FindTheChatGPTer
1.0.0
CHATGPT/GPT4 Open Source "Plain Ersatz" Zusammenfassung, kontinuierliches Update
Chatgpt ist populär geworden, und viele inländische Universitäten, Forschungsinstitutionen und Unternehmen haben Veröffentlichungspläne ähnlich wie ChatGPT herausgegeben. Chatgpt ist keine Open Source und es ist äußerst schwierig zu reproduzieren. Auch jetzt hat kein Gerät oder Unternehmen die vollständigen Fähigkeiten von GPT3 reproduziert. Im Moment kündigte OpenAI offiziell die Veröffentlichung des GPT4 -Modells mit multimodalen Grafiken und Text an, und seine Fähigkeiten wurden im Vergleich zu ChatGPT erheblich verbessert. Es scheint, dass es die vierte industrielle Revolution riecht, die von allgemeinen künstlichen Intelligenz dominiert wird.
Ob im Ausland oder zu Hause, die Lücke zwischen OpenAI wird immer größer und jeder holt in einer gewissen vorteilhafte Position in dieser technologischen Innovation in einer gewissen vorteilhaften Position auf. Gegenwärtig nimmt die Forschung und Entwicklung vieler großer Unternehmen im Grunde genommen die Closed-Source-Route ein. Es gibt nur wenige Details, die offiziell von ChatGPT und GPT4 veröffentlicht wurden, und es ist nicht wie in der vorherigen Einführung in Papier, in der Dutzende von Seiten eingeführt wurden. Die Ära der Kommerzialisierung von OpenAI ist eingetroffen. Natürlich haben einige Organisationen oder Einzelpersonen Open Source -Ersatz untersucht. Dieser Artikel ist wie folgt zusammengefasst. Ich werde sie weiterhin verfolgen. Es gibt aktualisierte Open -Source -Ersetzungen, um diesen Ort rechtzeitig zu aktualisieren.
Diese Art von Methode verwendet hauptsächlich Nicht-LLLAMA- und andere Feinabstimmungsmethoden, um GPT- und T5-Modelle unabhängig zu entwerfen oder zu optimieren, und realisiert Prozesse in vollem Zyklus wie Vorausbildung, überwachtes Feinabstimmung und Verstärkungslernen.
Chatyuan (Yuanyu AI) wird vom Yuanyu Intelligent Development Team entwickelt und veröffentlicht. Es behauptet, das erste funktionale Dialogmodell in China zu sein. Es kann Artikel schreiben, Hausaufgaben machen, Gedichte schreiben und Chinesisch und Englisch übersetzen. Einige spezifische Bereiche wie Gesetze können auch relevante Informationen liefern. Dieses Modell unterstützt derzeit nur Chinesen, und der GitHub -Link lautet:
https://github.com/clue-ai/chatyuan
Nach den offengelegten technischen Details nimmt die zugrunde liegende Ebene ein T5-Modell mit einer Skala von 700 Millionen Parametern an und beaufsichtigt und feine Tunes basierend auf promptClue zur Bildung von Chatyuan. Dieses Modell ist im Grunde der erste Schritt des dreistufigen Chatgpt-technischen Weges, und es werden keine Belohnungsmodellschulungen und PPO-Verstärkungslernen implementiert.
Kürzlich kolossalai open Source ihre Chatgpt -Implementierung. Teilen Sie ihre dreistufige Strategie und implementieren Sie die technische Route von Chatgpt Core vollständig: Der GitHub lautet wie folgt:
https://github.com/hpcaitech/colossalai
Basierend auf diesem Projekt habe ich die dreistufige Strategie geklärt und sie geteilt:
Die erste Stufe (Stufe1_Sft.py): Die Fine-Tuning-Stufe der SFT-Überwachung wurde nicht implementiert. Dies ist relativ einfach, da kolosssaliai das Umarmungsfeld nahtlos unterstützt. Ich verwende direkt ein paar Zeilen von Code of Huggingface -Trainerfunktion, um sie einfach zu implementieren. Hier habe ich ein GPT2 -Modell verwendet. Aus Sicht der Implementierung unterstützt es GPT2-, OPT- und Bloom -Modelle.
Die zweite Stufe (Stufe2_Rm.py): Das Trainingsstadium des Belohnungsmodells (RM), dh das Training_reward_Model.py Teil in den Projektbeispielen;
Die dritte Stufe (Stufe3_ppo.py): Stufe für Verstärkungslernen (RLHF), dh Project Train_prompts.py
Die Ausführung der drei Dateien muss im kolossalen Projekt platziert werden, bei dem die Kerne im Code im ursprünglichen Projekt Chatgpt sind, und Cores. Nn wird im Originalprojekt Chatgpt.models.
Chatglm ist ein Dialogmodell der GLM -Reihe von Zhipu AI, einem Unternehmen, das die technischen Leistungen in Tsinghua verändert, chinesische und englische Sprachen unterstützt und derzeit sein 6,2 -Milliarden -Parametermodell hat. Es erbt die Vorteile von GLM und optimiert die Modellarchitektur, wodurch der Schwellenwert für die Bereitstellung und Anwendung verringert wird und die Inferenzanwendung großer Modelle auf Verbrauchergrafikkarten realisiert. Ausführliche Techniken finden Sie in seinem GitHub:
Die Open-Source-Adresse von Chatglm-6b lautet: https://github.com/thudm/chatglm-6b
Aus technischer Sicht wurde ChatGPT gestärkt, das das Lernen der Strategie der menschlichen Ausrichtung verstärkt und den Erzeugungseffekt am menschlichen Wert besser und näher macht. Zu den aktuellen Fähigkeitsbereichen gehören hauptsächlich Selbstkognition, Umrissschreiben, Texter, E-Mail-Schreibassistent, Informationsextraktion, Rollenspiele, Kommentarvergleich, Reiseberatung usw. Es hat ein 130-Milliarden-Super-großer-Modell unter internem Test entwickelt, das als Dialogmodell mit einer größeren Parameterskala im aktuellen Open-Quell-Ersatz angesehen wird.
Visualglm-6b (aktualisiert am 19. Mai 2023)
Das Team hat kürzlich die multimodale Version von Chatglm-6b eröffnet, die den multimodalen Dialog in Bildern, Chinesisch und Englisch unterstützt. Das Sprachmodellteil verwendet Chatglm-6b, und der Bildteil erstellt eine Brücke zwischen dem visuellen Modell und dem Sprachmodell durch Training bLip2-Qformer. Das Gesamtmodell hat insgesamt 7,8 Milliarden Parameter. Visualglm-6b stützt sich auf 30 m hochwertige chinesische Grafikpaare aus dem CogView-Datensatz und wird mit 300 m gefilterten englischen Grafikpaaren mit dem gleichen Gewicht in Chinesisch und Englisch vorgebracht. Diese Trainingsmethode richtet visuelle Informationen besser in den semantischen Raum von Chatglm aus. In der nachfolgenden Feinabstimmung wird das Modell nach langen visuellen Fragen und Antworten geschult, um Antworten zu generieren, die die menschlichen Vorlieben entsprechen.
Visualglm-6b Open Source-Adresse lautet: https://github.com/thudm/visualglm-6b
CHATGLM2-6B (aktualisiert am 27. Juni 2023)
Das Team hat kürzlich die Version Chatglm2-6b von Chatglm in der zweiten Generation eröffnet. Im Vergleich zur Version der ersten Generation umfassen die Hauptmerkmale die Verwendung einer größeren Datenskala von 1T bis 1,4T. Am prominentesten ist der längere Kontextunterstützung, der sich von 2K auf 32 km erweitert hat und längere und höhere Eingabetouren ermöglicht. Darüber hinaus wurde die Inferenzgeschwindigkeit erheblich optimiert, ein Anstieg von 42%und die belegten Videospeicherressourcen wurden stark reduziert.
Chatglm2-6b Open Source-Adresse lautet: https://github.com/thudm/chatglm2-6b
Es ist als erstes Open -Source -Chatgpt -Ersatzprojekt bekannt, und seine grundlegende Idee basiert auf der Google Language Big Model Palm Architektur und der Verwendung von Verstärkungslernmethoden (RLHF) aus menschlichem Feedback. Palm ist ein 540-Milliarden-Parameter-Allround-Modell, das von Google im April dieses Jahres veröffentlicht wurde, basierend auf dem Pathways-Systemtraining. Es kann Aufgaben wie das Schreiben von Code, Chat, Sprachverständnis usw. erledigen und bei den meisten Aufgaben eine leistungsstarke Lernleistung mit niedriger Probe haben. Gleichzeitig wird der Chatgpt-ähnliche Verstärkungslernenmechanismus übernommen, wodurch die Antworten von AI mehr den Szenarioanforderungen entsprechen und die Modelltoxizität reduzieren können.
Github-Adresse lautet: https://github.com/lucidrains/palm-rlhf-pytorch
Das Projekt ist als das größte Open -Source -Modell mit bis zu 1,5 Billion bekannt und ist ein multimodales Modell. Zu seinen Fähigkeitsdomänen gehören natürliches Sprachverständnis, maschinelle Übersetzung, intelligente Frage und Antwort, Stimmungsanalyse und grafische Übereinstimmung usw. Die Open -Source -Adresse lautet:
https://huggingface.co/banana-dev/gptrillion
(Am 24. Mai 2023 ist dieses Projekt ein Witzprogramm für Aprilscherze. Das Projekt wurde gelöscht. Ich werde es hiermit erklären
OpenFlamingo ist ein Rahmen, der GPT-4 Benchmarks und die Schulung und Bewertung großer multimodaler Modelle unterstützt. Es wurde von gemeinnützigem Laion veröffentlicht und ist eine Reproduktion des Flamingo-Modells von DeepMind. Derzeit ist Open Source das Lama-basierte OpenFlamingo-9b-Modell. Das Flamingo-Modell wird auf einem groß angelegten Netzwerkkorpus miteinander ausgebildet, das zusammengelassene Text und Bilder enthält, und kann kontextbeschränkte Proben lernen. OpenFlamingo implementiert die gleiche Architektur, die im ursprünglichen Flamingo vorgeschlagen wurde und auf 5m Proben aus einem neuen multimodalen C4-Datensatz und 10m Proben aus Laion-2b trainiert wurde. Die Open -Source -Adresse dieses Projekts lautet:
https://github.com/mlfoundations/open_flamingo
Am 21. Februar dieses Jahres veröffentlichte die Fudan University Moss und eröffnete die öffentliche Beta, was nach dem Zusammenbruch der öffentlichen Beta zu Kontroversen führte. Jetzt hat das Projekt wichtige Updates und Open Source eingeleitet. Das Open-Source-Moss unterstützt sowohl chinesische als auch englische Sprachen und unterstützt die Plug-Inization, wie das Lösen von Gleichungen, die Suche usw. Die Parameter sind 16B und in etwa 700 Milliarden chinesischen und englischen und Code-Wörtern ausgebildet. Die nachfolgenden Dialoganweisungen sind fein abgestimmte, Plug-in Enhanced Learning und Human Preference Training verfügen über mehrere Runden von Dialogfunktionen und die Möglichkeit, mehrere Plug-Ins zu verwenden. Die Open -Source -Adresse dieses Projekts lautet:
https://github.com/openlmlab/moss
Ähnlich wie bei Minigpt-4 und Llava handelt es sich um ein multimodales Open-Source-Modell mit Benchmarking GPT-4, das die modulare Trainingsidee der Mplug-Serie fortsetzt. Derzeit öffnet es das 7B-Parametermengenmodell und schlägt gleichzeitig zum ersten Mal einen umfassenden Testsatz Owleval für das Verständnis für visuell bezogene Anweisungen vor. Durch die manuelle Bewertung zeigen vorhandene Modelle, einschließlich LLAVA, Minigpt-4 und anderer Arbeiten, bessere multimodale Funktionen, insbesondere bei multimodalen Anweisungsverständnisfähigkeiten, Multi-Runden-Dialogfähigkeit, Fähigkeit zur Wissensbekämpfung usw. Es ist bedauerlich, dass wie andere Grafik- und Textmodelle immer noch Englisch unterstützt, aber die chinesische Version ist bereits in seiner offenen Quellliste.
Die Open-Source-Adresse dieses Projekts lautet: https://github.com/x-plug/mplug-wl
Pandalm ist ein Modellbewertungsmodell, das darauf abzielt, die Vorlieben anderer groß angelegter Modelle automatisch zu bewerten, um Inhalte zu generieren und manuelle Bewertungskosten zu sparen. Pandalm verfügt über eine Weboberfläche für die Analyse und unterstützt auch Python -Code -Anrufe. Es kann Text und Daten mit nur drei Codezeilen bewerten, die sehr bequem zu verwenden sind.
Die Open -Source -Adresse des Projekts lautet: https://github.com/weopenml/pandalm
Auf der kürzlich stattfindenden Zhiyuan -Konferenz eröffnete das Zhiyuan Research Institute die Quelle seines Modells zur Aufklärung und seines Sky Eagle, das zweisprachige Kenntnisse Chinesen und Englisch gibt. Die Grundmodellparameter der Open -Source -Version umfassen 7 Milliarden und 33 Milliarden. Gleichzeitig öffnet es das Modell des Aquilachat-Dialogmodells und des Quilacode-Textcode-Generierungsmodells und beide wurden für kommerzielle Lizenzen geöffnet. Aquila übernimmt nur Decoder-Architekturen wie GPT-3 und LLAMA und aktualisiert auch das Wortschatz für chinesische und englische Zweisprachigkeit und übernimmt seine beschleunigte Trainingsmethode. Die Leistungsgarantie hängt nicht nur von der Optimierung und Verbesserung des Modells ab, sondern profitiert auch von Zhiyuans Akkumulation hochwertiger Daten zu großen Modellen in den letzten Jahren.
Die Open-Source-Adresse des Projekts lautet: https://github.com/flagai-open/flagai/tree/master/examples/aquila
Kürzlich hat Microsoft ein multimodales großes Modellpapier und Open-Source-Code-Codi veröffentlicht, das die Text-Voice-Image-Video vollständig verbindet und beliebige Eingabe- und beliebige Modalausgaben unterstützt. Um die Erzeugung willkürlicher Modalitäten zu erreichen, unterteilten die Forscher das Training in zwei Phasen. In der ersten Stufe verwendete der Autor die Strategie der Brückenausrichtung und die kombinierten Bedingungen, um zu trainieren, wodurch ein potenzielles Diffusionsmodell für jeden Modus geschaffen wurde. In der zweiten Stufe wurde jedem potenziellen Diffusionsmodell und Umweltcodierer ein Aufmerksamkeitsmodul für Schnittstellen hinzugefügt, das die latenten Variablen des potenziellen Diffusionsmodells in den gemeinsamen Raum projizieren konnte, so dass die generierten Modalitäten weiter diversifiziert wurden.
Die Open-Source-Adresse dieses Projekts lautet: https://github.com/microsoft/i-code/tree/main/i-code-v3
META hat seine multimodale Big Model Imagebind gestartet und geöffnet, mit der 6 Modalitäten wie Bild, Video, Audio, Tiefe, Wärme und räumliche Bewegung gekreuzt werden können. ImageBind löst das Ausrichtungsproblem mithilfe der Bindungseigenschaften von Bildern, indem große visuelle Sprachmodelle und Funktionen der Null-Stichprobe auf neue Modalitäten erweitert werden. Bildpaarungsdaten sind ausreichend, um diese sechs Modi miteinander zu binden, sodass unterschiedliche Modi modale Spaltungen voneinander öffnen können.
Die Open -Source -Adresse des Projekts lautet: https://github.com/facebookresearch/imageBind
Am 10. April 2023 kündigte Wang Xiaochuan offiziell die Gründung der AI Big Model Company "Baichuan Intelligence" an, um eine chinesische Version von OpenAI zu erstellen. Zwei Monate nach seiner Gründung hat Baichuan Intelligent eine wichtige Quelle seines unabhängig entwickelten Baichuan-7b-Modells erstellt, das Chinesisch und Englisch unterstützt. Baichuan-7b übertrifft nicht nur andere große Modelle wie Chatglm-6b mit erheblichen Vorteilen für die Liste C-Eval, Ageval und Gaokao Chinese Autoritative Evaluation, sondern führt auch die LLAMA-7B in der MMLU English English Authoritative Evaluation List. Dieses Modell erreicht eine Billionen-Token-Skala für qualitativ hochwertige Daten und unterstützt die Expansionsfähigkeit von Zehntausenden von ultralangen dynamischen Fenstern, die auf einer effizienten Optimierung des Operators der Aufmerksamkeit basieren. Derzeit unterstützt Open Source 4K -Kontextfunktionen. Dieses Open -Source -Modell ist im Handel erhältlich und freundlicher als Lama.
Die Open-Source-Adresse des Projekts lautet: https://github.com/baichuan-inc/baichuan-7b
Am 6. August 2023 eröffnete das Yuanxiang Xverse-Team das Xverse-13B-Modell. Dieses Modell ist ein mehrsprachiges großes Modell, das bis zu mehr als 40 Sprachen unterstützt und die kontextbezogene Länge von bis zu 8192 unterstützt. Nach dem Team sind die Merkmale dieses Modells: Modellstruktur: Xverse-13b verwendet den Mainstream-Decoder-Standard-Standard-Transformatorstruktur, unterstützt 8K-Kontextlänge. Trainingsdaten: 1,4 Billionen Token hochwertiger und vielfältiger Daten werden entwickelt, um das Modell vollständig auszubilden, darunter 40 chinesische, Englisch, Russisch und Western. Mehrere Sprachen, indem das Stichprobenverhältnis verschiedener Datenarten fein festgelegt wird, funktionieren die chinesischen und englischen Sprachen gut und können auch die Auswirkungen anderer Sprachen berücksichtigen. Wortsegmentierung: Basierend auf dem BPE -Algorithmus wurde eine Wortsegmentierung mit einer Vokabulargröße von 100.278 mit Hunderten von GB -Korpus geschult, die mehrere Sprachen gleichzeitig ohne zusätzliche Ausdehnung der Wortliste unterstützen kann. Schulungsrahmen: Es wurde unabhängig voneinander eine Reihe von Schlüsseltechnologien entwickelt, darunter effiziente Operatoren, Videospeicheroptimierung, parallele Planungsstrategien, Überlappung der Datenverbindung, die Zusammenarbeit von Plattform und Framework usw., wodurch die Schulungseffizienz höher und die Modellstabilität stark ist. Die Peak -Rateing -Leistungsnutzungsrate am Kilocard -Cluster kann 58,5%erreichen, was in der Branche unter dem Vordergrund steht.
Die Open-Source-Adresse dieses Projekts lautet: https://github.com/xverse-ai/xverse-13b
Am 3. August 2023 war das 7 -Milliarden -Modell von Alibaba Tongyi Qianwen Open Source, einschließlich allgemeiner Modelle und Dialogmodelle, und ist Open Source, kostenlos und kommerziell erhältlich. Berichten zufolge ist QWEN-7B ein großes Sprachmodell, das auf Transformator basiert und nach Daten vor dem Training ausgebildet wird. Die Datentypen vor dem Training sind vielfältig und decken eine breite Palette von Bereichen ab, darunter eine große Anzahl von Online-Texten, professionellen Büchern, Codes usw. Es ist ein Dock-Modell, das chinesische und englische Sprachen unterstützt, die auf mehr als 2 Billionen Token-Datensätzen trainiert werden, und die Kontextfensterlänge erreicht 8K. QWEN-7B-CHAT ist ein chinesisch-englisches Dialogmodell, das auf dem QWEN-7B-Sockelmodell basiert. Das Tongyi Qianwen 7B-Vorgebildete machte in mehreren maßgeblichen Benchmark-Bewertungen gut ab. Die chinesischen und englischen Fähigkeiten übertreffen die Open -Source -Modelle derselben Skala im In- und Ausland weit, und einige Funktionen überschritten sogar die Open -Source -Modelle von 12B- und 13B -Größen.
Die Open-Source-Adresse des Projekts lautet: https://github.com/qwenlm/qwen-7b
LLAMA ist ein brandneues, großes Sprachmodell für künstliche Intelligenz, das von Meta veröffentlicht wurde, das bei Aufgaben wie Erzeugung von Text, Dialog, Zusammenfassung schriftlicher Materialien, der Beweisung mathematischer Theoreme oder der Vorhersage von Proteinstrukturen eine gute Leistung erbringt. Das LLAMA -Modell unterstützt 20 Sprachen, darunter lateinische und kyrillische alphabetische Sprachen. Derzeit unterstützt das ursprüngliche Modell Chinesisch nicht. Es kann gesagt werden, dass das epische Leck von Lama die Open-Source-Entwicklung von Chatgpt-ähnlich fördert.
(Aktualisiert am 22. April 2023) Aber leider ist die Genehmigung von Llama derzeit begrenzt und kann nur für die wissenschaftliche Forschung verwendet werden und ist für den kommerziellen Gebrauch nicht zulässig. Um das kommerzielle Problem mit vollständigem Open -Source -Problem zu lösen, wurde das Redpajama -Projekt entstanden und zielte darauf ab, eine vollständig Open -Source -Replik von Lama zu erstellen, die für kommerzielle Anwendungen verwendet werden kann und einen transparenterer Prozess für die Forschung bereitstellt. Das komplette Redpajama enthält einen 1,2-Billion-Token-Datensatz, und der nächste Schritt wird darin bestehen, ein großflächiges Training zu beginnen. Diese Arbeit ist es immer noch wert, sich darauf zu freuen, und seine Open -Source -Adresse lautet:
https://github.com/togethercomputer/redpajama-data
(Aktualisiert am 7. Mai 2023)
Redpajama hat seine Trainingsmodelldatei aktualisiert, darunter zwei Parameter: 3B und 7B, wobei 3B auf der vor 5 Jahren veröffentlichten RTX2070 -Gaming -Grafikkarte ausgeführt werden kann, was die Lücke in Lama auf 3B ausgeht. Die Modelladresse lautet:
https://huggingface.co/TogetherComputer
Zusätzlich zu Redpajama hat Mosaicml das Modell der MPT -Serie auf den Markt gebracht, und seine Trainingsdaten verwenden Redpajama -Daten. In verschiedenen Leistungsbewertungen ist das 7B -Modell mit dem ursprünglichen Lama vergleichbar. Die Open -Source -Adresse seines Modells lautet:
https://huggingface.co/mosaicml
Egal, ob es sich um Redpajama oder MPT handelt, es ist auch das entsprechende Chat -Versionsmodell. Die Open Source dieser beiden Modelle hat die Kommerzialisierung von Chatgpt-ähnlich stark gesteigert.
(Aktualisiert am 1. Juni 2023)
Falcon ist eine offene große Modellbasis, die Lama vergleicht. Es hat zwei Parametermessskalen: 7b und 40b. Die Leistung von 40b ist als Ultra-High 65B Lama bekannt. Es wird davon ausgegangen, dass Falcon immer noch das autoregressive Decoder -Modell der GPT verwendet, aber es hat viel Aufwand in die Daten gesteckt. Nach dem Abkratzen von Inhalten aus dem öffentlichen Netzwerk und dem Aufbau des anfänglichen vorbereiteten Datensatzes verwendet es Commoncrawl-Dump, um eine groß angelegte Filterung und groß angelegte Deduplizierung durchzuführen, und erhält schließlich einen riesigen, vorbereiteten Datensatz, der aus fast 5 Billionen Token besteht. Gleichzeitig wurden viele ausgewählte Korpussen hinzugefügt, einschließlich Forschungsarbeiten und Social -Media -Gesprächen. Die Genehmigung des Projekts war jedoch umstritten, und die "halbkommerzielle" Autorisierungsmethode wird jedoch angewendet, und 10% der kommerziellen Ausgaben werden beginnen, nachdem das Einkommen 1 Million erreicht hat.
Die Open -Source -Adresse des Projekts lautet: https://huggingface.co/tiiuae
(Aktualisiert am 3. Juli 2023)
Dem ursprünglichen Falcon fehlen die chinesischen Unterstützungsfähigkeiten wie Lama. Das "Linly" -Projektteam baute und eröffnete die chinesische Version von Chinese-Falcon basierend auf dem Falcon-Modell. Das Modell erweiterte und erweiterte die Wortschatzliste, einschließlich 8701 häufig verwendete chinesische Charaktere, die ersten 20.000 chinesischen Hochfrequenzwörter in der Jieba-Vokabularliste und 60 chinesische Interpunktionsmarken. Nach der Deduplizierung wurde die Größe der Wortschatzliste auf 90.046 erweitert. Während der Trainingsphase wurden für das Training 50G-Korpus- und 2T-groß angelegte Daten verwendet.
Die Open-Source-Adresse des Projekts lautet: https://github.com/cvi-szu/linly
(Aktualisiert am 24. Juli 2023)
Dem ursprünglichen Falcon fehlen die chinesischen Unterstützungsfähigkeiten wie Lama. Das "Linly" -Projektteam baute und eröffnete die chinesische Version von Chinese-Falcon basierend auf dem Falcon-Modell. Das Modell erweiterte und erweiterte die Wortschatzliste, einschließlich 8701 häufig verwendete chinesische Charaktere, die ersten 20.000 chinesischen Hochfrequenzwörter in der Jieba-Vokabularliste und 60 chinesische Interpunktionsmarken. Nach der Deduplizierung wurde die Größe der Wortschatzliste auf 90.046 erweitert. Während der Trainingsphase wurden für das Training 50G-Korpus- und 2T-groß angelegte Daten verwendet.
Die Open-Source-Adresse des Projekts lautet: https://github.com/cvi-szu/linly
Das von Stanford veröffentlichte Alpaka (Alpaca-Modell) ist ein neues Modell, das auf dem LLAMA-7B-Modell basiert. Das Grundprinzip besteht darin, das Text-Davinci-003-Modell von OpenAI 52K-Anweisungen auf selbstverstärkende Weise zu generieren, um Lama zu finanzieren. Das Projekt hat Quell -Schulungsdaten, Code zum Generieren von Trainingsdaten und Hyperparametern eröffnet. Die Modelldatei wurde noch nicht geöffnet und erreichte an einem Tag mehr als 5,6.000 Sterne. Diese Arbeit ist aufgrund ihrer kostengünstigen und einfachen Datenzugang sehr beliebt und hat auch den Weg zur Nachahmung von kostengünstigem Chatgpt geöffnet. Die Github -Adresse lautet:
https://github.com/tatsu-lab/stanford_alpaca
Es handelt sich um eine Open -Source -Implementierung des LLAMA+AI -Chatbots basierend auf dem von Nebuly+AI gestarteten Lernen für die Verstärkung des menschlichen Feedbacks. Die technische Route ähnelt Chatgpt. Das Projekt wurde gerade für 2 Tage gestartet und hat 5,2.000 Stars gewonnen. Die Github -Adresse lautet:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
Der Chatllama -Trainingsprozessalgorithmus wird hauptsächlich verwendet, um ein schnelleres und billigeres Training zu erreichen als Chatgpt. Es soll fast 15 -mal schneller sein. Die Hauptmerkmale sind:
Eine vollständige Open-Source-Implementierung ermöglicht es Benutzern, Dienste im ChatGPT-Stil basierend auf vorgeborenen Lama-Modellen zu erstellen.
Die Lama -Architektur ist kleiner, wodurch der Trainingsprozess und die Argumentation schneller und kostspieliger wird.
Integrierte Unterstützung für DeepSpeed Zero, um den Feinabstimmungsprozess zu beschleunigen;
Unterstützt LLAMA-Modellarchitekturen verschiedener Größen, und Benutzer können das Modell nach ihren eigenen Vorlieben optimieren.
OpenChatkit wurde gemeinsam vom gemeinsamen Team erstellt, in dem sich ehemalige OpenAI -Forscher sowie die Laion- und Ontocord.ai -Teams befinden. OpenChatkit enthält 20 Milliarden Parameter und ist mit der Open-Source-Version von GPT-3 GPT-NOX-20B abgestimmt. Gleichzeitig verwendet OpenChatkit ein unterschiedliches Verstärkungslernen von Chatgpts und verwendet ein 6 -Milliarden -Parameterprüfungsmodell, um unangemessene oder schädliche Informationen zu filtern, um die Sicherheit und Qualität des generierten Inhalts sicherzustellen. Die Github -Adresse lautet:
https://github.com/togethercomputer/openchatkit
Basierend auf Stanford Alpaca wird die beaufsichtigte Feinabstimmung auf der Grundlage von Bloom und Lama realisiert. Die Samenaufgaben von Stanford Alpaca sind alle in englischer Sprache und die gesammelten Daten sind auch in englischer Sprache. Dieses Open -Source -Projekt soll die Entwicklung des chinesischen Dialogs Big Model Open -Source -Community fördern. Es wurde für Chinesen optimiert. Die Modellabstimmung verwendet nur Daten, die von CHATGPT erstellt wurden (ohne andere Daten). Das Projekt enthält Folgendes:
175 chinesische Saatgutmissionen
Code zum Generieren von Daten
Die von 10 m generierten Daten sind derzeit offen mit 1,5 m, 0,25 m mathematischen Anweisungsdatensätzen und 0,8 m Multi-Runden-Aufgabendialogdatensätzen.
Modell optimiert basierend auf Bloomz-7b1-MT und Lama-7b
Github -Adresse lautet: https://github.com/lianjiatech/belle
Alpaca-Lora ist ein weiteres Meisterwerk der Stanford University. Es verwendet die LORA-Technologie (Low-Rank Adaptation), um die Ergebnisse von Alpaka unter Verwendung einer kostengünstigeren Methode zu reproduzieren, und nur 5 Stunden lang auf einer RTX 4090-Grafikkarte trainiert, um ein Modell mit einem Alpaka-Level zu erhalten. Darüber hinaus kann das Modell auf einem Himbeer -Pi ausgeführt werden. In diesem Projekt verwendet es Peft von Sugging Face für billige und effiziente Feinabstimmungen. PEFT ist eine Bibliothek (LORA ist eine ihrer unterstützten Technologien), mit der Sie eine Vielzahl von transformatorbasierten Sprachmodellen verwenden und mit LORA optimieren können, um eine kostengünstige und effiziente Feinabstimmung des Modells auf allgemeine Hardware zu erhalten. Die Github -Adresse dieses Projekts lautet:
https://github.com/tloen/alpaca-lora
Obwohl Alpaka und Alpaka-Lora große Fortschritte erzielt haben, sind ihre Saatgutaufgaben sowohl in Englisch als auch keine Unterstützung für Chinesen. Einerseits, zusätzlich zu den oben genannten erwähnten, dass Belle eine große Menge chinesischer Korpus gesammelt hat, andererseits auf der Grundlage der Arbeit von Vorgängern wie Alpaka-Lora, dem chinesischen Sprachmodell Luotuo (Luotuo), der von drei einzelnen Entwicklern der Zentralchina-Normalen und anderer Institutionen offen gesammelt wurde, kann die Ausbildung abschließen. Derzeit veröffentlicht das Projekt zwei Modelle Luotuo-Lora-7b-0.1, Luotuo-Lora-7b-0,3, und ein Modell befindet sich im Plan. Die Github -Adresse lautet:
https://github.com/lc1332/chinese-alpaca-lora
Inspiriert von Alpaka verwendete Dolly den Alpaka-Datensatz, um eine Feinabstimmung von GPT-J-6B zu erreichen. Da Dolly selbst ein "Klon" eines Modells ist, beschloss das Team schließlich, es "Dolly" zu nennen. Inspiriert von Alpaka wird diese Klonierungsmethode immer beliebter. Zusammenfassend wird die Open-Source-Datenerfassungsmethode von Alpaca in etwa übernommen, und Feinabstiegsanweisungen zu alten Modellen mit 6b- oder 7b-Größe, um ChatGPT-ähnliche Effekte zu erzielen. Diese Idee ist sehr wirtschaftlich und kann den Charme von Chatgpt schnell imitieren. Es ist sehr beliebt und sobald es gestartet wurde, ist es voller Sterne. Die Github -Adresse dieses Projekts lautet:
https://github.com/databrickslabs/dolly
Nach dem Start von Alpaka haben sich Stanford Scholars mit CMU, UC Berkeley usw. zusammengetan, um ein neues Modell mit 13 Milliarden Parametern (allgemein als Alpaka und Lama bekannt) zu starten. Es kostet nur 300 US -Dollar, um eine 90% ige Leistung von ChatGPT zu erzielen. Vicuna wird verwendet, um Lama im von ShareGPT gesammelten Dialog mit dem von Nutzern abgestimmten Dialog zu optimieren. Der Testprozess verwendet GPT-4 als Bewertungskriterien. Die Ergebnisse zeigen, dass Vicuna-13b in mehr als 90% der Fälle Funktionen erreicht, die Chatgpt und Bard entsprechen.
UC Berkeley LMSYS Org hat kürzlich Vicuna mit 7 Milliarden Parametern veröffentlicht. Es ist nicht nur klein, hohe Effizienz und starke Fähigkeiten, sondern kann auch auf einem Mac mit M1/M2 -Chip in nur zwei Befehlslinien ausgeführt und können auch die GPU -Beschleunigung ermöglichen!
GitHub Open Source-Adresse lautet: https://github.com/lm-sys/fastchat/
Eine andere chinesische Version wurde von chinesischer Vicuna offen bezogen, wobei die Github-Adresse als:
https://github.com/facico/chinese-vicuna
Nachdem Chatgpt populär geworden war, suchten die Leute nach einem schnellen Weg zum Tempel. Einige Chatgpt-ähnliche Auftritte erschienen zu erscheinen, insbesondere nach Chatgpt zu geringen Kosten zu einer beliebten Art und Weise. LMFLOW ist ein Produkt, das in diesem Nachfrage -Szenario geboren wurde und es ermöglicht, dass große Modelle auf normalen Grafikkarten wie 3090 verfeinert werden. Das Projekt wurde von der Universität und Technologiestatistik in Hongkong und dem Laborteam für maschinelles Lernen initiiert und verpflichtet sich, eine vollständig geöffnete große Modellforschung, die verschiedene Experimente unter Begrenzung der Maschinenressourcen zu erstellen, und die vorhandenen Datenanwendungsmethoden und die vorhandenen Datenverwendungsmethoden und die Voraussetzungsmethoden und die Datenanwendungsmethoden und die Verbrauchsanwendungsmethoden und die Verbrauchsanwendungsmethoden und die Datenanwendungsmethoden und das Verbesserung der Datenanwendungsmethoden und das Verbesserung der Datenanwendungsmethoden und das Verbesserung der Datenanwendungsmethoden und das Verbesserung der Datenanwendungsmethoden. Modelltrainingssystem, das effizienter ist als die vorherigen Methoden.
Mit diesem Projekt können auch begrenzte Rechenressourcen Benutzer personalisierte Schulungen für proprietäre Bereiche unterstützen. Zum Beispiel dauert LLAMA-7B, ein 3090, 5 Stunden, um das Training abzuschließen, was die Kosten erheblich senkt. Das Projekt eröffnet auch den Q & A-Service für Webseiten-Sofortlebnisse (lmflow.com). Die Entstehung und Open Source von LMFlow ermöglichen es normale Ressourcen, verschiedene Aufgaben wie Q & A, Kameradschaft, Schreiben, Übersetzung, Experten -Feldberatung usw. zu schulen. Viele Forscher versuchen derzeit, dieses Projekt zu verwenden, um große Modelle mit einem Parametervolumen von 65 Milliarden oder sogar höher zu schulen.
Die Github -Adresse dieses Projekts lautet:
https://github.com/optimalscale/lmflow
Das Projekt schlägt eine Methode vor, um automatisch ChatGPT-Gespräche zu sammeln, sodass Chatgpt sich selbst übertreffen kann. Batch erzeugt hochwertige Multi-Runden-Dialogdatensätze und sammeln etwa 50.000 Q & A-Korpus von Quora, Stackoverflow bzw. Medqa und waren alle offen. Gleichzeitig verbesserte es das Lama -Modell und der Effekt ist ziemlich gut. Bai Ze übernahm auch die aktuelle kostengünstige Lora-Feinabstimmungslösung, um drei verschiedene Skalen zu erhalten: BAI ZE-7B, 13B und 30B sowie ein Modell im vertikalen Bereich der medizinischen Versorgung. Leider ist der chinesische Name gut benannt, aber er unterstützt Chinesen immer noch nicht. Das chinesische Bai Ze -Modell steht Berichten zufolge im Plan und wird in Zukunft veröffentlicht. Die Open -Source -Github -Adresse lautet:
https://github.com/project-baize/baize
Der in LLAMA ansässige Chatgpt-Flat-Ersatz fermentiert weiter und fermentiert weiter. Berkeley von UC Berkeley hat ein Gesprächsmodell Koala veröffentlicht, das mit Parametern von 13b auf Verbraucher-GPUs betrieben werden kann. Der Trainingsdatensatz von Koala enthält die folgenden Teile: ChatGPT -Daten und Open Source -Daten (Open Instruction Generalist (OIG), Datensatz, verwendet vom Stanford Alpaca -Modell, Anthropic HH, OpenAI WebGPT, OpenAI -Zusammenfassung). Das Koala -Modell wird in EasyLM mit JAX/Flachs mit 8 A100 GPUs implementiert und dauert 6 Stunden, bis 2 Iterationen abgeschlossen sind. Der Evaluierungseffekt ist besser als Alpaka und erzielt eine 50% ige Leistung von ChatGPT.
Open Source-Adresse: https://github.com/young-geng/easylm
Mit dem Aufkommen von Stanford Alpaka begann eine große Anzahl von Alpaka-Familien in Lama ansässig und erweiterte Tierfamilien zu entstehen, und schließlich veröffentlichte die umarmten Gesichtsforscher kürzlich einen Blog Stackllama: ein praktischer Leitfaden zur Ausbildung von Lama mit RLHF. Gleichzeitig wurde auch ein 7 -Milliarden -Parametermodell - Stackllama, veröffentlicht. Dies ist ein Modell, das in LLAMA-7B durch menschliches Feedback-Verstärkungslernen fein abgestimmt ist. Weitere Informationen finden Sie in der Blog -Adresse:
https://huggingface.co/blog/stackllama
Das Projekt optimiert LLAMA für Chinesisch und eröffnet sein fein abgestimmtes Dialogsystem. Zu den spezifischen Schritten dieses Projekts gehören: 1. Erweitern Sie die Wortliste, indem Sie das Satzstück mit chinesischen Daten trainieren und konstruieren, und fusionierte mit der Lama -Wortliste; 2. Auf der neuen Wortliste wurden etwa 20 g des allgemeinen chinesischen Korpus geschult, und die Lora-Technologie wurde in der Ausbildung eingesetzt. 3. Mit Stanford Alpaka wurde ein Feinabstimmungstraining an 51K-Daten durchgeführt, um die Dialogfähigkeit zu erhalten.
Die Open-Source-Adresse lautet: https://github.com/ymcui/chinese-lama-alpaca
Am 12. April veröffentlichte Databricks Dolly 2.0, bekannt als die erste Open-Source-LLM-Richtlinie der Branche. Der Datensatz wurde von Databricks -Mitarbeitern generiert und für kommerzielle Zwecke offen und verfügbar. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
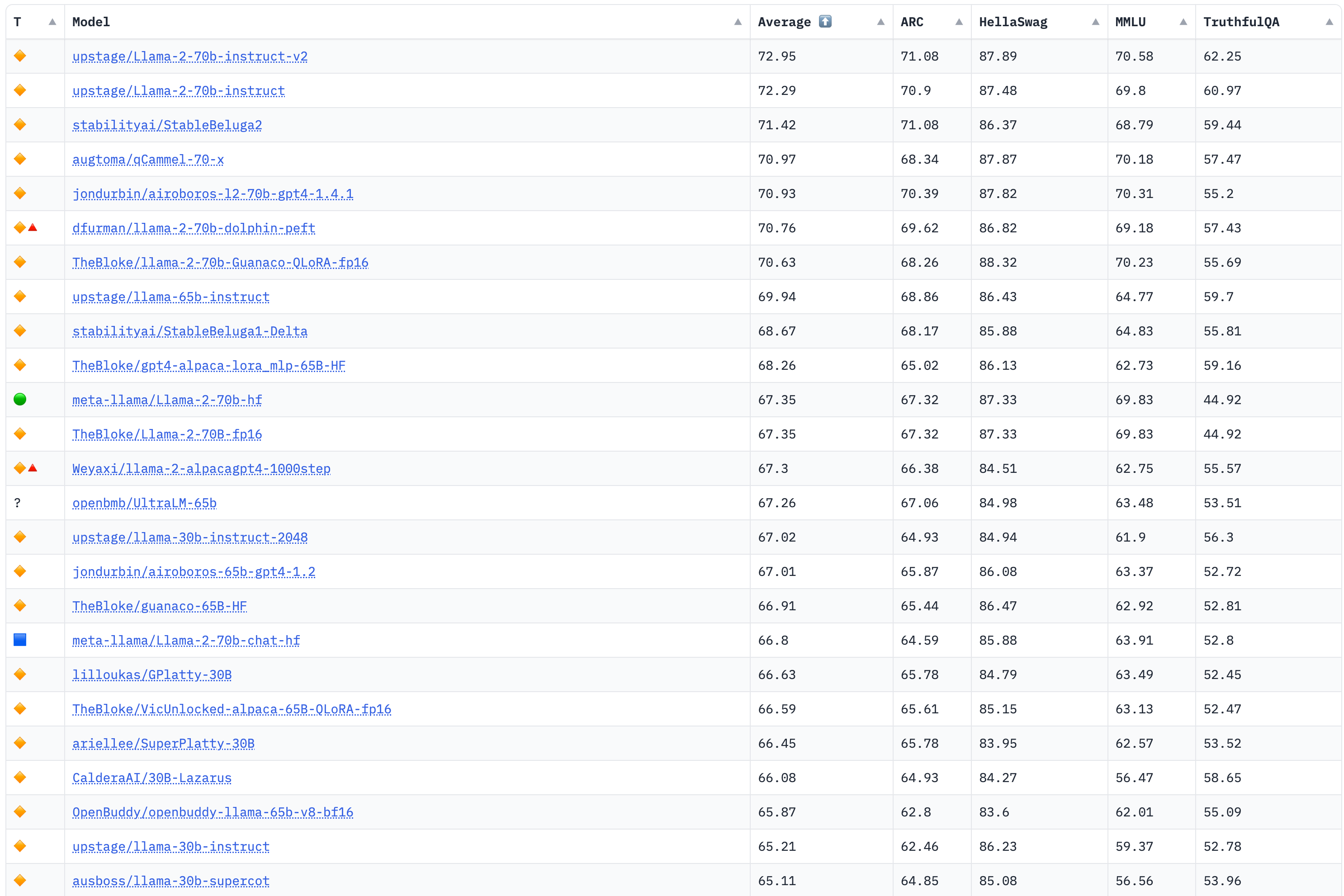
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
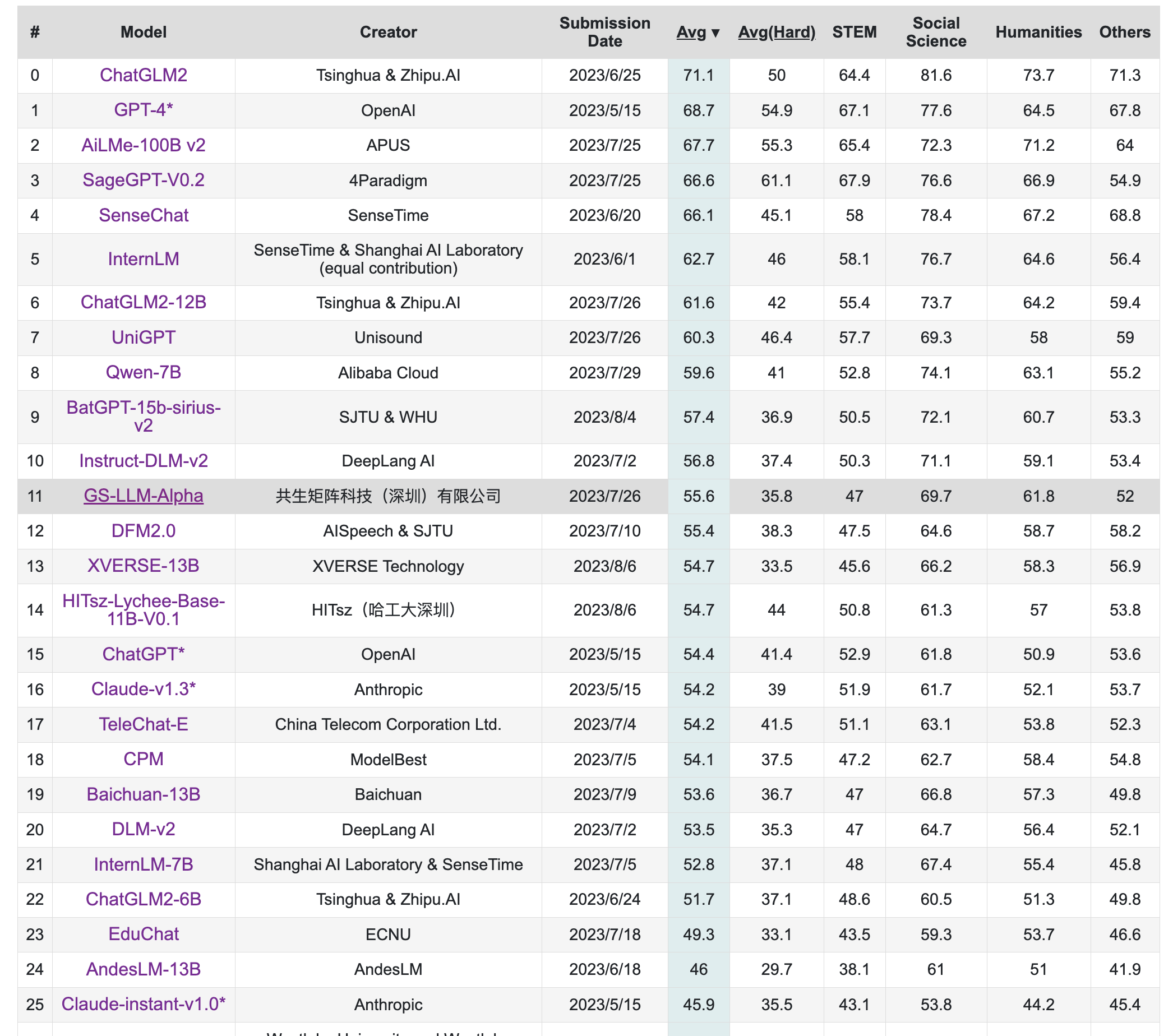
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

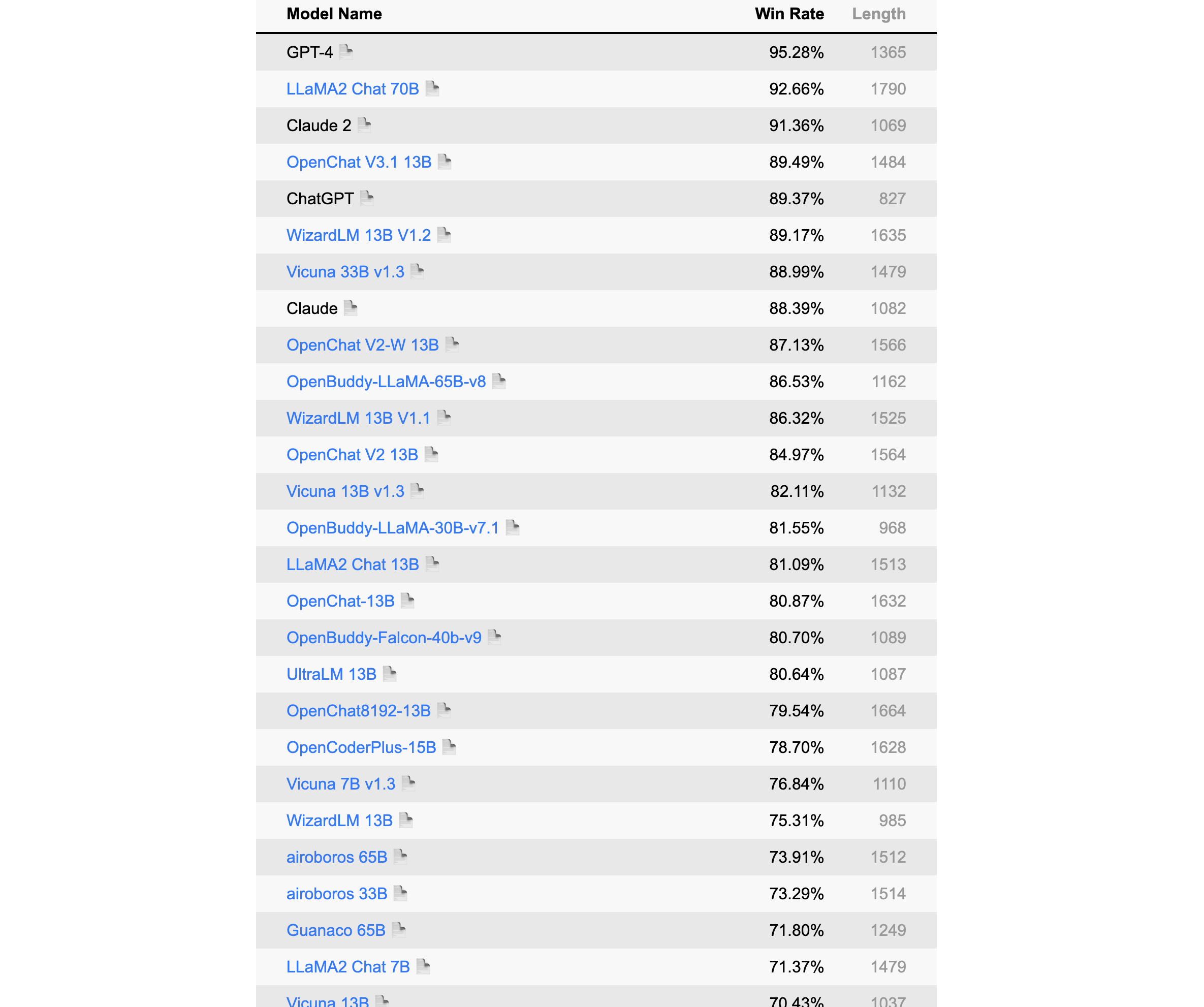
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


