FindTheChatGPTer
1.0.0
Resumen de "reemplazo simple" de código abierto de chatgpt/gpt4, actualización continua
ChatGPT se ha vuelto popular, y muchas universidades nacionales, instituciones de investigación y empresas han emitido planes de liberación similares a ChatGPT. ChatGPT no es de código abierto, y es extremadamente difícil de reproducir. Incluso ahora, ninguna unidad o empresa ha reproducido las capacidades completas de GPT3. Justo ahora, Operai anunció oficialmente el lanzamiento del modelo GPT4 con gráficos y texto multimodales, y sus capacidades se han mejorado mucho en comparación con ChatGPT. Parece que huele a la cuarta revolución industrial dominada por la inteligencia artificial general.
Ya sea en el extranjero o en casa, la brecha entre OpenAi se está haciendo cada vez más grande, y todos se están poniendo al día de una manera ocupada, por lo que están en una cierta posición ventajosa en esta innovación tecnológica. En la actualidad, la investigación y el desarrollo de muchas grandes empresas básicamente está tomando la ruta de código cerrado. Hay pocos detalles publicados oficialmente por ChatGPT y GPT4, y no es como la introducción de documento anterior que introdujo docenas de páginas, ha llegado la era de comercialización de OpenAI. Por supuesto, algunas organizaciones o individuos han explorado reemplazos de código abierto. Este artículo se resume de la siguiente manera. Continuaré rastreándolos. Hay reemplazos actualizados de código abierto para actualizar este lugar de manera oportuna.
Este tipo de método adopta principalmente los métodos que no son LLAMA y otros métodos de ajuste fino para diseñar u optimizar de forma independiente los modelos GPT y T5, y realiza procesos de ciclo completo, como la capacitación previa, el ajuste fino supervisado y el aprendizaje de refuerzo.
Chatyuan (Yuanyu AI) es desarrollado y publicado por el equipo de desarrollo inteligente Yuanyu. Afirma ser el primer modelo de diálogo funcional en China. Puede escribir artículos, hacer tareas, escribir poesía y traducir chino e inglés; Algunas áreas específicas, como las leyes, también pueden proporcionar información relevante. Este modelo actualmente solo admite el chino, y el enlace GitHub es:
https://github.com/clue-ai/chatyuan
A juzgar por los detalles técnicos revelados, la capa subyacente adopta un modelo T5 con una escala de 700 millones de parámetros, y supervisa y ajustes finos basados en Preclue para formar Chatyuan. Este modelo es básicamente el primer paso de la ruta técnica CHATGPT de tres pasos, y no se implementan capacitación en modelo de recompensa y capacitación en aprendizaje de refuerzo PPO.
Recientemente, Colossalai Open Source su implementación de chatgpt. Comparta su estrategia de tres pasos e implementa completamente la ruta técnica del núcleo de chatgpt: su github es el siguiente:
https://github.com/hpcaitech/colossalai
Según este proyecto, he aclarado la estrategia de tres pasos y la compartí:
La primera etapa (etapa1_sft.py): la etapa de ajuste de supervisión SFT, el proyecto de código abierto no se implementó, esto es relativamente simple porque Colossalai admite sin problemas Huggingface. Utilizo directamente algunas líneas de la función de entrenador de Code of Huggingface para implementarla fácilmente. Aquí utilicé un modelo GPT2. Desde su punto de vista de implementación, admite modelos GPT2, OPT y Bloom;
La segunda etapa (Stage2_rm.py): la etapa de entrenamiento del modelo de recompensa (RM), es decir, la parte Train_reward_Model.py en los ejemplos del proyecto;
La tercera etapa (Stage3_Ppo.py): Etapa de aprendizaje de refuerzo (RLHF), es decir, Project Train_Prompts.py
La ejecución de los tres archivos debe colocarse en el proyecto Colossalai, donde los núcleos en el código están chatgpt en el proyecto original, y cores.nn se convierte en chatgpt.models en el proyecto original.
Chatglm es un modelo de diálogo de la serie GLM de Zhipu Ai, una compañía que transforma los logros tecnológicos en Tsinghua, admite idiomas chinos e ingleses, y actualmente tiene su modelo de parámetros de 6.2 mil millones. Hereda las ventajas de GLM y optimiza la arquitectura del modelo, reduciendo así el umbral para la implementación y la aplicación, realizando la aplicación de inferencia de grandes modelos en las tarjetas gráficas de consumo. Para obtener técnicas detalladas, consulte su GitHub:
La dirección de código abierto de chatglm-6b es: https://github.com/thudm/chatglm-6b
Desde la perspectiva técnica, ha implementado el aprendizaje reforzado de ChatGPT de la estrategia de alineación humana, lo que hace que el efecto de generación sea mejor y más cercano al valor humano. Sus áreas de capacidad actuales incluyen principalmente autocognición, redacción de esquemas, redacción de redacción, asistente de escritura por correo electrónico, extracción de información, juego de roles, comparación de comentarios, asesoramiento de viajes, etc. Ha desarrollado un modelo súper grande de 130 mil millones bajo pruebas internas, que se considera un modelo de diálogo con una escala de parámetros más grande en el reemplazo de código abierto actual.
Visualglm-6b (actualizado el 19 de mayo de 2023)
El equipo abrió recientemente la versión multimodal de ChatGLM-6B, que admite el diálogo multimodal en imágenes, chinos e inglés. La parte del modelo de idioma utiliza ChatGLM-6B, y la parte de la imagen construye un puente entre el modelo visual y el modelo de lenguaje mediante la capacitación de Blip2-Qformer. El modelo general tiene un total de 7.8 mil millones de parámetros. VisualGLM-6B se basa en pares gráficos chinos de alta calidad de alta calidad del conjunto de datos COGVIEW, y se capacita previamente con pares gráficos en inglés filtrados de 300 m, con el mismo peso en chino e inglés. Este método de entrenamiento alinea mejor la información visual con el espacio semántico de Chatglm; En la etapa posterior de ajuste, el modelo está entrenado en datos visuales de preguntas y respuestas para generar respuestas que cumplan con las preferencias humanas.
Visualglm-6b La dirección de código abierto es: https://github.com/thudm/visualglm-6b
CHATGLM2-6B (actualizado el 27 de junio de 2023)
El equipo abrió recientemente la versión de segunda generación de ChatGlm de origen CHATGLM2-6B. En comparación con la versión de primera generación, sus características principales incluyen el uso de una escala de datos más grande, de 1T a 1.4T; El más destacado es su soporte de contexto más largo, que se ha expandido de 2k a 32k, lo que permite rondas de entradas más largas y más altas; Además, la velocidad de inferencia se ha optimizado en gran medida, un aumento del 42%y los recursos de memoria de video ocupados se han reducido considerablemente.
Chatglm2-6b La dirección de código abierto es: https://github.com/thudm/chatglm2-6b
Se conoce como el primer proyecto de reemplazo de CHATGPT de código abierto, y su idea básica se basa en la arquitectura de la palma de modelos Big Language de Google y el uso de métodos de aprendizaje de refuerzo (RLHF) de la retroalimentación humana. Palm es un modelo general de parámetros de 540 mil millones publicado por Google en abril de este año, basado en la capacitación del sistema Pathways. Puede completar tareas como escribir código, chat, comprensión del idioma, etc., y tiene un poderoso rendimiento de aprendizaje de baja muestra en la mayoría de las tareas. Al mismo tiempo, se adopta el mecanismo de aprendizaje de refuerzo similar a ChatGPT, lo que puede hacer que las respuestas de IA sean más en línea con los requisitos de escenario y reducir la toxicidad del modelo.
La dirección de Github es: https://github.com/lucidrains/palm-rlhf-pytorch
El proyecto se conoce como el modelo de código abierto más grande, hasta 1.5 billones, y es un modelo multimodal. Sus dominios de habilidad incluyen comprensión del lenguaje natural, traducción automática, preguntas y respuestas inteligentes, análisis de sentimientos y coincidencia gráfica, etc. Su dirección de código abierto es:
https://huggingface.co/banana-dev/gptrillion
(El 24 de mayo de 2023, este proyecto es un programa de broma del Día de los Inocentes de April. El proyecto ha sido eliminado. Lo explicaré por la presente
OpenFlamingo es un marco que compare GPT-4 y admite capacitación y evaluación de modelos multimodales a gran escala. Fue lanzado por la organización sin fines de lucro Laion y es una reproducción del modelo Flamingo de Deepmind. Actualmente Open Source es su modelo OpenFlamingo-9B basado en Llama. El modelo de flamenco está entrenado en un corpus de red a gran escala que contiene texto e imágenes entrelazados, y tiene la capacidad de aprender muestras de contexto limitado. OpenFlamingo implementa la misma arquitectura propuesta en el flamenco original, entrenado en muestras de 5 m de un nuevo conjunto de datos C4 multimodal y 10 m muestras de Laion-2B. La dirección de código abierto de este proyecto es:
https://github.com/mlfoundations/open_flamingo
El 21 de febrero de este año, la Universidad de Fudan lanzó a Moss y abrió beta pública, lo que causó cierta controversia después del colapso beta público. Ahora el proyecto ha marcado el comienzo de las actualizaciones importantes y el código abierto. El MOSS de código abierto admite idiomas chinos e ingleses, y admite complementos, como resolver ecuaciones, búsqueda, etc. Los parámetros son 16B y pretrontrados en aproximadamente 700 mil millones de palabras chinas e inglesas y de código. Las instrucciones de diálogo posteriores son ajustadas, el aprendizaje mejorado de los complementos y el entrenamiento de preferencias humanas tienen múltiples rondas de capacidades de diálogo y la capacidad de usar múltiples complementos. La dirección de código abierto de este proyecto es:
https://github.com/openlmlab/moss
Similar a Minigpt-4 y Llava, es un modelo multimodal de código abierto que comparó GPT-4, que continúa la idea de entrenamiento modular de la serie MPLUG. Actualmente abre el modelo de cantidad de parámetros 7B, y al mismo tiempo, propone un conjunto de pruebas integral Owleval por primera vez para la comprensión de las instrucciones relacionadas con la visual. A través de la evaluación manual, los modelos existentes, incluidos Llava, Minigpt-4 y otros trabajos, demuestran mejores capacidades multimodales, especialmente en la capacidad de comprensión de instrucciones multimodales, la capacidad de diálogo multi-rondas, la capacidad de razonamiento de conocimiento, etc. Es lamentable que, al igual que otros modelos gráficos y de texto, todavía solo admite inglés, pero la versión china ya está en su lista de fuente abierta.
La dirección de código abierto de este proyecto es: https://github.com/x-plug/mplug-owl
Pandalm es un modelo de evaluación de modelo que tiene como objetivo evaluar automáticamente las preferencias de otros modelos a gran escala para generar contenido, ahorrando costos de evaluación manual. Pandalm viene con una interfaz web para el análisis, y también admite llamadas de código Python. Puede evaluar el texto generado por cualquier modelo y datos con solo tres líneas de código, que es muy conveniente de usar.
La dirección de código abierto del proyecto es: https://github.com/weopenml/pandalm
En la conferencia Zhiyuan celebrada recientemente, el Instituto de Investigación Zhiyuan abrió la fuente de su modelo de Ilustración y Sky Eagle, que tiene un conocimiento bilingüe de chino e inglés. Los parámetros del modelo básico de la versión de código abierto incluyen 7 mil millones y 33 mil millones. Al mismo tiempo, abre el modelo de diálogo de Aquilachat y el modelo de generación de código de texto de quilacode, y ambos se han abierto para licencias comerciales. Aquila adopta arquitecturas de decodificadores solo como GPT-3 y LLAMA, y también actualiza el vocabulario para el bilingüismo chino e inglés, y adopta su método de entrenamiento acelerado. Su garantía de rendimiento no solo depende de la optimización y la mejora del modelo, sino que también se beneficia de la acumulación de Zhiyuan de datos de alta calidad en grandes modelos en los últimos años.
La dirección de código abierto del proyecto es: https://github.com/flagai-open/flagai/tree/master/examples/aquila
Recientemente, Microsoft ha publicado un modelo de modelo Big Modal multimodal y un código de código fuente abierto -Codi, que conecta completamente el texto de votación de texto-video, admite entrada arbitraria y salida modal arbitraria. Para lograr la generación de modalidades arbitrarias, los investigadores dividieron la capacitación en dos etapas. En la primera etapa, el autor utilizó la estrategia de alineación del puente y las condiciones combinadas para entrenar, creando un modelo de difusión potencial para cada modo; En la segunda etapa, se agregó un módulo de atención de intersección a cada modelo de difusión potencial y codificador ambiental, lo que podría proyectar las variables latentes del modelo de difusión potencial en el espacio compartido, de modo que las modalidades generadas se diversificaron aún más.
La dirección de código abierto de este proyecto es: https://github.com/microsoft/i-code/tree/main/i-code-v3
Meta ha lanzado y abierto de su gran modelo de imagen de modelo multimodal, que puede lograr una transmisión de modalidades, incluyendo imágenes, video, audio, profundidad, calor y movimiento espacial. ImageBind resuelve el problema de alineación utilizando las características de enlace de las imágenes, utilizando grandes modelos de lenguaje visual y capacidades de muestras cero para expandirse a nuevas modalidades. Los datos de emparejamiento de imágenes son suficientes para unir estos seis modos, permitiendo que diferentes modos se abran divisiones modales entre sí.
La dirección de código abierto del proyecto es: https://github.com/facebookresearch/iMagebind
El 10 de abril de 2023, Wang Xiaochuan anunció oficialmente el establecimiento de la compañía de grandes modelos de IA "Baichuan Intelligence", con el objetivo de crear una versión china de OpenAI. Dos meses después de su establecimiento, Baichuan Intelligent ha hecho una fuente importante de su modelo Baichuan-7B desarrollado de forma independiente, apoyando a los chinos e inglés. Baichuan-7B no solo supera otros modelos grandes como ChatGlm-6b con ventajas significativas en la lista de evaluación autorizada de C-EVAL, Agieval y Gaokao China, sino que también lidera significativamente LLAMA-7B en la lista de evaluación autoritaria de MMLU en inglés. Este modelo alcanza una escala de billones de tokens en datos de alta calidad, y admite la capacidad de expansión de decenas de miles de ventanas dinámicas ultra largas basadas en la optimización eficiente del operador de atención. Actualmente, el código abierto admite capacidades de contexto 4K. Este modelo de código abierto está disponible comercialmente y es más amigable que LLAMA.
La dirección de código abierto del proyecto es: https://github.com/baichuan-inc/baichuan-7b
El 6 de agosto de 2023, el equipo de Yuanxiang Xverse abrió el modelo Xverse-13B. Este modelo es un modelo multilingüe grande que admite hasta más de 40 lenguajes y admite una longitud contextual de hasta 8192. Según el equipo, las características de este modelo son: Estructura del modelo: Xverse-13b utiliza la estructura de transformador estándar de decodificador principal, respalda la longitud de contexto 8K, que es la más larga entre el mismo modelo de tamaño y puede satisfacer las necesidades de un diálogo multi-ruido más largo, el conocimiento Q & A y Summary; Datos de capacitación: 1.4 billones de tokens de datos de alta calidad y diversos se construyen para entrenar completamente el modelo, incluidos 40 chinos, inglés, ruso y occidental. Múltiples idiomas, al establecer finamente la relación de muestreo de diferentes tipos de datos, los idiomas chinos e inglés funcionan bien, y también pueden tener en cuenta los efectos de otros idiomas; Segmentación de palabras: según el algoritmo BPE, una segmentación de palabras con un tamaño de vocabulario de 100,278 fue entrenado utilizando cientos de corpus GB, que puede soportar múltiples idiomas al mismo tiempo sin expansión adicional de la lista de palabras; Marco de capacitación: desarrolló de forma independiente una serie de tecnologías clave, que incluyen operadores eficientes, optimización de memoria de video, estrategias de programación paralela, superposición de comunicación de datos, colaboración de plataforma y marco, etc., lo que hace que la eficiencia de capacitación sea más alta y estabilidad del modelo sea fuerte. La tasa de utilización de potencia informática máxima en el clúster Kilocard puede alcanzar el 58.5%, clasificando entre la vanguardia en la industria.
La dirección de código abierto de este proyecto es: https://github.com/xverse-ai/xverse-13b
El 3 de agosto de 2023, el modelo de 7 mil millones de Alibaba Tongyi Qianwen era de código abierto, incluidos modelos generales y modelos de diálogo, y es de código abierto, gratuito y comercialmente disponible. Según los informes, QWEN-7B es un modelo de lenguaje grande basado en el transformador y está entrenado en datos de pre-entrenamiento de gran escala de gran nivel. Los tipos de datos previos al entrenamiento son diversos y cubren una amplia gama de áreas, que incluyen una gran cantidad de textos en línea, libros profesionales, códigos, etc. Es un modelo de muelle que admite idiomas chinos e ingleses, capacitados en más de 2 billones de conjuntos de datos de token, y la longitud de la ventana de contexto alcanza 8K. QWEN-7B-CHAT es un modelo de diálogo chino-inglés basado en el modelo de pedestal QWEN-7B. El modelo previamente capacitado Tongyi Qianwen 7B funcionó bien en múltiples evaluaciones de referencia autorizadas. Sus capacidades chinas e inglesas exceden con creces los modelos de código abierto de la misma escala en el hogar y en el extranjero, y algunas capacidades incluso excedieron los modelos de código abierto de tamaños de 12B y 13B.
La dirección de código abierto del proyecto es: https://github.com/qwenlm/qwen-7b
Llama es un nuevo modelo de lenguaje de inteligencia artificial a gran escala publicado por Meta, que funciona bien en tareas como generar texto, diálogo, resumir materiales escritos, probar teoremas matemáticos o predecir estructuras de proteínas. El modelo LLAMA admite 20 idiomas, incluidos los idiomas alfabéticos latinos y cirílicos. Actualmente, el modelo original no es compatible con el chino. Se puede decir que la fuga épica de LLAMA ha promovido vigorosamente el desarrollo de código abierto de ChatGPT.
(Actualizado el 22 de abril de 2023) Pero desafortunadamente, la autorización de LLAMA actualmente es limitada y solo puede usarse para la investigación científica y no se permite el uso comercial. Para resolver el problema comercial de código completo, surgió el proyecto Redpajama, con el objetivo de crear una réplica de código de código abierto de LLAMA que pueda usarse para aplicaciones comerciales y proporcionar un proceso más transparente para la investigación. El RedPajama completo incluye un conjunto de datos de tokens de 1.2 billones, y su próximo paso será comenzar el entrenamiento a gran escala. Todavía vale la pena esperar este trabajo, y su dirección de código abierto es:
https://github.com/TogeterComputer/redpajama-data
(Actualizado el 7 de mayo de 2023)
Redpajama actualizó su archivo de modelo de entrenamiento, incluidos dos parámetros: 3B y 7B, donde 3B puede ejecutarse en la tarjeta de gráficos RTX2070 Gaming lanzada hace 5 años, lo que compensa la brecha en LLAMA en 3B. Su dirección de modelo es:
https://huggingface.co/TogeterComuter
Además de Redpajama, MosaicML ha lanzado el modelo de la serie MPT, y sus datos de entrenamiento utilizan datos de Redpajama. En varias evaluaciones de rendimiento, el modelo 7B es comparable a la llama original. La dirección de código abierto de su modelo es:
https://huggingface.co/mosaicml
Ya sea RedPajama o MPT, también abre el código de código de chat correspondiente. El código abierto de estos dos modelos ha llevado un gran impulso a la comercialización de ChatGPT.
(Actualizado el 1 de junio de 2023)
Falcon es una gran base de modelo abierto que compara el llamado. Tiene dos escalas de medición de parámetros: 7b y 40b. El rendimiento de 40B se conoce como la Llama 65B Ultra High. Se entiende que Falcon todavía usa el modelo de decodificadores Autorregresses GPT, pero ha puesto mucho esfuerzo en los datos. Después de raspar el contenido de la red pública y construir el conjunto de datos inicial previamente practicado, utiliza el volcado CommonCrawl para realizar un filtrado a gran escala y una deduplicación a gran escala, y finalmente obtiene un enorme conjunto de datos previos a la pretrada compuesto por casi 5 billones de tokens. Al mismo tiempo, se han agregado muchos corpus seleccionados, incluidos trabajos de investigación y conversaciones en las redes sociales. Sin embargo, la autorización del proyecto ha sido controvertida, y se adopta el método de autorización "semi-comercial", y el 10% de los gastos comerciales comenzarán a ocurrir después de que el ingreso alcance 1 millón.
La dirección de código abierto del proyecto es: https://huggingface.co/tiiuae
(Actualizado el 3 de julio de 2023)
El Halcón original carece de capacidades de apoyo chino como Llama. El equipo del proyecto "Linly" construyó y abrió la versión china de China-Falcon basada en el modelo Falcon. El modelo primero amplió y amplió en gran medida la lista de vocabulario, incluidos 8701 caracteres chinos comúnmente utilizados, las primeras 20,000 palabras chinas de alta frecuencia en la lista de vocabulario de Jieba y 60 signos de puntuación chinos. Después de la deduplicación, el tamaño de la lista de vocabulario se amplió a 90,046. Durante la fase de entrenamiento, se utilizaron datos de 50G Corpus y 2T a gran escala para el entrenamiento.
La dirección de código abierto del proyecto es: https://github.com/cvi-szu/linly
(Actualizado el 24 de julio de 2023)
El Halcón original carece de capacidades de apoyo chino como Llama. El equipo del proyecto "Linly" construyó y abrió la versión china de China-Falcon basada en el modelo Falcon. El modelo primero amplió y amplió en gran medida la lista de vocabulario, incluidos 8701 caracteres chinos comúnmente utilizados, las primeras 20,000 palabras chinas de alta frecuencia en la lista de vocabulario de Jieba y 60 signos de puntuación chinos. Después de la deduplicación, el tamaño de la lista de vocabulario se amplió a 90,046. Durante la fase de entrenamiento, se utilizaron datos de 50G Corpus y 2T a gran escala para el entrenamiento.
La dirección de código abierto del proyecto es: https://github.com/cvi-szu/linly
El Alpaca (modelo Alpaca) lanzado por Stanford es un nuevo modelo basado en el modelo LLAMA-7B. El principio básico es permitir que el modelo de texto de OpenAI-Davinci-003 genere 52k muestras de instrucciones de manera autoestructura para ajustar la llama. El proyecto ha abierto datos de capacitación de origen, código para generar datos de capacitación e hiperparámetros. El archivo modelo aún no se ha abierto, llegando a más de 5.6k estrellas en un día. Este trabajo es muy popular debido a su bajo costo y acceso fácil de datos, y también ha abierto el camino a la imitación de ChatGPT de bajo costo. Su dirección de GitHub es:
https://github.com/tatsu-lab/stanford_alpaca
Es una implementación de código abierto del chatbot LLAMA+AI basado en el aprendizaje de refuerzo de retroalimentación humana lanzada por Nebuly+AI. Su ruta técnica es similar a ChatGPT. El proyecto acaba de lanzarse durante 2 días y ha ganado 5.2k estrellas. Su dirección de GitHub es:
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelate/chatllama
El algoritmo de proceso de entrenamiento de Chatllama se utiliza principalmente para lograr una capacitación más rápida y barata que ChatGPT. Se dice que es casi 15 veces más rápido. Las características principales son:
Una implementación completa de código abierto permite a los usuarios crear servicios de estilo CHATGPT basados en modelos de llama pretrados;
La arquitectura de llamas es más pequeña, lo que hace que el proceso de capacitación y el razonamiento sean más rápido y menos costoso;
Soporte incorporado para Deepspeed Zero para acelerar el proceso de ajuste fino;
Admite arquitecturas de modelos de LLAMA de varios tamaños, y los usuarios pueden ajustar el modelo de acuerdo con sus propias preferencias.
OpenChatkit es creado conjuntamente por el equipo juntos, donde se encuentran los ex investigadores de Operai, así como los equipos de Laion y Ontocord.ai. OpenChatkit contiene 20 mil millones de parámetros y está ajustado con la versión de código abierto de GPT-3 GPT-NOX-20B. Al mismo tiempo, el aprendizaje de refuerzo diferente de los chatgpts, OpenChatkit utiliza un modelo de auditoría de parámetros de 6 mil millones para filtrar información inapropiada o dañina para garantizar la seguridad y la calidad del contenido generado. Su dirección de GitHub es:
https://github.com/TogeterComputer/openchatkit
Basado en Stanford Alpaca, el ajuste superior supervisado se realiza en base a Bloom y Llama. Las tareas de semillas de Stanford Alpaca están en inglés, y los datos recopilados también están en inglés. Este proyecto de código abierto es promover el desarrollo de la comunidad de código abierto del gran diálogo chino. Ha sido optimizado para los chinos. La sintonización del modelo solo utiliza datos producidos por ChatGPT (sin incluir ningún otro datos). El proyecto contiene lo siguiente:
175 misiones de semillas chinas
Código para generar datos
Los datos generados por 10m están actualmente abiertos con un código de origen de 1,5 m, 0,25 m conjuntos de datos de instrucciones matemáticas y conjuntos de datos de diálogo de tareas multi-rondas de 0,8 m.
Modelo optimizado basado en Bloomz-7B1-MT y Llama-7B
La dirección de Github es: https://github.com/lianjiatech/belle
Alpaca-Lora es otra obra maestra de la Universidad de Stanford. Utiliza la tecnología Lora (adaptación de bajo rango) para reproducir los resultados de la alpaca, utilizando un método de menor costo, y solo entrenado en una tarjeta gráfica RTX 4090 durante 5 horas para obtener un modelo con un nivel de alpaca. Además, el modelo puede ejecutarse en una Raspberry Pi. En este proyecto, utiliza Hugging Face's Peft para un ajuste fino barato y eficiente. PEFT es una biblioteca (Lora es una de sus tecnologías compatibles) que le permite usar una variedad de modelos de lenguaje basados en transformadores y ajustarlos con Lora, lo que permite ajustar el modelo de hardware general económico y eficiente. La dirección de GitHub de este proyecto es:
https://github.com/tloen/alpaca-lora
Aunque Alpaca y Alpaca-Lora han hecho un gran progreso, sus tareas de semillas están en inglés y carecen de apoyo para los chinos. Por un lado, además de lo mencionado anteriormente, Belle ha recolectado una gran cantidad de corpus chino, por otro lado, basado en el trabajo de predecesores como Alpaca-lora, el modelo de idioma chino Luotuo (Luotuo) abierto de tres desarrolladores individuales de la Universidad Normal de China Central y otras instituciones, una sola tarjeta puede completar el despliegue de entrenamiento. Actualmente, el proyecto libera dos modelos Luotuo-Lora-7b-0.1, Luotuo-Lora-7b-0.3, y un modelo está en el plan. Su dirección de GitHub es:
https://github.com/lc1332/chinese-alpaca-lora
Inspirado en Alpaca, Dolly utilizó el conjunto de datos Alpaca para lograr el ajuste fino en GPT-J-6B. Dado que Dolly en sí es un "clon" de un modelo, el equipo finalmente decidió nombrarlo "Dolly". Inspirado en Alpaca, este método de clonación se está volviendo cada vez más popular. En resumen, se adopta aproximadamente el método de adquisición de datos de código abierto de Alpaca e instrucciones de ajuste fino en modelos antiguos de tamaño 6B o 7B para lograr efectos similares a ChatGPT. Esta idea es muy económica y puede imitar rápidamente el encanto de ChatGPT. Es muy popular y una vez que se lanzó, está lleno de estrellas. La dirección de GitHub de este proyecto es:
https://github.com/databrickslabs/dolly
Después de lanzar Alpaca, Stanford Scholars se asociaron con CMU, UC Berkeley, etc. para lanzar un nuevo modelo: Vicuna con 13 mil millones de parámetros (comúnmente conocidos como Alpaca y Llama). Solo cuesta $ 300 para lograr un rendimiento del 90% de ChatGPT. Vicuna se usa para ajustar la llama en el diálogo compartido de usuarios recopilado por ShareGPT. El proceso de prueba utiliza GPT-4 como criterios de evaluación. Los resultados muestran que Vicuna-13B alcanza las capacidades que coinciden con ChatGPT y Bard en más del 90% de los casos.
UC Berkeley LMSys Org lanzó recientemente Vicuna con 7 mil millones de parámetros. No solo es pequeño en tamaño, alta eficiencia y capacidad fuerte, sino que también puede ejecutarse en una Mac con chip M1/M2 en solo dos líneas de comando, ¡y también puede habilitar la aceleración de GPU!
La dirección de código abierto de GitHub es: https://github.com/lm-sys/fastchat/
Otra versión china ha sido abierta por chino-vicuna, con la dirección de GitHub como:
https://github.com/facico/chinese-vicuna
Después de que ChatGPT se hizo popular, la gente estaba buscando una manera rápida al templo. Comenzaron a aparecer algunas apariciones similares a ChatGPT, especialmente después de ChatGPT a un bajo costo se ha convertido en una forma popular. LMFlow es un producto nacido en este escenario de demanda, que permite que los grandes modelos se refinen en tarjetas gráficas ordinarias como 3090. El proyecto fue iniciado por la Universidad de Ciencia y Estadísticas de Tecnología de Hong Kong y el equipo de Laboratorio de Aprendizaje Machine de Hong Kong, y está comprometido a establecer una gran plataforma de investigación de modelos completamente abiertos en la plataforma que respalda la plataforma de la plataforma, y mejora los métodos de uso de datos existentes y la optimización de la optimización a los Algorización de la plataforma en la plataforma, la plataforma de la plataforma, la plataforma de la plataforma, la plataforma de la plataforma bajo la plataforma de la plataforma. Sistema de entrenamiento de modelos más grande que es más eficiente que los métodos anteriores.
Usando este proyecto, incluso los recursos informáticos limitados pueden permitir a los usuarios apoyar la capacitación personalizada para campos propietarios. Por ejemplo, Llama-7B, un 3090 tarda 5 horas en completar el entrenamiento, lo que reduce en gran medida el costo. El proyecto también abre el servicio de preguntas y respuestas de experiencia instantánea del lado web (lmflow.com). El surgimiento y el código abierto de LMFlow permiten que los recursos ordinarios capaciten diversas tareas, como preguntas y respuestas, compañía, escritura, traducción, consulta de campo experto, etc. Muchos investigadores están tratando de utilizar este proyecto para capacitar a grandes modelos con un volumen de parámetros de 65 mil millones o incluso más.
La dirección de GitHub de este proyecto es:
https://github.com/optimalscale/lmflow
El proyecto propone un método para recopilar automáticamente las conversaciones de CHATGPT, permitiendo que el chatGPT se auto terminee, genere datos de diálogos de alta calidad de ronda de alta calidad y recolecte alrededor de 50,000 corpus de preguntas y respuestas de alta calidad de Quora, Stackoverflow y Medqa, respectivamente, y ha sido de origen abierto. Al mismo tiempo, mejoró el modelo de llama y el efecto es bastante bueno. Bai Ze también adoptó la solución actual de ajuste fino de Lora de bajo costo para obtener tres escalas diferentes: Bai ZE-7B, 13B y 30B, así como un modelo en el campo vertical de la atención médica. Desafortunadamente, el nombre chino está bien nombrado, pero aún no es compatible con los chinos. Según los informes, el modelo chino Bai Ze está bajo el plan y se publicará en el futuro. Su dirección GitHub de código abierto es:
https://github.com/project-baize/baize
El reemplazo plano de ChatGPT, con sede en Llama, continúa fermentando, Berkeley de UC Berkeley ha lanzado un modelo de conversación Koala que puede ejecutarse en GPU de consumo con parámetros de 13b. El conjunto de datos de capacitación de Koala incluye las siguientes partes: Datos de CHATGPT y datos de código abierto (generalista de instrucciones abiertas (OIG), conjunto de datos utilizado por el modelo Stanford Alpaca, antrópico HH, OpenAi WebGPT, resumen de OpenAI). El modelo Koala se implementa en Easylm usando Jax/Flax, utilizando 8 GPU A100, y tarda 6 horas en completar 2 iteraciones. El efecto de evaluación es mejor que la alpaca, logrando un rendimiento del 50% de ChatGPT.
Dirección de código abierto: https://github.com/young-geng/easylm
Con el advenimiento de Stanford Alpaca, una gran cantidad de familias de alpaca basadas en LLAMA y familias de animales extendidas comenzaron a surgir, y finalmente, abrazando a los investigadores de la cara recientemente publicó un blog Stackllama: A Practical Guide to Training Llama con RLHF. Al mismo tiempo, también se lanzó un modelo de parámetros de 7 mil millones: Stackllama. Este es un modelo ajustado en LLAMA-7B a través del aprendizaje de refuerzo de retroalimentación humana. Para más detalles, consulte su dirección de blog:
https://huggingface.co/blog/stackllama
El proyecto optimiza la LLAMA para chino y abre su sistema de diálogo ajustado. Los pasos específicos de este proyecto incluyen: 1. Expandir la lista de palabras, usando la pieza de oración para entrenar y construir en datos chinos, y fusionarse con la lista de palabras de LLAMA; 2. Prerreining, en la nueva lista de palabras, se capacitó alrededor de 20 g de Corpus General Chino, y la tecnología Lora se utilizó en la capacitación; 3. Usando Stanford Alpaca, el entrenamiento de ajuste fino se realizó en datos 51K para obtener la capacidad de diálogo.
La dirección de código abierto es: https://github.com/ymcui/chinese-llama-alpaca
El 12 de abril, Databricks lanzó Dolly 2.0, conocido como el primer código abierto de la industria, LLM compatible con la directiva. El conjunto de datos fue generado por los empleados de Databricks y fue de origen abierto y disponible para fines comerciales. The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
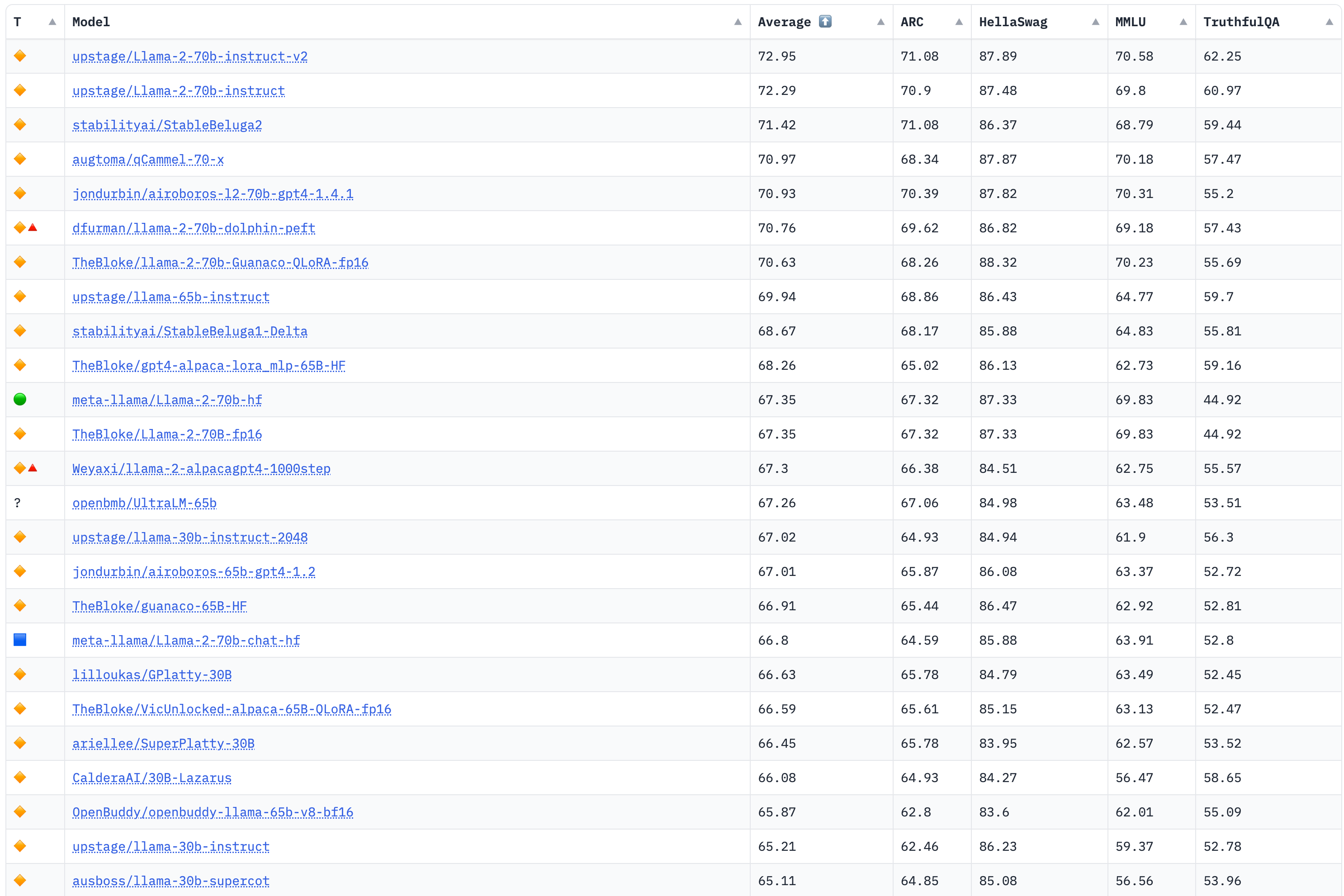
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
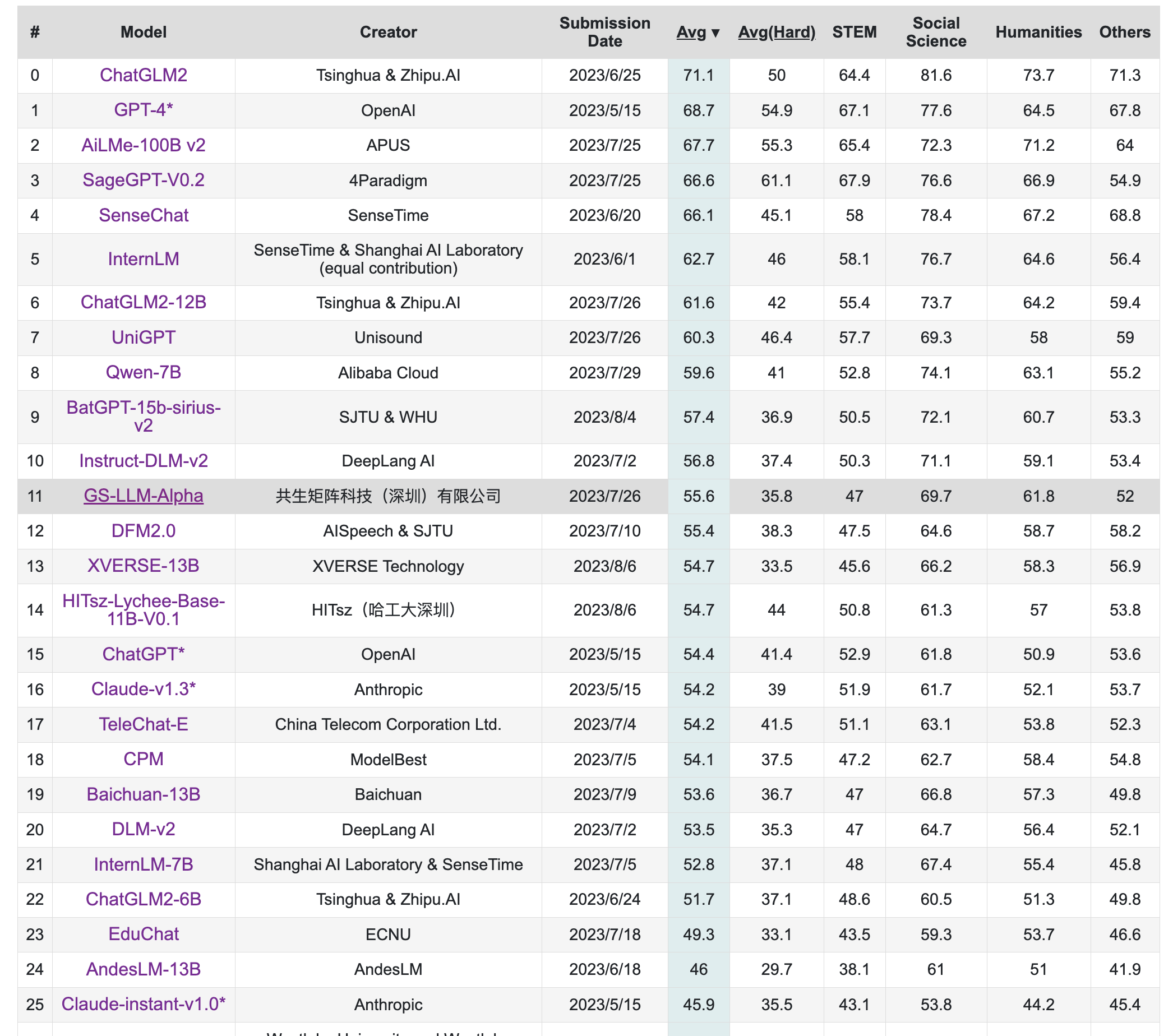
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

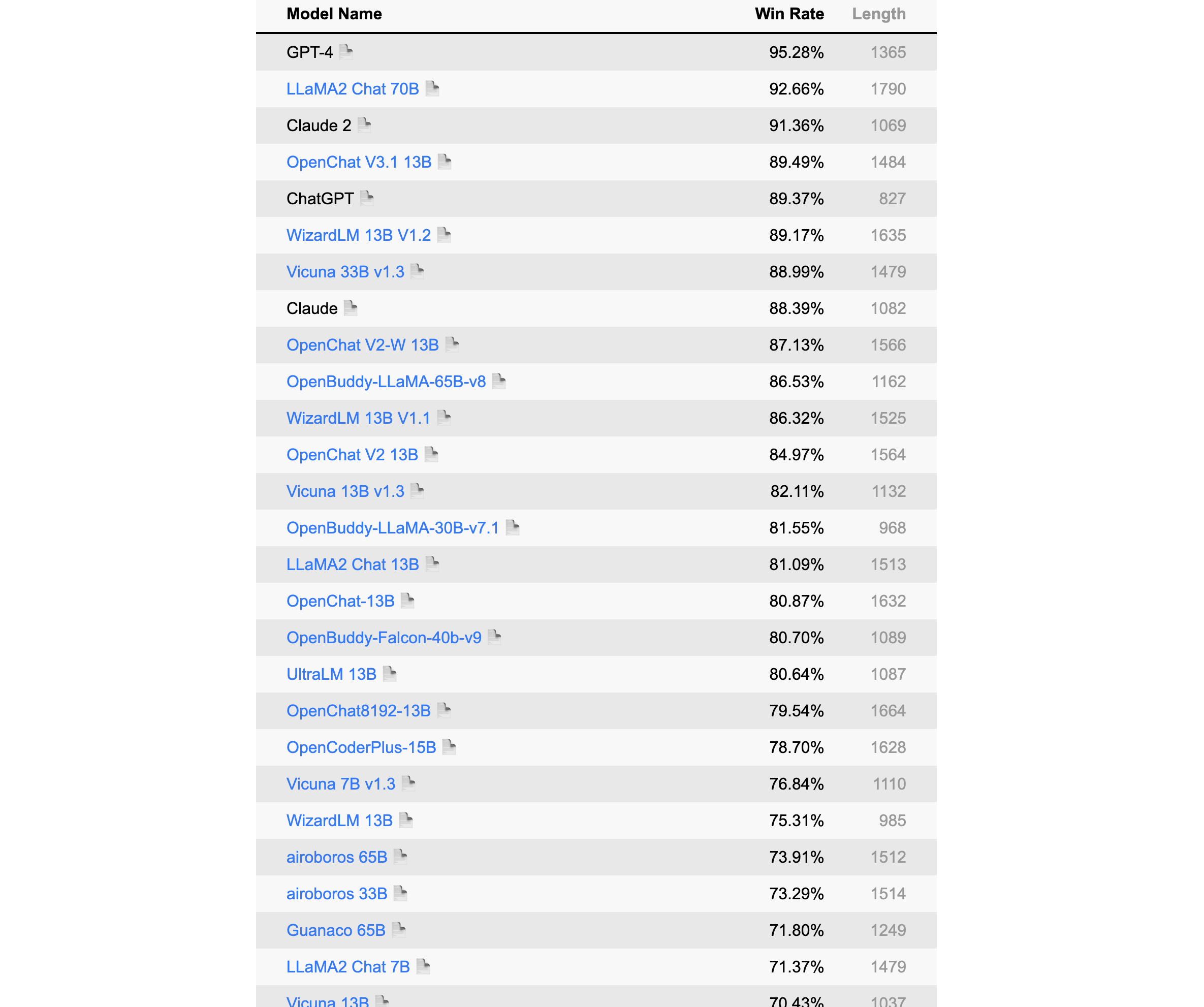
该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


