FindTheChatGPTer
1.0.0
Résumé de "Remplacement" de remplacement simple "open source / GPT4, mise à jour continue
Chatgpt est devenu populaire et de nombreuses universités nationales, institutions de recherche et entreprises ont émis des plans de libération similaires à Chatgpt. Chatgpt n'est pas open source, et il est extrêmement difficile à reproduire. Même maintenant, aucune unité ou entreprise n'a reproduit toutes les capacités de GPT3. Tout à l'heure, Openai a officiellement annoncé la sortie du modèle GPT4 avec des graphiques et du texte multimodal, et ses capacités ont été considérablement améliorées par rapport à Chatgpt. Il semble qu'il sente la quatrième révolution industrielle dominée par l'intelligence artificielle générale.
Que ce soit à l'étranger ou à la maison, l'écart entre Openai devient de plus en plus grand, et tout le monde se rattrape de manière chargée, ils sont donc dans une certaine position avantageuse dans cette innovation technologique. À l'heure actuelle, la recherche et le développement de nombreuses grandes entreprises emprunte essentiellement l'itinéraire de source fermée. Il y a peu de détails officiellement publiés par Chatgpt et GPT4, et ce n'est pas comme l'introduction de l'article précédent qui a introduit des dizaines de pages, l'ère de la commercialisation d'Openai est arrivée. Bien sûr, certaines organisations ou individus ont exploré les remplacements open source. Cet article est résumé comme suit. Je continuerai à les suivre. Il existe des remplacements open source mis à jour pour mettre à jour cet endroit en temps opportun.
Ce type de méthode adopte principalement des méthodes non las et d'autres méthodes de réglage fin pour concevoir ou optimiser indépendamment les modèles GPT et T5, et réalise les processus à cycle complet tels que la pré-formation, le réglage fin supervisé et l'apprentissage du renforcement.
Chatyuan (Yuanyu AI) est développé et publié par l'équipe de développement intelligent de Yuanyu. Il prétend être le premier modèle de dialogue fonctionnel en Chine. Il peut écrire des articles, faire ses devoirs, écrire de la poésie et traduire le chinois et l'anglais; Certains domaines spécifiques tels que les lois peuvent également fournir des informations pertinentes. Ce modèle ne prend actuellement en charge que le chinois, et le lien github est:
https://github.com/clue-ai/chatyuan
À en juger par les détails techniques divulgués, la couche sous-jacente adopte un modèle T5 avec une échelle de 700 millions de paramètres, et supervise et des tuneaux fins basés sur PromptClue pour former Chatyuan. Ce modèle est essentiellement la première étape de l'itinéraire technique de Chatgpt en trois étapes, et aucune formation de modèle de récompense et la formation d'apprentissage par renforcement PPO ne sont mises en œuvre.
Récemment, Colossalai a ouvert son implémentation Chatgpt. Partagez leur stratégie en trois étapes et mettez en œuvre entièrement la voie technique de Chatgpt Core: son github est le suivant:
https://github.com/hpcaitech/colossalai
Sur la base de ce projet, j'ai clarifié la stratégie en trois étapes et je l'ai partagée:
La première étape (stage1_sft.py): l'étape de réglage de la supervision SFT, le projet open source n'a pas été mis en œuvre, c'est relativement simple car Colossalai prend en charge de manière transparente HuggingFace. J'utilise directement quelques lignes de code de la fonction Trainer de HuggingFace pour l'implémenter facilement. Ici, j'ai utilisé un modèle GPT2. Du point de vue de la mise en œuvre, il prend en charge les modèles GPT2, OPT et Bloom;
La deuxième étape (stage2_rm.py): l'étape de formation du modèle de récompense (RM), c'est-à-dire la partie Train_reward_model.py dans les exemples de projet;
La troisième étape (stage3_ppo.py): étape de l'apprentissage par renforcement (RLHF), c'est-à-dire, projeter Train_prompt.py
L'exécution des trois fichiers doit être placée dans le projet Colossalai, où les cœurs du code sont Chatgpt dans le projet d'origine, et cores.nn devient chatppt.models dans le projet d'origine.
ChatGLM est un modèle de dialogue de la série GLM de Zhipu AI, une entreprise qui transforme les réalisations technologiques à Tsinghua, soutient les langues chinoises et anglaises, et a actuellement son modèle de paramètres de 6,2 milliards. Il hérite des avantages de GLM et optimise l'architecture du modèle, réduisant ainsi le seuil de déploiement et d'application, réalisant l'application d'inférence de grands modèles sur les cartes graphiques de consommation. Pour des techniques détaillées, veuillez vous référer à son github:
L'adresse open source de chatglm-6b est: https://github.com/thudm/chatglm-6b
Du point de vue technique, il a mis en œuvre l'apprentissage renforcé par ChatGpt de la stratégie d'alignement humain, ce qui rend l'effet de génération meilleur et plus proche de la valeur humaine. Ses domaines de capacité actuels incluent principalement l'auto-cosse, la rédaction de contour, la rédaction, l'assistant d'écriture par e-mail, l'extraction d'informations, le jeu de rôle, la comparaison des commentaires, les conseils de voyage, etc. Il a développé un modèle de super-grand de 130 milliards de super-grands sous les tests internes, qui est considéré comme un modèle de dialogue avec une échelle de paramètre plus grande dans le remplacement actuel de la source ouverte.
VisualGlm-6b (mis à jour le 19 mai 2023)
L'équipe a récemment ouvert la version multimodale de ChatGLM-6B, qui prend en charge le dialogue multimodal dans les images, le chinois et l'anglais. La partie du modèle de langue utilise ChatGLM-6B et la pièce d'image construit un pont entre le modèle visuel et le modèle de langue en formant BLIP2-QFORMER. Le modèle global a un total de 7,8 milliards de paramètres. VisualGlm-6b s'appuie sur 30 m de paires graphiques chinoises de haute qualité de l'ensemble de données COGVIEW et est pré-formé avec des paires graphiques anglais filtrées de 300 m, avec le même poids en chinois et en anglais. Cette méthode de formation aligne mieux les informations visuelles dans l'espace sémantique du chatglm; Dans le stade de réglage final, le modèle est formé sur de longues données visuelles de questions et de réponses pour générer des réponses qui répondent aux préférences humaines.
VisualGlm-6b L'adresse open source est: https://github.com/thudm/visualglm-6b
ChatGLM2-6B (mis à jour le 27 juin 2023)
L'équipe a récemment ouvert la version de deuxième génération d'obtention de la deuxième génération de ChatGLM. Par rapport à la version de première génération, ses principales caractéristiques incluent l'utilisation d'une plus grande échelle de données, de 1T à 1,4 T; Le plus important est son support de contexte plus long, qui est passé de 2k à 32k, permettant des cycles d'intrants plus et plus élevés; De plus, la vitesse d'inférence a été considérablement optimisée, une augmentation de 42% et les ressources de mémoire vidéo occupées ont été considérablement réduites.
ChatGlm2-6b L'adresse open source est: https://github.com/thudm/chatglm2-6b
Il est connu comme le premier projet de remplacement de ChatGPT open source, et son idée de base est basée sur l'architecture de palmier Big Model Language Google et l'utilisation des méthodes d'apprentissage de renforcement (RLHF) à partir de la rétroaction humaine. Palm est un modèle polyvalent de 540 milliards de paramètres publié par Google en avril de cette année, sur la base de la formation du système Pathways. Il peut effectuer des tâches telles que la rédaction de code, le chat, la compréhension des langues, etc., et a de puissantes performances d'apprentissage à faible échantillon sur la plupart des tâches. Dans le même temps, le mécanisme d'apprentissage du renforcement de type Chatgpt est adopté, ce qui peut rendre les réponses de l'IA plus conformes aux exigences du scénario et réduire la toxicité du modèle.
L'adresse github est: https://github.com/lucidrains/palm-rlhf-pytorch
Le projet est connu comme le plus grand modèle open source, jusqu'à 1,5 billion, et est un modèle multimodal. Ses domaines de capacité comprennent la compréhension du langage naturel, la traduction automatique, la question et la réponse intelligentes, l'analyse des sentiments et la correspondance graphique, etc. Son adresse open source est:
https://huggingface.co/banana-dev/gptrillion
(Le 24 mai 2023, ce projet est un programme de blagues de la journée des imbéciles d'avril. Le projet a été supprimé. Je vais l'expliquer par la présente
OpenFlamingo est un cadre qui benchmarks GPT-4 et soutient la formation et l'évaluation des modèles multimodaux à grande échelle. Il a été publié par LAION à but non lucratif et est une reproduction du modèle Flamingo de Deepmind. Actuellement, Open Source est son modèle OpenFlamingo-9b basé sur LLAMA. Le modèle Flamingo est formé sur un corpus de réseau à grande échelle contenant du texte et des images entrelacés, et a la capacité d'apprendre des échantillons limités au contexte. OpenFlamingo implémente la même architecture proposée dans le Flamingo d'origine, formé sur des échantillons de 5 m à partir d'un nouvel ensemble de données C4 multimodal et de 10m de LAION-2B. L'adresse open source de ce projet est:
https://github.com/mlfoundations/open_flamingo
Le 21 février de cette année, l'Université Fudan a libéré Moss et a ouvert la version bêta publique, ce qui a provoqué une controverse après l'effondrement de la version bêta publique. Maintenant, le projet a inauguré des mises à jour importantes et des open source. L'Open Source Moss prend en charge les langues chinoises et anglaises et prend en charge la plug-inrisation, telles que la résolution d'équations, la recherche, etc. Les paramètres sont 16B et pré-formés dans environ 700 milliards de mots chinois et anglais et code. Les instructions de dialogue suivantes sont affinées, l'apprentissage amélioré du plug-in et la formation des préférences humaines ont plusieurs cycles de capacités de dialogue et la possibilité d'utiliser plusieurs plug-ins. L'adresse open source de ce projet est:
https://github.com/openlmlab/moss
Semblable à Minigpt-4 et Llava, il s'agit d'un modèle de modèle multimodal open source GPT-4, qui poursuit l'idée de formation modulaire de la série MPLUG. Il ouvre actuellement le modèle de quantité de paramètres 7B, et en même temps, il propose un ensemble de tests complet pour la première fois pour la compréhension de l'enseignement lié à la visuelle. Grâce à l'évaluation manuelle, les modèles existants, y compris Llava, Minigpt-4 et d'autres travaux, démontrent de meilleures capacités multimodales, en particulier dans la capacité de compréhension de l'enseignement multimodal, la capacité de dialogue multi-ronde, la capacité de raisonnement de connaissances, etc. Il est regrettable que comme d'autres modèles graphiques et de texte, il ne soutient toujours que l'anglais, mais la version chinoise est déjà dans sa liste open source.
L'adresse open source de ce projet est: https://github.com/x-plug/mplug-owl
Pandalm est un modèle d'évaluation du modèle qui vise à évaluer automatiquement les préférences d'autres modèles à grande échelle pour générer du contenu, économisant les coûts d'évaluation manuels. Pandalm est livré avec une interface Web pour l'analyse et prend également en charge les appels de code Python. Il peut évaluer le texte généré par n'importe quel modèle et données avec seulement trois lignes de code, ce qui est très pratique à utiliser.
L'adresse open source du projet est: https://github.com/weopenml/pandalm
Lors de la conférence de Zhiyuan qui s'est tenue récemment, le Zhiyuan Research Institute a ouvert la source de son modèle d'illumination et de Sky Eagle, qui a une connaissance bilingue des chinois et de l'anglais. Les paramètres de base du modèle de la version open source comprennent 7 milliards et 33 milliards. Dans le même temps, il ouvre le modèle de dialogue Aquilachat et le modèle de génération de code de texte de quilacode, et les deux ont été ouverts pour des licences commerciales. Aquila adopte des architectures réservées au décodeur telles que GPT-3 et LLAMA, et met également à jour le vocabulaire du bilinguisme chinois et anglais, et adopte sa méthode de formation accélérée. Sa garantie de performance dépend non seulement de l'optimisation et de l'amélioration du modèle, mais bénéficie également de l'accumulation de données de haute qualité par Zhiyuan sur les grands modèles ces dernières années.
L'adresse open source du projet est: https://github.com/flagai-open/flagai/tree/master/examples/aquila
Récemment, Microsoft a publié un article multimodal Big Model et un code open source -codi, qui connecte complètement le texte-Image-Image-video, prend en charge les entrées arbitraires et la sortie modale arbitraire. Afin d'atteindre la génération de modalités arbitraires, les chercheurs ont divisé la formation en deux étapes. Dans la première étape, l'auteur a utilisé la stratégie d'alignement du pont et des conditions combinées pour s'entraîner, créant un modèle de diffusion potentiel pour chaque mode; Dans la deuxième étape, un module d'attention d'intersection a été ajouté à chaque modèle de diffusion potentiel et encodeur environnemental, qui pourrait projeter les variables latentes du modèle de diffusion potentiel dans l'espace partagé, afin que les modalités générées soient plus diversifiées.
L'adresse open source de ce projet est: https://github.com/microsoft/i-code/tree/main/icode-v3
Meta a lancé et ouvert ses provisions de Big Model Multimodal ImageBind, qui peuvent réaliser 6 modalités de croisement, y compris l'image, la vidéo, l'audio, la profondeur, la chaleur et le mouvement spatial. ImageBind résout le problème d'alignement en utilisant les caractéristiques de liaison des images, en utilisant de grands modèles de langage visuel et des capacités d'échantillon zéro pour se développer à de nouvelles modalités. Les données d'appariement d'images sont suffisantes pour lier ces six modes ensemble, permettant à différents modes d'ouvrir les divisions modales les unes des autres.
L'adresse open source du projet est: https://github.com/facebookresearch/imagebind
Le 10 avril 2023, Wang Xiaochuan a officiellement annoncé la création de la société de Big Model "Baichuan Intelligence", visant à créer une version chinoise d'Openai. Deux mois après sa création, Baichuan Intelligent a fait une source majeure de son modèle Baichuan-7B développé indépendamment, soutenant le chinois et l'anglais. Baichuan-7b dépasse non seulement d'autres grands modèles tels que ChatGLM-6B avec des avantages importants sur la liste d'évaluation autoritaire C-Eval, Agieval et Gaokao, mais dirige également de manière significative LLAMA-7B dans la liste d'évaluation de l'autorité en anglais MMLU. Ce modèle atteint une échelle de jetons sur des données de haute qualité et prend en charge la capacité d'expansion de dizaines de milliers de fenêtres dynamiques ultra-longues en fonction d'une optimisation efficace de l'opérateur d'attention. Actuellement, Open Source prend en charge les capacités de contexte 4K. Ce modèle open source est disponible dans le commerce et est plus sympathique que Llama.
L'adresse open source du projet est: https://github.com/baichuan-inc/baichuan-7b
Le 6 août 2023, l'équipe de Yuanxiang Xverse a ouvert le modèle Xverse-13B. Ce modèle est un grand modèle multilingue qui prend en charge jusqu'à 40 langues et prend en charge la longueur contextuelle jusqu'à 8192. Selon l'équipe, les caractéristiques de ce modèle sont: la structure du modèle: Xverse-13B utilise le modèle de transformateur standard du décodeur. Données de formation: 1,4 billion de jetons de données de haute qualité et diverses sont construits pour former pleinement le modèle, dont 40 chinois, anglais, russe et occidental. Plusieurs langues, en définissant finement le rapport d'échantillonnage de différents types de données, les langues chinoises et anglaises fonctionnent bien et peuvent également prendre en compte les effets d'autres langues; Segmentation des mots: Sur la base de l'algorithme BPE, une segmentation des mots avec une taille de vocabulaire de 100 278 a été formée en utilisant des centaines de corpus GB, qui peuvent prendre en charge plusieurs langues en même temps sans expansion supplémentaire de la liste des mots; Cadre de formation: développé indépendamment un certain nombre de technologies clés, notamment des opérateurs efficaces, l'optimisation de la mémoire vidéo, les stratégies de planification parallèle, le chevauchement des communications de communication de données, la collaboration sur la plate-forme et le cadre, etc., ce qui rend l'efficacité de la formation plus élevée et la stabilité du modèle solide. Le taux d'utilisation de puissance de calcul de pointe sur le cluster de Kilocard peut atteindre 58,5%, se classant parmi le premier plan de l'industrie.
L'adresse open source de ce projet est: https://github.com/xverse-ai/xverse-13b
Le 3 août 2023, le modèle de 7 milliards d'Alibaba Tongyi Qianwen était open source, y compris les modèles généraux et les modèles de dialogue, et est open source, gratuit et disponible dans le commerce. Selon les rapports, Qwen-7b est un modèle de langue large basé sur le transformateur et est formé sur des données pré-formation à l'échelle super-large. Les types de données pré-formation sont diverses et couvrent un large éventail de domaines, y compris un grand nombre de textes en ligne, de livres professionnels, de codes, etc. Il s'agit d'un modèle de quai qui prend en charge les langues chinoises et anglaises, formées sur plus de 2 billions d'ensembles de données de jeton, et la longueur de la fenêtre de contexte atteint 8k. Qwen-7b-chat est un modèle de dialogue chinois-anglais basé sur le modèle de piédestal QWEN-7B. Le modèle pré-formé Tongyi Qianwen 7B a bien fonctionné dans plusieurs évaluations de référence faisant autorité. Ses capacités chinoises et anglaises dépassent de loin les modèles open source de la même échelle au pays et à l'étranger, et certaines capacités ont même dépassé les modèles open source de tailles 12b et 13b.
L'adresse open source du projet est: https://github.com/qwenlm/qwen-7b
Llama est un tout nouveau modèle de langage d'intelligence artificielle à grande échelle publié par Meta, qui fonctionne bien dans des tâches telles que la génération de texte, le dialogue, le résumé des matériaux écrits, la prouvance des théorèmes mathématiques ou la prévision des structures protéiques. Le modèle LLAMA prend en charge 20 langues, y compris les langues alphabétiques latines et cyrilliques. Actuellement, le modèle d'origine ne soutient pas le chinois. On peut dire que la fuite épique de Llama a vigoureusement favorisé le développement open source de type Chatgpt.
(Mis à jour le 22 avril 2023) mais malheureusement, l'autorisation de Llama est actuellement limitée et ne peut être utilisée que pour la recherche scientifique et n'est pas autorisée pour une utilisation commerciale. Pour résoudre le problème commercial entièrement open source, le projet Redpajama a vu le jour, visant à créer une réplique entièrement open source de lama qui peut être utilisée pour des applications commerciales et à fournir un processus plus transparent pour la recherche. Le Redpajama complet comprend un ensemble de données de jetons de 1,2 billion, et sa prochaine étape sera de commencer une formation à grande échelle. Ce travail vaut toujours la peine d'attendre et son adresse open source est:
https://github.com/togethercomputer/redpajama-data
(Mis à jour le 7 mai 2023)
Redpajama a mis à jour son fichier de modèle de formation, y compris deux paramètres: 3b et 7b, où 3B peut fonctionner sur la carte graphique de jeu RTX2070 publiée il y a 5 ans, compensant l'écart dans LLAMA sur 3B. Son adresse modèle est:
https://huggingface.co/togetherComputer
En plus de Redpajama, Mosaicml a lancé le modèle de la série MPT et ses données de formation utilisent les données Redpajama. Dans diverses évaluations des performances, le modèle 7B est comparable au lama d'origine. L'adresse open source de son modèle est:
https://huggingface.co/mosaicml
Qu'il s'agisse de Redpajama ou MPT, il ouvre également le modèle de version de chat correspondante. L'open source de ces deux modèles a apporté un énorme coup de pouce à la commercialisation de Chatgpt-like.
(Mis à jour le 1er juin 2023)
Falcon est une base de gros modèles ouverte qui compare Llama. Il a deux échelles de mesure des paramètres: 7b et 40b. Les performances de 40b sont connues sous le nom de LLAMA 65B Ultra-High. Il est entendu que Falcon utilise toujours le modèle de décodeur autorégressif GPT, mais il a fait beaucoup d'efforts dans les données. Après avoir gratté le contenu du réseau public et construit l'ensemble de données pré-étiré initial, il utilise le vidage CommonCrawl pour effectuer un filtrage à grande échelle et une déduplication à grande échelle, et obtient enfin un énorme ensemble de données pré-trainé composé de près de 5 billions de jetons. Dans le même temps, de nombreux corpus sélectionnés ont été ajoutés, notamment des articles de recherche et des conversations sur les réseaux sociaux. Cependant, l'autorisation du projet a été controversée et la méthode d'autorisation "semi-commerciale" est adoptée, et 10% des dépenses commerciales commencent à se produire après que le revenu atteint 1 million.
L'adresse open source du projet est: https://huggingface.co/tiiuae
(Mis à jour le 3 juillet 2023)
Le Falcon d'origine manque de capacités de soutien chinois comme Llama. L'équipe de projet "Linly" a construit et ouvert la version chinoise de Chinese-Falcon basée sur le modèle Falcon. Le modèle a d'abord étendu et étendu la liste de vocabulaire, dont 8701 caractères chinois couramment utilisés, les 20 000 premiers mots chinois à haute fréquence dans la liste de vocabulaire Jieba et 60 marques de ponctuation chinoises. Après la déduplication, la taille de la liste de vocabulaire a été étendue à 90 046. Pendant la phase d'entraînement, le corpus 50G et les données à grande échelle 2T ont été utilisés pour la formation.
L'adresse open source du projet est: https://github.com/cvi-szu/linly
(Mis à jour le 24 juillet 2023)
Le Falcon d'origine manque de capacités de soutien chinois comme Llama. L'équipe de projet "Linly" a construit et ouvert la version chinoise de Chinese-Falcon basée sur le modèle Falcon. Le modèle a d'abord étendu et étendu la liste de vocabulaire, dont 8701 caractères chinois couramment utilisés, les 20 000 premiers mots chinois à haute fréquence dans la liste de vocabulaire Jieba et 60 marques de ponctuation chinoises. Après la déduplication, la taille de la liste de vocabulaire a été étendue à 90 046. Pendant la phase d'entraînement, le corpus 50G et les données à grande échelle 2T ont été utilisés pour la formation.
L'adresse open source du projet est: https://github.com/cvi-szu/linly
L'alpaga (modèle alpaca) publié par Stanford est un nouveau modèle basé sur le modèle LLAMA-7B. Le principe de base est de permettre au modèle Text-DavinciCI-003 d'OpenAI de générer des échantillons d'instructions de 52k de manière auto-instruite pour affiner le lama. Le projet a ouvert les données de formation des sources, du code pour générer des données de formation et des hyperparamètres. Le fichier modèle n'a pas encore été ouvert, atteignant plus de 5,6 000 étoiles en une journée. Ce travail est très populaire en raison de son faible coût et de son accès aux données faciles, et a également ouvert la voie à l'imitation de Chatgpt à faible coût. Son adresse GitHub est:
https://github.com/tatsu-bab/stanford_alpaca
Il s'agit d'une implémentation open source du chatbot LLAMA + AI basé sur l'apprentissage du renforcement de la rétroaction humaine lancée par Nebuly + AI. Son itinéraire technique est similaire à Chatgpt. Le projet vient d'être lancé depuis 2 jours et a remporté des étoiles 5,2k. Son adresse GitHub est:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accerate/chatllama
L'algorithme de processus de formation Chatllama est principalement utilisé pour obtenir une formation plus rapide et moins chère que le chatgpt. On dit que cela est près de 15 fois plus rapide. Les principales caractéristiques sont:
Une implémentation open source complète permet aux utilisateurs de créer des services de style ChatGPT basés sur des modèles LLAMA pré-formés;
L'architecture de lama est plus petite, ce qui rend le processus de formation et le raisonnement plus rapide et moins coûteux;
Prise en charge intégrée pour Deeppeed Zero pour accélérer le processus de réglage fin;
Prend en charge les architectures de modèle LLAMA de différentes tailles, et les utilisateurs peuvent affiner le modèle en fonction de leurs propres préférences.
Openchatkit est créé conjointement par l'équipe ensemble, où se trouvent les anciens chercheurs d'Openai, ainsi que par les équipes LAION et ONTOCORD.AI. Openchatkit contient 20 milliards de paramètres et est affiné avec la version open source de GPT-3 GPT-NOX-20B. Dans le même temps, un apprentissage en renforcement différent de ChatGpts, Openchatkit utilise un modèle d'audit de paramètres de 6 milliards pour filtrer des informations inappropriées ou nocives pour assurer la sécurité et la qualité du contenu généré. Son adresse GitHub est:
https://github.com/togetherComputer/Openchatkit
Basé sur Stanford Alpaca, le réglage fin supervisé est réalisé sur la base de Bloom et Llama. Les tâches de semences de Stanford Alpaca sont toutes en anglais et les données recueillies sont également en anglais. Ce projet open source est de promouvoir le développement de la communauté open source du Big Model du dialogue chinois. Il a été optimisé pour le chinois. Le réglage du modèle utilise uniquement les données produites par Chatgpt (sans inclure d'autres données). Le projet contient ce qui suit:
175 Missions de semences chinoises
Code pour générer des données
Les données générées par 10m sont actuellement ouvertes avec des ensembles de données d'instructions mathématiques de 1,5 m, 0,25 m et des ensembles de données de dialogue de tâches multi-rounds de 0,8 m.
Modèle optimisé basé sur Bloomz-7b1-MT et LLAMA-7B
L'adresse github est: https://github.com/lianjatech/belle
Alpaca-Lora est un autre chef-d'œuvre de l'Université de Stanford. Il utilise la technologie LORA (Adaptation de faible rang) pour reproduire les résultats de l'alpaga, en utilisant une méthode à moindre coût, et uniquement formé sur une carte graphique RTX 4090 pendant 5 heures pour obtenir un modèle avec un niveau d'alpaga. De plus, le modèle peut fonctionner sur un Raspberry Pi. Dans ce projet, il utilise des étreintes de PEFT de Face pour un réglage fin bon marché et efficace. PEFT est une bibliothèque (LORA est l'une de ses technologies prises en charge) qui vous permet d'utiliser une variété de modèles de langage basés sur des transformateurs et de les affiner avec LORA, permettant un réglage fin peu coûteux et efficace du modèle sur le matériel général. L'adresse GitHub de ce projet est:
https://github.com/tloen/alpaca-lora
Bien que l'alpaga et l'alpaga-lora aient fait de grands progrès, leurs tâches de semences sont toutes deux en anglais et manquent de soutien aux Chinois. D'une part, en plus de ce qui précède, Belle a collecté une grande quantité de corpus chinois, d'autre part, sur la base du travail de prédécesseurs tels que Alpaca-Lora, le modèle de langue chinoise Luotuo (Luotuo) ouverte par trois développeurs individuels de la Central Chire Normal University et d'autres institutions, une seule carte peut terminer le déploiement d'entraînement. Actuellement, le projet publie deux modèles Luotuo-Lora-7B-0.1, Luotuo-Lora-7B-0.3, et un modèle est dans le plan. Son adresse GitHub est:
https://github.com/lc1332/chinese-alpaca-lora
Inspiré par Alpaca, Dolly a utilisé l'ensemble de données Alpaca pour atteindre un réglage fin sur GPT-J-6B. Étant donné que Dolly elle-même est un "clone" d'un modèle, l'équipe a finalement décidé de le nommer "Dolly". Inspiré par l'alpaga, cette méthode de clonage devient de plus en plus populaire. En résumé, il est à peu près adopté la méthode d'acquisition de données open source d'Alpaga et a affiner les instructions sur les anciens modèles de taille 6B ou 7B pour obtenir des effets de type Chatgpt. Cette idée est très économique et peut rapidement imiter le charme de Chatgpt. Il est très populaire et une fois qu'il a été lancé, il est plein d'étoiles. L'adresse GitHub de ce projet est:
https://github.com/databrickslabs/dolly
Après avoir lancé Alpaca, les chercheurs de Stanford se sont associés à CMU, UC Berkeley, etc. pour lancer un nouveau modèle - Vicuna avec 13 milliards de paramètres (communément appelés Alpaca et Llama). Il ne coûte que 300 $ pour obtenir des performances de 90% de Chatgpt. Vicuna est utilisée pour affiner le lama sur le dialogue a-to-axé collecté par Sharegpt. Le processus de test utilise GPT-4 comme critères d'évaluation. Les résultats montrent que Vicuna-13b obtient des capacités qui correspondent à Chatgpt et Bard dans plus de 90% des cas.
UC Berkeley Lmsys Org a récemment publié Vicuna avec 7 milliards de paramètres. Il est non seulement de petite taille, de grande efficacité et de capacité forte, mais peut également fonctionner sur un Mac avec une puce M1 / M2 en seulement deux lignes de commande, et peut également permettre l'accélération du GPU!
L'adresse open source de GitHub est: https://github.com/lm-sys/fastchat/
Une autre version chinoise a été ouverte par chinois-vicuna, avec l'adresse github comme:
https://github.com/facico/chinese-vicuna
Après que Chatgpt est devenu populaire, les gens cherchaient un chemin rapide vers le temple. Certaines apparitions de type Chatgpt ont commencé à apparaître, en particulier la suite de chatppt à faible coût est devenue une manière populaire. LMFlow est un produit né dans ce scénario de demande, qui permet de raffiner de grands modèles sur des cartes graphiques ordinaires comme le 3090. Le projet a été lancé par l'équipe de statistiques de science et de technologie de Hong Kong Science and Technology, et s'est engagée à établir une plate-forme de recherche entièrement ouverte en grande partie qui prend en charge diverses expériences sous les ressources machines, et améliore la plate-forme existante des méthodes de données et un élaboration d'optimisation ALGORITHA Système de formation de modèle plus grand qui est plus efficace que les méthodes précédentes.
En utilisant ce projet, même les ressources informatiques limitées peuvent permettre aux utilisateurs de prendre en charge une formation personnalisée pour les champs propriétaires. Par exemple, LLAMA-7B, un 3090 prend 5 heures pour terminer la formation, ce qui réduit considérablement le coût. Le projet ouvre également le service de questions / réponses de l'expérience instantanée côté Web (lmflow.com). L'émergence et l'open source de LMFlow permettent aux ressources ordinaires de former diverses tâches telles que les questions et réponses, la compagnie, l'écriture, la traduction, la consultation sur le terrain experte, etc. De nombreux chercheurs tentent actuellement d'utiliser ce projet pour former de grands modèles avec un volume de paramètres de 65 milliards ou même plus.
L'adresse GitHub de ce projet est:
https://github.com/optimalscale/lmflow
Le projet propose une méthode pour collecter automatiquement les conversations ChatGpt, permettant à Chatgpt de se dispenser, de génère des jeux de données de dialogue multi-rondes de haute qualité et de collecter environ 50 000 Corpus Q&R de haute qualité de Quora, Stackoverflow et Medqa, respectivement, et a été tous ouverts. Dans le même temps, il a amélioré le modèle LLAMA et l'effet est assez bon. Bai Ze a également adopté la solution de réglage fin LORA à faible coût à faible coût pour obtenir trois échelles différentes: Bai Ze-7B, 13B et 30B, ainsi qu'un modèle dans le domaine vertical des soins médicaux. Malheureusement, le nom chinois est bien nommé, mais il ne soutient toujours pas le chinois. Le modèle chinois Bai Ze serait sous le plan et serait publié à l'avenir. Son adresse github open source est:
https://github.com/project-baize/baize
Le remplacement de Flat basé sur Llama continue de fermenter, Berkeley d'UC Berkeley a publié un modèle de conversation Koala qui peut fonctionner sur les GPU de consommation avec des paramètres de 13B. L'ensemble de données de formation de Koala comprend les parties suivantes: Données ChatGPT et données open source (Open Instruction Generalist (OIG), jeu de données utilisé par le modèle de Stanford Alpaca, Anthropic HH, Openai WebGPT, Openai Résumé). Le modèle Koala est implémenté en Easylm en utilisant JAX / Flax, en utilisant 8 GPU A100, et il faut 6 heures pour terminer 2 itérations. L'effet d'évaluation est meilleur qu'Alpaca, atteignant 50% de performances de Chatgpt.
Adresse open source: https://github.com/young-geng/Easylm
Avec l'avènement de Stanford Alpaca, un grand nombre de familles d'Alpaca basées sur des lama et de familles d'animaux élargies ont commencé à émerger, et enfin, les chercheurs en face de l'étreinte ont récemment publié un blog Stackllama: A Practical Guide to Training Llama avec RLHF. Dans le même temps, un modèle de paramètres de 7 milliards - Stackllama a également été publié. Il s'agit d'un modèle affiné dans LLAMA-7B grâce à l'apprentissage du renforcement de la rétroaction humaine. Pour plus de détails, consultez l'adresse de son blog:
https://huggingface.co/blog/stackllama
Le projet optimise Llama pour chinois et ouvre son système de dialogue affiné. Les étapes spécifiques de ce projet incluent: 1. Développez la liste des mots, en utilisant la phrase pour s'entraîner et construire sur les données chinoises et fusionner avec la liste de mots LLAMA; 2. Pré-formation, sur la nouvelle liste de mots, environ 20 g de corpus chinois général ont été formés et la technologie LORA a été utilisée dans la formation; 3. En utilisant l'alpaga de Stanford, une formation finale a été effectuée sur des données 51k pour obtenir la capacité de dialogue.
L'adresse open source est: https://github.com/ymcui/chinese-llama-alpaca
Le 12 avril, Databricks a publié Dolly 2.0, connu sous le nom de première source open source de l'industrie, LLM conforme à la directive. L'ensemble de données a été généré par les employés de Databricks et a été ouvert et disponible à des fins commerciales. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
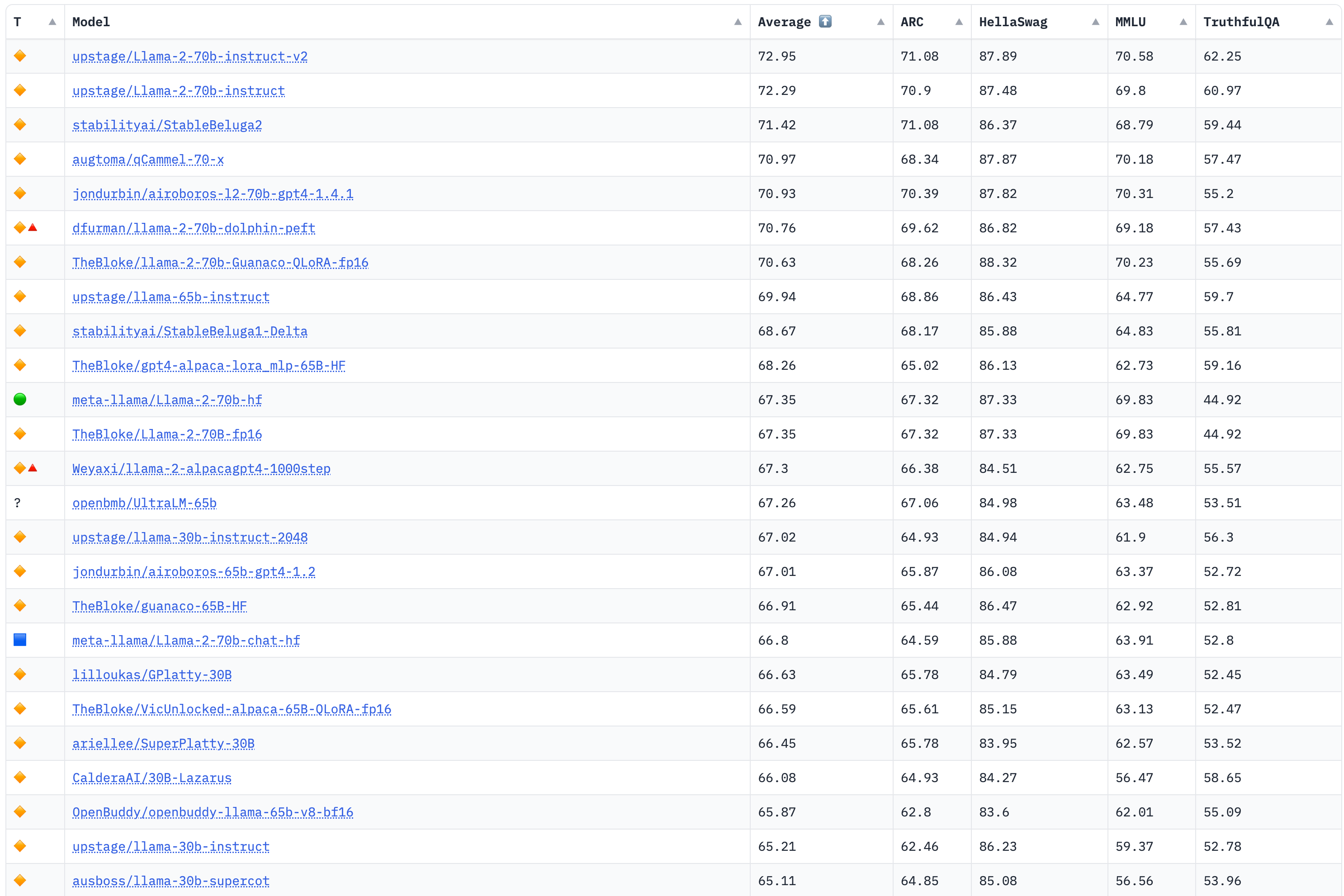
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
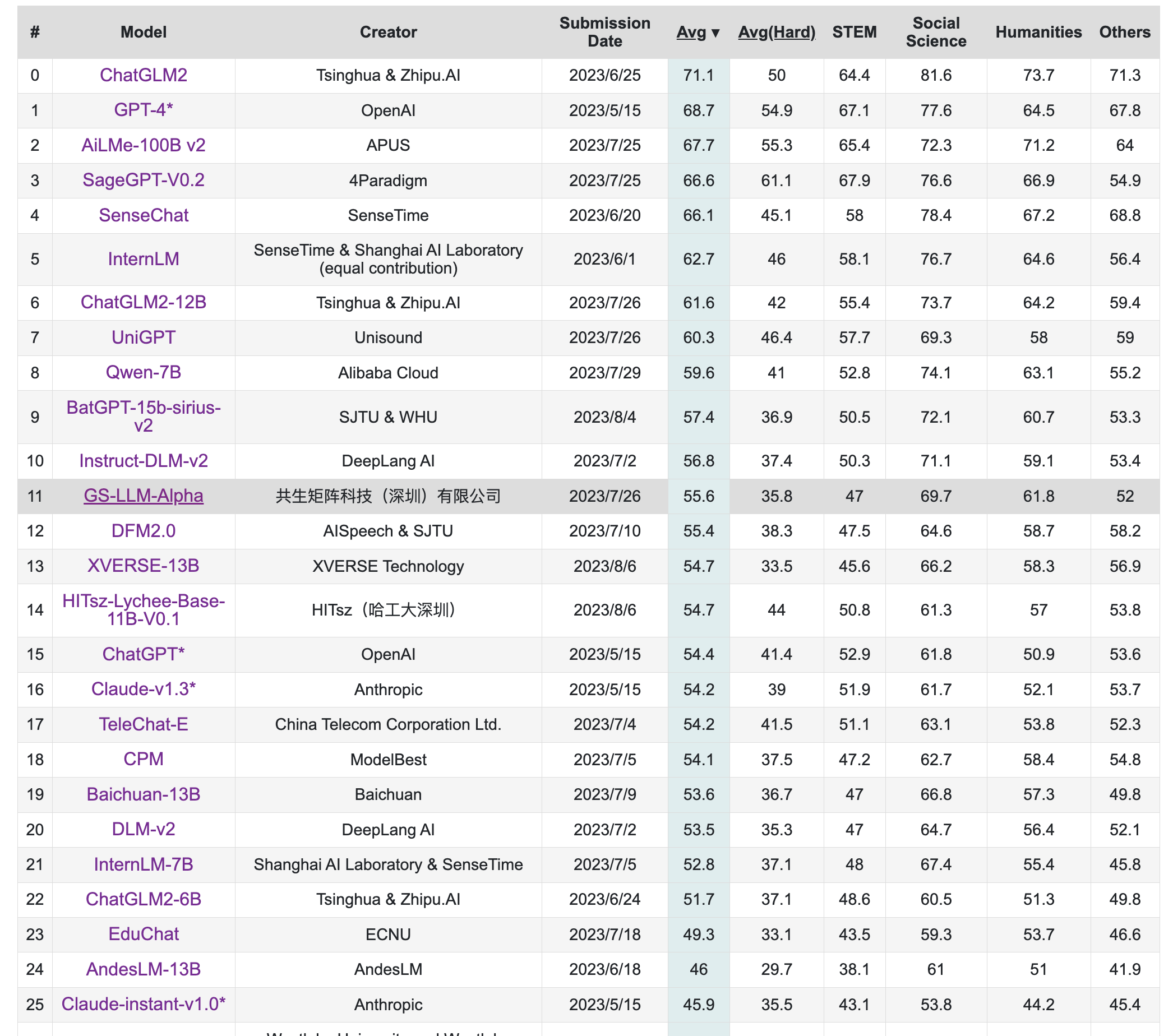
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

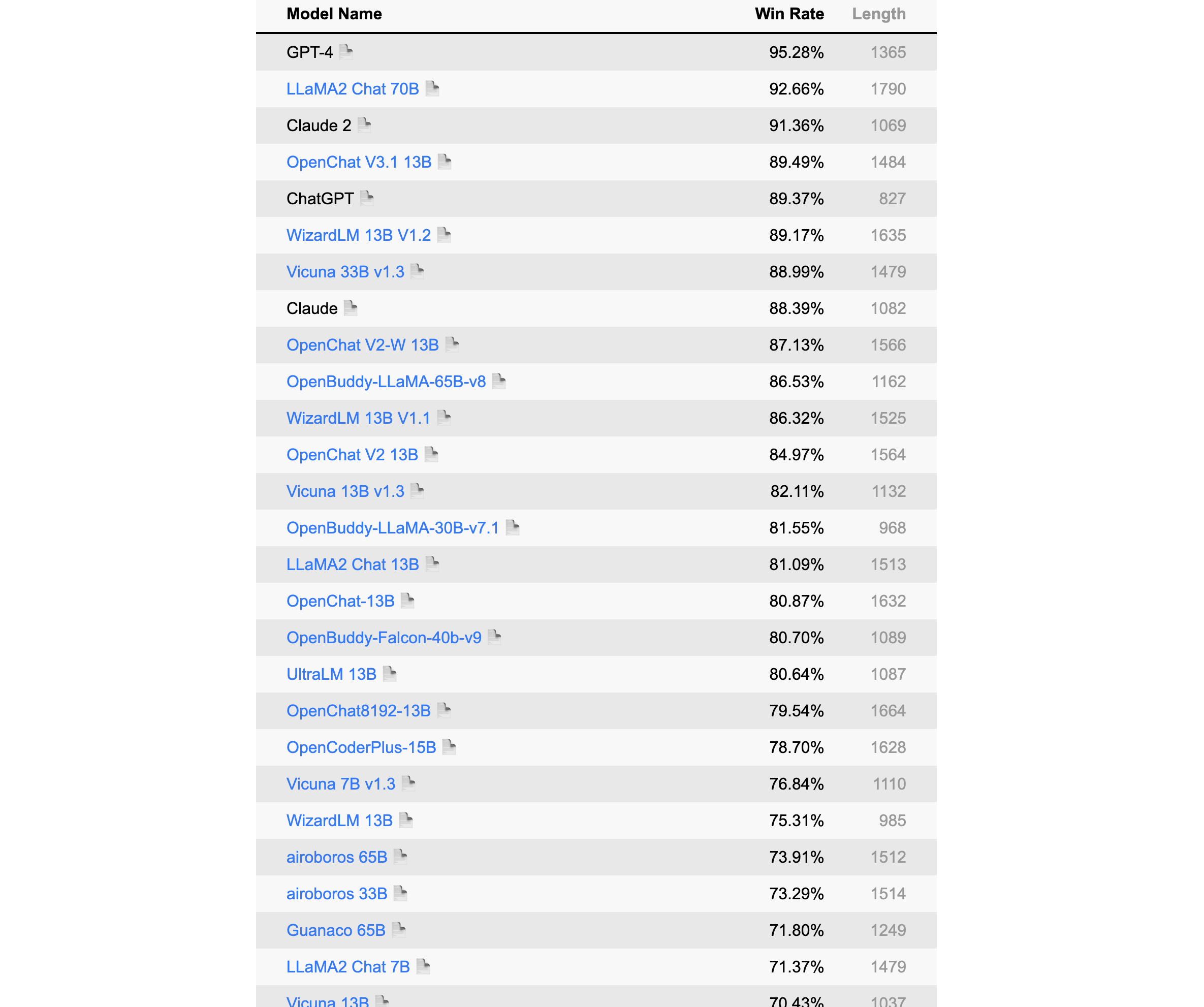
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


