FindTheChatGPTer
1.0.0
ملخص chatgpt/gpt4 مفتوح المصدر "استبدال عادي" ، تحديث مستمر
أصبحت ChatGPT شائعة ، وأصدرت العديد من الجامعات المحلية والمؤسسات البحثية والمؤسسات خطط إصدار مماثلة لـ ChatGPT. ChatGPT ليس مفتوح المصدر ، ومن الصعب للغاية إعادة إنتاج. حتى الآن ، لم تستنسخ أي وحدة أو مؤسسة القدرات الكاملة لـ GPT3. الآن ، أعلن Openai رسميًا عن إصدار نموذج GPT4 مع رسومات ونص متعدد الوسائط ، وقد تم تحسين قدراته بشكل كبير مقارنة بـ ChatGPT. يبدو أنه رائحة الثورة الصناعية الرابعة التي يسيطر عليها الذكاء الاصطناعي العام.
سواء أكان في الخارج أو في المنزل ، فإن الفجوة بين Openai تكبر وأكبر ، والجميع يلحقون بطريقة مزدحمة ، لذلك هم في وضع مفيد في هذا الابتكار التكنولوجي. في الوقت الحاضر ، فإن البحث وتطوير العديد من الشركات الكبيرة يأخذ بشكل أساسي طريق المصدر المغلقة. هناك القليل من التفاصيل التي تم إصدارها رسميًا بواسطة ChatGPT و GPT4 ، وليس مثل المقدمة الورقية السابقة التي قدمت عشرات الصفحات ، فقد وصل عصر تسويق Openai. بالطبع ، استكشفت بعض المنظمات أو الأفراد بدائل مفتوحة المصدر. تم تلخيص هذه المقالة على النحو التالي. سأستمر في تتبعها. هناك بدائل مفتوحة المصدر محدثة لتحديث هذا المكان في الوقت المناسب.
يتبنى هذا النوع من الطرق بشكل أساسي أساليب غير الملمس وغيرها من أساليب التثبيت لتصميم أو تحسين نماذج GPT و T5 بشكل مستقل ، ويدرك عمليات دورة كاملة مثل التدريب قبل التدريب ، والتعلم الخاضع للإشراف ، والتعلم التعزيز.
تم تطوير Chatyuan (Yuanyu AI) ونشره من قبل فريق Yuanyu Intelligent Development. يدعي أنه أول نموذج حوار وظيفي في الصين. يمكنه كتابة المقالات ، والقيام بالواجب المنزلي ، وكتابة الشعر ، وترجمة الصينية والإنجليزية ؛ يمكن أن توفر بعض المجالات المحددة مثل القوانين المعلومات ذات الصلة. هذا النموذج حاليًا يدعم الصينية فقط ، ورابط Github هو:
https://github.com/clue-ai/chatyuan
انطلاقًا من التفاصيل الفنية التي تم الكشف عنها ، تعتمد الطبقة الأساسية نموذجًا لـ T5 بمقياس 700 مليون معلمة ، وتشرف على النغمات بشكل جيد بناءً على recorclue لتشكيل Chatyuan. هذا النموذج هو في الأساس الخطوة الأولى من المسار الفني لثلاث خطوات ، ولا يتم تنفيذ أي تدريب على نموذج المكافأة والتدريب على التعلم التعزيز PPO.
في الآونة الأخيرة ، Open Colossalai Open Source تنفيذ ChatGpt. شارك استراتيجيتهم المكونة من ثلاث خطوات وتنفيذ المسار الفني لـ ChatGpt Core: GitHub هو كما يلي:
https://github.com/hpcaitech/colossalai
بناءً على هذا المشروع ، أوضحت استراتيجية ثلاث خطوات وشاركتها:
المرحلة الأولى (Stage1_sft.py): مرحلة صقل الإشراف SFT ، لم يتم تنفيذ المشروع المفتوح المصدر ، وهذا بسيط نسبيًا لأن Colossalai يدعم العناق. أستخدم مباشرة بضعة أسطر من وظيفة مدرب Huggingface لتنفيذها بسهولة. هنا استخدمت نموذج GPT2. من وجهة نظر تنفيذها ، فإنه يدعم نماذج GPT2 و OPT و Bloom ؛
المرحلة الثانية (Stage2_RM.Py): مرحلة تدريب نموذج المكافآت (RM) ، أي جزء Train_Reward_Model.py في أمثلة المشروع ؛
المرحلة الثالثة (Stage3_ppo.py): مرحلة التعلم التعزيز (RLHF) ، أي ، Project Train_prompts.py
يجب وضع تنفيذ الملفات الثلاثة في مشروع Colossalai ، حيث يتم ChatGpt النوى في الكود في المشروع الأصلي ، ويصبح Cores.nn chatgpt.models في المشروع الأصلي.
ChatGLM هو نموذج حوار لسلسلة GLM من Zhipu AI ، وهي شركة تحول إنجازات التكنولوجيا في Tsinghua ، ويدعم اللغات الصينية والإنجليزية ، ولديها حاليًا نموذج المعلمة 6.2 مليار. يرث مزايا GLM ويحسن بنية النموذج ، وبالتالي خفض العتبة للنشر والتطبيق ، مع إدراك تطبيق الاستدلال للنماذج الكبيرة على بطاقات رسومات المستهلك. للحصول على تقنيات مفصلة ، يرجى الرجوع إلى github:
عنوان المصدر المفتوح لـ chatglm-6b هو: https://github.com/thudm/chatglm-6b
من المنظور التقني ، قامت بتنفيذ التعلم المعزز بـ ChatGPT لاستراتيجية المحاذاة البشرية ، مما يجعل تأثير الجيل أفضل وأقرب إلى القيمة الإنسانية. تشمل مجالات قدرتها الحالية بشكل أساسي الإدراك الذاتي ، والكتابة عن الخطوط العريضة ، وكتابة النصوص ، ومساعد كتابة البريد الإلكتروني ، واستخراج المعلومات ، والعب الأدوار ، ومقارنة التعليقات ، ونصائح السفر ، وما إلى ذلك. وقد طورت نموذجًا فائقًا 130 مليارًا تحت الاختبار الداخلي ، وهو ما يعتبر نموذج حوار مع مقياس أكبر للمعلمة في البديل الحالي مفتوح المصدر.
VisualGLM-6B (تم تحديثه في 19 مايو 2023)
افتتح الفريق مؤخرًا الإصدار متعدد الوسائط من ChatGlm-6B ، والذي يدعم الحوار متعدد الوسائط في الصور ، الصينية والإنجليزية. يستخدم جزء نموذج اللغة chatglm-6b ، ويقوم جزء الصورة بإنشاء جسر بين النموذج المرئي ونموذج اللغة عن طريق تدريب blip2-qformer. النموذج العام لديه ما مجموعه 7.8 مليار معلمة. يعتمد VisualGLM-6B على أزواج رسومية صينية عالية الجودة من مجموعة بيانات COGVIEW ، ويتم تدريبها مسبقًا مع 300 متر من أزواج الرسوم الإنجليزية المصفاة ، مع نفس الوزن باللغة الصينية والإنجليزية. تعمل طريقة التدريب هذه بشكل أفضل على محاذاة المعلومات المرئية في المساحة الدلالية لـ ChatGlm ؛ في مرحلة الضبط اللاحقة ، يتم تدريب النموذج على بيانات أسئلة وأجوبة مرئية طويلة لإنشاء إجابات تلبي التفضيلات البشرية.
VisualGLM-6B عنوان المصدر المفتوح هو: https://github.com/thudm/visualglm-6b
ChatGlm2-6b (تم تحديثه في 27 يونيو 2023)
افتتح الفريق مؤخرًا إصدار ChatGLM2-6B من ChatGlm من ChatGlm. مقارنةً بإصدار الجيل الأول ، تشمل ميزاته الرئيسية استخدام مقياس بيانات أكبر ، من 1T إلى 1.4T ؛ الأبرز هو دعمه الأطول في السياق ، والذي توسع من 2K إلى 32 ألف ، مما يتيح جولات أطول وأعلى من المدخلات ؛ بالإضافة إلى ذلك ، تم تحسين سرعة الاستدلال بشكل كبير ، بزيادة قدرها 42 ٪ ، وقد انخفضت موارد ذاكرة الفيديو المشغولة بشكل كبير.
chatglm2-6b عنوان مفتوح المصدر هو: https://github.com/thudm/Chatglm2-6b
يُعرف باسم أول مشروع استبدال chatgpt مفتوح المصدر ، وتستند فكرته الأساسية إلى بنية النخيل الكبيرة لغة Google واستخدام أساليب التعلم التعزيز (RLHF) من التعليقات البشرية. PALM هو طراز معلمة 540 مليار معلمة أصدرتها Google في أبريل من هذا العام ، استنادًا إلى تدريب نظام المسارات. يمكنه إكمال المهام مثل كتابة التعليمات البرمجية ، والدردشة ، وفهم اللغة ، وما إلى ذلك ، ولديها أداء تعليمي قوي منخفض العينة في معظم المهام. في الوقت نفسه ، تم اعتماد آلية التعلم المعززة التي تشبه ChatGPT ، والتي يمكن أن تجعل إجابات الذكاء الاصطناعي أكثر تمشيا مع متطلبات السيناريو وتقليل سمية النموذج.
عنوان github هو: https://github.com/lucidrains/palm-rlhf-pytorch
يُعرف المشروع بأنه أكبر نموذج مفتوح المصدر ، يصل إلى 1.5 تريليون ، وهو نموذج متعدد الوسائط. تتضمن مجالات قدرتها فهم اللغة الطبيعية ، والترجمة الآلية ، والسؤال الذكي والإجابة ، وتحليل المشاعر ومطابقة الرسوم ، وما إلى ذلك. عنوان المصدر المفتوح هو:
https://huggingface.co/banana-dev/gptrillion
(في 24 مايو ، 2023 ، هذا المشروع هو برنامج نكتة يوم كذبة أبريل. تم حذف المشروع. سأشرح ذلك بموجب هذا
OpenFlamingo هو إطار يعمل على معايير GPT-4 ويدعم تدريب وتقييم النماذج متعددة الوسائط واسعة النطاق. تم إصداره من قِبل Laion غير الهادفة للربح وهو استنساخ لنموذج Flamingo DeepMind. يعد OpenFlamingo-9B القائم على المصدر المفتوح حاليًا طراز OpenFlamingo-9b. يتم تدريب نموذج Flamingo على مجموعة شبكية واسعة النطاق تحتوي على نص وصور متشابكة ، ولديه القدرة على تعلم عينات محدودة السياق. ينفذ OpenFlamingo نفس الهندسة المعمارية المقترحة في Flamingo الأصلي ، والتي تم تدريبها على عينات 5 أمتار من مجموعة بيانات C4 جديدة متعددة الوسائط وعينات 10 أمتار من Laion-2B. عنوان المصدر المفتوح لهذا المشروع هو:
https://github.com/mlfoundations/open_flamingo
في 21 فبراير من هذا العام ، أصدرت جامعة فودان MOSS وفتحت تجريبية عامة ، والتي تسببت في بعض الجدل بعد انهيار الإصدار التجريبي العام. الآن بدأ المشروع في تحديثات مهمة ومصدر مفتوح. يدعم MOSS مفتوح المصدر كل من اللغات الصينية والإنجليزية ، ويدعم إمكانية التكلفة ، مثل حل المعادلات والبحث ، وما إلى ذلك. المعلمات 16B ، وتدربت مسبقًا في حوالي 700 مليار كلمة صينية وإنجليزية ورمز. تعرّف تعليمات الحوار اللاحقة ، وتدريب التعلم المعزز للمكوّلية والتدريب على التفضيلات البشرية ، ولديه جولات متعددة من إمكانيات الحوار والقدرة على استخدام المكونات الإضافية المتعددة. عنوان المصدر المفتوح لهذا المشروع هو:
https://github.com/openlmlab/moss
على غرار Minigpt-4 و Llava ، فهو عبارة عن نموذج متعدد الوسائط مفتوح المصدر GPT-4 ، والذي يستمر في فكرة التدريب المعياري لسلسلة MPLUG. يفتح حاليًا نموذج كمية المعلمة 7B ، وفي الوقت نفسه ، يقترح مجموعة اختبار شاملة Owleval لأول مرة لفهم التعليمات المرئية. من خلال التقييم اليدوي ، توضح النماذج الحالية ، بما في ذلك LLAVA و MINIGPT-4 وغيرها من الأعمال ، قدرات أفضل متعددة الوسائط ، وخاصة في قدرة فهم التعليمات متعددة الوسائط ، وقدرة الحوار متعدد الجولات ، وقدرة التفكير المعرفة ، وما إلى ذلك. من المؤسف أنه مثل النماذج الرسومية والنصية الأخرى ، فإنها لا تزال تدعم اللغة الإنجليزية فقط ، ولكن النسخة الصينية هي بالفعل في قائمة المصدر المفتوح.
عنوان المصدر المفتوح لهذا المشروع هو: https://github.com/x-plug/mplug-owl
Pandalm هو نموذج لتقييم النموذج يهدف إلى تقييم تفضيلات النماذج الكبيرة الأخرى تلقائيًا لإنشاء محتوى ، وتوفير تكاليف التقييم اليدوي. يأتي Pandalm مع واجهة ويب للتحليل ، كما يدعم مكالمات رمز Python. يمكنه تقييم النص الذي تم إنشاؤه بواسطة أي نموذج وبيانات مع ثلاثة أسطر فقط من التعليمات البرمجية ، وهو مريح للغاية للاستخدام.
عنوان المصدر المفتوح للمشروع هو: https://github.com/weopenml/pandalm
في مؤتمر Zhiyuan الذي عقد مؤخرًا ، افتتح معهد Zhiyuan Research معهد تنويره ونموذج Sky Eagle ، الذي يعاني من معرفة بلغتين باللغة الإنجليزية والإنجليزية. تشمل معلمات النموذج الأساسية للنسخة المفتوحة المصدر 7 مليارات و 33 مليار. في الوقت نفسه ، يفتح نموذج حوار Aquilachat ونموذج توليد رمز النص Quilacode ، وقد تم فتح كلاهما للتراخيص التجارية. تتبنى Aquila هياكل Deconder فقط مثل GPT-3 و Llama ، وكذلك تحديث المفردات من أجل ثنائية اللغة الصينية والإنجليزية ، وتعتمد طريقة التدريب المتسارعة. لا يعتمد ضمان الأداء على تحسين النموذج وتحسينه فحسب ، بل يستفيد أيضًا من تراكم Zhiyuan للبيانات عالية الجودة على النماذج الكبيرة في السنوات الأخيرة.
عنوان المصدر المفتوح للمشروع هو: https://github.com/flagai-open/flagai/tree/master/examples/aquila
في الآونة الأخيرة ، نشرت Microsoft ورقة طراز كبيرة متعددة الوسائط ورمز المصدر المفتوح -CODI ، والتي تربط بالكامل فيميس-صورة ، تدخل الإدخال التعسفي والمخرجات التعسفية. من أجل تحقيق توليد طرائق تعسفية ، قام الباحثون بتقسيم التدريب إلى مرحلتين. في المرحلة الأولى ، استخدم المؤلف استراتيجية محاذاة الجسر والظروف المشتركة للتدريب ، مما يخلق نموذج انتشار محتمل لكل وضع ؛ في المرحلة الثانية ، تمت إضافة وحدة انتباه التقاطع إلى كل نموذج نشر محتمل ومشفر بيئي ، والذي يمكن أن يعرض المتغيرات الكامنة لنموذج الانتشار المحتمل في المساحة المشتركة ، بحيث تم تنوع الطرائق التي تم إنشاؤها.
العنوان المفتوح لهذا المشروع هو: https://github.com/microsoft/i-code/tree/main/i-code-v3
أطلقت Meta وفتحت مصادرها Multimodal Big Model ، والتي يمكن أن تحقق عبور 6 طرائق ، بما في ذلك الصورة والفيديو والصوت والعمق والحرارة والحركة المكانية. يحل ImageBind مشكلة المحاذاة باستخدام خصائص الربط للصور ، باستخدام نماذج اللغة البصرية الكبيرة وقدرات العينة الصفرية للتوسع إلى طرائق جديدة. بيانات إقران الصور كافية لربط هذه الأوضاع الستة معًا ، مما يتيح أنماط مختلفة لفتح انقسامات مشروط من بعضها البعض.
عنوان المصدر المفتوح للمشروع هو: https://github.com/facebookresearch/imagebind
في 10 أبريل 2023 ، أعلن وانغ شياوشوان رسميًا إنشاء شركة النموذج الكبير لمنظمة العفو الدولية "Baichuan Intelligence" ، بهدف إنشاء نسخة صينية من Openai. بعد شهرين من تأسيسها ، جعلت Baichuan Intelligent مصدرًا رئيسيًا لنموذج Baichuan-7B المتقدم بشكل مستقل ، ودعم الصينية والإنجليزية. لا يتجاوز Baichuan-7B نماذج كبيرة أخرى مثل ChatGLM-6B مع مزايا كبيرة على قائمة التقييم الصينية C-eval و Agieval و Gaokao الصينية ، ولكن أيضًا تقود Llama-7B بشكل كبير في قائمة التقييم الموثوق باللغة الإنجليزية MMLU. يصل هذا النموذج إلى مقياس رمزي تريليون على بيانات عالية الجودة ، ويدعم قدرة التوسع لعشرات الآلاف من النوافذ الديناميكية الطويلة الطويلة بناءً على تحسين عامل الاهتمام الفعال. حاليًا ، يدعم المصدر المفتوح قدرات سياق 4K. هذا النموذج مفتوح المصدر متاح تجاريا وهو أكثر ودية من لاما.
عنوان المصدر المفتوح للمشروع هو: https://github.com/baichuan-inc/baichuan-7b
في 6 أغسطس ، 2023 ، افتتح فريق Yuanxiang Xverse طراز Xverse-13B. هذا النموذج هو نموذج كبير متعدد اللغات يدعم ما يصل إلى أكثر من 40 لغة ويدعم طول السياق حتى 8192. ووفقًا للفريق ، فإن ميزات هذا النموذج هي: هيكل النموذج: يستخدم Xverse-13B هيكل المحول القياسي للترميز السائد فقط ، ويدعم طول الجولة الطويلة ، والمعارف ، والمعارف ، والمعارف ؛ بيانات التدريب: تم تصميم 1.4 تريليون رموز من البيانات عالية الجودة والمتنوعة لتدريب النموذج بالكامل ، بما في ذلك 40 صينيًا والإنجليز والروسي والغربي. لغات متعددة ، من خلال تحديد نسبة أخذ العينات بشكل ناع من أنواع مختلفة من البيانات ، تعمل اللغات الصينية والإنجليزية بشكل جيد ، ويمكن أن تأخذ في الاعتبار آثار اللغات الأخرى ؛ تجزئة الكلمات: استنادًا إلى خوارزمية BPE ، تم تدريب تجزئة الكلمات مع حجم المفردات 100،278 باستخدام مئات GB Corpus ، والتي يمكن أن تدعم لغات متعددة في نفس الوقت دون توسيع إضافي في قائمة الكلمات ؛ إطار التدريب: طورت بشكل مستقل عددًا من التقنيات الرئيسية ، بما في ذلك المشغلين الفعالين ، وتحسين ذاكرة الفيديو ، واستراتيجيات الجدولة الموازية ، وتداخل التواصل مع البيانات ، والتعاون من النظام الأساسي ، والتعاون الإطاري ، وما إلى ذلك ، مما يجعل كفاءة التدريب أعلى واستقرار النموذج قوي. يمكن أن يصل معدل استخدام طاقة الحوسبة الذروة على كتلة كيلوكر إلى 58.5 ٪ ، حيث يحتل المرتبة بين المقدمة في هذه الصناعة.
عنوان المصدر المفتوح لهذا المشروع هو: https://github.com/xverse-ai/xverse-13b
في 3 أغسطس ، 2023 ، كان نموذج Alibaba Tongyi Qianwen الذي يبلغ 7 مليارات المصدر مفتوحًا ، بما في ذلك النماذج العامة ونماذج الحوار ، وهو مفتوح المصدر ، مجاني ومتوفر تجاريًا. وفقًا للتقارير ، يعد QWEN-7B نموذجًا لغويًا كبيرًا يعتمد على محول ويتم تدريبه على بيانات التدريب المسبقة على نطاق الفائق. أنواع بيانات ما قبل التدريب متنوعة وتغطي مجموعة واسعة من المناطق ، بما في ذلك عدد كبير من النصوص عبر الإنترنت ، والكتب المهنية ، والرموز ، وما إلى ذلك ، إنه نموذج قفص الاتهام يدعم اللغات الصينية والإنجليزية ، المدرب على أكثر من 2 تريليون من مجموعات البيانات الرمزية ، وطول نافذة السياق يصل إلى 8 كيلو. Qwen-7B-Chat هو نموذج حوار من الإنجليزي الصيني يعتمد على نموذج قاعدة Qwen-7B. كان أداء Tongyi Qianwen 7B المدرب مسبقًا أداءً جيدًا في تقييمات قياسية موثوقة متعددة. تتجاوز قدراتها الصينية والإنجليزية نماذج المصدر المفتوح بنفس المقياس في المنزل والخارج ، وبعض القدرات تجاوزت النماذج المفتوحة المصدر بأحجام 12B و 13B.
عنوان المصدر المفتوح للمشروع هو: https://github.com/qwenlm/qwen-7b
LLAMA هو نموذج جديد لذكاء الذكاء الاصطناعي الجديد على نطاق واسع أصدرته META ، والذي يؤدي بشكل جيد في مهام مثل توليد النص أو الحوار ، وتلخيص المواد المكتوبة ، أو نظريات رياضية ، أو تنبؤ هياكل البروتين. يدعم نموذج Llama 20 لغة ، بما في ذلك اللغات الأبجدية اللاتينية والسيريلية. حاليا ، النموذج الأصلي لا يدعم الصينية. يمكن القول أن التسرب الملحمي لـ LLAMA قد روج بقوة إلى تطوير المصدر المفتوح لـ ChatGPT.
(تم تحديثه في 22 أبريل 2023) ولكن لسوء الحظ ، فإن ترخيص Llama محدود حاليًا ولا يمكن استخدامه إلا للبحث العلمي ولا يُسمح بالاستخدام التجاري. لحل مشكلة Open Source التجارية بالكامل ، ظهر مشروع Redpajama ، بهدف إنشاء نسخة طبق الأصل مفتوحة المصادر بالكامل من Llama والتي يمكن استخدامها للتطبيقات التجارية وتوفير عملية أكثر شفافية للبحث. تتضمن Redpajama الكاملة مجموعة بيانات رمزية بقيمة 1.2 تريليون ، وستكون خطوته التالية هي بدء تدريب واسع النطاق. لا يزال هذا العمل يستحق التطلع إليه ، وعنوان المصدر المفتوح هو:
https://github.com/togethercomputer/redpajama-data
(تم تحديثه في 7 مايو 2023)
قامت Redpajama بتحديث ملف طراز التدريب الخاص به ، بما في ذلك معلمتان: 3B و 7B ، حيث يمكن أن يعمل 3B على بطاقة رسومات الألعاب RTX2070 التي تم إصدارها قبل 5 سنوات ، مما يعوض عن الفجوة في Llama على 3B. عنوان النموذج الخاص به هو:
https://huggingface.co/TogetherComputer
بالإضافة إلى Redpajama ، أطلقت Mosaicml نموذج سلسلة MPT ، وتستخدم بيانات التدريب بيانات RedPajama. في تقييمات الأداء المختلفة ، يكون نموذج 7B مماثل لـ Llama الأصلي. عنوان المصدر المفتوح لنموذجه هو:
https://huggingface.co/mosaicml
سواء أكان Redpajama أو MPT ، فإنه أيضًا مفتوح مصدر إصدار إصدار الدردشة المقابل. جلب المصدر المفتوح لهذين النموذجين دفعة كبيرة لتسويق تشبه ChatGPT.
(تم تحديثه في 1 يونيو 2023)
Falcon عبارة عن قاعدة نموذجية مفتوحة تقارن Llama. لديها اثنين من المقاييس قياس المعلمة: 7B و 40B. يُعرف أداء 40B باسم Llama 65 ب. من المفهوم أن Falcon لا يزال يستخدم نموذج فك ترميز GPT Autoregressed ، لكنه بذل الكثير من الجهد في البيانات. بعد كشط المحتوى من الشبكة العامة وبناء مجموعة البيانات الأولية المسبقة ، يستخدم تفريغ CommonCrawl لإجراء ترشيح واسع النطاق وإلهاء واسع النطاق ، ويحصل أخيرًا على مجموعة بيانات ضخمة تتكون من حوالي 5 تريليونات من الرموز. في الوقت نفسه ، تمت إضافة العديد من الأجسام المختارة ، بما في ذلك الأوراق البحثية ومحادثات الوسائط الاجتماعية. ومع ذلك ، فإن ترخيص المشروع كان مثيرًا للجدل ، ويتم اعتماد طريقة الترخيص "شبه التجميلية" ، وسيبدأ 10 ٪ من النفقات التجارية بعد أن يصل الدخل إلى مليون.
عنوان المصدر المفتوح للمشروع هو: https://huggingface.co/tiiuae
(تم تحديثه في 3 يوليو 2023)
يفتقر الصقر الأصلي إلى قدرات الدعم الصينية مثل لاما. قام فريق مشروع "Linly" ببناء وافتتح النسخة الصينية من الصينيين الفالكون استنادًا إلى طراز Falcon. قام النموذج أولاً بتوسيع قائمة المفردات وتوسيعها إلى حد كبير ، بما في ذلك 8701 شخصيات صينية شائعة الاستخدام ، وأول 20 ألف كلمة صينية عالية التردد في قائمة المفردات Jieba ، و 60 علامات ترقيم صينية. بعد إلغاء البيانات ، تم توسيع حجم قائمة المفردات إلى 90،046. خلال مرحلة التدريب ، تم استخدام بيانات 50 جرام و 2 T بيانات واسعة النطاق للتدريب.
عنوان المصدر المفتوح للمشروع هو: https://github.com/cvi-szu/linly
(تم تحديثه في 24 يوليو 2023)
يفتقر الصقر الأصلي إلى قدرات الدعم الصينية مثل لاما. قام فريق مشروع "Linly" ببناء وافتتح النسخة الصينية من الصينيين الفالكون استنادًا إلى طراز Falcon. قام النموذج أولاً بتوسيع قائمة المفردات وتوسيعها إلى حد كبير ، بما في ذلك 8701 شخصيات صينية شائعة الاستخدام ، وأول 20 ألف كلمة صينية عالية التردد في قائمة المفردات Jieba ، و 60 علامات ترقيم صينية. بعد إلغاء البيانات ، تم توسيع حجم قائمة المفردات إلى 90،046. خلال مرحلة التدريب ، تم استخدام بيانات 50 جرام و 2 T بيانات واسعة النطاق للتدريب.
عنوان المصدر المفتوح للمشروع هو: https://github.com/cvi-szu/linly
يعد Abaca (نموذج الألبكة) الصادر عن ستانفورد نموذجًا جديدًا يعتمد على طراز Llama-7B. المبدأ الأساسي هو السماح لنموذج Openai Text-Davinci-003 بإنشاء عينة تعليمية 52 ألفًا بطريقة تتراكم ذاتيًا إلى Llama. قام المشروع بفتح بيانات التدريب المصدر ، والرمز لإنشاء بيانات التدريب ، ومقاطعات فرطمية. لم يتم فتح ملف النموذج بعد من مصادر ، حيث يصل إلى أكثر من 5.6 ألف نجوم في يوم واحد. يحظى هذا العمل بشعبية كبيرة بسبب انخفاض تكلفته وسهولة الوصول إلى البيانات ، وقد فتح أيضًا طريق تقليد chatgpt منخفض التكلفة. عنوان github الخاص به هو:
https://github.com/tatsu-lab/stanford_alpaca
إنه تطبيق مفتوح المصدر لـ LLAMA+AI chatbot استنادًا إلى تعلم التعليقات البشرية التي أطلقتها Nebuly+AI. طريقها الفني يشبه ChatGPT. تم إطلاق المشروع للتو لمدة يومين وفاز 5.2 كيلو بايت. عنوان github الخاص به هو:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
تستخدم خوارزمية عملية تدريب Chatllama بشكل أساسي لتحقيق تدريب أسرع وأرخص من ChatGPT. يقال أن يكون ما يقرب من 15 مرة أسرع. الميزات الرئيسية هي:
يتيح تطبيق Open Source الكامل للمستخدمين بناء خدمات على غرار ChatGpt استنادًا إلى نماذج Llama التي تم تدريبها مسبقًا ؛
بنية لاما أصغر ، مما يجعل عملية التدريب والتفكير أسرع وأقل تكلفة ؛
دعم مدمج لـ DeepSpeed Zero لتسريع عملية الضبط ؛
يدعم بنيات طراز Llama من مختلف الأحجام ، ويمكن للمستخدمين ضبط النموذج وفقًا لتفضيلاتهم الخاصة.
تم إنشاء OpenChatkit بشكل مشترك من قبل فريق Together ، حيث يوجد باحثون سابقون في Openai ، بالإضافة إلى فرق Laion و Ontocord.ai. يحتوي OpenChatkit على 20 مليار معلمة ويتم ضبطه مع الإصدار المفتوح المصدر GPT-3 GPT-NOX-20B. في الوقت نفسه ، يستخدم OpenChatkit على نموذج تدقيق المعلمة 6 مليارات نموذج لتصفية المعلومات غير المناسبة أو الضارة لضمان سلامة وجودة المحتوى الذي تم إنشاؤه. عنوان github الخاص به هو:
https://github.com/togethercomputer/openchatkit
استنادًا إلى ستانفورد الألباكا ، يتم تحقيق النقل الخاضع للإشراف على أساس بلوم ولاما. مهام ستانفورد الألباكا كلها باللغة الإنجليزية ، والبيانات التي تم جمعها هي أيضا باللغة الإنجليزية. هذا المشروع مفتوح المصدر هو تعزيز تطوير مجتمع الحوار الصيني Big Model Open Source. لقد تم تحسينه للصينيين. يستخدم ضبط النموذج فقط البيانات التي تنتجها ChatGPT (لا تشمل أي بيانات أخرى). يحتوي المشروع على ما يلي:
175 مهمة بذرة صينية
رمز لإنشاء البيانات
البيانات التي تم إنشاؤها بواسطة 10 أمتار مفتوحة حاليًا من مصادر بمجموعات بيانات التعليمات الرياضية 1.5m و 0.25 متر ومجموعات بيانات حوار المهمة متعددة الجولات 0.8m.
نموذج محسن استنادًا إلى Bloomz-7B1-MT و Llama-7B
عنوان github هو: https://github.com/lianjiatech/belle
الألباكا لورا هي تحفة أخرى من جامعة ستانفورد. يستخدم تقنية LORA (التكيف منخفض الرتب) لإعادة إنتاج نتائج الألبكة ، باستخدام طريقة منخفضة التكلفة ، وتدريب فقط على بطاقة رسومات RTX 4090 لمدة 5 ساعات للحصول على طراز مع مستوى الألبكة. علاوة على ذلك ، يمكن أن يعمل النموذج على Raspberry Pi. في هذا المشروع ، يستخدم PEFT المعانقة للوجه من أجل صقل رخيص وفعال. PEFT هي مكتبة (Lora هي واحدة من تقنياتها المدعومة) التي تتيح لك استخدام مجموعة متنوعة من نماذج اللغة القائمة على المحولات وضبطها مع Lora ، مما يتيح صقلًا غير مكلف وفعال للنموذج على الأجهزة العامة. عنوان جيثب لهذا المشروع هو:
https://github.com/tloen/alpaca-lora
على الرغم من أن الألبكة والألباكا لورا حققت تقدماً كبيراً ، فإن مهامهم البذرة في اللغة الإنجليزية وتفتقر إلى الدعم للصينيين. من ناحية ، بالإضافة إلى ما ذكر أعلاه أن Belle جمعت كمية كبيرة من المجموعة الصينية ، من ناحية أخرى ، استنادًا إلى عمل أسلاف مثل الألباكا-لورا ، ونموذج اللغة الصينية Luotuo (Luotuo) يفتح من قبل ثلاثة مطورين فرديين من جامعة سنترال الصين العادية ، ويمكن لبطاقة واحدة أن تكمل عملية التدريب. حاليًا ، يطلق المشروع نموذجين من Luotuo-Lora-7B-0.1 ، Luotuo-Lora-7B-0.3 ، ونموذج واحد في الخطة. عنوان github الخاص به هو:
https://github.com/lc1332/chinese-alpaca-lora
مستوحاة من الألبكة ، استخدمت Dolly مجموعة بيانات الألبكة لتحقيق صقل جيد على GPT-J-6B. نظرًا لأن Dolly نفسها هي "استنساخ" لنموذج ما ، فقد قرر الفريق أخيرًا تسميته "Dolly". مستوحاة من الألبكة ، أصبحت طريقة الاستنساخ هذه أكثر وأكثر شعبية. باختصار ، يتم تبنيها تقريبًا طريقة الحصول على البيانات المفتوحة للمصدر في الألباكا ، وتعليمات دقيقة على النماذج القديمة بحجم 6B أو 7B لتحقيق تأثيرات تشبه ChatGPT. هذه الفكرة اقتصادية للغاية ويمكنها تقليد سحر chatgpt بسرعة. تحظى بشعبية كبيرة وبمجرد إطلاقها ، فهي مليئة بالنجوم. عنوان جيثب لهذا المشروع هو:
https://github.com/databrickslabs/dolly
بعد إطلاق الألبكة ، تعاون علماء ستانفورد مع CMU ، UC Berkeley ، وما إلى ذلك لإطلاق نموذج جديد - Vicuna مع 13 مليار معلمة (المعروفة باسم الألبكة ولاما). يكلف 300 دولار فقط لتحقيق 90 ٪ أداء من chatgpt. يتم استخدام Vicuna لضبط Llama في حوار مشتركة للمستخدمين التي تم جمعها بواسطة ShareGPT. تستخدم عملية الاختبار GPT-4 كمعايير التقييم. تظهر النتائج أن Vicuna-13B يحقق القدرات التي تتطابق مع ChatGpt و Bard في أكثر من 90 ٪ من الحالات.
أصدرت UC Berkeley Lmsys Org مؤخرًا Vicuna مع 7 مليارات معلمات. ليس صغيرًا في الحجم فقط ، وكفاءة عالية وقوية في القدرة ، ولكن يمكن أيضًا تشغيله على MAC مع شريحة M1/M2 في سطرين فقط من القيادة ، ويمكن أيضًا تمكين تسارع GPU!
العنوان المصدر المفتوح Github هو: https://github.com/lm-sys/fastchat/
تم فتح نسخة صينية أخرى من قبل الصينيين فيكونا ، مع عنوان جيثب على النحو التالي:
https://github.com/facico/chinese-vicuna
بعد أن أصبح Chatgpt شائعًا ، كان الناس يبحثون عن طريقة سريعة للمعبد. بدأت بعض المظاهر التي تشبه ChatGPT تظهر ، خاصة بعد ChatGPT بتكلفة منخفضة ، أصبحت طريقة شائعة. LMFLOW هو منتج ولد في سيناريو الطلب هذا ، والذي يمكّن من تحسين النماذج الكبيرة على بطاقات الرسومات العادية مثل 3090. بدأ المشروع من قبل جامعة هونغ كونغ للإحصاءات والتكنولوجيا ومختبرات التعلم الآلي ، ويتم التزامه بإنشاء منصة أكبر على أساس منصة. نظام تدريب النماذج أكثر كفاءة من الأساليب السابقة.
باستخدام هذا المشروع ، يمكن أن تسمح موارد الحوسبة المحدودة للمستخدمين بدعم التدريب الشخصي لحقول الملكية. على سبيل المثال ، يستغرق Llama-7B ، 3090 5 ساعات لإكمال التدريب ، مما يقلل من التكلفة بشكل كبير. يفتح المشروع أيضًا خدمة Q&A Experience من جانب الويب (lmflow.com). يمكّن ظهور ومصدر مفتوح لـ LMFLOW الموارد العادية لتدريب مختلف المهام مثل سؤال وجواب ، والرفقة ، والكتابة ، والترجمة ، والاستشارة الميدانية الخبراء ، وما إلى ذلك. يحاول العديد من الباحثين حاليًا استخدام هذا المشروع لتدريب النماذج الكبيرة بحجم معلمة 65 مليار أو حتى أعلى.
عنوان جيثب لهذا المشروع هو:
https://github.com/optimalscale/lmflow
يقترح المشروع طريقة لجمع محادثات ChatGPT تلقائيًا ، مما يسمح لـ ChatGPT بالتحدث الذاتي ، وتوليد دفعة من مجموعات بيانات حوار متعددة الجودة عالية الجودة ، وجمع حوالي 50000 جودة من أسئلة وأجوبة عالية الجودة من Quora و Stackoverflow و Medqa ، على التوالي ، تم الحصول عليها من المصادر المفتوحة. في الوقت نفسه ، قام بتحسين نموذج اللاما والتأثير جيد جدًا. اعتمدت Bai Ze أيضًا حل Lora الصقل الحالي Lora الحالي للحصول على ثلاثة مقاييس مختلفة: Bai Ze-7B و 13B و 30B ، بالإضافة إلى نموذج في مجال الرعاية الطبية الرأسية. لسوء الحظ ، تم تسمية الاسم الصيني بشكل جيد ، لكنه لا يزال لا يدعم اللغة الصينية. يقال إن نموذج Bai Ze الصيني يخضع للخطة وسيتم إصداره في المستقبل. عنوان GitHub مفتوح المصدر هو:
https://github.com/project-baize/baize
يستمر Ratgpt Flat Replace الذي يتخذ من Llama مقراً له في التخمير ، أصدرت بيركلي من جامعة كاليفورنيا في بيركلي نموذج محادثة Koala يمكن تشغيله على وحدات معالجة الرسومات الاستهلاكية مع معلمات 13 ب. تتضمن مجموعة بيانات التدريب في Koala الأجزاء التالية: بيانات ChatGPT وبيانات المصدر المفتوح (Open Erransive Generalist (OIG) ، ومجموعة البيانات التي تستخدمها نموذج Stanford Alpaca ، و HH ، Openai WebGPT ، Openai Summarization). يتم تنفيذ نموذج Koala في EasyLM باستخدام Jax/Flax ، باستخدام 8 A100 وحدات معالجة الرسومات ، ويستغرق 6 ساعات لإكمال 2 تكرار. تأثير التقييم أفضل من الألبكة ، حيث يحقق أداء بنسبة 50 ٪ من chatgpt.
عنوان مفتوح المصدر: https://github.com/young-geng/easylm
مع ظهور ستانفورد الألباكا ، بدأ عدد كبير من عائلات الألباكا التي تتخذ من لاما وعائلات الحيوانات الممتدة في الظهور ، وأخيراً ، نشر باحثون في مواجهة مدونة Stackllama: دليل عملي لتدريب Llama مع RLHF. في الوقت نفسه ، تم إصدار نموذج معلمة 7 مليارات - Stackllama. هذا نموذج تم ضبطه في LLAMA-7B من خلال التعلم التعزيز التعليقات البشرية. للحصول على التفاصيل ، راجع عنوان مدونتها:
https://huggingface.co/blog/stackllama
يعمل المشروع على تحسين Llama للصينية ويفتح نظام الحوار الذي تم ضبطه. تتضمن الخطوات المحددة لهذا المشروع ما يلي: 2. ما قبل التدريب ، على قائمة الكلمات الجديدة ، تم تدريب حوالي 20 جرام من المجموعة الصينية العامة ، واستخدمت تقنية Lora في التدريب ؛ 3. باستخدام Stanford Alpaca ، تم تنفيذ التدريب على صياغة 51K بيانات 51K للحصول على قدرة الحوار.
العنوان المفتوح المصدر هو: https://github.com/ymcui/Chinese-llama-alpaca
في 12 أبريل ، أصدرت Databricks Dolly 2.0 ، المعروفة باسم أول مصدر مفتوح في الصناعة ، LLM المتوافق مع التوجيه. تم إنشاء مجموعة البيانات من قبل موظفي DataBricks وكانت مفتوحة من مصادر ومتاحة للأغراض التجارية. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
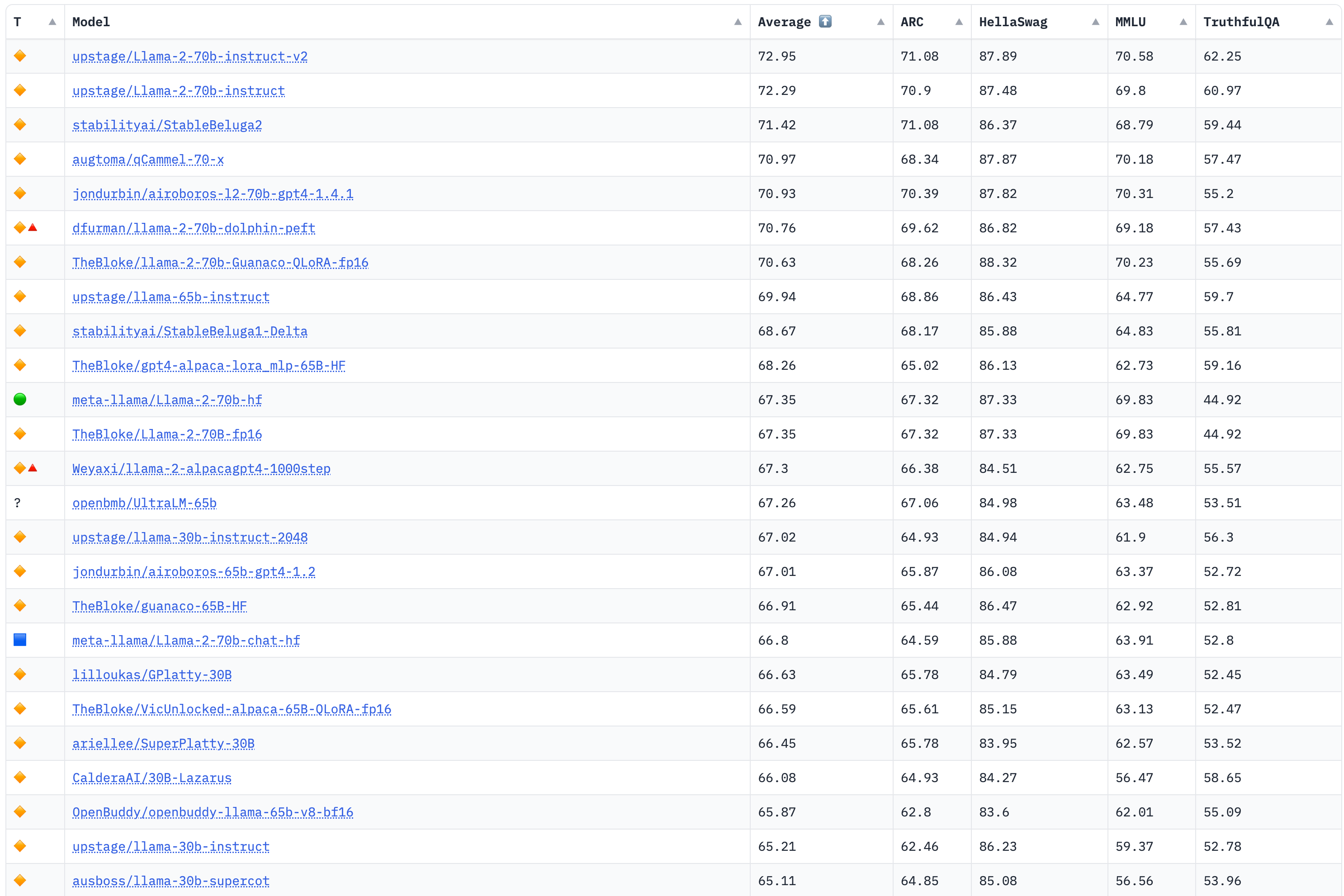
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
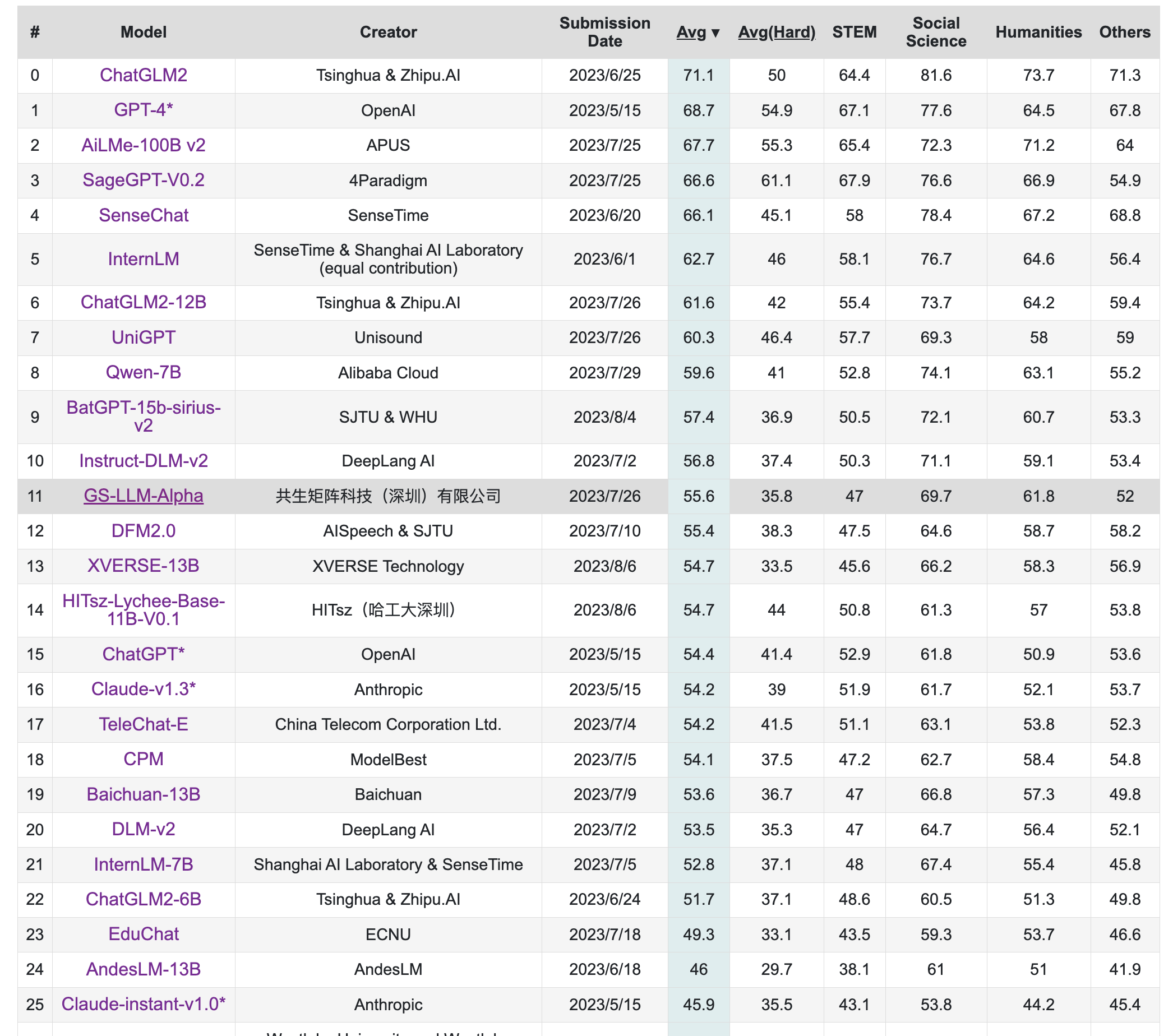
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

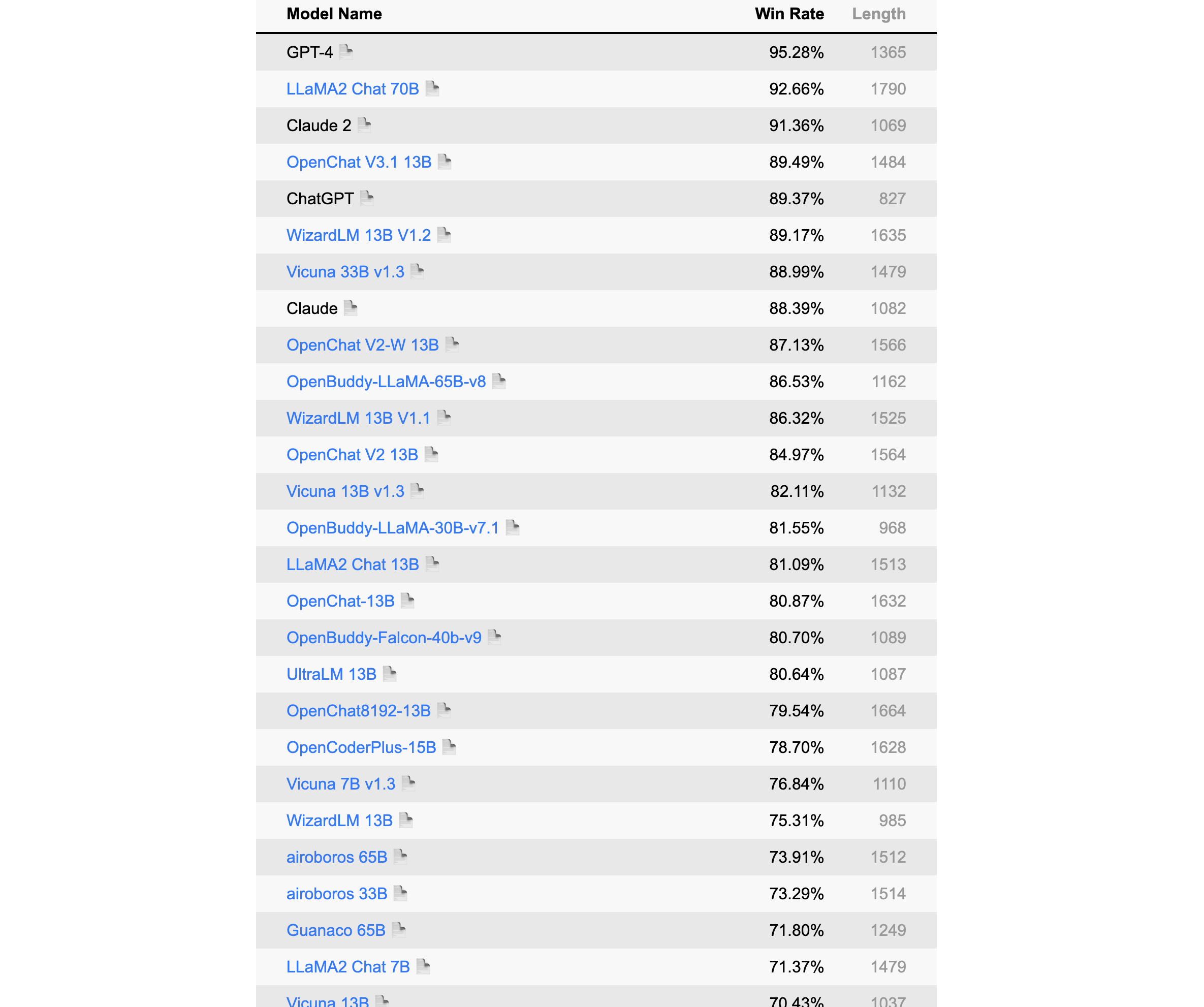
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


