Эта идея очень экономична и может быстро подражать очарованию Chatgpt. Он очень популярен, и как только он был запущен, он полон звезд. Адрес GitHub этого проекта:
https://github.com/databrickslabs/dolly
После запуска Alpaca Stanford Scholars объединился с CMU, UC Berkeley и т. Д., Чтобы запустить новую модель - Vicuna с 13 миллиардами параметров (обычно известных как Alpaca и Llama). Это стоит всего 300 долларов США для достижения 90% производительности CHATGPT. Vicuna используется для точной настройки Llama на диалоге с положением пользователей, собранным ShareGPT. Процесс тестирования использует GPT-4 в качестве критериев оценки. Результаты показывают, что Vicuna-13b достигает возможностей, которые соответствуют CHATGPT и BARD в более чем 90% случаев.
UC Berkeley Lmsys Org недавно выпустила Vicuna с 7 миллиардами параметров. Он не только небольшой по размеру, высокой эффективности и сильной способности, но также может работать на Mac с чипом M1/M2 всего за две строки команды, а также может обеспечить ускорение графического процессора!
GitHub с открытым исходным кодом: https://github.com/lm-sys/fastchat/
Другая китайская версия была открыта Китай-Викуной, с адресом GitHub AS:
https://github.com/facico/chinese-vicuna
После того, как Чатгп стал популярным, люди искали быстрый путь в храм. Появились некоторые появления, подобные Чатгпту, особенно после того, как Чатгпт по низкой стоимости стал популярным способом. LMFLOW - это продукт, родившийся в этом сценарии спроса, который позволяет уточнить крупные модели на обычных видеокартах, таких как 3090. Большая модельная система обучения, которая более эффективна, чем предыдущие методы.
Используя этот проект, даже ограниченные вычислительные ресурсы могут позволить пользователям поддерживать персонализированное обучение для проприетарных областей. Например, Llama-7B, 3090, требуется 5 часов, чтобы завершить обучение, что значительно снижает стоимость. Проект также открывает услуги по вопросам и ответам на веб-сайт Instant Experience (lmflow.com). Появление и открытый исходный код LMFLOW позволяют обычным ресурсам для обучения различных задач, таких как вопросы и ответы, общение, письмо, перевод, экспертные полевые консультации и т. Д. Многие исследователи в настоящее время пытаются использовать этот проект для обучения крупных моделей с объемом параметров 65 миллиардов или даже выше.
Адрес GitHub этого проекта:
https://github.com/optimalscale/lmflow
Проект предлагает метод автоматического сбора разговоров CHATGPT, позволяя CHATGPT разговор с самостоятельностью, партия генерировать высококачественные наборы данных многоуровневых диалогов и собирать около 50 000 высококачественных качественных вопросов Quora, Stackoverflow и Medqa, соответственно, и он был открыт. В то же время это улучшило модель ламы, и эффект довольно хороший. Bai ZE также принял нынешнее недорогое решение для тонкой настройки LORA, чтобы получить три различных шкала: BAI ZE-7B, 13B и 30B, а также модель в вертикальной области медицинской помощи. К сожалению, китайское имя хорошо названо, но оно все еще не поддерживает китайцев. Китайская модель Bai ZE, как сообщается, находится в соответствии с планом и будет выпущена в будущем. Его адрес GitHub с открытым исходным кодом:
https://github.com/project-baize/baize
Плоская замена Chatgpt, базирующаяся в ламе, продолжает бродить, Berkeley UC Berkeley выпустила модель разговора, которая может работать на потребительских графических процессорах с параметрами 13B. Обучающий набор данных Koala включает в себя следующие детали: данные CHATGPT и данные с открытым исходным кодом (Open Trancing Generalist (OIG), набор данных, используемый Стэнфордской моделью альпаки, Anpropic HH, Openai Webgpt, Summarization OpenAI). Модель Koala реализована в Easylm с использованием JAX/лен, используя 8 A100 графических процессоров, и для завершения 2 итераций требуется 6 часов. Эффект оценки лучше, чем Alpaca, достигая 50% производительности CHATGPT.
Адрес с открытым исходным кодом: https://github.com/young-geng/easylm
С появлением Стэнфордской Альпаки, большое количество семей Альпака из ламы и расширенные семьи животных начали появляться, и, наконец, обнимая исследователей лица недавно опубликовало блог Стеклламу: практическое руководство по обучению ламы с RLHF. В то же время была также выпущена модель параметров 7 миллиардов - Stackllama. Это модель, которая тонко настроена в Llama-7B с помощью обучения подкреплению обратной связи. Для получения подробной информации см. Его адрес блога:
https://huggingface.co/blog/stackllama
Проект оптимизирует ламу для китайской и открывает свою тонкую систему диалога. Конкретные шаги этого проекта включают в себя: 1. Разверните список слов, используя предложение для обучения и построения на китайских данных, и объединен с списком слов Llama; 2. Предварительное обучение, в новом списке слов, было обучено около 20 г общего китайского корпуса, а технология LORA использовалась на обучении; 3. Используя Стэнфордскую Альпаку, на 51 тыс. Данных было проведено обучение с тонкой настройкой для получения способности диалога.
Адрес с открытым исходным кодом: https://github.com/ymcui/chinese-lama-alpaca
12 апреля DataBricks выпустила Dolly 2.0, известный как первый в отрасли с открытым исходным кодом, Directive-Socective LLM. Набор данных был создан сотрудниками DataBricks и был открыт и доступен для коммерческих целей. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
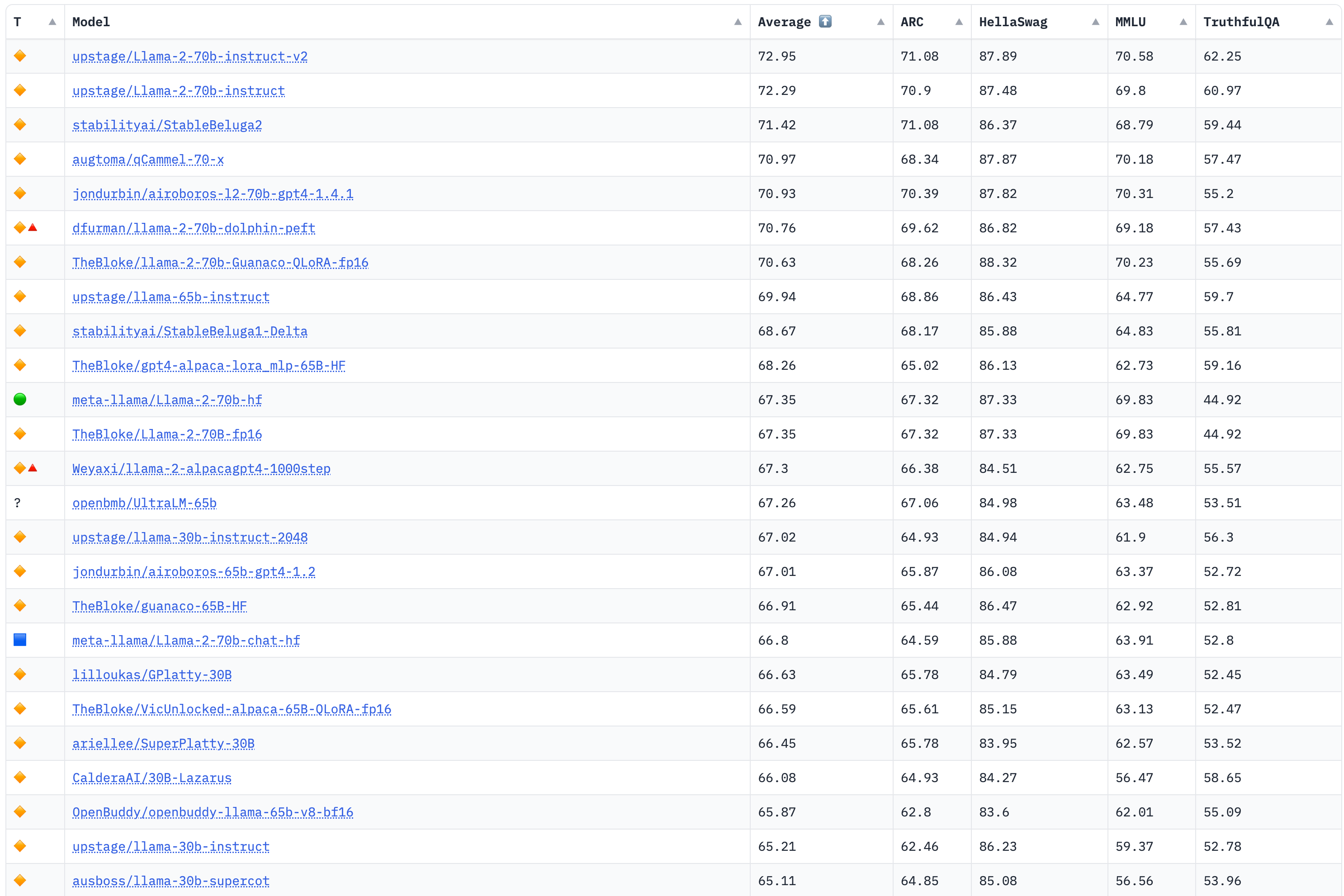
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
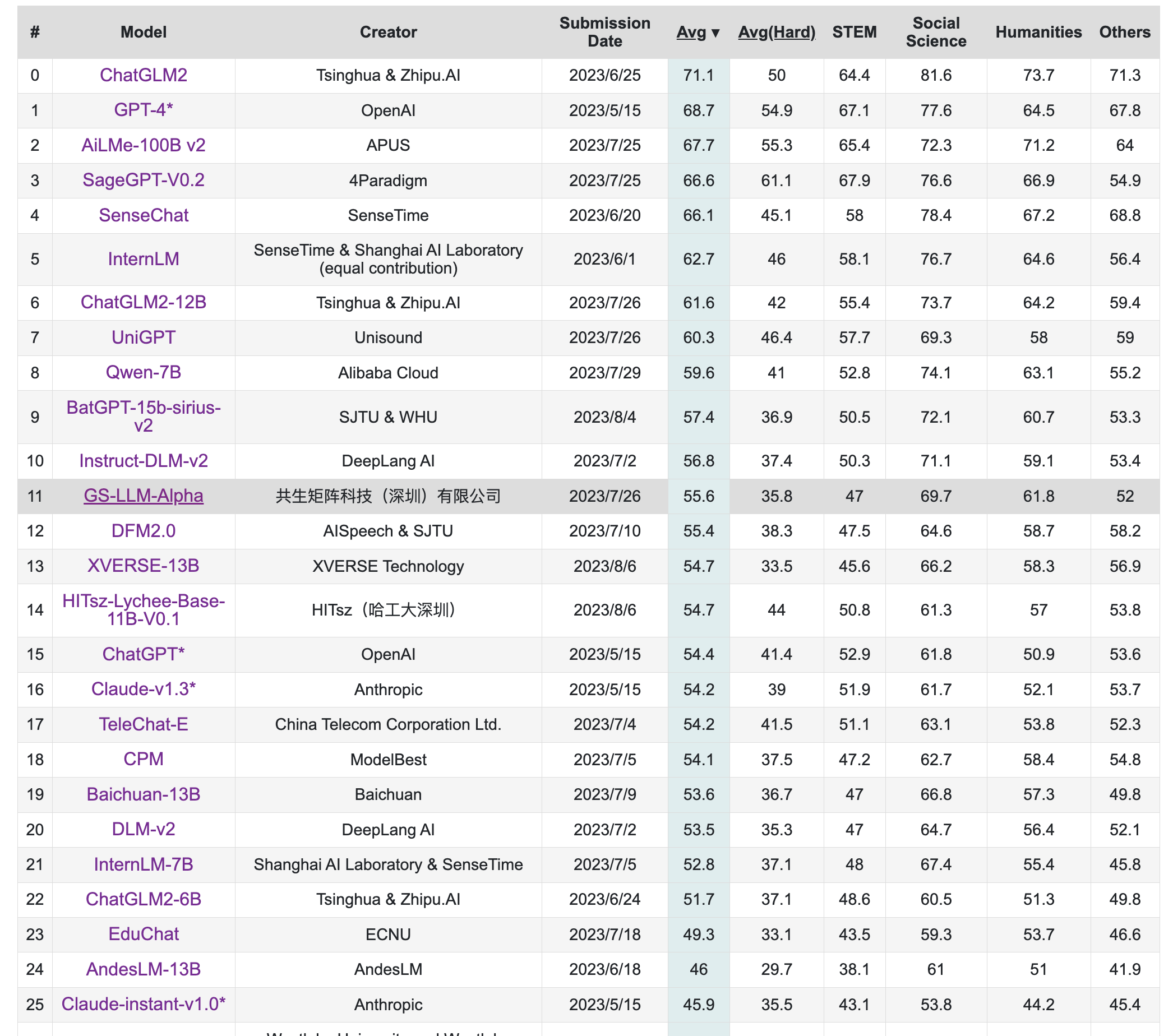
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
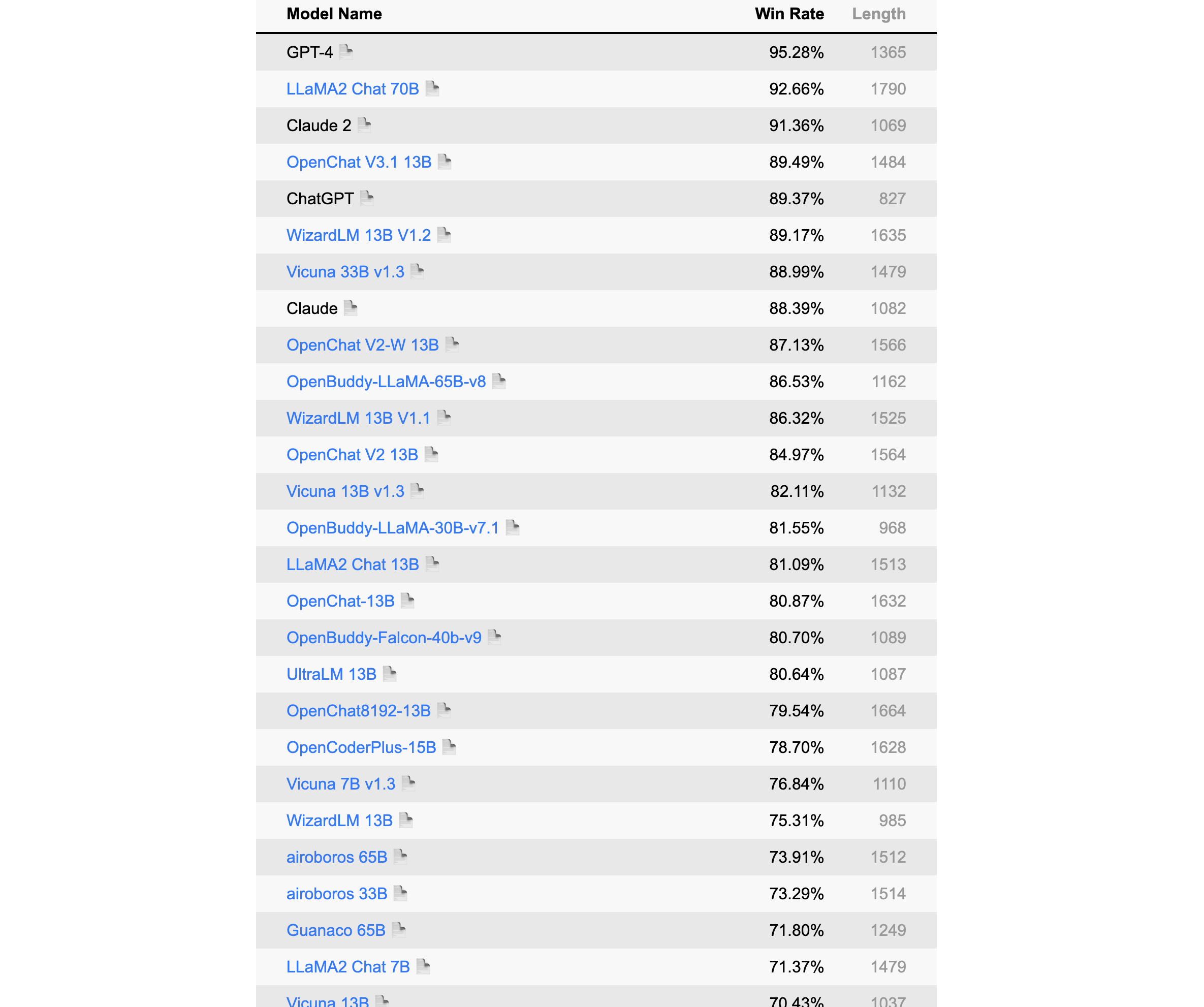
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts. This project is basically crowdfunding. We design Prompts together. It can be used to train ChatGPT, or it can be used to obtain the corpus by yourself in Stanford-alpaca. Есть две версии:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


