FindTheChatGPTer
1.0.0
chatgpt/gpt4 오픈 소스 "일반 교체"요약, 연속 업데이트
Chatgpt는 인기를 얻었으며 많은 국내 대학, 연구 기관 및 기업이 Chatgpt와 유사한 출시 계획을 발표했습니다. Chatgpt는 오픈 소스가 아니며 재생산하기가 매우 어렵습니다. 지금도 GPT3의 전체 기능을 재현 한 단위 나 기업은 없습니다. 방금 OpenAi는 공식적으로 멀티 모달 그래픽 및 텍스트로 GPT4 모델의 출시를 발표했으며 ChatGpt에 비해 그 기능이 크게 향상되었습니다. 그것은 일반적인 인공 지능에 의해 지배되는 네 번째 산업 혁명을 냄새 맡는 것 같습니다.
해외 또는 집에서 Openai 사이의 격차가 점점 커지고 있으며 모두가 바쁜 방식으로 따라 잡고 있기 때문에이 기술 혁신에서 어떤 유리한 위치에 있습니다. 현재 많은 대기업의 연구 개발은 기본적으로 폐쇄 소스 경로를 취하고 있습니다. Chatgpt와 GPT4가 공식적으로 발표 한 세부 사항은 거의 없으며, 수십 개의 페이지를 소개 한 이전 논문 소개와는 다릅니다. OpenAI의 상용화 시대가 도착했습니다. 물론 일부 조직이나 개인은 오픈 소스 교체를 탐색했습니다. 이 기사는 다음과 같이 요약되어 있습니다. 계속 추적 할 것입니다. 이 장소를 적시에 업데이트하기 위해 업데이트 된 오픈 소스 교체가 있습니다.
이 유형의 방법은 주로 비 롤라마 및 기타 미세 조정 방법을 채택하여 GPT 및 T5 모델을 독립적으로 설계하거나 최적화하고 사전 훈련, 감독 미세 조정 및 강화 학습과 같은 전체 사이클 프로세스를 실현합니다.
Chatyuan (Yuanyu AI)은 Yuanyu Intelligent Development Team에서 개발하고 출판했습니다. 그것은 중국 최초의 기능 대화 모델이라고 주장합니다. 그것은 기사를 쓰고, 숙제를하고,시를 쓰고, 중국어와 영어를 번역 할 수 있습니다. 법률과 같은 일부 특정 영역도 관련 정보를 제공 할 수 있습니다. 이 모델은 현재 중국 만 지원하며 Github 링크는 다음과 같습니다.
https://github.com/clue-ai/chatyuan
공개 된 기술적 세부 사항에서 판단하여 기본 계층은 7 억 개의 매개 변수의 척도를 가진 T5 모델을 채택하고 PromptClue를 기반으로 한 감독 및 미세 조정을하여 Chatyuan을 형성합니다. 이 모델은 기본적으로 3 단계 ChatGpt 기술 경로의 첫 번째 단계이며 보상 모델 교육 및 PPO 강화 학습 교육은 구현되지 않습니다.
최근 Colossalai Open Source chatgpt 구현. 3 단계 전략을 공유하고 Chatgpt Core의 기술 경로를 완전히 구현하십시오. Github는 다음과 같습니다.
https://github.com/hpcaitech/colossalai
이 프로젝트를 바탕으로 3 단계 전략을 명확히하고 공유했습니다.
첫 번째 단계 (Stage1_Sft.py) : SFT 감독 미세 조정 단계 인 오픈 소스 프로젝트가 구현되지 않았으며, Colossalai가 Huggingface를 원활하게 지원하기 때문에 비교적 간단합니다. Huggingface의 트레이너 기능 몇 줄을 직접 사용하여 쉽게 구현합니다. 여기서 GPT2 모델을 사용했습니다. 구현 관점에서 GPT2, OPT 및 Bloom 모델을 지원합니다.
두 번째 단계 (Stage2_rm.py) : 보상 모델 (RM) 교육 단계, 즉 프로젝트 예제의 Train_Reward_model.py 부분;
세 번째 단계 (Stage3_ppo.py) : 강화 학습 (RLHF) 단계, 즉 Project Train_prompts.py
세 가지 파일의 실행은 Colossalai 프로젝트에 배치해야하며, 여기서 코드의 코어는 원래 프로젝트에서 chatgpt이고 Cores.nn은 원래 프로젝트에서 chatgpt.models가됩니다.
ChatGLM은 Tsinghua의 기술 성과를 변화시키고 중국어 및 영어를 지원하며 현재 62 억 개의 매개 변수 모델을 보유하고있는 Zhipu AI의 GLM 시리즈의 대화 모델입니다. GLM의 장점을 상속하고 모델 아키텍처를 최적화하여 배포 및 응용 프로그램의 임계 값을 낮추어 소비자 그래픽 카드에서 대형 모델의 추론 적용을 실현합니다. 자세한 기술은 GitHub를 참조하십시오.
chatglm-6b의 오픈 소스 주소는 https://github.com/thudm/chatglm-6b입니다
기술적 인 관점에서, 그것은 인간 정렬 전략에 대한 Chatgpt 강화 학습을 구현하여 세대 효과를 더 좋고 인간의 가치에 더 가깝게 만듭니다. 현재의 능력 영역에는 주로 자기 인식, 개요 작성, 카피 라이팅, 이메일 쓰기 보조, 정보 추출, 롤 플레잉, 댓글 비교, 여행 조언 등이 포함됩니다. 내부 테스트에서 1,300 억 명의 초대형 모델을 개발했으며, 이는 현재 오픈 소스 교체품에서 더 큰 매개 변수 스케일을 가진 대화 모델로 간주됩니다.
VisualGLM-6B (2023 년 5 월 19 일에 업데이트)
이 팀은 최근 이미지, 중국어 및 영어에서 멀티 모달 대화를 지원하는 멀티 모달 버전의 ChatGLM-6B를 열었습니다. 언어 모델 부분은 ChatGLM-6B를 사용하며 이미지 부분은 Blip2-QFormer를 교육하여 시각적 모델과 언어 모델 사이의 브리지를 구축합니다. 전체 모델에는 총 78 억 개의 매개 변수가 있습니다. VisualGLM-6B는 Cogview 데이터 세트의 30m 고품질 중국 그래픽 쌍에 의존하며 300m 필터링 된 영어 그래픽 쌍으로 미리 훈련되며 중국어와 영어로 무게가 동일합니다. 이 훈련 방법은 시각 정보를 ChatGLM의 시맨틱 공간에 더 잘 정렬합니다. 후속 미세 조정 단계 에서이 모델은 긴 시각적 질문 및 답변 데이터에 대한 교육을 받아 인간의 선호도를 충족시키는 답변을 생성합니다.
VisualGlm-6b 오픈 소스 주소는 https://github.com/thudm/visualglm-6b입니다
Chatglm2-6b (2023 년 6 월 27 일에 업데이트)
이 팀은 최근에 소스 Chatglm의 2 세대 버전 Chatglm2-6B를 열었습니다. 1 세대 버전과 비교하여 주요 기능은 1T에서 1.4T의 더 큰 데이터 척도 사용을 포함합니다. 가장 두드러진 것은 더 긴 컨텍스트 지원으로 2k에서 32k로 확장되어 더 길고 높은 라운드의 입력을 허용하는 것입니다. 또한 추론 속도는 크게 최적화되었으며 42%증가했으며 차지하는 비디오 메모리 리소스가 크게 줄어들 었습니다.
chatglm2-6b 오픈 소스 주소는 https://github.com/thudm/chatglm2-6b입니다
그것은 최초의 오픈 소스 Chatgpt 교체 프로젝트로 알려져 있으며, 기본 아이디어는 Google 언어 Big Model Palm Architecture 및 Human Feedblice의 RLHF (Renforcement Learning Methods) 사용을 기반으로합니다. Palm은 Pathways System Training을 기반으로 올해 4 월 Google에서 출시 한 540 억 매개 변수의 올라운드 모델입니다. 코드 작성, 채팅, 언어 이해 등과 같은 작업을 완료 할 수 있으며 대부분의 작업에서 강력한 저 샘플 학습 성능을 제공합니다. 동시에 ChatGpt와 같은 강화 학습 메커니즘이 채택되어 AI의 답변을 시나리오 요구 사항에 따라 더 많이 만들고 모델 독성을 줄일 수 있습니다.
github 주소는 다음과 같습니다. https://github.com/lucidrains/palm-rlhf-pytorch
이 프로젝트는 최대 1.5 조의 최대 오픈 소스 모델로 알려져 있으며 멀티 모달 모델입니다. 능력 영역은 자연어 이해, 기계 번역, 지능적인 질문 및 답변, 감정 분석 및 그래픽 매칭 등을 포함합니다. 오픈 소스 주소는 다음과 같습니다.
https://huggingface.co/banana-dev/gptrillion
(2023 년 5 월 24 일,이 프로젝트는 April Fools의 날 농담 프로그램입니다. 프로젝트가 삭제되었습니다. 여기에 설명하겠습니다.
OpenFlamingo는 GPT-4를 벤치마킹하고 대규모 멀티 모드 모델의 교육 및 평가를 지원하는 프레임 워크입니다. 비영리 Laion에 의해 발표되었으며 Deepmind의 Flamingo 모델을 재현 한 것입니다. 현재 오픈 소스는 LLAMA 기반 OpenFlamingo-9B 모델입니다. Flamingo 모델은 인터레이스 된 텍스트와 이미지가 포함 된 대규모 네트워크 코퍼스에서 교육을받으며 컨텍스트 제한 샘플을 배울 수 있습니다. OpenFlamingo는 원래 플라밍고에서 제안 된 것과 동일한 아키텍처를 구현하며, 새로운 멀티 모달 C4 데이터 세트의 5m 샘플과 Laion-2B의 10m 샘플에 대해 훈련 된 것입니다. 이 프로젝트의 오픈 소스 주소는 다음과 같습니다.
https://github.com/mlfoundations/open_flamingo
올해 2 월 21 일, Fudan University는 Moss를 석방하고 공개 베타를 열었으며, 이는 공공 베타 붕괴 후 약간의 논쟁을 일으켰습니다. 이제 프로젝트는 중요한 업데이트와 오픈 소스를 안내했습니다. 오픈 소스 Moss는 중국어와 영어를 모두 지원하며 방정식, 검색 등과 같은 플러그인화를 지원합니다. 매개 변수는 16B이며 약 7 천억 중국어 및 영어 및 코드 단어로 미리 훈련됩니다. 후속 대화 지침은 미세 조정, 플러그인 향상된 학습 및 인간 선호 교육에는 여러 라운드의 대화 기능이 있으며 여러 플러그인을 사용할 수있는 기능이 있습니다. 이 프로젝트의 오픈 소스 주소는 다음과 같습니다.
https://github.com/openlmlab/moss
MINIGPT-4 및 LLAVA와 유사하게 MPLUG 시리즈의 모듈 식 교육 아이디어를 계속하는 오픈 소스 멀티 모달 모델 벤치마킹 GPT-4입니다. 현재 7b 매개 변수 수량 모델을 열고 동시에 시각 관련 지시 이해를 위해 처음으로 포괄적 인 테스트 세트 Owleval을 제안합니다. 수동 평가를 통해 LLAVA, MINIGPT-4 및 기타 작업을 포함한 기존 모델은 특히 멀티 모달 지시 이해 능력, 멀티 라운드 대화 능력, 지식 추론 능력 등에서 더 나은 멀티 모달 기능을 보여줍니다. 다른 그래픽 및 텍스트 모델과 마찬가지로 유감스럽게도 영어 만 지원하는 것은 이미 오픈 소스 목록에 있습니다.
이 프로젝트의 오픈 소스 주소는 https://github.com/x-plug/mplug-owl입니다
Pandalm은 다른 대규모 모델의 선호도를 자동으로 평가하여 컨텐츠를 생성하여 수동 평가 비용을 절약하는 모델 평가 모델입니다. Pandalm은 분석을위한 웹 인터페이스와 함께 제공되며 Python 코드 호출도 지원합니다. 3 줄의 코드만으로 모든 모델과 데이터로 생성 된 텍스트를 평가할 수 있으며 사용하기에 매우 편리합니다.
프로젝트의 오픈 소스 주소는 https://github.com/weopenml/pandalm입니다
최근 개최 된 Zhiyuan 컨퍼런스에서 Zhiyuan Research Institute는 중국어와 영어에 대한 이중 언어 지식을 가지고있는 깨달음과 Sky Eagle 모델의 출처를 열었습니다. 오픈 소스 버전의 기본 모델 매개 변수에는 70 억과 330 억이 포함됩니다. 동시에 Aquilachat 대화 모델과 퀼라 코드 텍스트 코드 생성 모델을 엽니 다. Aquila는 GPT-3 및 LLAMA와 같은 디코더 전용 아키텍처를 채택하고 중국어 및 영어 이중 언어에 대한 어휘를 업데이트하고 가속화 된 교육 방법을 채택합니다. 성능 보장은 모델의 최적화와 개선에 달려있을뿐만 아니라 최근 몇 년 동안 Zhiyuan의 대형 모델에 대한 고품질 데이터 축적의 혜택을받습니다.
프로젝트의 오픈 소스 주소는 https://github.com/flagai-open/flagai/tree/master/examples/aquila입니다
최근 Microsoft는 텍스트-voice-image-video를 완전히 연결하는 멀티 모달 큰 모델 용지와 오픈 소스 코드 -codi를 발표했으며 임의의 입력 및 임의의 모달 출력을 지원합니다. 임의의 양식의 생성을 달성하기 위해 연구원들은 훈련을 두 단계로 나누었습니다. 첫 번째 단계에서 저자는 브리지 정렬 전략과 조건을 사용하여 훈련하여 각 모드에 대한 잠재적 확산 모델을 만듭니다. 두 번째 단계에서, 교차로주의 모듈이 각 전위 확산 모델 및 환경 인코더에 추가되었으며, 이는 전위 확산 모델의 잠재 변수를 공유 공간으로 투사하여 생성 된 양식이 더 다각화되도록 할 수 있습니다.
이 프로젝트의 오픈 소스 주소는 https://github.com/microsoft/i-code/tree/main/i-code-v3입니다
Meta는 이미지, 비디오, 오디오, 깊이, 열 및 공간 운동을 포함하여 6 가지 양식을 가로 지르는 멀티 모달 큰 모델 Imagebind를 출시 및 오픈 소스했습니다. ImageBind는 큰 시각적 언어 모델과 제로 샘플 기능을 사용하여 새로운 양식으로 확장하여 이미지의 바인딩 특성을 사용하여 정렬 문제를 해결합니다. 이미지 페어링 데이터는이 6 가지 모드를 함께 바인딩하기에 충분하므로 다른 모드가 서로 모달 분할을 열 수 있습니다.
프로젝트의 오픈 소스 주소는 https://github.com/facebookresearch/imagebind입니다
2023 년 4 월 10 일, Wang Xiaochuan은 공식적으로 AI Big Model Company "Baichuan Intelligence"의 설립을 발표하여 OpenAI의 중국어 버전을 만들기 위해 발표했습니다. 설립 된 지 2 개월 만에 Baichuan Intelligent는 독립적으로 개발 된 Baichuan-7B 모델의 주요 공급원으로 중국어와 영어를 지원했습니다. Baichuan-7b는 C-Eval, Agieval 및 Gaokao Chinese 권위 평가 목록에 대한 상당한 장점을 가진 ChatGLM-6B와 같은 다른 큰 모델을 능가 할뿐만 아니라 MMLU 영어 권위 평가 목록에서 LLAMA-7B를 크게 이끌어냅니다. 이 모델은 고품질 데이터에 대한조차 토큰 스케일에 도달하며 효율적인 주의력 운영자 최적화를 기반으로 수만 건의 초경량 동적 창의 확장 기능을 지원합니다. 현재 오픈 소스는 4K 컨텍스트 기능을 지원합니다. 이 오픈 소스 모델은 상업적으로 이용 가능하며 LLAMA보다 더 친절합니다.
프로젝트의 오픈 소스 주소는 https://github.com/baichuan-inc/baichuan-7b입니다
2023 년 8 월 6 일, Yuanxiang Xverse 팀은 Xverse-13B 모델을 열었습니다. 이 모델은 최대 40 개 이상의 언어를 지원하고 최대 8192의 상황 길이를 지원하는 다국어 대형 모델입니다. 팀의 기능은 다음과 같습니다.이 모델의 기능은 다음과 같습니다. 모델 구조 : Xverse-13B는 주류 디코더 전용 표준 변압기 구조를 사용하며 동일한 크기 모델 중에서 가장 긴 크기의 요구 사항을 충족 할 수 있으며, 지식 Q & A 및 A 및 A 및 A 및 A 및 A 및 A. 교육 데이터 : 1.4 조 고품질의 고품질 및 다양한 데이터는 40 개 중국어, 영어, 러시아어 및 서양을 포함하여 모델을 완전히 훈련시키기 위해 구축되었습니다. 여러 언어는 다양한 유형의 데이터의 샘플링 비율을 미세하게 설정함으로써 중국어와 영어가 잘 수행되며 다른 언어의 영향을 고려할 수도 있습니다. 단어 세분화 : BPE 알고리즘을 기반으로, 어휘 크기가 100,278 인 단어 세분화는 수백 개의 GB 코퍼스를 사용하여 교육을 받았으며, 이는 단어 목록의 추가 확장없이 동시에 여러 언어를 지원할 수 있습니다. 교육 프레임 워크 : 효율적인 운영자, 비디오 메모리 최적화, 병렬 일정 전략, 데이터 컴퓨팅 통신 중첩, 플랫폼 및 프레임 워크 협력 등을 포함한 여러 주요 기술을 독립적으로 개발하여 교육 효율성을 높이고 모델 안정성을 강하게 만듭니다. 킬로 카드 클러스터의 피크 컴퓨팅 전력 활용률은 58.5%에 도달하여 업계의 최전선 중 하나입니다.
이 프로젝트의 오픈 소스 주소는 https://github.com/xverse-ai/xverse-13b입니다
2023 년 8 월 3 일, Alibaba Tongyi Qianwen의 70 억 모델은 일반 모델 및 대화 모델을 포함한 오픈 소스였으며 오픈 소스, 무료 및 상업적으로 이용 가능합니다. 보고서에 따르면 Qwen-7b는 변압기를 기반으로하는 대형 언어 모델이며 초대형 사전 훈련 데이터에 대한 교육을 받았습니다. 사전 훈련 데이터 유형은 다양하며 다양한 온라인 텍스트, 전문 서적, 코드 등을 포함하여 광범위한 영역을 다룹니다. 이는 중국어 및 영어를 지원하고 2 조의 토큰 데이터 세트에 대해 훈련 된 도크 모델이며 컨텍스트 창 길이는 8K에 도달합니다. Qwen-7B-Chat은 Qwen-7B 받침대 모델을 기반으로 한 중국어-영어 대화 모델입니다. Tongyi Qianwen 7B 사전 훈련 된 모델은 여러 권위있는 벤치 마크 평가에서 잘 수행되었습니다. 중국어 및 영어 기능은 국내외에서 동일한 규모의 오픈 소스 모델을 훨씬 능가했으며 일부 기능은 12B 및 13B 크기의 오픈 소스 모델을 초과했습니다.
프로젝트의 오픈 소스 주소는 https://github.com/qwenlm/qwen-7b입니다
LLAMA는 META에서 발표 한 새로운 대규모 인공 지능 언어 모델로 텍스트 생성, 대화, 서면 자료 요약, 수학적 이론 입증 또는 단백질 구조 예측과 같은 작업에서 잘 수행됩니다. 라마 모델은 라틴어 및 키릴 알파벳 언어를 포함한 20 개의 언어를 지원합니다. 현재 원래 모델은 중국어를 지원하지 않습니다. 라마의 서사시 누출이 Chatgpt와 같은 오픈 소스 개발을 적극적으로 홍보했다고 말할 수 있습니다.
(2023 년 4 월 22 일에 업데이트 됨) 불행히도, Llama의 승인은 현재 제한되어 있으며 과학 연구에만 사용될 수 있으며 상업적 사용은 허용되지 않습니다. 상업적인 오픈 소스 문제를 해결하기 위해 Redpajama 프로젝트는 상업용 애플리케이션에 사용될 수있는 LLAMA의 완전히 오픈 소스 복제본을 만들고보다 투명한 연구 프로세스를 제공하는 것을 목표로했습니다. 완전한 Redpajama에는 1.2 조 개의 토큰 데이터 세트가 포함되어 있으며 다음 단계는 대규모 교육을 시작하는 것입니다. 이 작업은 여전히 기대할 가치가 있으며 오픈 소스 주소는 다음과 같습니다.
https://github.com/togethercomputer/redpajama-data
(2023 년 5 월 7 일에 업데이트)
Redpajama는 3B와 7B의 두 매개 변수를 포함하여 교육 모델 파일을 업데이트했습니다. 여기서 3B는 5 년 전에 출시 된 RTX2070 게임 그래픽 카드에서 실행하여 3B의 LLAMA의 갭을 구성했습니다. 모델 주소는 다음과 같습니다.
https://huggingface.co/togethercomputer
Redpajama 외에도 Mosaicml은 MPT 시리즈 모델을 시작했으며 교육 데이터는 Redpajama 데이터를 사용합니다. 다양한 성능 평가에서 7B 모델은 원래 LLAMA와 비슷합니다. 모델의 오픈 소스 주소는 다음과 같습니다.
https://huggingface.co/mosaicml
Redpajama이든 MPT이든 해당 채팅 버전 모델을 오픈 소스도 제공합니다. 이 두 모델의 오픈 소스는 Chatgpt와 같은 상업화를 크게 향상 시켰습니다.
(2023 년 6 월 1 일에 업데이트)
Falcon은 라마를 비교하는 개방형 큰 모델 기반입니다. 7b와 40b의 두 가지 매개 변수 측정 척도가 있습니다. 40B의 성능은 Ultra-High 65B Llama로 알려져 있습니다. Falcon은 여전히 GPT 자동 회귀 디코더 모델을 사용한다는 것이 이해되지만 데이터에 많은 노력을 기울였습니다. 공개 네트워크에서 컨텐츠를 긁어 내고 초기 사전 법적 데이터 세트를 구축 한 후 CommonCrawl 덤프를 사용하여 대규모 필터링 및 대규모 중복 제거를 수행하고 거의 5 조 5 조의 토큰으로 구성된 거대한 사전 처리 된 데이터 세트를 얻습니다. 동시에 연구 논문 및 소셜 미디어 대화를 포함하여 많은 선택된 소문이 추가되었습니다. 그러나이 프로젝트의 승인은 논란의 여지가 있으며 "반영 상업"권한 부여 방법이 채택되었으며 소득이 백만 명에 이르는 후 상업 비용의 10%가 발생하기 시작합니다.
프로젝트의 오픈 소스 주소는 https://huggingface.co/tiiuae입니다
(2023 년 7 월 3 일에 업데이트)
원래 Falcon에는 Llama와 같은 중국 지원 기능이 부족합니다. "Linly"프로젝트 팀은 Falcon 모델을 기반으로 중국 버전의 중국어 버전을 구축하고 열었습니다. 이 모델은 먼저 8701 개의 일반적으로 사용되는 중국어, Jieba 어휘 목록의 최초 20,000 개의 중국 고주파 단어 및 60 개의 중국 구두점을 포함하여 어휘 목록을 확장하고 크게 확장했습니다. 중복 제거 후, 어휘 목록 크기는 90,046으로 확장되었습니다. 훈련 단계에서 50G 코퍼스 및 2T 대규모 데이터를 훈련에 사용했습니다.
프로젝트의 오픈 소스 주소는 https://github.com/cvi-szu/linly입니다
(2023 년 7 월 24 일에 업데이트)
원래 Falcon에는 Llama와 같은 중국 지원 기능이 부족합니다. "Linly"프로젝트 팀은 Falcon 모델을 기반으로 중국 버전의 중국어 버전을 구축하고 열었습니다. 이 모델은 먼저 8701 개의 일반적으로 사용되는 중국어, Jieba 어휘 목록의 최초 20,000 개의 중국 고주파 단어 및 60 개의 중국 구두점을 포함하여 어휘 목록을 확장하고 크게 확장했습니다. 중복 제거 후, 어휘 목록 크기는 90,046으로 확장되었습니다. 훈련 단계에서 50G 코퍼스 및 2T 대규모 데이터를 훈련에 사용했습니다.
프로젝트의 오픈 소스 주소는 https://github.com/cvi-szu/linly입니다
Stanford가 발표 한 Alpaca (Alpaca Model)는 LLAMA-7B 모델을 기반으로 한 새로운 모델입니다. 기본 원칙은 OpenAI의 Text-DavInci-003 모델이 LLAMA를 미세 조정하기 위해 자체 강조 방식으로 52K 명령 샘플을 생성하도록하는 것입니다. 이 프로젝트는 소스 교육 데이터, 교육 데이터를 생성하기위한 코드 및 하이퍼 파라미터를 열었습니다. 모델 파일은 아직 공급되지 않았으며 하루에 5.6k 이상의 별에 도달했습니다. 이 작업은 저렴한 비용과 쉬운 데이터 액세스로 인해 매우 인기가 있으며 저렴한 ChatGpt의 모방으로가는 길을 열었습니다. Github 주소는 다음과 같습니다.
https://github.com/tatsu-lab/stanford_alpaca
Nebuly+AI가 시작한 인간 피드백 강화 학습을 기반으로 LLAMA+AI 챗봇의 오픈 소스 구현입니다. 기술 경로는 Chatgpt와 유사합니다. 이 프로젝트는 방금 2 일 동안 출시되었으며 5.2K 스타를 수상했습니다. Github 주소는 다음과 같습니다.
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
Chatllama 교육 프로세스 알고리즘은 주로 Chatgpt보다 더 빠르고 저렴한 교육을 달성하는 데 사용됩니다. 거의 15 배 더 빠른 것으로 알려져 있습니다. 주요 기능은 다음과 같습니다.
완전한 오픈 소스 구현을 통해 사용자는 미리 훈련 된 LLAMA 모델을 기반으로 ChatGpt 스타일 서비스를 구축 할 수 있습니다.
라마 아키텍처는 더 작아서 훈련 과정과 추론이 더 빠르고 비용이 적게 듭니다.
미세 조정 프로세스 속도를 높이기 위해 DeepSpeed Zero에 대한 내장 지원;
다양한 크기의 LLAMA 모델 아키텍처를 지원하며 사용자는 자신의 선호도에 따라 모델을 미세 조정할 수 있습니다.
OpenChatkit은 전직 Openai 연구원들과 Laion 및 Ontocord.ai 팀이 위치한 The Toket Team에 의해 공동으로 만들어졌습니다. OpenChatkit에는 200 억 개의 매개 변수가 포함되어 있으며 GPT-3의 오픈 소스 버전 GPT-NOX-20B로 미세 조정됩니다. 동시에 ChatGPT의 다양한 강화 학습 인 OpenChatkit은 60 억 파라미터 감사 모델을 사용하여 부적절하거나 유해한 정보를 필터링하여 생성 된 컨텐츠의 안전성과 품질을 보장합니다. Github 주소는 다음과 같습니다.
https://github.com/togethercomputer/openchatkit
Stanford Alpaca를 기반으로 한 Supervised Fine Tuning은 Bloom과 Llama를 기반으로 실현됩니다. Stanford Alpaca의 종자 작업은 모두 영어로되어 있으며 수집 된 데이터는 영어로되어 있습니다. 이 오픈 소스 프로젝트는 중국 대화 대형 모델 오픈 소스 커뮤니티의 개발을 촉진하는 것입니다. 중국어에 최적화되었습니다. 모델 튜닝은 ChatGpt에서 생성 된 데이터 만 사용합니다 (다른 데이터는 포함되지 않음). 프로젝트에는 다음이 포함되어 있습니다.
175 중국 종자 임무
데이터 생성을위한 코드
10m에 의해 생성 된 데이터는 현재 1.5m, 0.25m 수학 명령 데이터 세트 및 0.8m 다중 라운드 작업 대화 데이터 세트로 오픈 소스입니다.
Bloomz-7B1-MT 및 LLAMA-7B를 기반으로 최적화 된 모델
github 주소는 다음과 같습니다. https://github.com/lianjiatech/belle
Alpaca-Lora는 Stanford University의 또 다른 걸작입니다. LORA (저 순위 적응) 기술을 사용하여 저렴한 방법을 사용하여 Alpaca의 결과를 재현하고 5 시간 동안 RTX 4090 그래픽 카드에서만 훈련되어 알파카 수준의 모델을 얻습니다. 또한이 모델은 라즈베리 파이에서 실행될 수 있습니다. 이 프로젝트에서는 저렴하고 효율적인 미세 조정을 위해 Hugging Face의 PEFT를 사용합니다. PEFT는 라이브러리 (LORA는 지원되는 기술 중 하나)로 다양한 변압기 기반 언어 모델을 사용하여 LORA로 미세 조정하여 일반 하드웨어에서 모델의 저렴하고 효율적인 미세 조정을 허용합니다. 이 프로젝트의 github 주소는 다음과 같습니다.
https://github.com/tloen/alpaca-lora
Alpaca와 Alpaca-Lora는 큰 진전을 이루었지만 종자 작업은 영어로되어 있으며 중국어에 대한 지원이 부족합니다. 한편, 벨은 알파카-로라 (Alpaca-Lora), 중국 언어 모델 Luotuo (Luotuo)와 같은 전임자들과 같은 전임자들의 작업에 기초하여 많은 양의 중국 코퍼스를 수집했다고 위에서 언급 한 것 외에도 중국 중국 평범한 대학 및 기타 기관의 3 명의 개별 개발자가 공개 한 단일 카드는 훈련 배치를 완료 할 수 있습니다. 현재이 프로젝트는 Luotuo-Lora-7B-0.1 인 Luotuo-Lora-7B-0.3의 두 가지 모델을 출시하고 하나의 모델이 계획에 있습니다. Github 주소는 다음과 같습니다.
https://github.com/lc1332/chinese-alpaca-lora
Alpaca에서 영감을 얻은 Dolly는 Alpaca 데이터 세트를 사용하여 GPT-J-6B에서 미세 조정을 달성했습니다. Dolly 자체는 모델의 "클론"이기 때문에 팀은 마침내 "Dolly"라는 이름을 지정하기로 결정했습니다. 알파카에서 영감을 얻은이 복제 방법은 점점 더 인기를 얻고 있습니다. 요약하면, 그것은 대략 Alpaca의 오픈 소스 데이터 수집 방법과 6b 또는 7b 크기의 기존 모델에 대한 미세 조정 지침으로 채택되어 Chatgpt와 같은 효과를 달성합니다. 이 아이디어는 매우 경제적이며 Chatgpt의 매력을 빠르게 모방 할 수 있습니다. 그것은 매우 인기가 있으며 일단 출시되면 별들로 가득합니다. 이 프로젝트의 github 주소는 다음과 같습니다.
https://github.com/databrickslabs/dolly
Alpaca를 출시 한 후 Stanford Scholars는 CMU, UC Berkeley 등과 협력하여 130 억 개의 매개 변수 (일반적으로 Alpaca 및 LLAMA)의 새로운 모델 -Vicuna를 출시했습니다. Chatgpt의 90% 성능을 달성하는 데 $ 300에 불과합니다. Vicuna는 ShareGpt가 수집 한 사용자 공유 대화에서 라마를 미세 조정하는 데 사용됩니다. 테스트 프로세스는 GPT-4를 평가 기준으로 사용합니다. 결과는 Vicuna-13B가 사례의 90% 이상에서 Chatgpt 및 Bard와 일치하는 기능을 달성 함을 보여줍니다.
UC Berkeley LMSYS ORG는 최근 70 억 개의 매개 변수로 Vicuna를 출시했습니다. 크기가 작고 효율성이 높고 능력이 강 할뿐만 아니라 M1/M2 칩으로 두 줄의 명령으로 MAC에서 실행될 수 있으며 GPU 가속도를 가능하게 할 수도 있습니다!
github 오픈 소스 주소는 다음과 같습니다. https://github.com/lm-sys/fastchat/
또 다른 중국어 버전은 중국-비쿠나가 공개적으로 공급되었으며 Github 주소는 다음과 같습니다.
https://github.com/facico/chinese-vicuna
Chatgpt가 인기를 얻은 후 사람들은 성전으로의 빠른 길을 찾고있었습니다. 일부 chatgpt와 같은 외관이 나타나기 시작했으며, 특히 Chatgpt에 따라 저렴한 비용으로 인기있는 방법이되었습니다. Lmflow는이 수요 시나리오에서 태어난 제품으로, 3090과 같은 일반적인 그래픽 카드에서 대규모 모델을 개선 할 수 있습니다.이 프로젝트는 홍콩 과학 및 기술 통계 및 기계 학습 실험실 팀에 의해 시작되었으며 제한된 기계 자원 하에서 다양한 실험을 지원하는 다양한 개방형 모델 연구 플랫폼을 구축하고, 기존의 데이터 사용 방법과 ALGORETHM의 최적화를 개선시켜주고 있습니다. 이전 방법보다 더 효율적인 더 큰 모델 교육 시스템.
이 프로젝트를 사용하면 제한된 컴퓨팅 리소스조차도 사용자가 독점 분야에 대한 개인화 된 교육을 지원할 수 있습니다. 예를 들어, LLAMA-7B, 3090은 교육을 완료하는 데 5 시간이 걸리므로 비용이 크게 줄어 듭니다. 이 프로젝트는 또한 웹 쪽 인스턴트 경험 Q & A 서비스 (lmflow.com)를 열어줍니다. LMFlow의 출현 및 오픈 소스는 일반 리소스가 Q & A, 동반자, 작문, 번역, 전문 현장 상담 등과 같은 다양한 작업을 훈련시킬 수있게 해줍니다. 많은 연구자들은 현재이 프로젝트를 사용하여 650 억 이상의 매개 변수량으로 대형 모델을 훈련 시키려고 노력하고 있습니다.
이 프로젝트의 github 주소는 다음과 같습니다.
https://github.com/optimalscale/lmflow
이 프로젝트는 Chatgpt 대화를 자동으로 수집하여 Chatgpt가 자기 대화를 할 수 있도록하는 방법을 제안하고, Batch는 고품질의 다중 라운드 대화 데이터 세트를 생성하고 각각 약 50,000 개의 고품질 Q & A 코퍼스, StackoverFlow 및 MEDQA를 수집하고 모두 공개되었습니다. 동시에 Llama 모델을 개선했으며 그 효과는 꽤 좋습니다. Bai Ze는 또한 현재의 저렴한 LORA 미세 조정 솔루션을 채택하여 Bai ZE-7B, 13B 및 30B의 세 가지 다른 규모와 수직 의료 분야의 모델을 얻었습니다. 불행히도, 중국 이름은 잘 지명되었지만 여전히 중국어를 지원하지는 않습니다. 중국 바이 제이 모델은이 계획에 따라 진행되며 향후 발표 될 예정이다. 오픈 소스 Github 주소는 다음과 같습니다.
https://github.com/project-baize/baize
Llama 기반 Chatgpt Flat 교체는 계속해서 발효되고 있습니다. UC Berkeley의 Berkeley는 13B의 매개 변수로 소비자 GPU에서 실행할 수있는 대화 모델 Koala를 발표했습니다. Koala의 교육 데이터 세트에는 다음 부분이 포함되어 있습니다. Chatgpt 데이터 및 오픈 소스 데이터 (OIG (Open Instruction Generalist), Stanford Alpaca Model, Anthropic HH, OpenAi WebGPT, OpenAi 요약에서 사용하는 데이터 세트)가 포함됩니다. Koala 모델은 8 A100 GPU를 사용하여 Jax/Flax를 사용하여 Easylm에서 구현되며 2 회 반복을 완료하는 데 6 시간이 걸립니다. 평가 효과는 Alpaca보다 우수하여 ChatGpt의 50% 성능을 달성합니다.
오픈 소스 주소 : https://github.com/young-geng/easylm
스탠포드 알파카 (Stanford Alpaca)의 출현으로, 많은 라마에 기반을 둔 알파카 가족과 확장 된 동물 가족이 등장하기 시작했고, 마침내 포옹 페이스 연구자들은 최근 블로그 스택 라마 (Stackllama)를 출판했습니다. 동시에 70 억 개의 매개 변수 모델 -Stackllama도 출시되었습니다. 이것은 인간 피드백 강화 학습을 통해 LLAMA-7B에서 미세 조정 된 모델입니다. 자세한 내용은 블로그 주소를 참조하십시오.
https://huggingface.co/blog/stackllama
이 프로젝트는 중국 및 오픈 소스의 미세 조정 대화 시스템에 대한 LLAMA를 최적화합니다. 이 프로젝트의 특정 단계에는 다음이 포함됩니다. 1. 문장을 사용하여 중국 데이터를 훈련시키고 구성하고 Llama Word 목록과 병합 된 단어 목록을 확장합니다. 2. 새로운 단어 목록에서, 약 20G의 중국 주민들이 훈련을 받았으며, LORA 기술은 훈련에 사용되었습니다. 3. Stanford Alpaca를 사용하여 대화 능력을 얻기 위해 51K 데이터에 대해 미세 조정 교육을 수행했습니다.
오픈 소스 주소는 https://github.com/ymcui/chinese-llama-alpaca입니다
4 월 12 일, Databricks는 업계 최초의 오픈 소스 인 Directive Compliant LLM으로 알려진 Dolly 2.0을 출시했습니다. 이 데이터 세트는 Databricks 직원에 의해 생성되었으며 공개 공급원으로 상업적 목적으로 사용할 수있었습니다. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
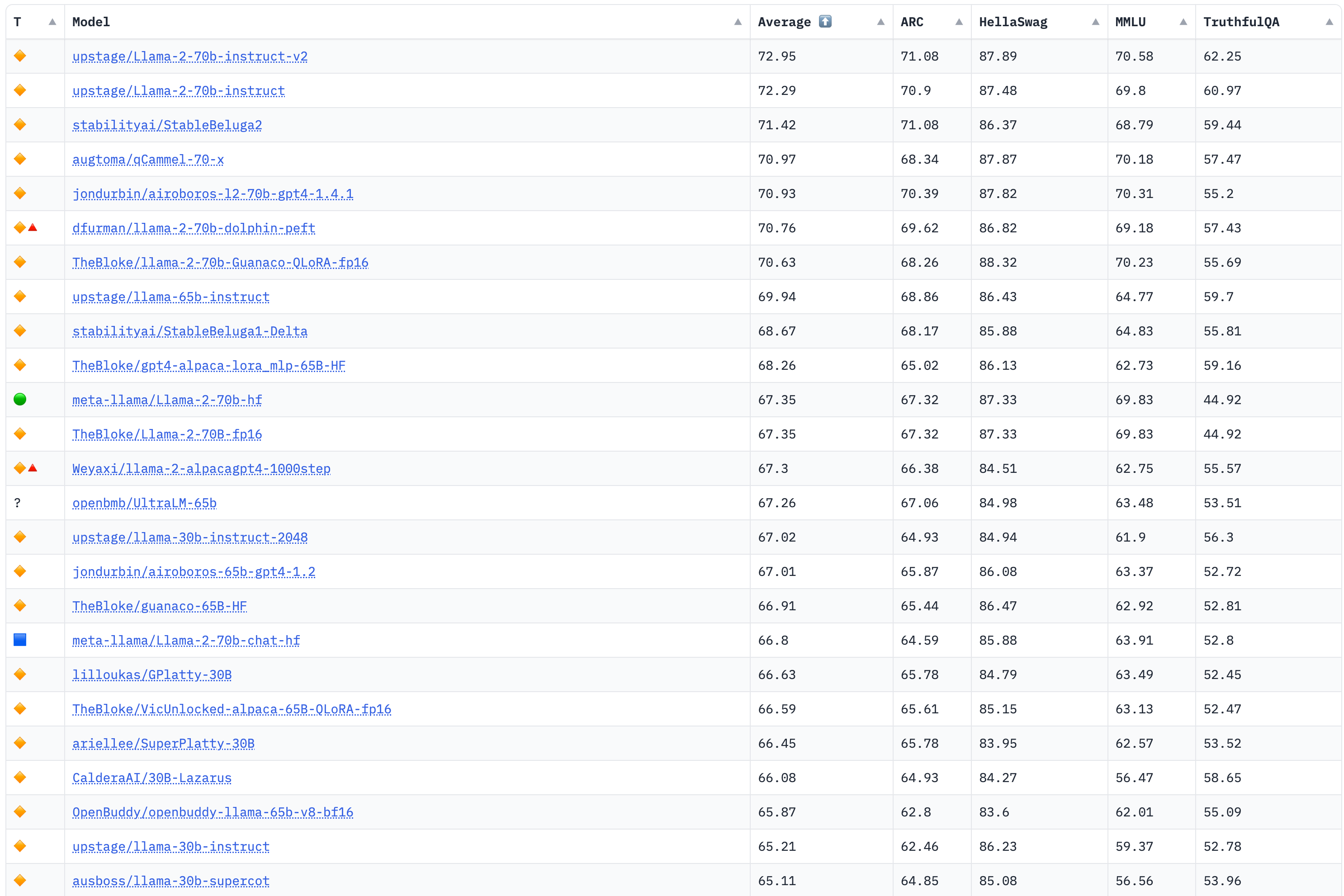
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
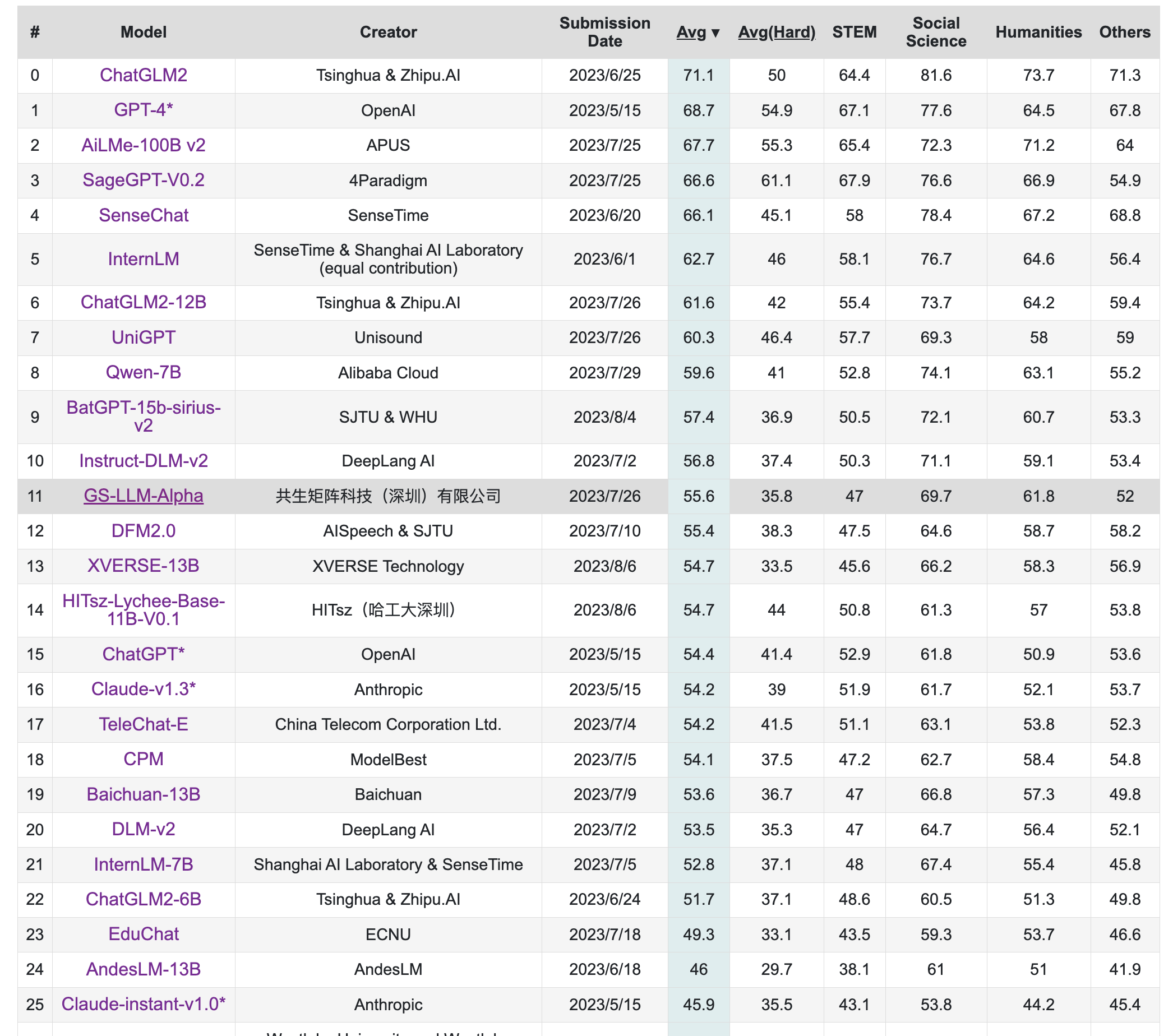
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

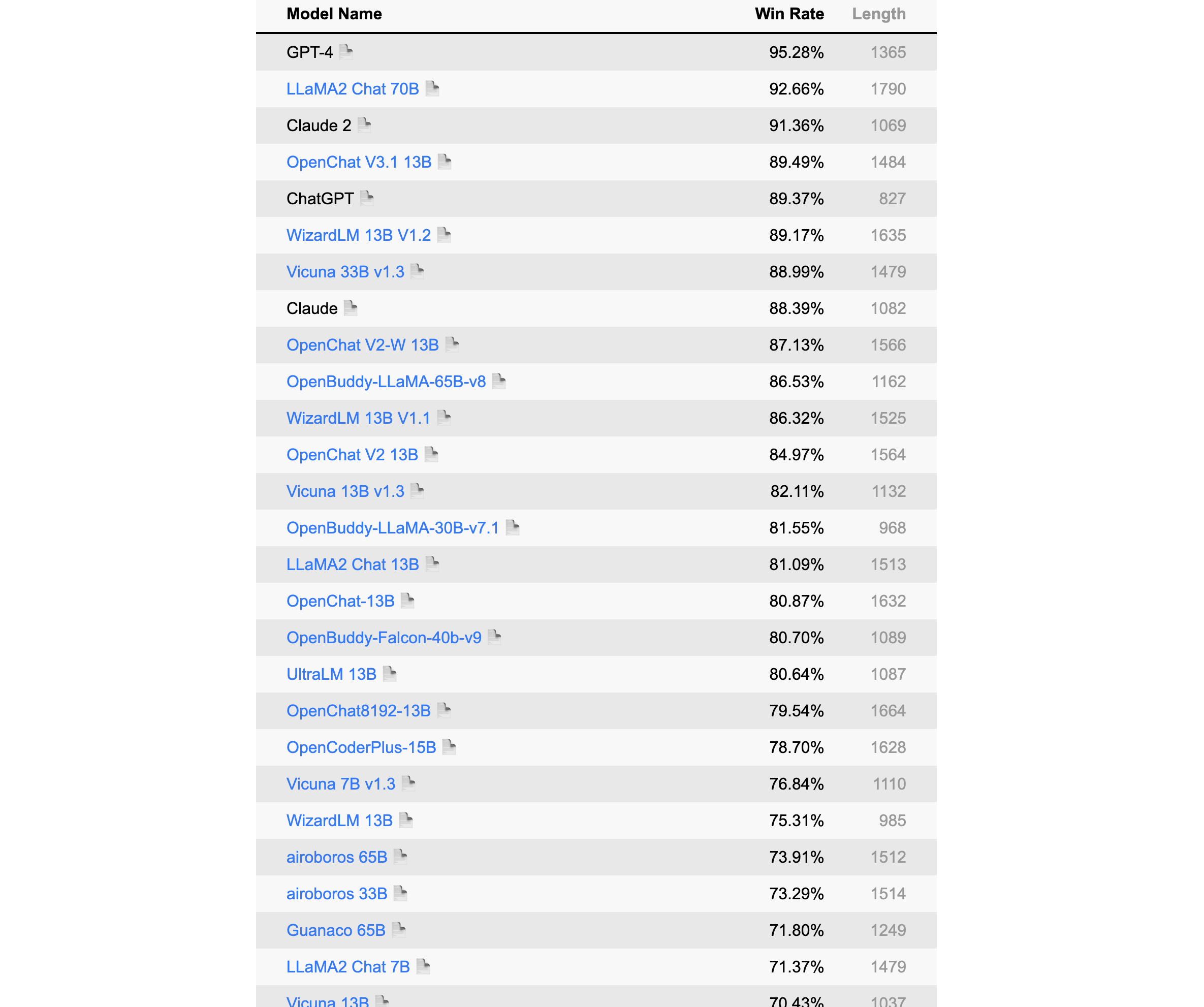
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


