FindTheChatGPTer
1.0.0
สรุป chatgpt/gpt4 โอเพ่นซอร์ส "การแทนที่แบบธรรมดา" การอัปเดตต่อเนื่อง
ChatGPT ได้รับความนิยมและมหาวิทยาลัยในประเทศหลายแห่งสถาบันวิจัยและองค์กรต่างๆได้ออกแผนการวางจำหน่ายที่คล้ายกับ ChatGPT CHATGPT ไม่ใช่โอเพ่นซอร์สและเป็นเรื่องยากมากที่จะทำซ้ำ แม้ตอนนี้ไม่มีหน่วยหรือองค์กรได้ทำซ้ำความสามารถเต็มรูปแบบของ GPT3 ตอนนี้ OpenAi ประกาศการเปิดตัวรุ่น GPT4 อย่างเป็นทางการด้วยกราฟิกและข้อความหลายรูปแบบและความสามารถของมันได้รับการปรับปรุงอย่างมากเมื่อเทียบกับ CHATGPT ดูเหมือนว่ามันจะได้กลิ่นการปฏิวัติอุตสาหกรรมครั้งที่สี่ที่ครอบงำด้วยปัญญาประดิษฐ์ทั่วไป
ไม่ว่าจะเป็นในต่างประเทศหรือที่บ้านช่องว่างระหว่าง Openai เริ่มใหญ่ขึ้นและใหญ่ขึ้นและทุกคนกำลังติดตามในลักษณะที่วุ่นวายดังนั้นพวกเขาจึงอยู่ในตำแหน่งที่ได้เปรียบในนวัตกรรมทางเทคโนโลยีนี้ ในปัจจุบันการวิจัยและพัฒนาขององค์กรขนาดใหญ่หลายแห่งนั้นใช้เส้นทางปิดแหล่งข้อมูล มีรายละเอียดเล็กน้อยที่เปิดตัวอย่างเป็นทางการโดย CHATGPT และ GPT4 และไม่เหมือนการแนะนำบทความก่อนหน้านี้ที่แนะนำหลายสิบหน้ายุคของการค้าของ OpenAi มาถึงแล้ว แน่นอนว่าองค์กรหรือบุคคลบางแห่งได้สำรวจการเปลี่ยนโอเพ่นซอร์ส บทความนี้สรุปได้ดังนี้ ฉันจะติดตามพวกเขาต่อไป มีการเปลี่ยนโอเพนซอร์สที่ได้รับการปรับปรุงเพื่ออัปเดตสถานที่นี้ในเวลาที่เหมาะสม
วิธีการประเภทนี้ส่วนใหญ่ใช้วิธีการที่ไม่ใช่ llama และวิธีการปรับแต่งอื่น ๆ เพื่อออกแบบอย่างอิสระหรือเพิ่มประสิทธิภาพโมเดล GPT และ T5 และตระหนักถึงกระบวนการวงจรเต็มรูปแบบเช่นการฝึกอบรมล่วงหน้าการปรับแต่งการปรับแต่งและการเรียนรู้เสริมแรง
Chatyuan (Yuanyu AI) ได้รับการพัฒนาและเผยแพร่โดยทีมพัฒนาอัจฉริยะของ Yuanyu มันอ้างว่าเป็นรูปแบบการสนทนาการทำงานครั้งแรกในประเทศจีน มันสามารถเขียนบทความทำการบ้านเขียนบทกวีและแปลภาษาจีนและภาษาอังกฤษ บางพื้นที่เฉพาะเช่นกฎหมายสามารถให้ข้อมูลที่เกี่ยวข้อง ปัจจุบันรุ่นนี้รองรับภาษาจีนเท่านั้นและลิงค์ GitHub คือ:
https://github.com/clue-ai/chatyuan
ตัดสินจากรายละเอียดทางเทคนิคที่เปิดเผยเลเยอร์พื้นฐานใช้โมเดล T5 ที่มีขนาดพารามิเตอร์ 700 ล้านพารามิเตอร์และการควบคุมและการปรับแต่งตาม Prottclue เพื่อจัดรูปแบบ Chatyuan โมเดลนี้เป็นขั้นตอนแรกของเส้นทางเทคนิคสามขั้นตอน ChatGPT และไม่มีการฝึกอบรมแบบจำลองรางวัลและการฝึกอบรมการเรียนรู้การเสริมแรง PPO
เมื่อเร็ว ๆ นี้โอเพ่นซอร์ส Colossalai Operation CHATGPT ของพวกเขา แบ่งปันกลยุทธ์สามขั้นตอนของพวกเขาและใช้เส้นทางทางเทคนิคของ CHATGPT Core: GitHub มีดังนี้:
https://github.com/hpcaitech/colossalai
จากโครงการนี้ฉันได้ชี้แจงกลยุทธ์สามขั้นตอนและแบ่งปัน:
ขั้นตอนแรก (Stage1_sft.py): ขั้นตอนการปรับแต่ง SFT การควบคุมอย่างละเอียดโครงการโอเพ่นซอร์สไม่ได้ดำเนินการนี่ค่อนข้างง่ายเพราะ Colossalai รองรับ HuggingFace ได้อย่างราบรื่น ฉันใช้ฟังก์ชั่นผู้ฝึกสอนของ HuggingFace โดยตรงสองสามบรรทัดเพื่อนำไปใช้งานได้อย่างง่ายดาย ที่นี่ฉันใช้รุ่น GPT2 จากมุมมองของการใช้งานมันรองรับ GPT2, OPT และ Bloom Models;
ขั้นตอนที่สอง (stage2_rm.py): ขั้นตอนการฝึกอบรมรางวัล (RM) นั่นคือส่วนฝึกอบรม train_reward_model.py ในตัวอย่างโครงการ;
ขั้นตอนที่สาม (stage3_ppo.py): ขั้นตอนการเรียนรู้การเสริมแรง (RLHF) นั่นคือ Project Train_prompts.py
การดำเนินการของไฟล์ทั้งสามไฟล์จะต้องวางไว้ในโครงการ Colossalai ซึ่งแกนในรหัสเป็น CHATGPT ในโครงการดั้งเดิมและ cores.nn กลายเป็น chatgpt.models ในโครงการดั้งเดิม
Chatglm เป็นรูปแบบการสนทนาของซีรี่ส์ GLM ของ Zhipu AI บริษัท ที่เปลี่ยนความสำเร็จด้านเทคโนโลยีใน Tsinghua สนับสนุนภาษาจีนและภาษาอังกฤษและปัจจุบันมีโมเดลพารามิเตอร์ 6.2 พันล้าน มันสืบทอดข้อดีของ GLM และปรับสถาปัตยกรรมแบบจำลองให้เหมาะสมซึ่งจะช่วยลดเกณฑ์สำหรับการปรับใช้และแอปพลิเคชันโดยตระหนักถึงการประยุกต์ใช้การอนุมานของโมเดลขนาดใหญ่บนกราฟิกการ์ดผู้บริโภค สำหรับเทคนิคโดยละเอียดโปรดดูที่ GitHub:
ที่อยู่โอเพ่นซอร์สของ chatglm-6b คือ: https://github.com/thudm/chatglm-6b
จากมุมมองทางเทคนิคมันได้นำการเรียนรู้การเสริมแรงของ Chatgpt เกี่ยวกับกลยุทธ์การจัดตำแหน่งของมนุษย์ทำให้ผลการผลิตดีขึ้นและใกล้เคียงกับคุณค่าของมนุษย์มากขึ้น พื้นที่ความสามารถในปัจจุบันส่วนใหญ่รวมถึงการรับรู้ตนเองการเขียนโครงร่างการเขียนคำโฆษณาผู้ช่วยการเขียนอีเมลการสกัดข้อมูลการเล่นบทบาทการเปรียบเทียบความคิดเห็นคำแนะนำการเดินทาง ฯลฯ มันได้พัฒนาโมเดลขนาดใหญ่สุดยอด 130 พันล้านภายใต้การทดสอบภายในซึ่งถือเป็นแบบจำลองบทสนทนาที่มีพารามิเตอร์ขนาดใหญ่ขึ้น
VisualGLM-6B (อัปเดตเมื่อวันที่ 19 พฤษภาคม 2566)
เมื่อเร็ว ๆ นี้ทีมได้เปิดรุ่น Multimodal ของ Chatglm-6B ซึ่งรองรับบทสนทนาหลายรูปแบบในภาพภาษาจีนและภาษาอังกฤษ ส่วนของโมเดลภาษาใช้ chatglm-6b และส่วนภาพสร้างสะพานเชื่อมระหว่างโมเดลภาพและโมเดลภาษาโดยการฝึกอบรม blip2-qformer โมเดลโดยรวมมีพารามิเตอร์ทั้งหมด 7.8 พันล้านพารามิเตอร์ VisualGLM-6B ขึ้นอยู่กับคู่กราฟิกจีนคุณภาพสูง 30 เมตรจากชุดข้อมูล Cogview และได้รับการฝึกฝนล่วงหน้าด้วยคู่กราฟิกภาษาอังกฤษที่กรอง 300 ม. ด้วยน้ำหนักเท่ากันในภาษาจีนและภาษาอังกฤษ วิธีการฝึกอบรมนี้ดีกว่าจัดเรียงข้อมูลภาพให้เข้ากับพื้นที่ความหมายของ Chatglm; ในขั้นตอนการปรับแต่งที่ตามมาแบบจำลองได้รับการฝึกอบรมเกี่ยวกับข้อมูลคำถามและคำตอบที่มองเห็นได้นานเพื่อสร้างคำตอบที่ตรงตามความต้องการของมนุษย์
Visualglm-6b ที่อยู่โอเพ่นซอร์สคือ: https://github.com/thudm/visualglm-6b
chatglm2-6b (อัปเดตเมื่อวันที่ 27 มิถุนายน 2566)
ทีมเพิ่งเปิดรุ่นที่สองรุ่นที่สองของ Chatglm ที่มาจาก ChatglM2-6B เมื่อเปรียบเทียบกับรุ่นรุ่นแรกคุณสมบัติหลักของมันรวมถึงการใช้มาตราส่วนข้อมูลขนาดใหญ่จาก 1t ถึง 1.4t; สิ่งที่โดดเด่นที่สุดคือการสนับสนุนบริบทที่ยาวนานขึ้นซึ่งขยายจาก 2K เป็น 32K ช่วยให้อินพุตที่ยาวขึ้นและสูงขึ้น นอกจากนี้ความเร็วการอนุมานได้รับการปรับให้เหมาะสมอย่างมากเพิ่มขึ้น 42%และทรัพยากรหน่วยความจำวิดีโอที่ถูกครอบครองลดลงอย่างมาก
chatglm2-6b ที่อยู่โอเพ่นซอร์สคือ: https://github.com/thudm/chatglm2-6b
เป็นที่รู้จักกันในชื่อโครงการทดแทนโอเพนซอร์ส Chatgpt แห่งแรกและแนวคิดพื้นฐานนั้นขึ้นอยู่กับสถาปัตยกรรมของ Google Language Model Model และการใช้วิธีการเรียนรู้เสริมแรง (RLHF) จากข้อเสนอแนะของมนุษย์ Palm เป็นรุ่นพารามิเตอร์ 540 พันล้านรุ่นที่เปิดตัวโดย Google ในเดือนเมษายนปีนี้ตามการฝึกอบรมระบบ Pathways มันสามารถทำงานให้เสร็จสมบูรณ์เช่นการเขียนโค้ดแชทการทำความเข้าใจภาษา ฯลฯ และมีประสิทธิภาพการเรียนรู้ตัวอย่างต่ำที่ทรงพลังในงานส่วนใหญ่ ในเวลาเดียวกันมีการใช้กลไกการเรียนรู้การเสริมแรงแบบ chatgpt ซึ่งสามารถทำให้คำตอบของ AI สอดคล้องกับความต้องการสถานการณ์และลดความเป็นพิษของแบบจำลอง
ที่อยู่ GitHub คือ: https://github.com/lucidrains/palm-rlhf-pytorch
โครงการนี้เป็นที่รู้จักกันในชื่อโมเดลโอเพนซอร์สที่ใหญ่ที่สุดสูงถึง 1.5 ล้านล้านและเป็นแบบจำลองหลายรูปแบบ โดเมนความสามารถของมันรวมถึงการทำความเข้าใจภาษาธรรมชาติการแปลเครื่องคำถามและคำตอบอัจฉริยะการวิเคราะห์ความเชื่อมั่นและการจับคู่กราฟิก ฯลฯ ที่อยู่โอเพนซอร์สคือ:
https://huggingface.co/banana-dev/gptrillion
(ในวันที่ 24 พฤษภาคม 2566 โครงการนี้เป็นโปรแกรมตลกวัน April Fools '
OpenFlamingo เป็นกรอบการทำงานที่เกณฑ์มาตรฐาน GPT-4 และสนับสนุนการฝึกอบรมและการประเมินผลของแบบจำลองหลายรูปแบบขนาดใหญ่ มันได้รับการปล่อยตัวโดย Laion ที่ไม่แสวงหาผลกำไรและเป็นการทำซ้ำของโมเดลฟลามิงโกของ DeepMind ปัจจุบันโอเพ่นซอร์สเป็นรุ่น OpenFlamingo-9B ที่ใช้ Llama โมเดลฟลามิงโกได้รับการฝึกฝนในคลังข้อมูลเครือข่ายขนาดใหญ่ที่มีข้อความและรูปภาพที่เชื่อมโยงกันและมีความสามารถในการเรียนรู้ตัวอย่างที่ จำกัด บริบท OpenFlamingo ใช้สถาปัตยกรรมเดียวกันที่เสนอในฟลามิงโกดั้งเดิมซึ่งได้รับการฝึกฝนเกี่ยวกับตัวอย่าง 5M จากชุดข้อมูล C4 แบบหลายรูปแบบใหม่และตัวอย่าง 10M จาก LAION-2B ที่อยู่โอเพ่นซอร์สของโครงการนี้คือ:
https://github.com/mlfoundations/open_flamingo
เมื่อวันที่ 21 กุมภาพันธ์ปีนี้มหาวิทยาลัย Fudan เปิดตัวมอสและเปิดเบต้าสาธารณะซึ่งทำให้เกิดการโต้เถียงกันหลังจากการล่มสลายของเบต้าสาธารณะ ตอนนี้โครงการได้นำไปสู่การอัปเดตที่สำคัญและโอเพ่นซอร์ส มอสโอเพนซอร์สรองรับทั้งภาษาจีนและภาษาอังกฤษและรองรับปลั๊กอินเช่นการแก้สมการการค้นหา ฯลฯ พารามิเตอร์คือ 16B และได้รับการฝึกอบรมล่วงหน้าในภาษาจีนและภาษาอังกฤษประมาณ 700 พันล้านคำ คำแนะนำการสนทนาที่ตามมาได้รับการปรับแต่งการเรียนรู้ที่เพิ่มขึ้นปลั๊กอินและการฝึกอบรมการตั้งค่าของมนุษย์มีความสามารถในการสนทนาหลายรอบและความสามารถในการใช้ปลั๊กอินหลายตัว ที่อยู่โอเพ่นซอร์สของโครงการนี้คือ:
https://github.com/openlmlab/moss
เช่นเดียวกับ minigpt-4 และ llava มันเป็นแบบจำลองแบบหลายรูปแบบแบบโอเพนซอร์ส GPT-4 ซึ่งยังคงดำเนินต่อไปแนวคิดการฝึกอบรมแบบแยกส่วนของซีรี่ส์ MPLUG ปัจจุบันเปิดตัวโมเดลปริมาณพารามิเตอร์ 7B และในเวลาเดียวกันก็เสนอชุดทดสอบที่ครอบคลุม Owleval เป็นครั้งแรกสำหรับการทำความเข้าใจการเรียนการสอนที่เกี่ยวข้องกับภาพ ผ่านการประเมินด้วยตนเองแบบจำลองที่มีอยู่รวมถึง LLAVA, MINIGPT-4 และงานอื่น ๆ แสดงให้เห็นถึงความสามารถที่หลากหลายที่ดีขึ้นโดยเฉพาะอย่างยิ่งในความสามารถในการทำความเข้าใจการสอนหลายรูปแบบความสามารถในการสนทนาหลายรอบความสามารถในการให้เหตุผลความรู้ ฯลฯ
ที่อยู่โอเพ่นซอร์สของโครงการนี้คือ: https://github.com/x-plug/mplug-owl
Pandalm เป็นรูปแบบการประเมินแบบจำลองที่มีจุดมุ่งหมายเพื่อประเมินการตั้งค่าของแบบจำลองขนาดใหญ่อื่น ๆ โดยอัตโนมัติเพื่อสร้างเนื้อหาประหยัดค่าใช้จ่ายในการประเมินด้วยตนเอง Pandalm มาพร้อมกับเว็บอินเตอร์เฟสสำหรับการวิเคราะห์และยังรองรับการเรียกรหัส Python มันสามารถประเมินข้อความที่สร้างขึ้นโดยรุ่นและข้อมูลใด ๆ ที่มีรหัสเพียงสามบรรทัดซึ่งสะดวกมากในการใช้งาน
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/weopenml/pandalm
ในการประชุม Zhiyuan จัดขึ้นเมื่อเร็ว ๆ นี้สถาบันวิจัย Zhiyuan เปิดแหล่งที่มาของการตรัสรู้และแบบจำลอง Sky Eagle ซึ่งมีความรู้สองภาษาของจีนและอังกฤษ พารามิเตอร์โมเดลพื้นฐานของเวอร์ชันโอเพ่นซอร์สรวมถึง 7 พันล้านและ 33 พันล้าน ในขณะเดียวกันก็เปิดโมเดลการสนทนา Aquilachat และรูปแบบการสร้างรหัสข้อความของ Quilacode และทั้งคู่ได้รับการเปิดสำหรับใบอนุญาตเชิงพาณิชย์ Aquila ใช้สถาปัตยกรรมแบบถอดรหัสอย่างเดียวเช่น GPT-3 และ Llama และยังปรับปรุงคำศัพท์สำหรับภาษาจีนและภาษาอังกฤษสองภาษาและใช้วิธีการฝึกอบรมเร่งความเร็ว การรับประกันประสิทธิภาพไม่เพียง แต่ขึ้นอยู่กับการเพิ่มประสิทธิภาพและการปรับปรุงโมเดล แต่ยังได้รับประโยชน์จากการสะสมข้อมูลคุณภาพสูงของ Zhiyuan ในรุ่นใหญ่ในช่วงไม่กี่ปีที่ผ่านมา
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/flagai-open/flagai/tree/master/examples/aquila
เมื่อเร็ว ๆ นี้ Microsoft ได้เผยแพร่กระดาษรุ่นใหญ่หลายรูปแบบและรหัสโอเพ่นซอร์ส-รหัสซึ่งเชื่อมต่อ Video-Image-Image-Video อย่างสมบูรณ์รองรับการป้อนข้อมูลโดยพลการและเอาต์พุตโมดอลโดยพลการ เพื่อให้บรรลุการสร้างรังสีโดยพลการนักวิจัยได้แบ่งการฝึกอบรมออกเป็นสองขั้นตอน ในขั้นตอนแรกผู้เขียนใช้กลยุทธ์การจัดตำแหน่งสะพานและเงื่อนไขรวมในการฝึกอบรมสร้างแบบจำลองการแพร่กระจายที่เป็นไปได้สำหรับแต่ละโหมด ในขั้นตอนที่สองโมดูลความสนใจแบบแยกถูกเพิ่มเข้าไปในรูปแบบการแพร่กระจายที่เป็นไปได้แต่ละแบบและตัวเข้ารหัสสิ่งแวดล้อมซึ่งสามารถฉายตัวแปรแฝงของแบบจำลองการแพร่กระจายที่อาจเกิดขึ้นในพื้นที่ที่ใช้ร่วมกันเพื่อให้รังสีที่สร้างขึ้นนั้นมีความหลากหลายต่อไป
ที่อยู่โอเพ่นซอร์สของโครงการนี้คือ: https://github.com/microsoft/i-code/tree/main/i-code-v3
Meta ได้เปิดตัวและเปิดแหล่ง ImageBind รุ่นใหญ่หลายรูปแบบซึ่งสามารถบรรลุการข้าม 6 วิธีรวมถึงภาพวิดีโอเสียงความลึกความร้อนและการเคลื่อนไหวเชิงพื้นที่ ImageBind แก้ปัญหาการจัดตำแหน่งโดยใช้ลักษณะการเชื่อมโยงของภาพโดยใช้แบบจำลองภาษาภาพขนาดใหญ่และความสามารถในการตัวอย่างเป็นศูนย์เพื่อขยายไปยังโมเดลใหม่ ข้อมูลการจับคู่รูปภาพนั้นเพียงพอที่จะผูกโหมดทั้งหกนี้เข้าด้วยกันทำให้โหมดที่แตกต่างกันสามารถเปิดการแยกโมดอลจากกันและกัน
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/facebookresearch/imagebind
เมื่อวันที่ 10 เมษายน 2566 วัง Xiaochuan ประกาศอย่างเป็นทางการว่ามีการจัดตั้ง บริษัท AI Big Model "Baichuan Intelligence" อย่างเป็นทางการโดยมีวัตถุประสงค์เพื่อสร้าง Openai รุ่นจีน สองเดือนหลังจากการจัดตั้ง Baichuan Intelligent ได้สร้างแหล่งที่สำคัญของโมเดล Baichuan-7B ที่พัฒนาขึ้นอย่างอิสระซึ่งสนับสนุนจีนและอังกฤษ Baichuan-7b ไม่เพียง แต่เกินกว่ารุ่นใหญ่อื่น ๆ เช่น Chatglm-6B ที่มีข้อได้เปรียบที่สำคัญในรายการการประเมินผลที่มีอำนาจ C-eval, Agieval และ Gaokao ของจีน แต่ยังนำไปสู่ Llama-7b ในรายการประเมินผล โมเดลนี้มีระดับโทเค็นล้านล้านในข้อมูลคุณภาพสูงและรองรับความสามารถในการขยายตัวของหน้าต่างไดนามิกที่มีความยาวเป็นพิเศษหลายหมื่นครั้งบนพื้นฐานของการเพิ่มประสิทธิภาพของผู้ปฏิบัติงานที่ให้ความสนใจอย่างมีประสิทธิภาพ ปัจจุบันโอเพ่นซอร์สรองรับความสามารถในบริบท 4K โมเดลโอเพ่นซอร์สนี้มีวางจำหน่ายทั่วไปและเป็นมิตรมากกว่า Llama
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/baichuan-inc/baichuan-7b
เมื่อวันที่ 6 สิงหาคม 2566 ทีม Yuanxiang Xverse เปิดรุ่น Xverse-13b โมเดลนี้เป็นรุ่นขนาดใหญ่หลายภาษาที่รองรับได้ถึง 40+ ภาษาและรองรับความยาวตามบริบทสูงถึง 8192 ตามทีมงานคุณลักษณะของโมเดลนี้คือ: โครงสร้างของโมเดล: Xverse-13b ใช้โครงสร้างตัวถอดรหัสที่มีความยาวตามความต้องการ ข้อมูลการฝึกอบรม: 1.4 ล้านล้านโทเค็นของข้อมูลคุณภาพสูงและหลากหลายถูกสร้างขึ้นเพื่อฝึกอบรมแบบจำลองอย่างเต็มที่รวมถึง 40 จีนอังกฤษรัสเซียและตะวันตก หลายภาษาโดยการตั้งค่าอัตราส่วนการสุ่มตัวอย่างอย่างประณีตของข้อมูลประเภทต่าง ๆ ภาษาจีนและภาษาอังกฤษทำงานได้ดีและยังสามารถคำนึงถึงผลกระทบของภาษาอื่น ๆ การแบ่งส่วนคำ: ขึ้นอยู่กับอัลกอริทึม BPE การแบ่งส่วนคำที่มีขนาดคำศัพท์ 100,278 ได้รับการฝึกฝนโดยใช้คลังข้อมูล GB หลายร้อยแห่งซึ่งสามารถรองรับหลายภาษาในเวลาเดียวกันโดยไม่ต้องขยายรายการคำเพิ่มเติม กรอบการฝึกอบรม: พัฒนาเทคโนโลยีที่สำคัญจำนวนมากรวมถึงตัวดำเนินการที่มีประสิทธิภาพการเพิ่มประสิทธิภาพหน่วยความจำวิดีโอกลยุทธ์การกำหนดเวลาแบบขนานการซ้อนทับการสื่อสารข้อมูลการสื่อสารข้อมูลแพลตฟอร์มและเฟรมเวิร์กการทำงานร่วมกัน ฯลฯ ทำให้ประสิทธิภาพการฝึกอบรมสูงขึ้น อัตราการใช้พลังงานสูงสุดในการใช้พลังงานในคลัสเตอร์ Kilocard สามารถเข้าถึง 58.5%ซึ่งอยู่ในระดับแนวหน้าในอุตสาหกรรม
ที่อยู่โอเพ่นซอร์สของโครงการนี้คือ: https://github.com/xverse-ai/xverse-13b
เมื่อวันที่ 3 สิงหาคม 2566 โมเดล 7 พันล้านของอาลีบาบาตองบาคีเนียร์เป็นโอเพ่นซอร์สรวมถึงโมเดลทั่วไปและแบบจำลองการสนทนาและเป็นโอเพ่นซอร์สฟรีและมีจำหน่ายในเชิงพาณิชย์ ตามรายงาน QWEN-7B เป็นรูปแบบภาษาขนาดใหญ่ที่ใช้หม้อแปลงและได้รับการฝึกฝนเกี่ยวกับข้อมูลการฝึกอบรมก่อนระดับที่มีขนาดใหญ่มาก ประเภทข้อมูลการฝึกอบรมก่อนมีความหลากหลายและครอบคลุมพื้นที่หลากหลายรวมถึงข้อความออนไลน์จำนวนมากหนังสือมืออาชีพรหัส ฯลฯ เป็นรูปแบบท่าเรือที่รองรับภาษาจีนและภาษาอังกฤษได้รับการฝึกฝนเกี่ยวกับชุดข้อมูลโทเค็นมากกว่า 2 ล้านล้านชุดและความยาวหน้าต่างบริบทถึง 8K Qwen-7b-Chat เป็นแบบจำลองบทสนทนาภาษาจีน-อังกฤษโดยใช้โมเดลแท่น QWEN-7B โมเดลที่ได้รับการฝึกอบรมล่วงหน้าของ Tongyi Qianwen 7B ทำได้ดีในการประเมินเกณฑ์มาตรฐานที่มีสิทธิ์หลายครั้ง ความสามารถของจีนและภาษาอังกฤษเกินกว่ารุ่นโอเพนซอร์สที่มีสเกลเดียวกันทั้งในและต่างประเทศและความสามารถบางอย่างเกินกว่ารุ่นโอเพนซอร์สที่มีขนาด 12B และ 13B
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/qwenlm/qwen-7b
Llama เป็นรูปแบบภาษาปัญญาประดิษฐ์ขนาดใหญ่ใหม่ล่าสุดที่เผยแพร่โดย Meta ซึ่งทำงานได้ดีในงานต่าง ๆ เช่นการสร้างข้อความการสนทนาสรุปวัสดุที่เป็นลายลักษณ์อักษรพิสูจน์ทฤษฎีบททางคณิตศาสตร์หรือการทำนายโครงสร้างโปรตีน โมเดล Llama รองรับ 20 ภาษารวมถึงภาษาละตินและ Cyrillic ตามตัวอักษร ปัจจุบันโมเดลดั้งเดิมไม่สนับสนุนภาษาจีน อาจกล่าวได้ว่าการรั่วไหลของมหากาพย์ของ Llama ได้ส่งเสริมการพัฒนาโอเพ่นซอร์สอย่างจริงจัง
(อัปเดตเมื่อวันที่ 22 เมษายน 2023) แต่น่าเสียดายที่การอนุญาตของ Llama นั้นมี จำกัด และสามารถใช้สำหรับการวิจัยทางวิทยาศาสตร์เท่านั้นและไม่ได้รับอนุญาตให้ใช้ในเชิงพาณิชย์ เพื่อแก้ปัญหาโอเพนซอร์สเชิงพาณิชย์โครงการ Redpajama ได้เข้ามามีวัตถุประสงค์เพื่อสร้างแบบจำลองโอเพนซอร์ซแบบโอเพนซอร์สที่สามารถใช้สำหรับแอพพลิเคชั่นเชิงพาณิชย์และจัดทำกระบวนการวิจัยที่โปร่งใสมากขึ้น Redpajama ที่สมบูรณ์รวมชุดข้อมูลโทเค็น 1.2 ล้านล้านและขั้นตอนต่อไปคือการเริ่มการฝึกอบรมขนาดใหญ่ งานนี้ยังคงคุ้มค่าที่จะรอคอยและที่อยู่โอเพ่นซอร์สคือ:
https://github.com/togethercomputer/redpajama-data
(อัปเดตเมื่อวันที่ 7 พฤษภาคม 2566)
Redpajama อัปเดตไฟล์โมเดลการฝึกอบรมรวมถึงพารามิเตอร์สองตัว: 3B และ 7B ซึ่ง 3B สามารถทำงานบนการ์ดกราฟิกเกม RTX2070 ที่เปิดตัวเมื่อ 5 ปีที่แล้ว ที่อยู่รุ่นของมันคือ:
https://huggingface.co/togethercomputer
นอกเหนือจาก Redpajama แล้ว MosaicML ได้เปิดตัว MPT Series Model และข้อมูลการฝึกอบรมใช้ข้อมูล Redpajama ในการประเมินประสิทธิภาพที่หลากหลายโมเดล 7B เปรียบได้กับ Llama ดั้งเดิม ที่อยู่โอเพ่นซอร์สของโมเดลคือ:
https://huggingface.co/mosaicml
ไม่ว่าจะเป็น Redpajama หรือ MPT มันยังเปิดแหล่งข้อมูลรุ่นแชทที่สอดคล้องกัน แหล่งโอเพ่นซอร์สของทั้งสองรุ่นนี้ได้นำไปสู่การค้าขายของ Chatgpt อย่างมาก
(อัปเดตเมื่อวันที่ 1 มิถุนายน 2566)
Falcon เป็นฐานขนาดใหญ่แบบเปิดที่เปรียบเทียบ LLAMA มันมีเครื่องชั่งวัดพารามิเตอร์สองตัว: 7b และ 40b ประสิทธิภาพของ 40B เป็นที่รู้จักกันในชื่อ 65B สูงพิเศษ เป็นที่เข้าใจกันว่า Falcon ยังคงใช้โมเดลตัวถอดรหัส GPT autoregressive แต่มันใช้ความพยายามอย่างมากในข้อมูล หลังจากการขูดเนื้อหาจากเครือข่ายสาธารณะและสร้างชุดข้อมูลเบื้องต้นเริ่มต้นจะใช้การถ่ายโอนข้อมูลแบบ Commoncrawl เพื่อทำการกรองขนาดใหญ่และการขจัดข้อมูลซ้ำซ้อนขนาดใหญ่และในที่สุดก็ได้รับชุดข้อมูลที่มีขนาดใหญ่มากซึ่งประกอบด้วยโทเค็นเกือบ 5 ล้านล้านโท ในเวลาเดียวกันมีการเพิ่มคลังข้อมูลที่เลือกจำนวนมากรวมถึงงานวิจัยและการสนทนาโซเชียลมีเดีย อย่างไรก็ตามการอนุญาตของโครงการได้รับการโต้เถียงและใช้วิธีการอนุญาต "กึ่งเชิงพาณิชย์" และ 10% ของค่าใช้จ่ายเชิงพาณิชย์จะเริ่มเกิดขึ้นหลังจากรายได้สูงถึง 1 ล้าน
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://huggingface.co/tiiuae
(อัปเดตเมื่อวันที่ 3 กรกฎาคม 2566)
Falcon ดั้งเดิมขาดความสามารถในการสนับสนุนจีนเช่น Llama ทีมงานโครงการ "Linly" สร้างและเปิดเวอร์ชั่นภาษาจีนของจีน-Falcon ตามรุ่น Falcon โมเดลขยายตัวครั้งแรกและขยายรายการคำศัพท์อย่างมากรวมถึง 8701 ตัวละครจีนที่ใช้กันทั่วไปเป็นคำศัพท์ความถี่สูง 20,000 คำแรกในรายการคำศัพท์ Jieba และเครื่องหมายวรรคตอนจีน 60 รายการ หลังจากการซ้ำซ้อนขนาดของรายการคำศัพท์จะขยายเป็น 90,046 ในระหว่างขั้นตอนการฝึกอบรมมีการใช้ข้อมูลขนาดใหญ่ 50 กรัมและข้อมูลขนาดใหญ่ 2T สำหรับการฝึกอบรม
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/cvi-szu/linly
(อัปเดตเมื่อวันที่ 24 กรกฎาคม 2566)
Falcon ดั้งเดิมขาดความสามารถในการสนับสนุนจีนเช่น Llama ทีมงานโครงการ "Linly" สร้างและเปิดเวอร์ชั่นภาษาจีนของจีน-Falcon ตามรุ่น Falcon โมเดลขยายตัวครั้งแรกและขยายรายการคำศัพท์อย่างมากรวมถึง 8701 ตัวละครจีนที่ใช้กันทั่วไปเป็นคำศัพท์ความถี่สูง 20,000 คำแรกในรายการคำศัพท์ Jieba และเครื่องหมายวรรคตอนจีน 60 รายการ หลังจากการซ้ำซ้อนขนาดของรายการคำศัพท์จะขยายเป็น 90,046 ในระหว่างขั้นตอนการฝึกอบรมมีการใช้ข้อมูลขนาดใหญ่ 50 กรัมและข้อมูลขนาดใหญ่ 2T สำหรับการฝึกอบรม
ที่อยู่โอเพ่นซอร์สของโครงการคือ: https://github.com/cvi-szu/linly
รุ่น Alpaca (Alpaca) ที่วางจำหน่ายโดย Stanford เป็นรุ่นใหม่ที่ใช้โมเดล Llama-7b หลักการพื้นฐานคือการอนุญาตให้โมเดล Text-Davinci-003 ของ OpenAi สร้างตัวอย่างการเรียนการสอน 52K ในลักษณะที่เป็นเครื่องมือในตนเองเพื่อปรับแต่ง Llama โครงการได้เปิดข้อมูลการฝึกอบรมแหล่งที่มารหัสเพื่อสร้างข้อมูลการฝึกอบรมและไฮเปอร์พารามิเตอร์ ไฟล์โมเดลยังไม่ได้รับการเปิดแหล่งที่มาถึงมากกว่า 5.6k ดาวในหนึ่งวัน งานนี้ได้รับความนิยมอย่างมากเนื่องจากการเข้าถึงข้อมูลราคาถูกและง่ายและได้เปิดถนนสู่การเลียนแบบ CHATGPT ราคาถูก ที่อยู่ GitHub ของมันคือ:
https://github.com/tatsu-lab/stanford_alpaca
มันเป็นการใช้งานโอเพนซอร์สของ Llama+AI chatbot โดยใช้การเรียนรู้การเสริมแรงตอบกลับของมนุษย์ที่เปิดตัวโดย Nebuly+AI เส้นทางทางเทคนิคนั้นคล้ายกับ CHATGPT โครงการเพิ่งเปิดตัวเป็นเวลา 2 วันและได้รับรางวัลดาว 5.2K ที่อยู่ GitHub ของมันคือ:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
อัลกอริทึมกระบวนการฝึกอบรม Chatllama ส่วนใหญ่ใช้เพื่อให้ได้การฝึกอบรมที่เร็วและถูกกว่า ChatGPT ว่ากันว่าเร็วขึ้นเกือบ 15 เท่า คุณสมบัติหลักคือ:
การใช้งานโอเพนซอร์สที่สมบูรณ์ช่วยให้ผู้ใช้สามารถสร้างบริการสไตล์ chatgpt ตามรุ่น Llama ที่ผ่านการฝึกอบรมมาก่อน
สถาปัตยกรรม Llama มีขนาดเล็กลงทำให้กระบวนการฝึกอบรมและการให้เหตุผลเร็วขึ้นและมีค่าใช้จ่ายน้อยลง
การสนับสนุนในตัวสำหรับ Deepspeed Zero เพื่อเพิ่มความเร็วในการปรับแต่งกระบวนการปรับแต่ง
รองรับสถาปัตยกรรมโมเดล Llama ที่มีขนาดต่าง ๆ และผู้ใช้สามารถปรับแต่งโมเดลได้ตามความชอบของตนเอง
OpenChatkit ถูกสร้างขึ้นร่วมกันโดยทีมร่วมกันซึ่งอดีตนักวิจัย OpenAI ตั้งอยู่เช่นเดียวกับทีม LaIon และ Ontocord.ai OpenChatKit มีพารามิเตอร์ 20 พันล้านพารามิเตอร์และปรับแต่งด้วย GPT-NOX-20B เวอร์ชันโอเพ่นซอร์สของ GPT-3 ในขณะเดียวกันการเรียนรู้การเสริมแรงที่แตกต่างกันของ chatgpts, OpenChatkit ใช้รูปแบบการตรวจสอบพารามิเตอร์ 6 พันล้านเพื่อกรองข้อมูลที่ไม่เหมาะสมหรือเป็นอันตรายเพื่อให้มั่นใจถึงความปลอดภัยและคุณภาพของเนื้อหาที่สร้างขึ้น ที่อยู่ GitHub ของมันคือ:
https://github.com/togethercomputer/openchatkit
จากสแตนฟอร์ดอัลปากาการปรับจูนภายใต้การดูแลนั้นรับรู้จาก Bloom และ Llama งานเมล็ดพันธุ์ของ Stanford Alpaca ล้วนเป็นภาษาอังกฤษและข้อมูลที่เก็บรวบรวมก็เป็นภาษาอังกฤษ โครงการโอเพ่นซอร์สนี้คือการส่งเสริมการพัฒนาชุมชนโอเพนซอร์สรุ่นใหญ่ของจีน มันได้รับการปรับให้เหมาะสมสำหรับภาษาจีน การปรับแต่งแบบจำลองใช้ข้อมูลที่ผลิตโดย ChatGPT เท่านั้น (ไม่รวมข้อมูลอื่น ๆ ) โครงการมีสิ่งต่อไปนี้:
175 ภารกิจเมล็ดพันธุ์จีน
รหัสสำหรับการสร้างข้อมูล
ข้อมูลที่สร้างขึ้นโดย 10m นั้นเปิดให้บริการด้วยชุดข้อมูลคำสั่งทางคณิตศาสตร์ 1.5 ม., 0.25m และชุดข้อมูลการสนทนาหลายรอบหลายรอบ
แบบจำลองที่ได้รับการปรับปรุงตาม Bloomz-7B1-MT และ LLAMA-7B
ที่อยู่ GitHub คือ: https://github.com/lianjiatech/belle
Alpaca-Lora เป็นผลงานชิ้นเอกอีกชิ้นจากมหาวิทยาลัยสแตนฟอร์ด มันใช้เทคโนโลยี LORA (การปรับระดับต่ำ) เพื่อทำซ้ำผลลัพธ์ของ AlpACA โดยใช้วิธีต้นทุนต่ำและได้รับการฝึกฝนเฉพาะการ์ดกราฟิก RTX 4090 เป็นเวลา 5 ชั่วโมงเพื่อรับแบบจำลองที่มีระดับ Alpaca ยิ่งกว่านั้นรุ่นสามารถทำงานบน Raspberry Pi ในโครงการนี้มันใช้ Peft ของ Hugging Face สำหรับการปรับจูนราคาถูกและมีประสิทธิภาพ Peft เป็นห้องสมุด (LORA เป็นหนึ่งในเทคโนโลยีที่รองรับ) ที่ช่วยให้คุณใช้โมเดลภาษาที่ใช้หม้อแปลงหลากหลายและปรับแต่งด้วย LORA ช่วยให้การปรับจูนแบบจำลองราคาไม่แพงและมีประสิทธิภาพในฮาร์ดแวร์ทั่วไป ที่อยู่ GitHub ของโครงการนี้คือ:
https://github.com/tloen/alpaca-lora
แม้ว่า Alpaca และ Alpaca-Lora มีความคืบหน้าอย่างมาก แต่งานเมล็ดของพวกเขาก็เป็นทั้งภาษาอังกฤษและขาดการสนับสนุนจากจีน ในอีกด้านหนึ่งนอกเหนือจากที่กล่าวไว้ข้างต้นว่าเบลล์ได้รวบรวมคลังข้อมูลจีนจำนวนมากในทางกลับกันตามการทำงานของรุ่นก่อนเช่น Alpaca-Lora รูปแบบภาษาจีน Luotuo (Luotuo) ที่เปิดโดยนักพัฒนาสามคนจากมหาวิทยาลัยกลางกลางและสถาบันอื่น ๆ ปัจจุบันโครงการเปิดตัวสองรุ่น Luotuo-Lora-7b-0.1, Luotuo-Lora-7b-0.3 และรุ่นหนึ่งอยู่ในแผน ที่อยู่ GitHub ของมันคือ:
https://github.com/lc1332/chinese-alpaca-lora
แรงบันดาลใจจาก Alpaca Dolly ใช้ชุดข้อมูล Alpaca เพื่อให้ได้การปรับแต่งอย่างละเอียดเกี่ยวกับ GPT-J-6B เนื่องจากดอลลี่เองก็เป็น "โคลน" ของแบบจำลองในที่สุดทีมจึงตัดสินใจตั้งชื่อ "ดอลลี่" แรงบันดาลใจจาก Alpaca วิธีการโคลนนิ่งนี้กำลังได้รับความนิยมมากขึ้นเรื่อย ๆ โดยสรุปมันเป็นวิธีการเก็บข้อมูลโอเพ่นซอร์สของ Alpaca อย่างคร่าวๆและคำแนะนำในการปรับแต่งแบบจำลองขนาด 6B หรือ 7B เพื่อให้ได้เอฟเฟกต์เหมือน ChatGPT ความคิดนี้ประหยัดมากและสามารถเลียนแบบเสน่ห์ของ CHATGPT ได้อย่างรวดเร็ว มันเป็นที่นิยมมากและเมื่อเปิดตัวแล้วมันเต็มไปด้วยดวงดาว ที่อยู่ GitHub ของโครงการนี้คือ:
https://github.com/databrickslabs/dolly
หลังจากเปิดตัว Alpaca นักวิชาการสแตนฟอร์ดร่วมมือกับ CMU, UC Berkeley ฯลฯ เพื่อเปิดตัวโมเดลใหม่ - Vicuna ที่มีพารามิเตอร์ 13 พันล้านพารามิเตอร์ (รู้จักกันทั่วไปว่าอัลปากาและลลา) มีค่าใช้จ่ายเพียง $ 300 เพื่อให้ได้ประสิทธิภาพ 90% ของ CHATGPT Vicuna ใช้เพื่อปรับแต่ง Llama ในบทสนทนาที่ผู้ใช้ร่วมกันซึ่งรวบรวมโดย ShareGpt กระบวนการทดสอบใช้ GPT-4 เป็นเกณฑ์การประเมิน ผลการวิจัยพบว่า Vicuna-13b บรรลุความสามารถที่ตรงกับ CHATGPT และ BARD ในมากกว่า 90% ของกรณี
UC Berkeley LMSYS ORG เพิ่งเปิดตัว Vicuna ด้วยพารามิเตอร์ 7 พันล้าน มันไม่เพียง แต่มีขนาดเล็กประสิทธิภาพสูงและมีความสามารถสูง แต่ยังสามารถทำงานบน Mac ด้วยชิป M1/M2 ในคำสั่งเพียงสองบรรทัดและยังสามารถเปิดใช้งานการเร่งความเร็ว GPU!
ที่อยู่โอเพ่นซอร์สของ GitHub คือ: https://github.com/lm-sys/fastchat/
อีกเวอร์ชั่นภาษาจีนได้รับการเปิดโดย Vicuna จีนโดยมีที่อยู่ GitHub เป็น:
https://github.com/facico/chinese-vicuna
หลังจาก Chatgpt กลายเป็นที่นิยมผู้คนกำลังมองหาวิธีที่รวดเร็วไปยังวัด การปรากฏตัวที่คล้ายกับ chatgpt บางอย่างเริ่มปรากฏขึ้นโดยเฉพาะอย่างยิ่งการติดตาม chatgpt ในราคาที่ต่ำได้กลายเป็นวิธีที่ได้รับความนิยม LMFLOW เป็นผลิตภัณฑ์ที่เกิดในสถานการณ์ความต้องการนี้ซึ่งช่วยให้โมเดลขนาดใหญ่ได้รับการปรับปรุงในการ์ดกราฟิกทั่วไปเช่น 3090 โครงการเริ่มต้นโดยมหาวิทยาลัยวิทยาศาสตร์และเทคโนโลยีและเทคโนโลยีการเรียนรู้ของมหาวิทยาลัยฮ่องกง ในระบบการฝึกอบรมแบบจำลองขนาดใหญ่ที่มีประสิทธิภาพมากกว่าวิธีการก่อนหน้านี้
การใช้โครงการนี้แม้กระทั่งทรัพยากรการคำนวณที่ จำกัด สามารถอนุญาตให้ผู้ใช้สนับสนุนการฝึกอบรมส่วนบุคคลสำหรับสาขาที่เป็นกรรมสิทธิ์ ตัวอย่างเช่น LLAMA-7B, 3090 ใช้เวลา 5 ชั่วโมงในการฝึกอบรมให้เสร็จสมบูรณ์ซึ่งจะช่วยลดค่าใช้จ่ายได้อย่างมาก โครงการยังเปิดบริการตอบคำถามและตอบคำถามแบบฝั่งเว็บ (lmflow.com) การเกิดขึ้นและแหล่งที่มาของ LMFLOW ช่วยให้ทรัพยากรทั่วไปสามารถฝึกอบรมงานต่าง ๆ เช่นคำถาม & คำตอบมิตรภาพการเขียนการแปลการให้คำปรึกษาภาคสนามผู้เชี่ยวชาญ ฯลฯ นักวิจัยหลายคนกำลังพยายามใช้โครงการนี้เพื่อฝึกอบรมโมเดลขนาดใหญ่ที่มีปริมาณพารามิเตอร์ 65 พันล้านหรือสูงกว่า
ที่อยู่ GitHub ของโครงการนี้คือ:
https://github.com/optimalscale/lmflow
โครงการเสนอวิธีการรวบรวมการสนทนาโดยอัตโนมัติช่วยให้ Chatgpt สามารถพูดคุยด้วยตนเองแบทช์สร้างชุดข้อมูลการสนทนาหลายรอบคุณภาพสูงและรวบรวมคลังข้อมูล Q & A คุณภาพสูงประมาณ 50,000 คลังข้อมูลของ Quora, Stackoverflow และ Medqa ตามลำดับ ในขณะเดียวกันก็ปรับปรุงโมเดล Llama และเอฟเฟกต์นั้นค่อนข้างดี Bai Ze ยังใช้โซลูชันการปรับจูน Lora ที่มีต้นทุนต่ำในปัจจุบันเพื่อให้ได้เครื่องชั่งที่แตกต่างกันสามแบบ: Bai Ze-7b, 13b และ 30b รวมถึงแบบจำลองในสาขาการดูแลทางการแพทย์แนวตั้ง น่าเสียดายที่ชื่อจีนมีชื่อดี แต่ก็ยังไม่สนับสนุนภาษาจีน มีรายงานว่าแบบจำลอง Bai Ze ของจีนอยู่ภายใต้แผนและจะได้รับการปล่อยตัวในอนาคต ที่อยู่ GitHub โอเพนซอร์สคือ:
https://github.com/project-baize/baize
Chatgpt Flat Replacement ที่ใช้ Llama ยังคงหมักอย่างต่อเนื่อง Berkeley ของ UC Berkeley ได้เปิดตัว Koala รูปแบบการสนทนาที่สามารถทำงานบน GPU ผู้บริโภคด้วยพารามิเตอร์ 13B ชุดข้อมูลการฝึกอบรมของ Koala รวมถึงส่วนต่อไปนี้: ข้อมูล ChatGPT และข้อมูลโอเพนซอร์ส (Open Advicess Generalist (OIG), ชุดข้อมูลที่ใช้โดยรุ่น Stanford Alpaca, มานุษยวิทยา HH, OpenAI WebGPT, OpenAI Summarization) โมเดล Koala ถูกนำไปใช้ใน EasyLM โดยใช้ Jax/Flax โดยใช้ 8 A100 GPU และใช้เวลา 6 ชั่วโมงในการทำซ้ำ 2 ครั้ง เอฟเฟกต์การประเมินดีกว่า Alpaca ซึ่งได้รับประสิทธิภาพ 50% ของ ChatGPT
ที่อยู่โอเพ่นซอร์ส: https://github.com/young-geng/easylm
ด้วยการถือกำเนิดของสแตนฟอร์ดอัลปากาครอบครัวอัลปากาจำนวนมากและครอบครัวสัตว์ขยายเริ่มโผล่ออกมาและในที่สุดก็กอดนักวิจัย Face เพิ่งตีพิมพ์บล็อก Stackllama: คู่มือการฝึกอบรม Llama กับ RLHF ในเวลาเดียวกันโมเดลพารามิเตอร์ 7 พันล้าน - Stackllama ก็ถูกปล่อยออกมาเช่นกัน นี่คือแบบจำลองที่ปรับแต่งใน LLAMA-7B ผ่านการเรียนรู้การเสริมแรงตอบกลับของมนุษย์ สำหรับรายละเอียดดูที่อยู่บล็อก:
https://huggingface.co/blog/stackllama
โครงการเพิ่มประสิทธิภาพ Llama สำหรับภาษาจีนและเปิดระบบบทสนทนาที่ปรับแต่งได้อย่างละเอียด ขั้นตอนเฉพาะของโครงการนี้รวมถึง: 1 ขยายรายการคำโดยใช้ประโยคประโยคเพื่อฝึกอบรมและสร้างข้อมูลภาษาจีนและรวมเข้ากับรายการคำ Llama; 2. การฝึกอบรมล่วงหน้าในรายการคำศัพท์ใหม่ประมาณ 20 กรัมของคลังภาษาจีนทั่วไปได้รับการฝึกอบรมและใช้เทคโนโลยี LORA ในการฝึกอบรม 3. การใช้ Stanford Alpaca การฝึกอบรมการปรับแต่งได้ดำเนินการกับข้อมูล 51K เพื่อให้ได้ความสามารถในการสนทนา
ที่อยู่โอเพ่นซอร์สคือ: https://github.com/ymcui/chinese-llama-alpaca
เมื่อวันที่ 12 เมษายน DataBricks เปิดตัว Dolly 2.0 ซึ่งเป็นที่รู้จักกันในชื่อ LLM โอเพนซอร์สแห่งแรกของอุตสาหกรรม ชุดข้อมูลถูกสร้างขึ้นโดยพนักงาน DataBricks และเปิดแหล่งที่มาและพร้อมใช้งานเพื่อวัตถุประสงค์ทางการค้า The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
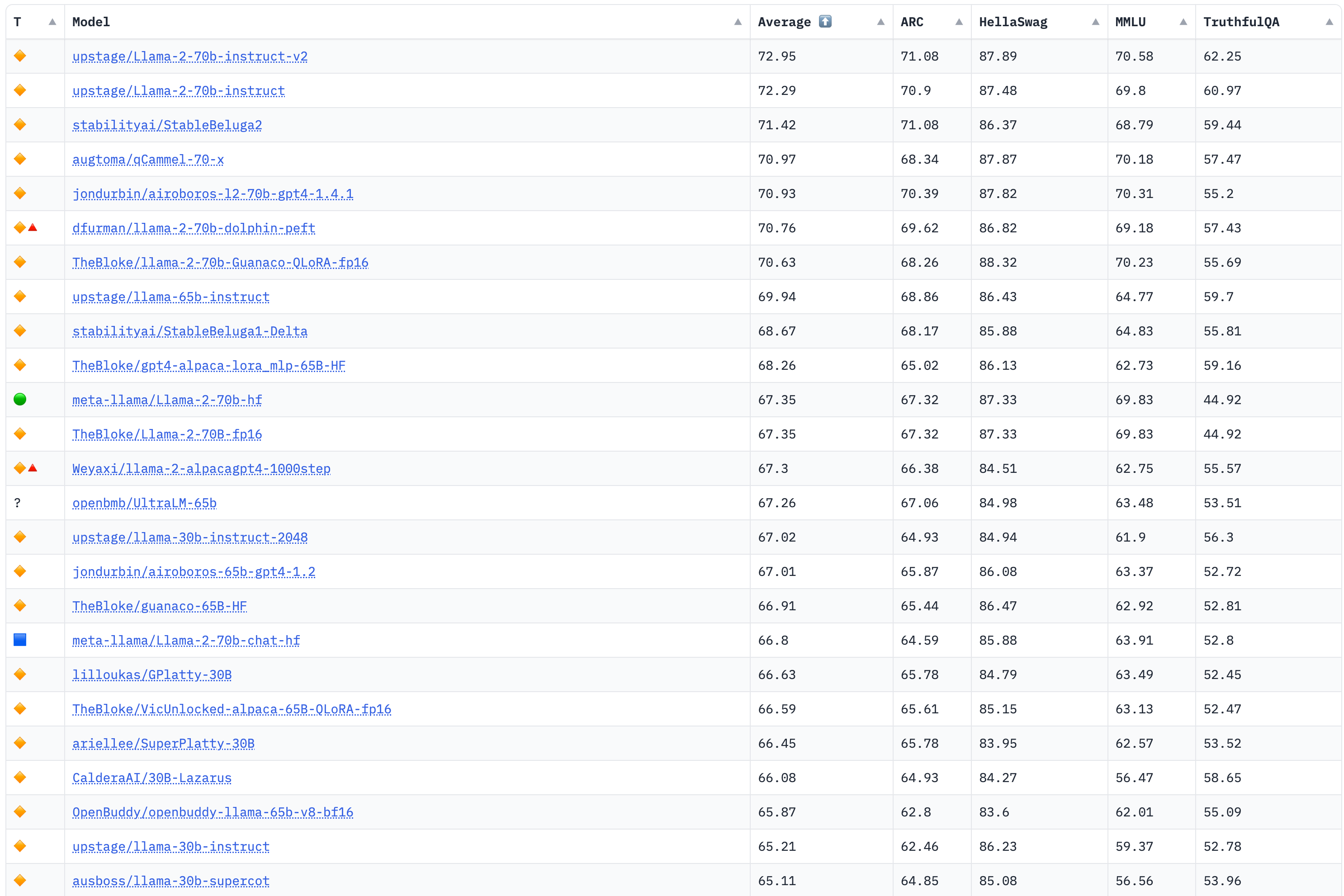
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
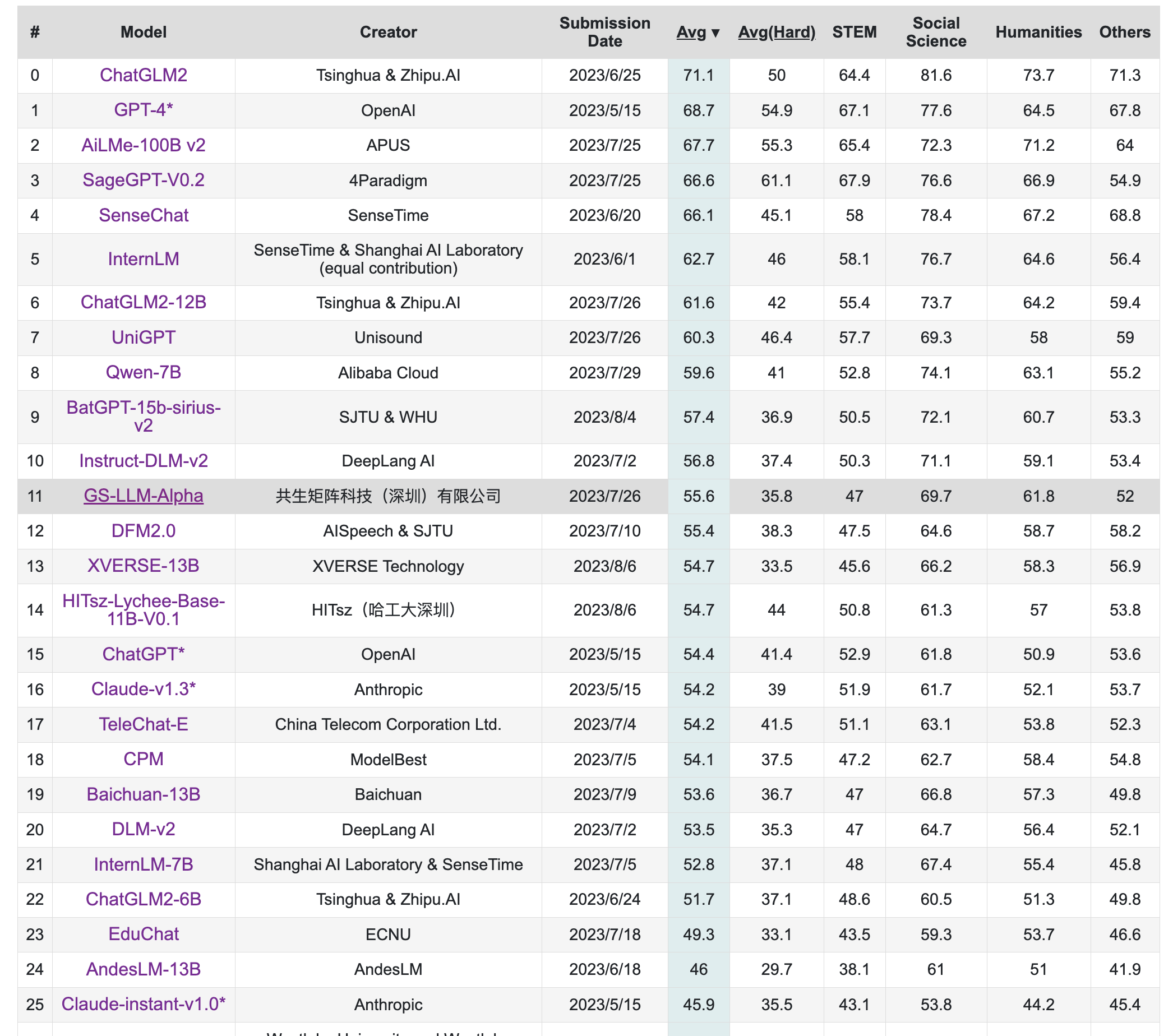
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

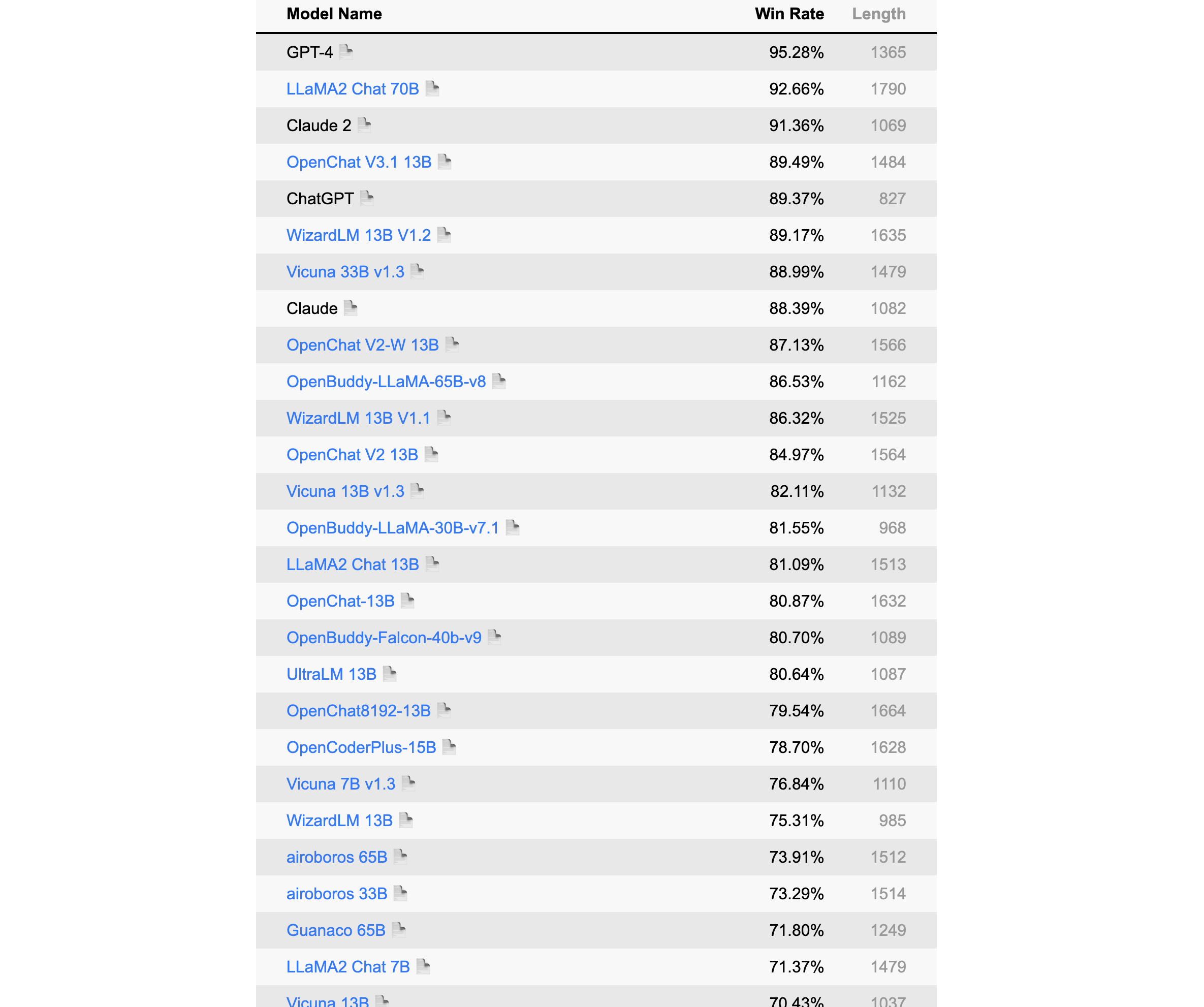
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


