FindTheChatGPTer
1.0.0
ChatGPT/GPT4 open source "plain replacement" summary, continuous update
ChatGPT has become popular, and many domestic universities, research institutions and enterprises have issued release plans similar to ChatGPT. ChatGPT is not open source, and it is extremely difficult to reproduce. Even now, no unit or enterprise has reproduced the full capabilities of GPT3. Just now, OpenAI officially announced the release of the GPT4 model with multimodal graphics and text, and its capabilities have been greatly improved compared to ChatGPT. It seems that it smells the fourth industrial revolution dominated by general artificial intelligence.
Whether abroad or at home, the gap between OpenAI is getting bigger and bigger, and everyone is catching up in a busy manner, so they are in a certain advantageous position in this technological innovation. At present, the research and development of many large enterprises is basically taking the closed-source route. There are few details officially released by ChatGPT and GPT4, and it is not like the previous paper introduction that introduced dozens of pages, the era of commercialization of OpenAI has arrived. Of course, some organizations or individuals have explored open source replacements. This article is summarized as follows. I will continue to track them. There are updated open source replacements to update this place in a timely manner.
This type of method mainly adopts non-LLAMA and other fine-tuning methods to independently design or optimize GPT and T5 models, and realizes full-cycle processes such as pre-training, supervised fine-tuning, and reinforcement learning.
ChatYuan (Yuanyu AI) is developed and published by the Yuanyu Intelligent Development Team. It claims to be the first functional dialogue model in China. It can write articles, do homework, write poetry, and translate Chinese and English; some specific areas such as laws can also provide relevant information. This model currently only supports Chinese, and the github link is:
https://github.com/clue-ai/ChatYuan
Judging from the disclosed technical details, the underlying layer adopts a T5 model with a scale of 700 million parameters, and supervises and fine-tunes based on PromptClue to form ChatYuan. This model is basically the first step of the three-step ChatGPT technical route, and no reward model training and PPO reinforcement learning training are implemented.
Recently, ColossalAI open source their ChatGPT implementation. Share their three-step strategy and fully implement the technical route of ChatGPT core: its Github is as follows:
https://github.com/hpcaitech/ColossalAI
Based on this project, I have clarified the three-step strategy and shared it:
The first stage (stage1_sft.py): The SFT supervision fine-tuning stage, the open source project was not implemented, this is relatively simple because ColossalAI seamlessly supports Huggingface. I directly use a few lines of code of Huggingface's Trainer function to easily implement it. Here I used a gpt2 model. From its implementation point of view, it supports GPT2, OPT and BLOOM models;
The second stage (stage2_rm.py): the reward model (RM) training stage, that is, the train_reward_model.py part in the project Examples;
The third stage (stage3_ppo.py): reinforcement learning (RLHF) stage, that is, project train_prompts.py
The execution of the three files needs to be placed in the ColossalAI project, where the cores in the code are chatgpt in the original project, and cores.nn becomes chatgpt.models in the original project.
ChatGLM is a dialogue model of the GLM series of Zhipu AI, a company that transforms technology achievements in Tsinghua, supports Chinese and English languages, and currently has its 6.2 billion parameter model. It inherits the advantages of GLM and optimizes the model architecture, thus lowering the threshold for deployment and application, realizing the inference application of large models on consumer graphics cards. For detailed techniques, please refer to its github:
The open source address of ChatGLM-6B is: https://github.com/THUDM/ChatGLM-6B
From the technical perspective, it has implemented ChatGPT reinforced learning of human alignment strategy, making the generation effect better and closer to human value. Its current ability areas mainly include self-cognition, outline writing, copywriting, email writing assistant, information extraction, role-playing, comment comparison, travel advice, etc. It has developed a 130 billion super-large model under internal testing, which is considered a dialogue model with a larger parameter scale in the current open source replacement.
VisualGLM-6B (Updated on May 19, 2023)
The team recently opened the multimodal version of ChatGLM-6B, which supports multimodal dialogue in images, Chinese and English. The language model part uses ChatGLM-6B, and the image part builds a bridge between the visual model and the language model by training BLIP2-Qformer. The overall model has a total of 7.8 billion parameters. VisualGLM-6B relies on 30M high-quality Chinese graphic pairs from the CogView dataset, and is pre-trained with 300M filtered English graphic pairs, with the same weight in Chinese and English. This training method better aligns visual information into the semantic space of ChatGLM; in the subsequent fine-tuning stage, the model is trained on long visual question-and-answer data to generate answers that meet human preferences.
VisualGLM-6B open source address is: https://github.com/THUDM/VisualGLM-6B
ChatGLM2-6B (Updated on June 27, 2023)
The team recently opened sourced ChatGLM's second-generation version ChatGLM2-6B. Compared with the first-generation version, its main features include the use of a larger data scale, from 1T to 1.4T; the most prominent is its longer context support, which has expanded from 2K to 32K, allowing longer and higher rounds of inputs; in addition, the inference speed has been greatly optimized, an increase of 42%, and the video memory resources occupied have been greatly reduced.
ChatGLM2-6B open source address is: https://github.com/THUDM/ChatGLM2-6B
It is known as the first open source ChatGPT replacement project, and its basic idea is based on the Google language big model PaLM architecture and the use of reinforcement learning methods (RLHF) from human feedback. PaLM is a 540 billion parameter all-around model released by Google in April this year, based on the Pathways system training. It can complete tasks such as writing code, chat, language understanding, etc., and has powerful low-sample learning performance on most tasks. At the same time, ChatGPT-like reinforcement learning mechanism is adopted, which can make AI's answers more in line with scenario requirements and reduce model toxicity.
Github address is: https://github.com/lucidrains/PaLM-rlhf-pytorch
The project is known as the largest open source model, up to 1.5 trillion, and is a multimodal model. Its ability domains include natural language understanding, machine translation, intelligent question and answer, sentiment analysis and graphic matching, etc. Its open source address is:
https://huggingface.co/banana-dev/GPTrillion
(On May 24, 2023, this project is an April Fools' Day joke program. The project has been deleted. I will explain it hereby
OpenFlamingo is a framework that benchmarks GPT-4 and supports training and evaluation of large-scale multimodal models. It was released by non-profit LAION and is a reproduction of DeepMind's Flamingo model. Currently open source is its LLaMA-based OpenFlamingo-9B model. The Flamingo model is trained on a large-scale network corpus containing interlaced text and images, and has the ability to learn context-limited samples. OpenFlamingo implements the same architecture proposed in the original Flamingo, trained on 5M samples from a new multimodal C4 dataset and 10M samples from LAION-2B. The open source address of this project is:
https://github.com/mlfoundations/open_flamingo
On February 21 this year, Fudan University released MOSS and opened public beta, which caused some controversy after the public beta collapse. Now the project has ushered in important updates and open source. The open source MOSS supports both Chinese and English languages, and supports plug-inization, such as solving equations, search, etc. The parameters are 16B, and pre-trained in about 700 billion Chinese and English and code words. The subsequent dialogue instructions are fine-tuned, plug-in enhanced learning and human preference training have multiple rounds of dialogue capabilities and the ability to use multiple plug-ins. The open source address of this project is:
https://github.com/OpenLMLab/MOSS
Similar to miniGPT-4 and LLaVA, it is an open source multimodal model benchmarking GPT-4, which continues the modular training idea of the mPLUG series. It currently opens the 7B parameter quantity model, and at the same time, it proposes a comprehensive test set OwlEval for the first time for visual-related instruction understanding. Through manual evaluation, existing models, including LLaVA, MiniGPT-4 and other work, demonstrates better multimodal capabilities, especially in multimodal instruction understanding ability, multi-round dialogue ability, knowledge reasoning ability, etc. It is regrettable that like other graphic and text models, it still only supports English, but the Chinese version is already in its open source List.
The open source address of this project is: https://github.com/X-PLUG/mPLUG-Owl
PandaLM is a model evaluation model that aims to automatically evaluate the preferences of other large-scale models to generate content, saving manual evaluation costs. PandaLM comes with a web interface for analysis, and also supports Python code calls. It can evaluate text generated by any model and data with only three lines of code, which is very convenient to use.
The open source address of the project is: https://github.com/WeOpenML/PandaLM
At the Zhiyuan Conference held recently, Zhiyuan Research Institute opened the source of its Enlightenment and Sky Eagle model, which has bilingual knowledge of Chinese and English. The basic model parameters of the open source version include 7 billion and 33 billion. At the same time, it opens the AquilaChat dialogue model and quilaCode text-code generation model, and both have been opened for commercial licenses. Aquila adopts Decoder-only architectures such as GPT-3 and LLaMA, and also updates the vocabulary for Chinese and English bilingualism, and adopts its accelerated training method. Its performance guarantee not only depends on the optimization and improvement of the model, but also benefits from Zhiyuan's accumulation of high-quality data on large models in recent years.
The open source address of the project is: https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
Recently, Microsoft has published a multi-modal big model paper and open source code -CoDi, which completely connects text-voice-image-video, supports arbitrary input and arbitrary modal output. In order to achieve the generation of arbitrary modalities, the researchers divided the training into two stages. In the first stage, the author used the bridge alignment strategy and combined conditions to train, creating a potential diffusion model for each mode; in the second stage, an intersection attention module was added to each potential diffusion model and environmental encoder, which could project the latent variables of the potential diffusion model into the shared space, so that the generated modalities were further diversified.
The open source address of this project is: https://github.com/microsoft/i-Code/tree/main/i-Code-V3
Meta has launched and open sourced its multimodal big model ImageBind, which can achieve crossing 6 modalities, including image, video, audio, depth, heat and spatial motion. ImageBind solves the alignment problem by using the binding characteristics of images, using large visual language models and zero-sample capabilities to expand to new modalities. Image pairing data is enough to bind these six modes together, allowing different modes to open up modal splits from each other.
The open source address of the project is: https://github.com/facebookresearch/ImageBind
On April 10, 2023, Wang Xiaochuan officially announced the establishment of the AI big model company "Baichuan Intelligence", aiming to create a Chinese version of OpenAI. Two months after its establishment, Baichuan Intelligent has made a major source of its independently developed baichuan-7B model, supporting Chinese and English. baichuan-7B not only surpasses other big models such as ChatGLM-6B with significant advantages on the C-Eval, AGIEval and Gaokao Chinese authoritative evaluation list, but also significantly leads LLaMA-7B in the MMLU English authoritative evaluation list. This model reaches a trillion token scale on high-quality data, and supports the expansion capability of tens of thousands of ultra-long dynamic windows based on efficient attention operator optimization. Currently, open source supports 4K context capabilities. This open source model is commercially available and is more friendly than LLaMA.
The open source address of the project is: https://github.com/baichuan-inc/baichuan-7B
On August 6, 2023, the Yuanxiang XVERSE team opened the XVERSE-13B model. This model is a multilingual large model that supports up to 40+ languages and supports contextual length up to 8192. According to the team, the features of this model are: Model structure: XVERSE-13B uses the mainstream Decoder-only standard Transformer structure, supports 8K context length, which is the longest among the same size model, and can meet the needs of longer multi-round dialogue, knowledge Q&A and summary; Training data: 1.4 trillion tokens of high-quality and diverse data are built to fully train the model, including 40 Chinese, English, Russian, and Western. Multiple languages, by finely setting the sampling ratio of different types of data, the Chinese and English languages perform well, and can also take into account the effects of other languages; Word segmentation: Based on the BPE algorithm, a word segmentation with a vocabulary size of 100,278 was trained using hundreds of GB corpus, which can support multiple languages at the same time without additional expansion of the word list; Training framework: independently developed a number of key technologies, including efficient operators, video memory optimization, parallel scheduling strategies, data-computing-communication overlap, platform and framework collaboration, etc., making training efficiency higher and model stability strong. The peak computing power utilization rate on the kilocard cluster can reach 58.5%, ranking among the forefront in the industry.
The open source address of this project is: https://github.com/xverse-ai/XVERSE-13B
On August 3, 2023, Alibaba Tongyi Qianwen's 7 billion model was open source, including general models and dialogue models, and is open source, free and commercially available. According to reports, Qwen-7B is a large language model based on Transformer and is trained on super-large-scale pre-training data. The pre-training data types are diverse and cover a wide range of areas, including a large number of online texts, professional books, codes, etc. It is a dock model that supports Chinese and English languages, trained on more than 2 trillion token data sets, and the context window length reaches 8k. Qwen-7B-Chat is a Chinese-English dialogue model based on the Qwen-7B pedestal model. The Tongyi Qianwen 7B pre-trained model performed well in multiple authoritative benchmark evaluations. Its Chinese and English capabilities far exceed the open source models of the same scale at home and abroad, and some capabilities even exceeded the open source models of 12B and 13B sizes.
The open source address of the project is: https://github.com/QwenLM/Qwen-7B
LLaMA is a brand new large-scale artificial intelligence language model released by Meta, which performs well in tasks such as generating text, dialogue, summarizing written materials, proving mathematical theorems, or predicting protein structures. The LLaMA model supports 20 languages, including Latin and Cyrillic alphabetical languages. Currently, the original model does not support Chinese. It can be said that the epic leak of LLaMA has vigorously promoted the open source development of ChatGPT-like.
(Updated on April 22, 2023) But unfortunately, LLama's authorization is currently limited and can only be used for scientific research and is not allowed for commercial use. To solve the commercial fully open source problem, the RedPajama project came into being, aiming to create a fully open source replica of LLaMA that can be used for commercial applications and provide a more transparent process for research. The complete RedPajama includes a 1.2 trillion token dataset, and its next step will be to start large-scale training. This work is still worth looking forward to, and its open source address is:
https://github.com/togethercomputer/RedPajama-Data
(Updated on May 7, 2023)
RedPajama updated its training model file, including two parameters: 3B and 7B, where 3B can run on the RTX2070 gaming graphics card released 5 years ago, making up for the gap in LLaMa on 3B. Its model address is:
https://huggingface.co/togethercomputer
In addition to RedPajama, MosaicML has launched the MPT series model, and its training data uses RedPajama data. In various performance evaluations, the 7B model is comparable to the original LLaMA. The open source address of its model is:
https://huggingface.co/mosaicml
Whether it is RedPajama or MPT, it also open source the corresponding Chat version model. The open source of these two models has brought a huge boost to the commercialization of ChatGPT-like.
(Updated on June 1, 2023)
Falcon is an open big model base that compares LLaMA. It has two parameter measurement scales: 7B and 40B. The performance of 40B is known as the ultra-high 65B LLaMA. It is understood that Falcon still uses the GPT autoregressive decoder model, but it has put a lot of effort into the data. After scraping content from the public network and building the initial pretrained data set, it uses CommonCrawl dump to perform large-scale filtering and large-scale deduplication, and finally obtains a huge pretrained data set composed of nearly 5 trillion tokens. At the same time, many selected corpuses have been added, including research papers and social media conversations. However, the authorization of the project has been controversial, and the "semi-commercial" authorization method is adopted, and 10% of the commercial expenses will begin to occur after the income reaches 1 million.
The open source address of the project is: https://huggingface.co/tiiuae
(Updated on July 3, 2023)
The original Falcon lacks Chinese support capabilities like LLaMA. The "Linly" project team built and opened the Chinese version of Chinese-Falcon based on the Falcon model. The model first expanded and greatly expanded the vocabulary list, including 8701 commonly used Chinese characters, the first 20,000 Chinese high-frequency words in the jieba vocabulary list, and 60 Chinese punctuation marks. After deduplication, the vocabulary list size was expanded to 90,046. During the training phase, 50G corpus and 2T large-scale data were used for training.
The open source address of the project is: https://github.com/CVI-SZU/Linly
(Updated on July 24, 2023)
The original Falcon lacks Chinese support capabilities like LLaMA. The "Linly" project team built and opened the Chinese version of Chinese-Falcon based on the Falcon model. The model first expanded and greatly expanded the vocabulary list, including 8701 commonly used Chinese characters, the first 20,000 Chinese high-frequency words in the jieba vocabulary list, and 60 Chinese punctuation marks. After deduplication, the vocabulary list size was expanded to 90,046. During the training phase, 50G corpus and 2T large-scale data were used for training.
The open source address of the project is: https://github.com/CVI-SZU/Linly
The alpaca (alpaca model) released by Stanford is a new model based on the LLaMA-7B model. The basic principle is to allow OpenAI's text-davinci-003 model to generate 52K instruction samples in a self-instruct manner to fine-tune LLaMA. The project has opened source training data, code to generate training data, and hyperparameters. The model file has not yet been opened sourced, reaching more than 5.6K stars in one day. This work is very popular due to its low cost and easy data access, and has also opened the road to imitation of low-cost ChatGPT. Its github address is:
https://github.com/tatsu-lab/stanford_alpaca
It is an open source implementation of the LLaMA+AI chatbot based on human feedback reinforcement learning launched by Nebuly+AI. Its technical route is similar to ChatGPT. The project has just been launched for 2 days and has won 5.2K stars. Its github address is:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA training process algorithm is mainly used to achieve faster and cheaper training than ChatGPT. It is said to be nearly 15 times faster. The main features are:
A complete open source implementation allows users to build ChatGPT-style services based on pre-trained LLaMA models;
The LLaMA architecture is smaller, making the training process and reasoning faster and less costly;
Built-in support for DeepSpeed ZERO to speed up the fine-tuning process;
Supports LLaMA model architectures of various sizes, and users can fine-tune the model according to their own preferences.
OpenChatKit is jointly created by the Together team, where former OpenAI researchers are located, as well as the LAION and Ontocord.ai teams. OpenChatKit contains 20 billion parameters and is fine-tuned with GPT-3's open source version GPT-NoX-20B. At the same time, different reinforcement learning of ChatGPTs, OpenChatKit uses a 6 billion parameter audit model to filter inappropriate or harmful information to ensure the safety and quality of the generated content. Its github address is:
https://github.com/togethercomputer/OpenChatKit
Based on Stanford Alpaca, supervised fine-tuning is realized based on Bloom and LLama. Stanford Alpaca's seed tasks are all in English, and the data collected is also in English. This open source project is to promote the development of the Chinese dialogue big model open source community. It has been optimized for Chinese. Model tuning only uses data produced by ChatGPT (not including any other data). The project contains the following:
175 Chinese seed missions
Code for generating data
The data generated by 10M is currently open sourced with 1.5M, 0.25M mathematical instruction data sets and 0.8M multi-round task dialogue data sets.
Model optimized based on BLOOMZ-7B1-mt and LLama-7B
github address is: https://github.com/LianjiaTech/BELLE
alpaca-lora is another masterpiece from Stanford University. It uses LoRA (low-rank adaptation) technology to reproduce the results of Alpaca, using a lower-cost method, and only trained on an RTX 4090 graphics card for 5 hours to get a model with an Alpaca level. Moreover, the model can run on a Raspberry Pi. In this project, it uses Hugging Face's PEFT for cheap and efficient fine-tuning. PEFT is a library (LoRA is one of its supported technologies) that allows you to use a variety of Transformer-based language models and fine-tune them with LoRA, allowing for inexpensive and efficient fine-tuning of the model on general hardware. The github address of this project is:
https://github.com/tloen/alpaca-lora
Although Alpaca and alpaca-lora have made great progress, their seed tasks are both in English and lack support for Chinese. On the one hand, in addition to the above mentioned that Belle has collected a large amount of Chinese corpus, on the other hand, based on the work of predecessors such as alpaca-lora, the Chinese language model Luotuo (Luotuo) open sourced by three individual developers from Central China Normal University and other institutions, a single card can complete the training deployment. Currently, the project releases two models luotuo-lora-7b-0.1, luotuo-lora-7b-0.3, and one model is in the plan. Its github address is:
https://github.com/LC1332/Chinese-alpaca-lora
Inspired by Alpaca, Dolly used the Alpaca dataset to achieve fine-tuning on GPT-J-6B. Since Dolly itself is a "clone" of a model, the team finally decided to name it "Dolly". Inspired by Alpaca, this cloning method is becoming more and more popular. In summary, it is roughly adopted Alpaca's open source data acquisition method, and fine-tune instructions on old models of 6B or 7B size to achieve ChatGPT-like effects. This idea is very economical and can quickly imitate the charm of ChatGPT. It is very popular and once it was launched, it is full of stars. The github address of this project is:
https://github.com/databrickslabs/dolly
After launching alpaca, Stanford Scholars teamed up with CMU, UC Berkeley, etc. to launch a new model - Vicuna with 13 billion parameters (commonly known as alpaca and llama). It only costs $300 to achieve 90% performance of ChatGPT. Vicuna is used to fine-tune LLaMA on user-shared dialogue collected by ShareGPT. The test process uses GPT-4 as the evaluation criteria. The results show that Vicuna-13B achieves capabilities that match ChatGPT and Bard in more than 90% of the cases.
UC Berkeley LMSys org recently released Vicuna with 7 billion parameters. It is not only small in size, high efficiency and strong in ability, but also can run on a Mac with M1/M2 chip in just two lines of command, and can also enable GPU acceleration!
github open source address is: https://github.com/lm-sys/FastChat/
Another Chinese version has been open sourced by Chinese-Vicuna, with the github address as:
https://github.com/Facico/Chinese-Vicuna
After ChatGPT became popular, people were looking for a quick way to the temple. Some ChatGPT-like appearances began to appear, especially following ChatGPT at a low cost has become a popular way. LMFlow is a product born in this demand scenario, which enables large models to be refined on ordinary graphics cards like 3090. The project was initiated by the Hong Kong University of Science and Technology Statistics and Machine Learning Laboratory team, and is committed to establishing a fully open large model research platform that supports various experiments under limited machine resources, and improves the existing data utilization methods and optimization algorithm efficiency on the platform, so that the platform can develop into a larger model training system that is more efficient than the previous methods.
Using this project, even limited computing resources can allow users to support personalized training for proprietary fields. For example, LLaMA-7B, a 3090 takes 5 hours to complete the training, which greatly reduces the cost. The project also opens the web-side instant experience Q&A service (lmflow.com). The emergence and open source of LMFlow enable ordinary resources to train various tasks such as Q&A, companionship, writing, translation, expert field consultation, etc. Many researchers are currently trying to use this project to train large models with a parameter volume of 65 billion or even higher.
The github address of this project is:
https://github.com/OptimalScale/LMFlow
The project proposes a method to automatically collect ChatGPT conversations, allowing ChatGPT to self-talk, batch generate high-quality multi-round dialogue datasets, and collect about 50,000 high-quality Q&A corpus of Quora, StackOverflow and MedQA, respectively, and has been all open sourced. At the same time, it improved the LLama model and the effect is pretty good. Bai Ze also adopted the current low-cost LoRA fine-tuning solution to obtain three different scales: Bai Ze-7B, 13B and 30B, as well as a model in the vertical field of medical care. Unfortunately, the Chinese name is well named, but it still does not support Chinese. The Chinese Bai Ze model is reportedly under the plan and will be released in the future. Its open source github address is:
https://github.com/project-baize/baize
LLama-based ChatGPT flat replacement continues to ferment, UC Berkeley's Berkeley has released a conversation model Koala that can run on consumer GPUs with parameters of 13B. Koala's training dataset includes the following parts: ChatGPT data and open source data (Open Instruction Generalist (OIG), dataset used by Stanford Alpaca model, Anthropic HH, OpenAI WebGPT, OpenAI Summarization). The Koala model is implemented in EasyLM using JAX/Flax, using 8 A100 GPUs, and it takes 6 hours to complete 2 iterations. The evaluation effect is better than Alpaca, achieving 50% performance of ChatGPT.
Open source address: https://github.com/young-geng/EasyLM
With the advent of Stanford Alpaca, a large number of LLama-based alpaca families and extended animal families began to emerge, and finally, Hugging Face researchers recently published a blog StackLLaMA: A practical guide to training LLaMA with RLHF. At the same time, a 7 billion parameter model - StackLLaMA was also released. This is a model fine-tuned in LLaMA-7B through human feedback reinforcement learning. For details, see its blog address:
https://huggingface.co/blog/stackllama
The project optimizes LLaMA for Chinese and open source its fine-tuned dialogue system. The specific steps of this project include: 1. Expand the word list, using sentencepiece to train and construct on Chinese data, and merged with the LLaMA word list; 2. Pre-training, on the new word list, about 20G of general Chinese corpus was trained, and LoRA technology was used in the training; 3. Using Stanford Alpaca, fine-tuning training was carried out on 51k data to obtain dialogue ability.
The open source address is: https://github.com/ymcui/Chinese-LLaMA-Alpaca
On April 12, Databricks released Dolly 2.0, known as the industry's first open source, directive-compliant LLM. The dataset was generated by Databricks employees and was open sourced and available for commercial purposes. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
The open source address is: https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
This project brought about the era of ChatGPT for all, and the training cost was greatly reduced again. The project was developed by Microsoft based on its Deep Speed optimization library. It has three core functions: enhanced reasoning, RLHF module, and RLHF system. It can increase the training speed by more than 15 times, but the cost is greatly reduced. For example, a 13 billion parameter-like ChatGPT model can be trained in just 1.25 hours.
The open source address is: https://github.com/microsoft/DeepSpeed
This project adopts a different approach from RLHF to perform human preference alignment, and the number of model and hyperparameters trained by RRHF is much lower than that of RLHF. The Wombat-7B obtained by RRHF training has a significant increase in performance compared to Alpaca, and is better aligned with human preferences.
The open source address is: https://github.com/GanjinZero/RRHF
Guanaco is an instruction alignment language model trained based on the current mainstream LLaMA-7B model. Based on the original 52K data, 534K+ pieces of data are added, covering English, Japanese, German, Simplified Chinese, Traditional Chinese (Taiwan), Traditional Chinese (Hong Kong), and various language and grammar tasks. Rich data helps improve and optimize the model, which demonstrates outstanding performance and potential in multilingual environments.
The open source address is: https://github.com/Guanaco-Model/Guanaco-Model.github.io
(Updated on May 27, 2023, Guanaco-65B)
Recently, the University of Washington proposed QLoRA, using 4-bit quantization to compress pre-trained language models, then freeze the big model parameters, and add a relatively small number of trainable parameters to the model in the form of Low-Rank Adapters. While the model volume is greatly compressed, it hardly affects its inference effect. This technology is used in fine-tuning LLaMA 65B, which usually requires 780GB of GPU video memory, which only requires 48GB, and the training cost is greatly reduced.
The open source address is: https://github.com/artidoro/qlora
LLMZoo, the LLM Zoo open source project, maintains a series of open source big models, including Phoenix (Phoenix) and Chimera, which have attracted much attention recently, developed by Professor Wang Benyou's team from the Chinese University of Hong Kong (Shenzhen) and Shenzhen Big Data Research Institute. The text effect is said to be close to Baidu Wenxin Yiyan, and the GPT-4 evaluation is said to have reached the level of 97% Wenxin Yiyan, and 50% of them are not inferior to Wenxin Yiyan in manual evaluation.
There are two differences in the Phoenix model: in terms of fine-tuning, instructional fine-tuning and dialogue fine-tuning are optimized and combined; it supports more than 40 global languages.
The open source address is: https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant is an open source chat assistant that can understand tasks, interact with third-party systems, and dynamically retrieve information. It is said that it is the first fully open source large-scale instruction fine-tuning model to be trained on human data. The main innovation of this model lies in a larger human feedback data set (see the data chapter for details). Public tests show that the effect is good in terms of human alignment and toxicity, but the Chinese effect is still insufficient.
The open source address is: https://github.com/LAION-AI/Open-Assistant
HuggingChat (Updated on April 26, 2023)
HuggingChat is an open source replacement for ChatGPT launched by Huggingface after OpenAssistant. Its ability domain is basically the same as ChatGPT, and its effect is amazing in English and other language systems, and it has become the strongest open source replacement for ChatGPT. But the author tried Chinese, which was a mess, and his Chinese ability still needs to be greatly improved. The base of HuggingChat is oasst-sft-6-llama-30b, which is also a language model based on the LLaMA-30B fine-tuning of Meta.
The open source address of this project is: https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
The online experience address is: https://huggingface.co/chat
StableVicuna is a fine-tuning model of RLHF for Vicuna-13B v0 (fine-tuning on LLaMA-13B).
StableLM-Alpha is based on the open source dataset the Pile (including multiple data sources such as Wikipedia, Stack Exchange and PubMed), with a training token volume of 1.5 trillion.
In order to adapt to the conversation, based on the Stanford Alpaca model, it combines Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH. and fine-tune the model StableLM-Tuned-Alpha.
The open source address of this project is: https://github.com/Stability-AI/StableLM
This model is vertical to the medical field, and fine-tuned the original LLaMA-7B model through Chinese medical instructions fine-tuning/instruction set, enhancing dialogue capabilities in the medical field.
The open source address of this project is: https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
The base of this model adopts the independently developed RWKV language model, 100% RNN, and the fine-tuning part is still classic Alpaca, CodeAlpaca, Guanaco, GPT4All, ShareGPT, etc. It open sourced the 1B5, 3B, 7B and 14B models, currently supports Chinese and English languages, and provides model files with different language proportions.
The open source address of the project is: https://github.com/BlinkDL/ChatRWKV or https://huggingface.co/BlinkDL/rwkv-4-raven
At present, most ChatGPT-like classes basically adopt manual alignment, such as RLHF and the Alpaca mode only implements ChatGPT's imitation alignment, and the alignment capability is limited by the original ChatGPT alignment capability. Researchers at the Carnegie Mellon University's Institute of Language Technology, IBM Research Institute MIT-IBM Watson AI Lab, and the University of Massachusetts Amherst have proposed a new method of self-alignment. It combines principle-driven reasoning and the generation ability of generative large models, and can achieve good results with very little supervision data. The project work was successfully applied to the LLaMA-65b model and Dromedary was developed.
The open source address of this project is: https://github.com/IBM/Dromedary
LLaVA is a multimodal language and visual dialogue model, similar to GPT-4. It mainly does a lot of work in multimodal data instruction engineering, and currently open source its 13B model file. In terms of performance, it is understood that the relative score of visual chat reached 85% of GPT-4; the scientific question and answer of multimodal reasoning tasks reached 92.53% of SoTA. The open source address of this project is:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
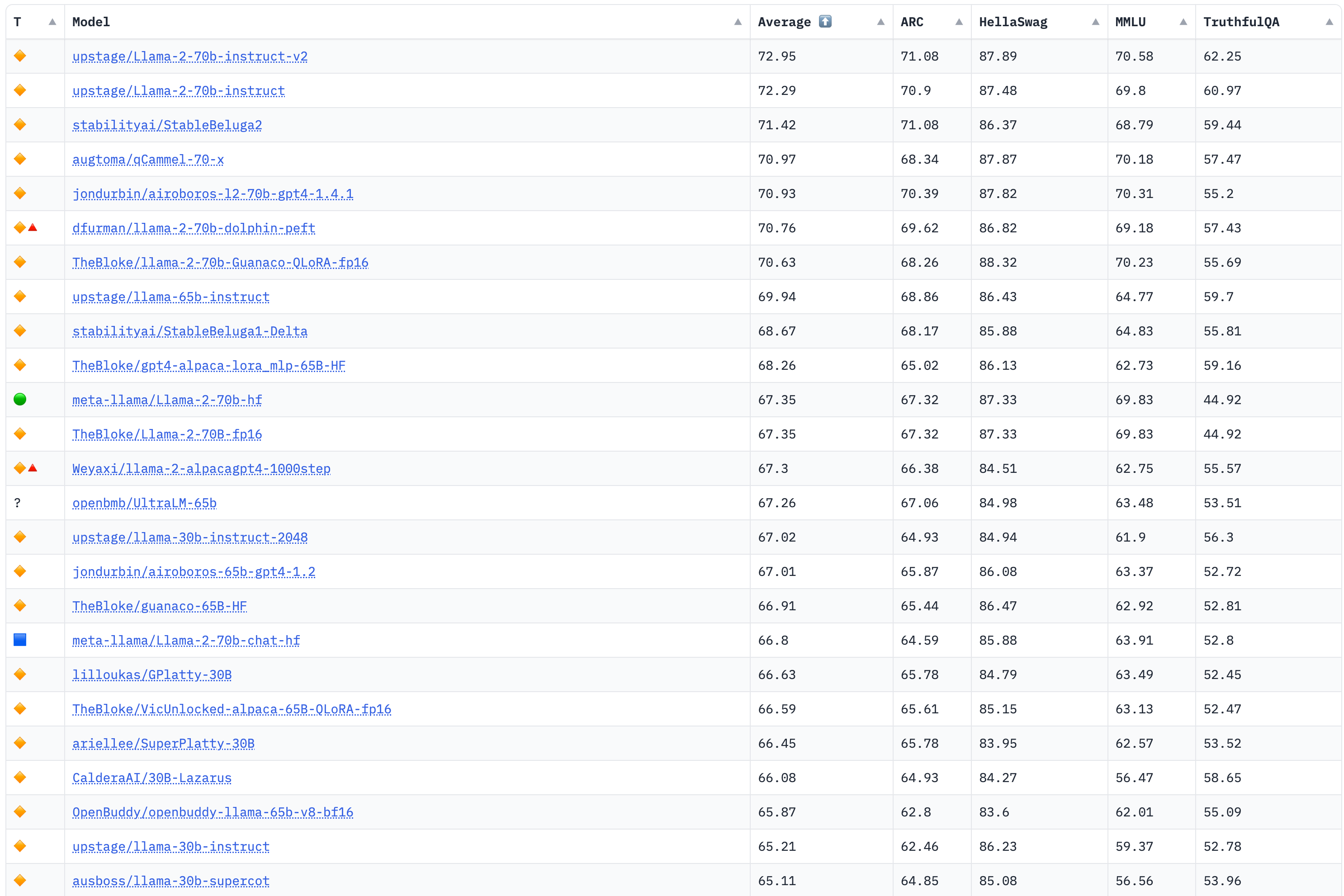
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
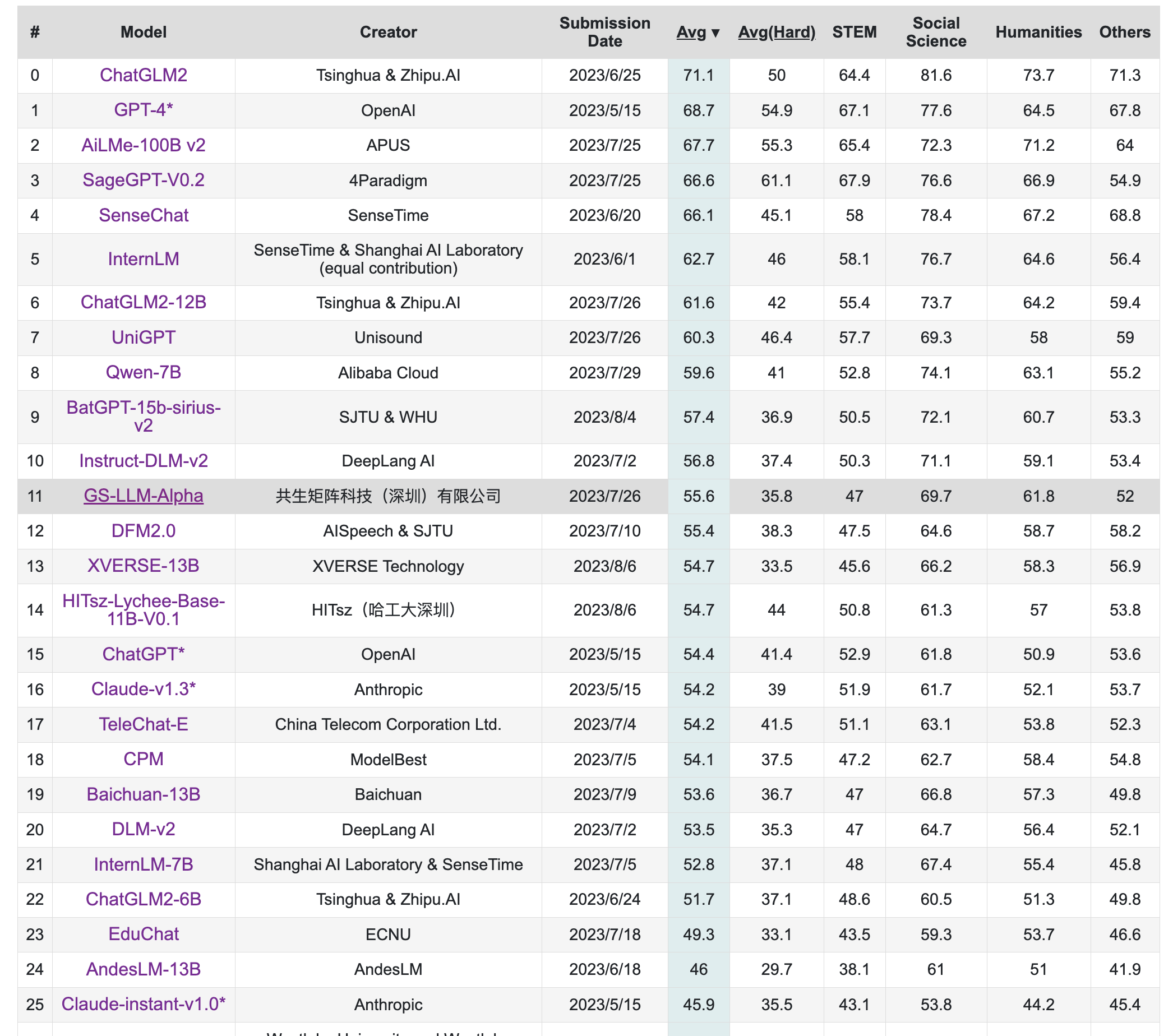
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

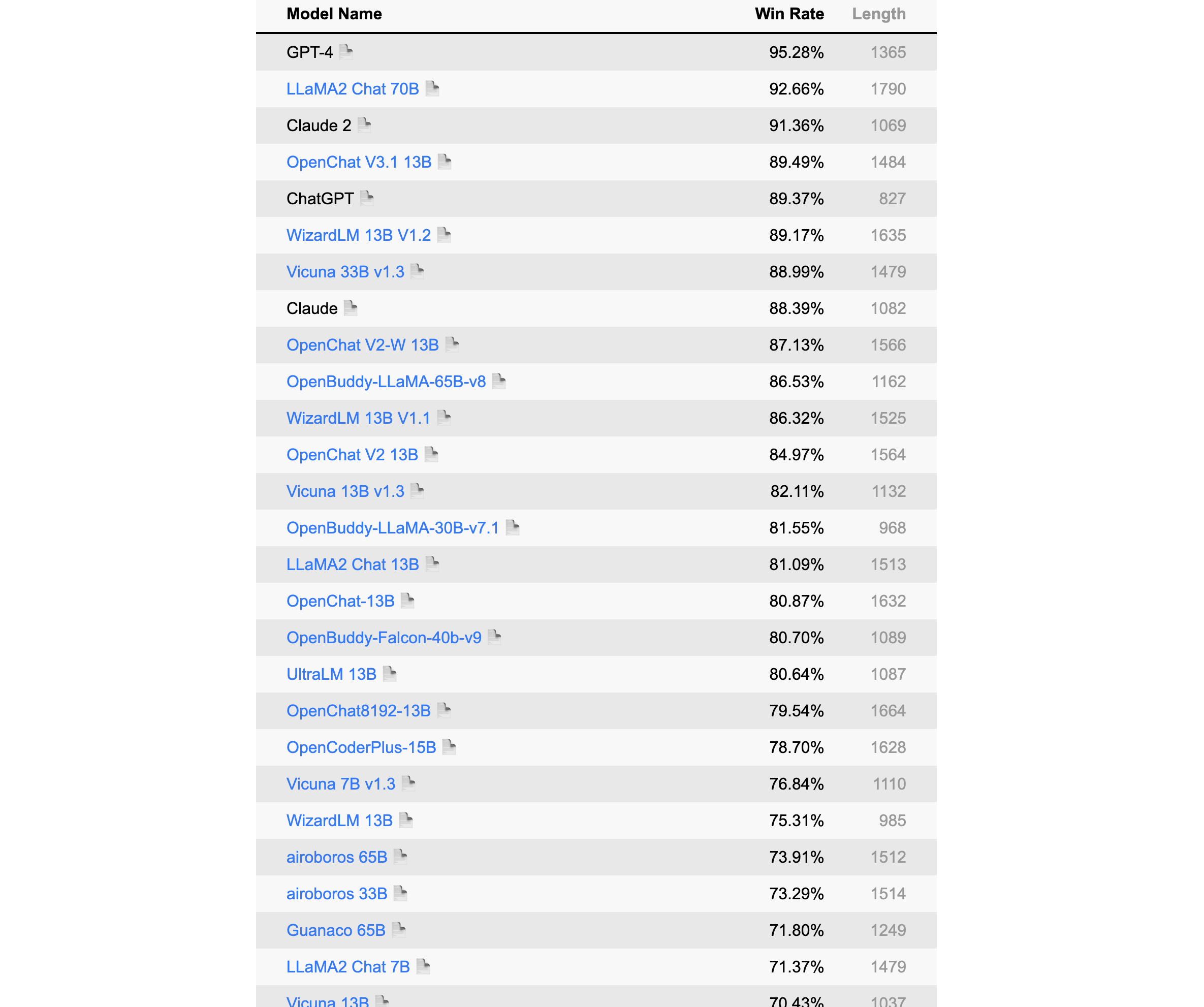
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


