FindTheChatGPTer
1.0.0
chatgpt/gpt4オープンソース「プレーン交換」概要、継続的な更新
ChatGptは人気が高まっており、多くの国内の大学、研究機関、企業がChatGptと同様のリリースプランを発行しています。 ChatGptはオープンソースではなく、再現することは非常に困難です。今でも、GPT3の完全な機能を複製したユニットやエンタープライズはありません。ちょうど今、Openaiはマルチモーダルグラフィックとテキストを備えたGPT4モデルのリリースを正式に発表しました。その機能はChatGPTと比較して大幅に改善されています。一般的な人工知能が支配する第4産業革命の匂いがするようです。
海外であろうと自宅であろうと、Openai間のギャップはますます大きくなり、誰もが忙しい方法で追いついているので、この技術革新で特定の有利な立場にあります。現在、多くの大企業の研究開発は、基本的に閉鎖ルートを取っています。 ChatGPTとGPT4によって公式にリリースされた詳細はほとんどありません。数十ページを導入した以前の論文の紹介とは違います。Openaiの商業化の時代が到着しました。もちろん、一部の組織や個人は、オープンソースの代替品を調査しています。この記事は次のように要約されています。私はそれらを追跡し続けます。この場所をタイムリーに更新するための更新されたオープンソースの交換があります。
このタイプの方法は、主に非ラマおよびその他の微調整方法を採用して、GPTおよびT5モデルを独立して設計または最適化し、トレーニング前、監視された微調整、強化学習などのフルサイクルプロセスを実現します。
Chatyuan(Yuanyu AI)は、Yuanyu Intelligent Developmentチームによって開発および公開されています。それは、中国で最初の機能的対話モデルであると主張しています。記事を書いたり、宿題をしたり、詩を書いたり、中国語と英語を翻訳したりできます。法律などの特定の領域には、関連情報も提供できます。このモデルは現在、中国語のみをサポートしており、GitHubリンクは次のとおりです。
https://github.com/clue-ai/chatyuan
開示された技術的詳細から判断すると、基礎となる層は、7億パラメーターのスケールを持つT5モデルを採用し、PromptClueに基づいてChatyuanを形成する監督と微調整を採用しています。このモデルは基本的に3段階のChatGPTテクニカルルートの最初のステップであり、報酬モデルトレーニングとPPO補強学習トレーニングは実装されていません。
最近、ColossalaiのオープンソースChatGpt実装。 3段階の戦略を共有し、ChatGpt Coreの技術的ルートを完全に実装します。そのgithubは次のとおりです。
https://github.com/hpcaitech/colossalai
このプロジェクトに基づいて、私は3段階の戦略を明確にし、それを共有しました。
最初の段階(Stage1_sft.py):SFT監督の微調整段階では、オープンソースプロジェクトは実装されていません。これは、ColossalaiがHuggingfaceをシームレスにサポートするため、比較的簡単です。 Huggingfaceのトレーナー機能のコードを数行使用して簡単に実装します。ここでは、GPT2モデルを使用しました。実装の観点から、GPT2、Opt、Bloomモデルをサポートします。
第2段階(Stage2_rm.py):報酬モデル(RM)トレーニング段階、つまりプロジェクトの例のtrain_reward_model.pyパーツ。
第3段階(stage3_ppo.py):補強学習(RLHF)段階、つまりProject Train_prompts.py
3つのファイルの実行は、コロサライのコアが元のプロジェクトのChatGPTであるColossalaiプロジェクトに配置する必要があり、cores.nnは元のプロジェクトのchatgpt.modelsになります。
ChatGlmは、Tsinghuaのテクノロジーの成果を変革し、中国語と英語をサポートし、現在62億パラメーターモデルを持っているZhipu AIのGLMシリーズの対話モデルです。 GLMの利点を継承し、モデルアーキテクチャを最適化するため、展開とアプリケーションのしきい値を下げて、消費者グラフィックスカードに対する大きなモデルの推論アプリケーションを実現します。詳細な手法については、そのgithubを参照してください。
chatglm-6bのオープンソースアドレスは、https://github.com/thudm/chatglm-6bです
技術的な観点からは、人間の整合戦略のChatGpt強化学習を実装し、生成効果をより良く、人間の価値に近づけました。現在の能力分野には、主に自己認知、概要の執筆、コピーライティング、電子メールライティングアシスタント、情報抽出、ロールプレイング、コメント比較、旅行アドバイスなどが含まれます。これは、現在のオープンソース交換におけるより大きなパラメータースケールを持つダイアログモデルと見なされる内部テストの下で1,300億の超大規模モデルを開発しました。
VisualGlm-6B(2023年5月19日に更新)
チームは最近、ChatGlm-6Bのマルチモーダルバージョンをオープンしました。これは、中国語と英語の画像のマルチモーダルダイアログをサポートしています。言語モデルパーツはChatGlm-6Bを使用し、画像部分はBlip2-QFormerをトレーニングすることにより、視覚モデルと言語モデルの間にブリッジを構築します。モデル全体には合計78億パラメーターがあります。 VisualGlm-6Bは、CogViewデータセットから30mの高品質の中国のグラフィックペアに依存しており、300mのフィルター処理された英語のグラフィックペアで事前に訓練されており、中国語と英語が同じです。このトレーニング方法は、視覚情報をChatGlmのセマンティックスペースに適切に調整します。その後の微調整段階では、モデルは長い視覚的な質問と回答のデータでトレーニングされ、人間の好みを満たす回答を生成します。
VisualGlm-6Bオープンソースアドレスはhttps://github.com/thudm/visualglm-6bです
chatglm2-6b(2023年6月27日に更新)
チームは最近、ChatGlmの第2世代バージョンのChatGlm2-6Bを開設しました。第1世代のバージョンと比較して、その主な機能には、1Tから1.4Tまでのより大きなデータスケールの使用が含まれます。最も顕著なのは、より長いコンテキストサポートであり、2Kから32Kに拡大し、より長くてより高いラウンドの入力を可能にします。さらに、推論速度が大幅に最適化され、42%の増加があり、占有されたビデオメモリリソースが大幅に削減されました。
chatglm2-6bオープンソースアドレスはhttps://github.com/thudm/chatglm2-6bです
これは、最初のオープンソースChatGPT代替プロジェクトとして知られており、その基本的なアイデアは、Google言語のビッグモデルPalmアーキテクチャと、人間のフィードバックからの強化学習方法(RLHF)の使用に基づいています。 Palmは、Pathways System Trainingに基づいて、今年4月にGoogleがリリースした5,400億パラメーターオールアラウンドモデルです。コードの作成、チャット、言語理解などのタスクを完了し、ほとんどのタスクで強力な低サンプル学習パフォーマンスを備えています。同時に、CHATGPTのような強化学習メカニズムが採用されているため、AIの答えがシナリオ要件に沿ってより多くの回答をもたらし、モデルの毒性を軽減できます。
Githubアドレスは:https://github.com/lucidrains/palm-rlhf-pytorchです
このプロジェクトは、最大のオープンソースモデル、最大1.5兆個のモデルとして知られており、マルチモーダルモデルです。その能力ドメインには、自然言語の理解、機械の翻訳、インテリジェントな質問と回答、センチメント分析、グラフィックマッチングなどが含まれます。そのオープンソースアドレスは次のとおりです。
https://huggingface.co/banana-dev/gptrillion
(2023年5月24日、このプロジェクトはエイプリルフールの日のジョークプログラムです。プロジェクトは削除されました。ここで説明します。
OpenFlamingoは、GPT-4をベンチマークするフレームワークであり、大規模なマルチモーダルモデルのトレーニングと評価をサポートしています。非営利のLaionによってリリースされ、DeepmindのFlamingoモデルの複製です。現在、オープンソースは、LlamaベースのOpenFlamingo-9Bモデルです。フラミンゴモデルは、インターレースのテキストと画像を含む大規模なネットワークコーパスでトレーニングされており、コンテキストに制限されたサンプルを学習する機能を備えています。 OpenFlamingoは、元のフラミンゴで提案された同じアーキテクチャを実装し、新しいマルチモーダルC4データセットから5MサンプルとLAION-2Bの10Mサンプルで訓練されています。このプロジェクトのオープンソースアドレスは次のとおりです。
https://github.com/mlfoundations/open_flamingo
今年の2月21日、フダン大学はモスをリリースし、パブリックベータ版をオープンしました。現在、このプロジェクトは重要な更新とオープンソースを案内しています。オープンソースのモスは、中国語と英語の両方をサポートし、方程式、検索などの解決などのプラグインズ化をサポートします。パラメーターは16Bで、約7,000億の中国語および英語とコードワードで事前に訓練されています。その後のダイアログの指示は微調整されており、プラグインの拡張学習と人間の好みのトレーニングには、複数のダイアログ機能と複数のプラグインを使用する機能があります。このプロジェクトのオープンソースアドレスは次のとおりです。
https://github.com/openlmlab/moss
Minigpt-4とLlavaと同様に、MPLUGシリーズのモジュールトレーニングアイデアを継続するオープンソースマルチモーダルモデルベンチマークGPT-4です。現在、7Bパラメーター数量モデルを開き、同時に、視覚関連の指導の理解のために包括的なテストセットOwlevalを初めて提案しています。手動評価を通じて、LLAVA、MINIGPT-4およびその他の作業を含む既存のモデルは、特にマルチモーダルの指導の理解能力、マルチラウンドの対話能力、知識推論能力などでより良いマルチモーダル機能を示します。
このプロジェクトのオープンソースアドレスは、https://github.com/x-plug/mplug-owlです
Pandalmは、他の大規模モデルの好みを自動的に評価してコンテンツを生成し、手動評価コストを節約することを目的とするモデル評価モデルです。 Pandalmには、分析用のWebインターフェイスが付属しており、Pythonコードコールもサポートしています。 3行のコードのみでモデルとデータによって生成されたテキストを評価できます。これは、使用するのに非常に便利です。
プロジェクトのオープンソースアドレスは、https://github.com/weopenml/pandalmです
最近開催されたZhiyuan Conferenceで、Zhiyuan Research Instituteは、中国語と英語に関するバイリンガルの知識を持っている啓発およびSky Eagleモデルの源泉を開設しました。オープンソースバージョンの基本モデルパラメーターには、70億と330億が含まれています。同時に、Aquilachatダイアログモデルとキラコードテキストコード生成モデルを開き、両方とも商業ライセンスのために開かれています。 Aquilaは、GPT-3やLlamaなどのデコーダーのみのアーキテクチャを採用し、中国と英語のバイリンガリズムの語彙を更新し、加速トレーニング方法を採用しています。そのパフォーマンス保証は、モデルの最適化と改善に依存するだけでなく、近年の大規模モデルでの高品質のデータのZhiyuanの蓄積の恩恵も恩恵を受けています。
プロジェクトのオープンソースアドレスは、https://github.com/flagai-open/flagai/tree/master/examples/aquilaです
最近、Microsoftは、Multi-Modal Big Model PaperとOpen Source Code-Codiを公開しました。これは、Text-Voice-Image-Videoを完全に接続し、任意の入力と任意のモーダル出力をサポートしています。 arbitrary意的なモダリティの生成を達成するために、研究者はトレーニングを2つの段階に分割しました。最初の段階では、著者はブリッジアライメント戦略と条件を組み合わせてトレーニングし、各モードの潜在的な拡散モデルを作成しました。第2段階では、各潜在的な拡散モデルと環境エンコーダーに交差点の注意モジュールが追加され、潜在的な拡散モデルの潜在変数を共有空間に投影できるため、生成されたモダリティがさらに多様化されました。
このプロジェクトのオープンソースアドレスは、https://github.com/microsoft/i-code/tree/main/i-code-v3です
Metaは、画像、ビデオ、オーディオ、深さ、熱、空間モーションを含む6つのモダリティを越えることができるマルチモーダルのビッグモデルImageBindを発売して調達しました。 ImageBindは、画像の結合特性を使用して、大きな視覚言語モデルとゼロサンプル機能を使用して新しいモダリティに拡張することにより、アライメント問題を解決します。画像ペアリングデータは、これらの6つのモードを結合するのに十分であり、さまざまなモードが互いにモーダルスプリットを開くことができます。
プロジェクトのオープンソースアドレスは、https://github.com/facebookresearch/imagebindです
2023年4月10日、王Xiaochuanは、中国語版のOpenaiを作成することを目指して、AI Big Model Company「Baichuan Intelligence」の設立を公式に発表しました。設立から2か月後、Baichuan Intelligentは、中国語と英語をサポートする独立して開発されたBaichuan-7Bモデルの主要な源泉を作りました。 Baichuan-7Bは、CHATGLM-6Bなどの他の大きなモデルを、C-Val、Agieval、およびGaokaoの中国の権威ある評価リストに大きな利点を持っているだけでなく、MMLU英語の権威ある評価リストでLLAMA-7Bを大幅にリードしています。このモデルは、高品質のデータで1兆個のトークンスケールに到達し、効率的な注意オペレーターの最適化に基づいて、数万の超長ダイナミックウィンドウの拡張機能をサポートします。現在、オープンソースは4Kコンテキスト機能をサポートしています。このオープンソースモデルは市販されており、ラマよりも友好的です。
プロジェクトのオープンソースアドレスは、https://github.com/baichuan-inc/baichuan-7bです
2023年8月6日、Yuanxiangの能力チームがvsverse-13bモデルを開きました。このモデルは、最大40以上の言語をサポートし、最大8192までのコンテキスト長をサポートする多言語の大型モデルです。チームによると、このモデルの機能は次のとおりです。モデル構造:vsverse-13Bは主流のデコーダーのみの標準トランス構造を使用し、8Kコンテキストの長さをサポートします。トレーニングデータ:40人の中国語、英語、ロシア語、西部を含むモデルを完全にトレーニングするために、1.4兆個の高品質で多様なデータが構築されています。複数の言語は、さまざまなタイプのデータのサンプリング比を細かく設定することにより、中国語と英語のパフォーマンスを発揮し、他の言語の効果も考慮することができます。単語セグメンテーション:BPEアルゴリズムに基づいて、100,278の語彙サイズの単語セグメンテーションを数百のGBコーパスを使用して訓練しました。トレーニングフレームワーク:効率的なオペレーター、ビデオメモリの最適化、並列スケジューリング戦略、データコンピューティング共産化の重複、プラットフォーム、フレームワークのコラボレーションなど、多くの主要なテクノロジーを独立して開発し、トレーニング効率を高め、モデルの安定性を強化します。キロカードクラスターのピークコンピューティングパワー利用率は58.5%に達する可能性があり、業界の最前線にランク付けされます。
このプロジェクトのオープンソースアドレスは、https://github.com/xverse-ai/xverse-13bです
2023年8月3日、Alibaba Tongyi Qianwenの70億モデルは、一般的なモデルや対話モデルを含むオープンソースであり、オープンソースで無料で市販されています。報告によると、QWEN-7Bはトランスに基づいた大規模な言語モデルであり、超大規模なスケールの事前トレーニングデータでトレーニングされています。トレーニング前のデータ型は多様であり、多数のオンラインテキスト、専門帳、コードなどを含む幅広い分野をカバーしています。これは、2兆以上のトークンデータセットで訓練された中国語と英語をサポートするドックモデルであり、コンテキストウィンドウの長さは8Kに達します。 QWEN-7B-chatは、QWEN-7B台座モデルに基づく中国語と英語の対話モデルです。 Tongyi Qianwen 7b事前に訓練されたモデルは、複数の権威あるベンチマーク評価でうまく機能しました。中国と英語の能力は、国内外で同じスケールのオープンソースモデルをはるかに超えており、一部の機能は12Bと13Bのサイズのオープンソースモデルを超えていました。
プロジェクトのオープンソースアドレスは、https://github.com/qwenlm/qwen-7bです
Llamaは、メタによってリリースされた新しい大規模な人工知能言語モデルであり、テキストの生成、対話、書面による資料の要約、数学の定理の証明、タンパク質構造の予測などのタスクでうまく機能します。ラマモデルは、ラテン語とキリル語のアルファベット語を含む20の言語をサポートしています。現在、元のモデルは中国語をサポートしていません。 Llamaの壮大な漏れは、ChatGptのようなオープンソース開発を激しく促進したと言えます。
(2023年4月22日に更新)しかし、残念なことに、ラマの承認は現在限られており、科学研究にのみ使用でき、商業的使用は許可されていません。コマーシャルの完全なオープンソースの問題を解決するために、Redpajamaプロジェクトは、商用アプリケーションに使用できるラマの完全にオープンソースのレプリカを作成し、研究のためにより透明なプロセスを提供することを目指しています。完全なRedpajamaには1.2兆個のトークンデータセットが含まれており、次のステップは大規模なトレーニングを開始することです。この作業はまだ楽しみにしており、そのオープンソースアドレスは次のとおりです。
https://github.com/togethercomputer/redpajama-data
(2023年5月7日に更新)
Redpajamaは、3Bと7Bの2つのパラメーターを含むトレーニングモデルファイルを更新しました。3Bは5年前にリリースされたRTX2070ゲームグラフィックカードで実行でき、3BのLlamaのギャップを補います。そのモデルアドレスは次のとおりです。
https://huggingface.co/togethercomputer
Redpajamaに加えて、MOSAICMLはMPTシリーズモデルを開始し、そのトレーニングデータはRedpajamaデータを使用しています。さまざまなパフォーマンス評価では、7Bモデルは元のラマに匹敵します。そのモデルのオープンソースアドレスは次のとおりです。
https://huggingface.co/mosaicml
RedpajamaであろうとMPTであろうと、対応するチャットバージョンモデルもオープンソースです。これら2つのモデルのオープンソースは、ChatGptのような商業化を大幅に後押ししました。
(2023年6月1日に更新)
ファルコンは、ラマを比較するオープンな大きなモデルベースです。 7bと40bの2つのパラメーター測定スケールがあります。 40Bの性能は、超高65Bラマとして知られています。 Falconは依然としてGPT Autore -Gurishing Decoderモデルを使用していることが理解されていますが、データに多くの努力を注いでいます。パブリックネットワークからコンテンツを削減し、最初の前提条件のデータセットを構築した後、CommonCrawlダンプを使用して大規模なフィルタリングと大規模な重複排除を実行し、最終的に5兆個近くのトークンで構成される巨大な前提条件のデータセットを取得します。同時に、研究論文やソーシャルメディアの会話など、多くの選択されたコーパスが追加されています。ただし、プロジェクトの承認は議論の余地があり、「半商業的」許可方法が採用されており、収入が100万に達した後、商業費の10%が発生し始めます。
プロジェクトのオープンソースアドレスは、https://huggingface.co/tiiuaeです
(2023年7月3日に更新)
元のファルコンには、ラマのような中国のサポート機能がありません。 「Linly」プロジェクトチームは、Falconモデルに基づいて中国語版の中国語版を構築し、オープンしました。このモデルは、8701一般的に使用される漢字、Jieba語彙リストの最初の20,000人の中国の高周波語、および60の中国の句読点を含む、最初に拡張して語彙リストを大幅に拡張しました。重複排除後、語彙リストサイズは90,046に拡張されました。トレーニング段階では、50gのコーパスと2Tの大規模データがトレーニングに使用されました。
プロジェクトのオープンソースアドレスは、https://github.com/cvi-szu/linlyです
(2023年7月24日に更新)
元のファルコンには、ラマのような中国のサポート機能がありません。 「Linly」プロジェクトチームは、Falconモデルに基づいて中国語版の中国語版を構築し、オープンしました。このモデルは、8701一般的に使用される漢字、Jieba語彙リストの最初の20,000人の中国の高周波語、および60の中国の句読点を含む、最初に拡張して語彙リストを大幅に拡張しました。重複排除後、語彙リストサイズは90,046に拡張されました。トレーニング段階では、50gのコーパスと2Tの大規模データがトレーニングに使用されました。
プロジェクトのオープンソースアドレスは、https://github.com/cvi-szu/linlyです
スタンフォードがリリースしたAlpaca(Alpacaモデル)は、Llama-7Bモデルに基づいた新しいモデルです。基本原則は、OpenaiのText-Davinci-003モデルがLlamaを微調整するために自己計算上の方法で52K命令サンプルを生成できるようにすることです。このプロジェクトは、ソーストレーニングデータ、トレーニングデータを生成するためのコード、およびハイパーパラメーターを開きました。モデルファイルはまだ開かれておらず、1日で5.6k以上の星に達しています。この作業は、低コストで簡単なデータアクセスのために非常に人気があり、低コストのChatGPTの模倣への道も開かれています。そのgithubアドレスは次のとおりです。
https://github.com/tatsu-lab/stanford_alpaca
これは、Nebuly+AIが立ち上げた人間のフィードバック強化学習に基づいて、Llama+AIチャットボットのオープンソースの実装です。その技術的なルートはChatGptに似ています。このプロジェクトは2日間開始されたばかりで、5.2Kスターを獲得しています。そのgithubアドレスは次のとおりです。
https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelere/chatllama
Chatllamaトレーニングプロセスアルゴリズムは、主にChATGPTよりも速く安価なトレーニングを実現するために使用されます。ほぼ15倍高速であると言われています。主な機能は次のとおりです。
完全なオープンソースの実装により、ユーザーは事前に訓練されたLlamaモデルに基づいてChatGptスタイルのサービスを構築できます。
ラマアーキテクチャは小さく、トレーニングプロセスと推論がより速く、コストがかかりません。
微調整プロセスをスピードアップするためのディープスピードゼロの組み込みサポート。
さまざまなサイズのラマモデルアーキテクチャをサポートしており、ユーザーは自分の好みに応じてモデルを微調整できます。
OpenChatkitは、元Openaiの研究者が居住しているThe Together TeamとLaionとOntocord.aiチームによって共同で作成されています。 OpenChatKitには200億パラメーターが含まれており、GPT-3のオープンソースバージョンGPT-NOX-20Bで微調整されています。同時に、CHATGPTSのさまざまな強化学習であるOpenChatKitは、60億パラメーター監査モデルを使用して不適切または有害な情報をフィルタリングして、生成されたコンテンツの安全性と品質を確保します。そのgithubアドレスは次のとおりです。
https://github.com/togethercomputer/openchatkit
スタンフォード・アルパカに基づいて、監視された微調整はブルームとラマに基づいて実現されます。スタンフォードアルパカのシードタスクはすべて英語であり、収集されたデータも英語です。このオープンソースプロジェクトは、中国の対話の大手モデルオープンソースコミュニティの開発を促進することです。中国語に最適化されています。モデルチューニングでは、CHATGPTによって生成されたデータのみを使用します(他のデータは含まれません)。プロジェクトには以下が含まれています。
175中国の種子ミッション
データを生成するためのコード
10mで生成されたデータは現在、1.5m、0.25mの数学的命令データセット、および0.8mのマルチラウンドタスクダイアログデータセットで供給されています。
Bloomz-7B1-MTおよびLLAMA-7Bに基づいて最適化されたモデル
GitHubアドレスはhttps://github.com/lianjiatech/belleです
Alpaca-Loraは、スタンフォード大学のもう1つの傑作です。 LORA(低ランク適応)テクノロジーを使用してAlpacaの結果を再現し、低コストの方法を使用して、RTX 4090グラフィックスカードでのみ5時間トレーニングしてAlpacaレベルのモデルを取得します。さらに、モデルはRaspberry Piで実行できます。このプロジェクトでは、抱きしめる顔のPEFTを使用して、安価で効率的な微調整を行います。 PEFTはライブラリ(LORAはサポートされているテクノロジーの1つ)であり、さまざまな変圧器ベースの言語モデルを使用してLORAで微調整できるため、一般的なハードウェア上のモデルの安価で効率的な微調整が可能になります。このプロジェクトのgithubアドレスは次のとおりです。
https://github.com/tloen/alpaca-lora
AlpacaとAlpaca-Loraは大きな進歩を遂げていますが、彼らの種子のタスクは英語の両方であり、中国人へのサポートもありません。一方で、上記に加えて、ベルがアルパカ・ロラなどの前任者の仕事に基づいて、ベルが大量の中国のコーパスを収集したことに加えて、中国語モデルのルオツオ(luotuo)が中央中国普通の大学と他の機関から3人の個々の開発者が供給したオープンで、単一のカードが訓練を完了することができます。現在、プロジェクトは2つのモデルLuotuo-Lora-7B-0.1、Luotuo-Lora-7B-0.3をリリースし、1つのモデルが計画にあります。そのgithubアドレスは次のとおりです。
https://github.com/lc1332/chinese-alpaca-lora
Alpacaに触発されたDollyは、Alpacaデータセットを使用してGPT-J-6bで微調整を実現しました。ドリー自体はモデルの「クローン」であるため、チームは最終的に「ドリー」と名付けることにしました。 Alpacaに触発されたこのクローニング方法は、ますます人気が高まっています。要約すると、Alpacaのオープンソースデータ収集方法と、6bまたは7bサイズの古いモデルに関する微調整の指示が微調整されているため、ChatGptのような効果を実現しています。このアイデアは非常に経済的であり、ChatGptの魅力をすぐに模倣できます。それは非常に人気があり、発売されると星がいっぱいになります。このプロジェクトのgithubアドレスは次のとおりです。
https://github.com/databrickslabs/dolly
Alpacaを発売した後、Stanford ScholarsはCMU、UC Berkeleyなどと協力して、130億パラメーター(一般にAlpacaおよびLlamaとして知られている)で新しいモデル-Vicunaを立ち上げました。 CHATGPTの90%のパフォーマンスを達成するのに300ドルしかかかりません。 Vicunaは、Sharegptによって収集されたユーザー共有の対話についてLlamaを微調整するために使用されます。テストプロセスでは、GPT-4を評価基準として使用します。結果は、VICUNA-13Bが症例の90%以上でChatGPTとBARDに一致する機能を達成していることを示しています。
UC Berkeley Lmsys Orgは最近、70億のパラメーターでVicunaをリリースしました。サイズが小さく、効率が高く、能力が強いだけでなく、M1/M2チップを備えたMACでわずか2行のコマンドで実行でき、GPU加速も有効にすることができます。
GitHubオープンソースアドレスはhttps://github.com/lm-sys/fastchat/
別の中国語版は、中国のヴィクナによって供給されており、GitHubのアドレスは次のとおりです。
https://github.com/facico/chinese-vicuna
ChatGptが人気を博した後、人々は神殿への簡単な方法を探していました。 ChatGptのようないくつかの外観が登場し始めました。特に、低コストでChatGptに続いて人気のある方法になりました。 LMFLOWは、この需要シナリオで生まれた製品であり、3090のような通常のグラフィックカードで大規模なモデルを洗練させることができます。このプロジェクトは、香港科学技術統計と機械学習研究所によって開始され、限られた機械リソースの下でのさまざまな実験をサポートするさまざまな実験をサポートする完全に開かれた大規模なモデル研究プラットフォームを確立することに取り組み、既存のデータイントールイントールイントールイントールを拡大することを改善することに取り組んでいます。以前の方法よりも効率的なモデルトレーニングシステム。
このプロジェクトを使用して、限られたコンピューティングリソースでさえ、ユーザーが独自の分野のパーソナライズされたトレーニングをサポートできるようになります。たとえば、llama-7b、3090はトレーニングを完了するのに5時間かかり、コストが大幅に削減されます。このプロジェクトでは、WebサイドのインスタントエクスペリエンスQ&Aサービス(lmflow.com)も開きます。 LMFLOWの出現とオープンソースにより、通常のリソースは、Q&A、交際、執筆、翻訳、専門家の相談などのさまざまなタスクをトレーニングできます。多くの研究者は現在、このプロジェクトを使用して、パラメーター量が650億以上で大規模なモデルをトレーニングしようとしています。
このプロジェクトのgithubアドレスは次のとおりです。
https://github.com/optimalscale/lmflow
このプロジェクトは、ChatGPTの会話を自動的に収集する方法を提案し、ChatGptがセルフトークになり、バッチが高品質のマルチラウンドダイアログデータセットを生成し、それぞれ約50,000の高品質のQ&Aコーパスをそれぞれ収集し、それぞれStackoverflow、Medqaを収集し、すべてオープンソースです。同時に、ラマモデルが改善され、効果はかなり良好です。 Bai Zeはまた、現在の低コストのLora微調整ソリューションを採用して、Bai ZE-7B、13B、30Bの3つの異なるスケールと、医療の垂直分野のモデルを取得しました。残念ながら、中国の名前はよく名付けられていますが、それでも中国語をサポートしていません。中国のバイゼモデルは計画中であると伝えられており、将来的にリリースされます。そのオープンソースのGitHubアドレスは次のとおりです。
https://github.com/project-baize/baize
ラマに拠点を置くChatGptフラット交換は発酵を続けており、カリフォルニア州バークレーのバークレーは、13Bのパラメーターで消費者GPUで実行できる会話モデルのコアラをリリースしました。 Koalaのトレーニングデータセットには、次のパーツが含まれています。ChatGPTデータとオープンソースデータ(Open Instruction Generalist(OIG)、Stanford Alpaca Model、Anthropic HH、Openai WebGPT、Openai Summarization)。 Koalaモデルは、8 A100 GPUを使用してJax/Flaxを使用してEaseLMに実装されており、2回の反復を完了するのに6時間かかります。評価効果はAlpacaよりも優れており、ChatGPTの50%のパフォーマンスを達成しています。
オープンソースアドレス:https://github.com/young-geng/easylm
スタンフォードアルパカの出現により、多数のラマに本拠を置くアルパカの家族と拡大動物の家族が出現し始め、最終的に、最近、レジャーの研究者がブログスタックラマを発表しました。同時に、70億パラメーターモデル-Stackllamaもリリースされました。これは、人間のフィードバック強化学習を通じて、Llama-7Bで微調整されたモデルです。詳細については、そのブログアドレスを参照してください。
https://huggingface.co/blog/stackllama
このプロジェクトは、中国のラマを最適化し、微調整されたダイアログシステムを開きます。このプロジェクトの特定の手順には、次のものがあります。1。単語リストを展開し、incentpieceを使用して中国データをトレーニングおよび構築し、llamaワードリストと合併します。 2。新しい単語リストでは、約20gの一般的な中国のコーパスが訓練され、LORA技術がトレーニングに使用されました。 3.スタンフォードアルパカを使用して、対話能力を得るために51Kデータで微調整されたトレーニングが実行されました。
オープンソースアドレスは、https://github.com/ymcui/chinese-llama-alpacaです
4月12日、Databricksは、業界初のオープンソースであるDirective Compliant LLMとして知られるDolly 2.0をリリースしました。データセットはDataBricksの従業員によって生成され、オープンソースがあり、商業目的で利用できました。 The newly proposed Dolly2.0 is a 12 billion parameter language model based on the open source EleutherAI pythia model series, and has been fine-tuned for the small open source instruction record corpus.
开源地址为:https://huggingface.co/databricks/dolly-v2-12b
https://github.com/databrickslabs/dolly
该项目带来了全民ChatGPT的时代,训练成本再次大幅降低。项目是微软基于其Deep Speed优化库开发而成,具备强化推理、RLHF模块、RLHF系统三大核心功能,可将训练速度提升15倍以上,成本却大幅度降低。例如,一个130亿参数的类ChatGPT模型,只需1.25小时就能完成训练。
开源地址为:https://github.com/microsoft/DeepSpeed
该项目采取了不同于RLHF的方式RRHF进行人类偏好对齐,RRHF相对于RLHF训练的模型量和超参数量远远降低。RRHF训练得到的Wombat-7B在性能上相比于Alpaca有显著的增加,和人类偏好对齐的更好。
开源地址为:https://github.com/GanjinZero/RRHF
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
开源地址为:https://github.com/Guanaco-Model/Guanaco-Model.github.io
(更新于2023年5月27日,Guanaco-65B)
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
开源地址为:https://github.com/artidoro/qlora
LLMZoo,即LLM动物园开源项目维护了一系列开源大模型,其中包括了近期备受关注的来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的Phoenix(凤凰)和Chimera等开源大语言模型,其中文本效果号称接近百度文心一言,GPT-4评测号称达到了97%文心一言的水平,在人工评测中五成不输文心一言。
Phoenix 模型有两点不同之处:在微调方面,指令式微调与对话式微调的进行了优化结合;支持四十余种全球化语言。
开源地址为:https://github.com/FreedomIntelligence/LLMZoo
OpenAssistant是一个开源聊天助手,其可以理解任务、与第三方系统交互、动态检索信息。据其说,其是第一个在人类数据上进行训练的完全开源的大规模指令微调模型。该模型主要创新在于一个较大的人类反馈数据集(详细说明见数据篇),公开测试显示效果在人类对齐和毒性方面做的不错,但是中文效果尚有不足。
开源地址为:https://github.com/LAION-AI/Open-Assistant
HuggingChat (更新于2023年4月26日)
HuggingChat是Huggingface继OpenAssistant推出的对标ChatGPT的开源平替。其能力域基本与ChatGPT一致,在英文等语系上效果惊艳,被成为ChatGPT目前最强开源平替。但笔者尝试了中文,可谓一塌糊涂,中文能力还需要有较大的提升。HuggingChat的底座是oasst-sft-6-llama-30b,也是基于Meta的LLaMA-30B微调的语言模型。
该项目的开源地址是:https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor
在线体验地址是:https://huggingface.co/chat
StableVicuna是一个Vicuna-13B v0(LLaMA-13B上的微调)的RLHF的微调模型。
StableLM-Alpha是以开源数据集the Pile(含有维基百科、Stack Exchange和PubMed等多个数据源)基础上训练所得,训练token量达1.5万亿。
为了适应对话,其在Stanford Alpaca模式基础上,结合了Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH.等数据集,微调获得模型StableLM-Tuned-Alpha
该项目的开源地址是:https://github.com/Stability-AI/StableLM
该模型垂直医学领域,经过中文医学指令精调/指令集对原始LLaMA-7B模型进行了微调,增强了医学领域上的对话能力。
该项目的开源地址是:https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
该模型的底座采用了自主研发的RWKV语言模型,100% RNN,微调部分仍然是经典的Alpaca、CodeAlpaca、Guanaco、GPT4All、 ShareGPT等。其开源了1B5、3B、7B和14B的模型,目前支持中英两个语种,提供不同语种比例的模型文件。
该项目的开源地址是:https://github.com/BlinkDL/ChatRWKV 或https://huggingface.co/BlinkDL/rwkv-4-raven
目前大部分类ChatGPT基本都是采用人工对齐方式,如RLHF,Alpaca模式只是实现了ChatGPT的效仿式对齐,对齐能力受限于原始ChatGPT对齐能力。卡内基梅隆大学语言技术研究所、IBM 研究院MIT-IBM Watson AI Lab和马萨诸塞大学阿默斯特分校的研究者提出了一种全新的自对齐方法。其结合了原则驱动式推理和生成式大模型的生成能力,用极少的监督数据就能达到很好的效果。该项目工作成功应用在LLaMA-65b模型上,研发出了Dromedary(单峰骆驼)。
该项目的开源地址是:https://github.com/IBM/Dromedary
LLaVA是一个多模态的语言和视觉对话模型,类似GPT-4,其主要还是在多模态数据指令工程上做了大量工作,目前开源了其13B的模型文件。从性能上,据了解视觉聊天相对得分达到了GPT-4的85%;多模态推理任务的科学问答达到了SoTA的92.53%。该项目的开源地址是:
https://github.com/haotian-liu/LLaVA
从名字上看,该项目对标GPT-4的能力域,实现了一个缩略版。该项目来自来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队。该模型利用两阶段的训练方法,先在大量对齐的图像-文本对上训练以获得视觉语言知识,然后用一个较小但高质量的图像-文本数据集和一个设计好的对话模板对预训练的模型进行微调,以提高模型生成的可靠性和可用性。该模型语言解码器使用Vicuna,视觉感知部分使用与BLIP-2相同的视觉编码器。
该项目的开源地址是:https://github.com/Vision-CAIR/MiniGPT-4
该项目与上述MiniGPT-4底层具有很大相通的地方,文本部分都使用了Vicuna,视觉部分则是BLIP-2微调而来。在论文和评测中,该模型在看图理解、逻辑推理和对话描述方面具有强大的优势,甚至号称超过GPT-4。InstructBLIP强大性能主要体现在视觉-语言指令数据集构建和训练上,使得模型对未知的数据和任务具有零样本能力。在指令微调数据上为了保持多样性和可及性,研究人员一共收集了涵盖了11个任务类别和28个数据集,并将它们转化为指令微调格式。同时其提出了一种指令感知的视觉特征提取方法,充分利用了BLIP-2模型中的Q-Former架构,指令文本不仅作为输入给到LLM,同时也给到了QFormer。
该项目的开源地址是:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
BiLLa是开源的推理能力增强的中英双语LLaMA模型,该模型训练过程和Chinese-LLaMA-Alpaca有点类似,都是三阶段:词表扩充、预训练和指令精调。不同的是在增强预训练阶段,BiLLa加入了任务数据,且没有采用Lora技术,精调阶段用到的指令数据也丰富的多。该模型在逻辑推理方面进行了特别增强,主要体现在加入了更多的逻辑推理任务指令。
该项目的开源地址是:https://github.com/Neutralzz/BiLLa
该项目是由IDEA开源,被成为"姜子牙",是在LLaMA-13B基础上训练而得。该模型也采用了三阶段策略,一是重新构建中文词表;二是在千亿token量级数据规模基础上继续预训练,使模型具备原生中文能力;最后经过500万条多任务样本的有监督微调(SFT)和综合人类反馈训练(RM+PPO+HFFT+COHFT+RBRS),增强各种AI能力。其同时开源了一个评估集,包括常识类问答、推理、自然语言理解任务、数学、写作、代码、翻译、角色扮演、翻译9大类任务,32个子类,共计185个问题。
该项目的开源地址是:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
评估集开源地址是:https://huggingface.co/datasets/IDEA-CCNL/Ziya-Eval-Chinese
该项目的研究者提出了一种新的视觉-语言指令微调对齐的端到端的经济方案,其称之为多模态适配器(MMA)。其巨大优势是只需要轻量化的适配器训练即可打通视觉和语言之间的桥梁,无需像LLaVa那样需要全量微调,因此成本大大降低。项目研究者还通过52k纯文本指令和152k文本-图像对,微调训练成一个多模态聊天机器人,具有较好的的视觉-语言理解能力。
该项目的开源地址是:https://github.com/luogen1996/LaVIN
该模型由港科大发布,主要是针对闭源大语言模型的对抗蒸馏思想,将ChatGPT的知识转移到了参数量LLaMA-7B模型上,训练数据只有70K,实现了近95%的ChatGPT能力,效果相当显著。该工作主要针对传统Alpaca等只有从闭源大模型单项输入的缺点出发,创新性提出正反馈循环机制,通过对抗式学习,使得闭源大模型能够指导学生模型应对难的指令,大幅提升学生模型的能力。
该项目的开源地址是:https://github.com/YJiangcm/Lion
最近多模态大模型成为开源主力,VPGTrans是其中一个,其动机是利用低成本训练一个多模态大模型。其一方面在视觉部分基于BLIP-2,可以直接将已有的多模态对话模型的视觉模块迁移到新的语言模型;另一方面利用VL-LLaMA和VL-Vicuna为各种新的大语言模型灵活添加视觉模块。
该项目的开源地址是:https://github.com/VPGTrans/VPGTrans
TigerBot是一个基于BLOOM框架的大模型,在监督指令微调、可控的事实性和创造性、并行训练机制和算法层面上都做了相应改进。本次开源项目共开源7B和180B,是目前开源参数规模最大的。除了开源模型外,其还开源了其用的指令数据集。
该项目开源地址是:https://github.com/TigerResearch/TigerBot
该模型是微软提出的在LLaMa基础上的微调模型,其核心采用了一种Evol-Instruct(进化指令)的思想。Evol-Instruct使用LLM生成大量不同复杂度级别的指令数据,其基本思想是从一个简单的初始指令开始,然后随机选择深度进化(将简单指令升级为更复杂的指令)或广度进化(在相关话题下创建多样性的新指令)。同时,其还提出淘汰进化的概念,即采用指令过滤器来淘汰出失败的指令。该模型以其独到的指令加工方法,一举夺得AlpacaEval的开源模型第一名。同时该团队又发布了WizardCoder-15B大模型,该模型专注代码生成,在HumanEval、HumanEval+、MBPP以及DS1000四个代码生成基准测试中,都取得了较好的成绩。
该项目开源地址是:https://github.com/nlpxucan/WizardLM
OpenChat一经开源和榜单评测公布,引发热潮评论,其在Vicuna GPT-4评测中,性能超过了ChatGPT,在AlpacaEval上也以80.9%的胜率夺得开源榜首。从模型细节上看也是基于LLaMA-13B进行了微调,只用到了6K GPT-4对话微调语料,能达到这个程度确实有点出乎意外。目前开源版本有OpenChat-2048和OpenChat-8192。
该项目开源地址是:https://github.com/imoneoi/openchat
百聆(BayLing)是一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。BayLing以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现,取得众多开源大模型中最佳的翻译能力,取得ChatGPT 90%的通用任务能力。BayLing开源了7B和13B的模型参数,以供后续翻译、大模型等相关研究使用。
该项目开源地址是:https://github.com/imoneoi/openchat
在线体验地址是:http://nlp.ict.ac.cn/bayling/demo
ChatLaw是由北大团队发布的面向法律领域的垂直大模型,其一共开源了三个模型:ChatLaw-13B,基于姜子牙Ziya-LLaMA-13B-v1训练而来,但是逻辑复杂的法律问答效果不佳;ChatLaw-33B,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据;ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,
该项目开源地址是:https://github.com/PKU-YuanGroup/ChatLaw
该项目是马里兰、三星和南加大的研究人员提出的,其针对Alpaca等方法构架的数据中包括很多质量低下的数据问题,提出了一种利用LLM自动识别和删除低质量数据的数据选择策略,不仅在测试中优于原始的Alpaca,而且训练速度更快。其基本思路是利用强大的外部大模型能力(如ChatGPT)自动评估每个(指令,输入,回应)元组的质量,对输入的各个维度如Accurac、Helpfulness进行打分,并过滤掉分数低于阈值的数据。
该项目开源地址是:https://lichang-chen.github.io/AlpaGasus
2023年7月18日,Meta正式发布最新一代开源大模型,不但性能大幅提升,更是带来了商业化的免费授权,这无疑为万模大战更添一新动力,并推进大模型的产业化和应用。此次LLaMA2共发布了从70亿、130亿、340亿以及700亿参数的预训练和微调模型,其中预训练过程相比1代数据增长40%(1.4T到2T),上下文长度也增加了一倍(2K到4K),并采用分组查询注意力机制(GQA)来提升性能;微调阶段,带来了对话版Llama 2-Chat,共收集了超100万条人工标注用于SFT和RLHF。但遗憾的是原生模型对中文支持仍然较弱,采用的中文数据集并不多,只占0.13%。
随着LLaMa 2的开源开放,一些优秀的LLaMa 2微调版开始涌现:
该项工作是OpenAI创始成员Andrej Karpathy的一个比较有意思的项目,中文俗称羊驼宝宝2代,该模型灵感来自llama.cpp,只有1500万参数,但是效果不错,能说会道。
该项目开源地址是:https://github.com/karpathy/llama2.c
该项目是由Stability AI和CarperAI实验室联合发布的基于LLaMA-2-70B模型的微调模型,模型采用了Alpaca范式,并经过SFT的全新合成数据集来进行训练,是LLaMA-2微调较早的成果之一。该模型在很多方面都表现出色,包括复杂的推理、理解语言的微妙之处,以及回答与专业领域相关的复杂问题。
该项目开源地址是:https://huggingface.co/stabilityai/FreeWilly2
该项目是由国内AI初创公司LinkSoul.Al推出,其在Llama-2-7b的基础上使用了1000万的中英文SFT数据进行微调训练,大幅增强了中文能力,弥补了原生模型在中文上的缺陷。
该项目开源地址是:https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
该项目是由OpenBuddy团队发布的,是基于Llama-2微调后的另一个中文增强模型。
该项目开源地址是:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
该项目简化了主流的预训练+精调两阶段训练流程,训练使用包含不同数据源的混合数据,其中无监督语料包括中文百科、科学文献、社区问答、新闻等通用语料,提供中文世界知识;英文语料包含SlimPajama、RefinedWeb 等数据集,用于平衡训练数据分布,避免模型遗忘已有的知识;以及中英文平行语料,用于对齐中英文模型的表示,将英文模型学到的知识快速迁移到中文上。有监督数据包括基于self-instruction构建的指令数据集,例如BELLE、Alpaca、Baize、InstructionWild等;使用人工prompt构建的数据例如FLAN、COIG、Firefly、pCLUE等。在词典扩充方面,该项目扩充了8076个常用汉字和标点符号。
该项目开源地址是:https://github.com/CVI-SZU/Linly
ChatGPT的出现使大家振臂欢呼AGI时代的到来,是打开通用人工智能的一把关键钥匙。但ChatGPT仍然是一种人机交互对话形式,针对你唤醒的指令问题进行作答,还没有产生通用的自主的能力。但随着AutoGPT的出现,人们已经开始向这个方向大跨步的迈进。
AutoGPT已经大火了一段时间,也被称为ChatGPT通往AGI的开山之作,截止4.26日已达114K星。AutoGPT虽然是用了GPT-4等的底座,但是这个底座可以进行迁移适配到开源版。其最大的特点就在于能全自动地根据任务指令进行分析和执行,自己给自己提问并进行回答,中间环节不需要用户参与,将“行动→观察结果→思考→决定下一步行动”这条路子给打通并循环了起来,使得工作更加的高效,更低成本。
该项目的开源地址是:https://github.com/Significant-Gravitas/Auto-GPT
OpenAGI将复杂的多任务、多模态进行语言模型上的统一,重点解决可扩展性、非线性任务规划和定量评估等AGI问题。OpenAGI的大致原理是将任务描述作为输入大模型以生成解决方案,选择和合成模型,并执行以处理数据样本,最后评估语言模型的任务解决能力可以通过比较输出和真实标签的一致性。OpenAGI内的专家模型主要来自于Hugging Face的transformers、diffusers以及Github库。
该项目的开源地址是:https://github.com/agiresearch/OpenAGI
BabyAGI是仅次于AutoGPT火爆的AGI,运行方式类似AutoGPT,但具有不同的任务导向喜好。BabyAGI除了理解用户输入任务指令,他还可以自主探索,完成创建任务、确定任务优先级以及执行任务等操作。
该项目的开源地址是:https://github.com/yoheinakajima/babyagi
提起Agent,不免想起langchain agent,langchain的思想影响较大,其中AutoGPT就是借鉴了其思路。langchain agent可以支持用户根据自己的需求自定义插件,描述插件的具体功能,通过统一输入决定采用不同的插件进行任务处理,其后端统一接入LLM进行具体执行。
最近Huggingface开源了自己的Transformers Agent,其可以控制10万多个Hugging Face模型完成各种任务,通用智能也许不只是一个大脑,而是一个群体智慧结晶。其基本思路是agent充分理解你输入的意图,然后将其转化为Prompt,并挑选合适的模型去完成任务。
该项目的开源地址是:https://huggingface.co/docs/transformers/en/transformers_agents
GPT-4的诞生,AI生成能力的大幅度跃迁,使人们开始更加关注数字人问题。通用人工智能的形态可能是更加智能、自主的人形智能体,他可以参与到我们真实生活中,给人类带来不一样的交流体验。近期,GitHub上开源了一个有意思的项目GirlfriendGPT,可以将现实中的女友克隆成虚拟女友,进行文字、图像、语音等不通模态的自主交流。
GirlfriendGPT现在可能只是一个toy级项目,但是随着AIGC的阶梯性跃迁变革,这样的陪伴机器人、数字永生机器人、冻龄机器人会逐渐进入人类的视野,并参与到人的社会活动中。
该项目的开源地址是:https://github.com/EniasCailliau/GirlfriendGPT
Camel AGI早在3月份就被发布了出来,比AutoGPT等都要早,其提出了提出了一个角色扮演智能体框架,可以实现两个人工智能智能体的交流。Camel的核心本质是提示工程, 这些提示被精心定义,用于分配角色,防止角色反转,禁止生成有害和虚假的信息,并鼓励连贯的对话。
该项目的开源地址是:https://github.com/camel-ai/camel
《西部世界小镇》是由斯坦福基于chatgpt打造的多智能体社区,论文一经发布爆火,英伟达高级科学家Jim Fan甚至认为"斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一",当前该项目迎来了重磅开源,很多人相信,这标志着AGI的开始。该项目中采用了一种全新的多智能体架构,在小镇中打造了25个智能体,他们能够使用自然语言存储各自的经历,并随着时间发展存储记忆,智能体在工作时会动态检索记忆从而规划自己的行为。
智能体和传统的语言模型能力最大的区别是自主意识,西部世界小镇中的智能体可以做到相互之间的社会行为,他们通过不断地"相处",形成新的关系,并且会记住自己与其他智能体的互动。智能体本身也具有自我规划能力,在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中,通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
该项目的开源地址是:https://github.com/joonspk-research/generative_agents
ChatGPT引爆了大模型的火山式喷发,琳琅满目的大模型出现在我们目前,本项目也汇聚了特别多的开源模型。但这些模型到底水平如何,还需要标准的测试。截止目前,大模型的评测逐渐得到重视,一些评测榜单也相继发布,因此,也汇聚在此处,供大家参考,以辅助判断模型的优劣。
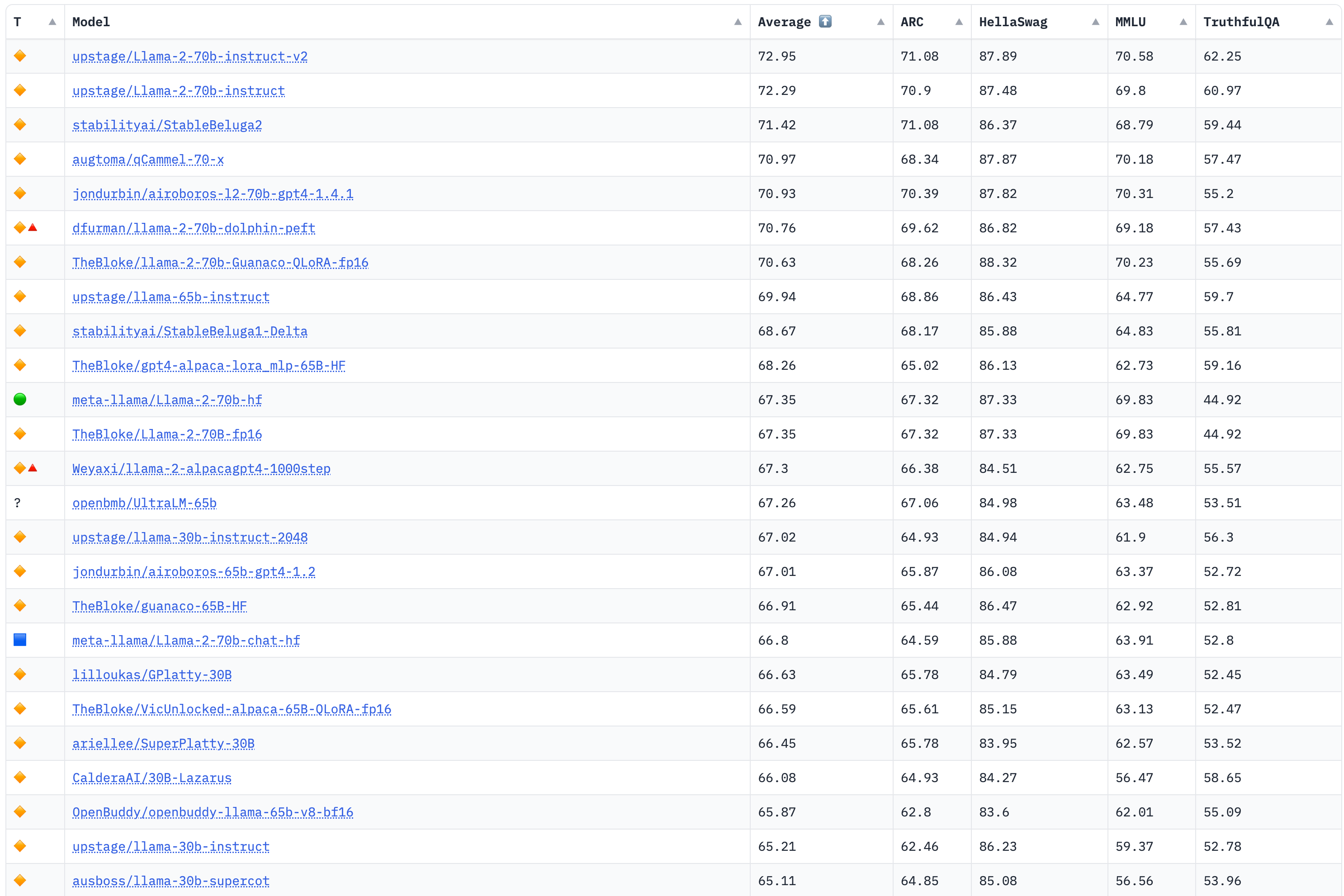
该榜单评测4个大的任务:AI2 Reasoning Challenge (25-shot),小学科学问题评测集;HellaSwag (10-shot),尝试推理评测集;MMLU (5-shot),包含57个任务的多任务评测集;TruthfulQA (0-shot),问答的是/否测试集。
榜单部分如下,详见:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
更新于2023年8月8日
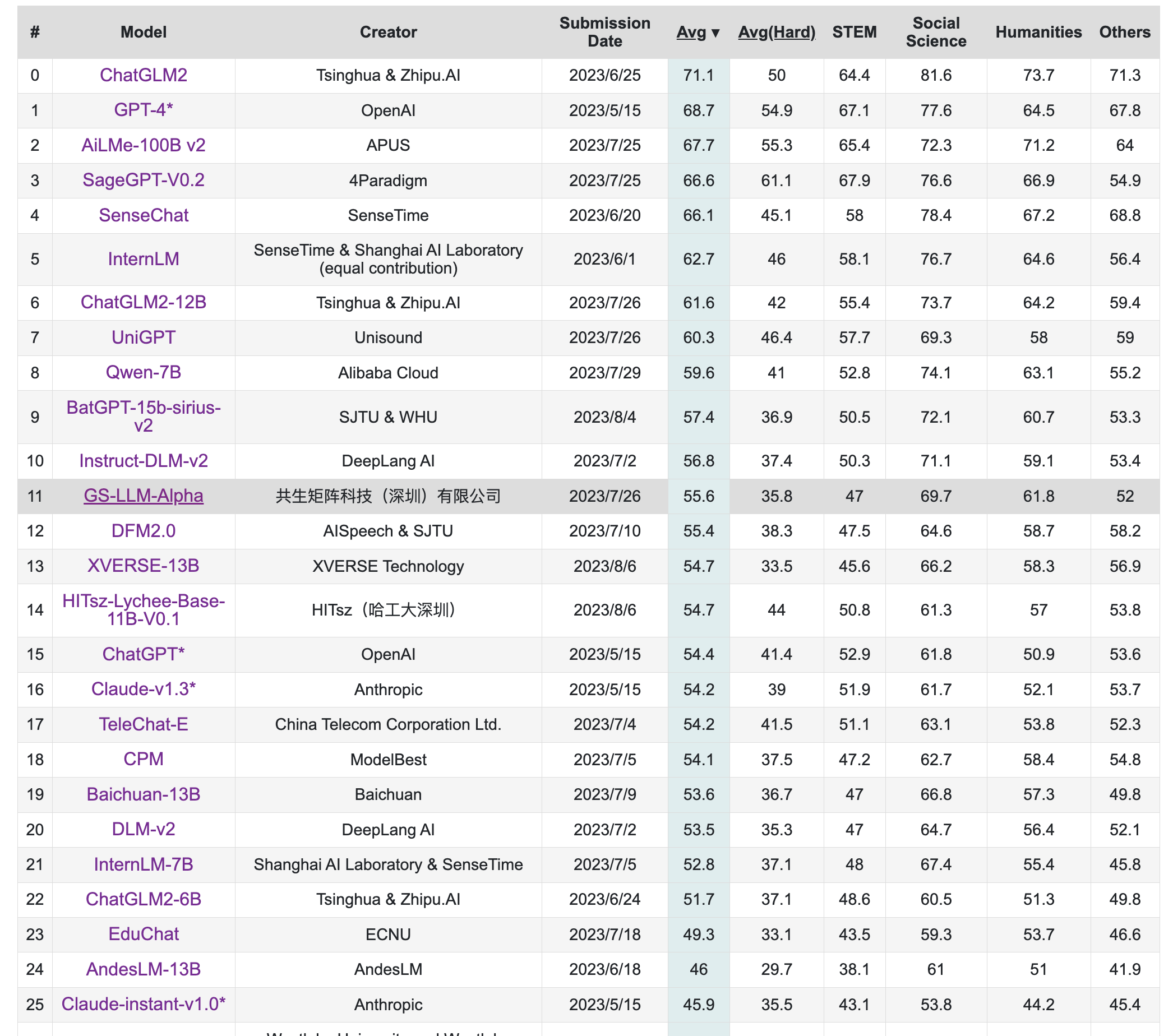
该榜单旨在构造中文大模型的知识评估基准,其构造了一个覆盖人文,社科,理工,其他专业四个大方向,52个学科的13948道题目,范围遍布从中学到大学研究生以及职业考试。其数据集包括三类,一种是标注的问题、答案和判断依据,一种是问题和答案,一种是完全测试集。
榜单部分如下,详见:https://cevalbenchmark.com/static/leaderboard.html
更新于2023年8月8日
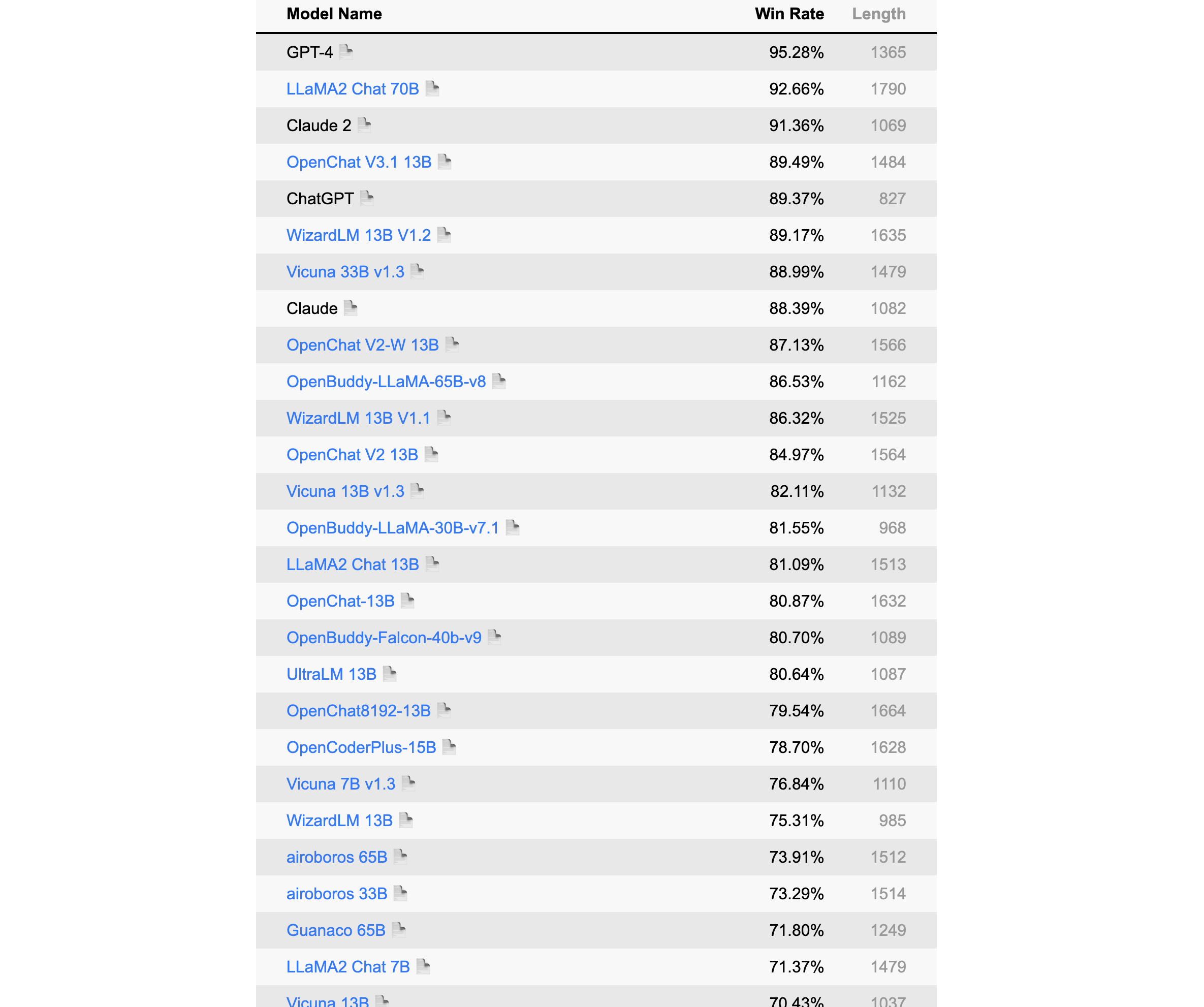
该榜单来自中文语言理解测评基准开源社区CLUE,其旨在构造一个中文大模型匿名对战平台,利用Elo评分系统进行评分。
榜单部分如下,详见:https://www.superclueai.com/
更新于2023年8月8日

该榜单由Alpaca的提出者斯坦福发布,是一个以指令微调模式语言模型的自动评测榜,该排名采用GPT-4/Claude作为标准。
榜单部分如下,详见:https://tatsu-lab.github.io/alpaca_eval/
更新于2023年8月8日
LCCC,数据集有base与large两个版本,各包含6.8M和12M对话。这些数据是从79M原始对话数据中经过严格清洗得到的,包括微博、贴吧、小黄鸡等。
https://github.com/thu-coai/CDial-GPT#Dataset-zh
Stanford-Alpaca数据集,52K的英文,采用Self-Instruct技术获取,数据已开源:
https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
中文Stanford-Alpaca数据集,52K的中文数据,通过机器翻译翻译将Stanford-Alpaca翻译筛选成中文获得:
https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data/alpaca_data_zh_51k.json
pCLUE数据,基于提示的大规模预训练数据集,根据CLUE评测标准转化而来,数据量较大,有300K之多
https://github.com/CLUEbenchmark/pCLUE/tree/main/datasets
Belle数据集,主要是中文,目前有2M和1.5M两个版本,都已经开源,数据获取方法同Stanford-Alpaca
3.5M:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
2M:https://huggingface.co/datasets/BelleGroup/train_2M_CN
1M:https://huggingface.co/datasets/BelleGroup/train_1M_CN
0.5M:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
0.8M多轮对话:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
微软GPT-4数据集,包括中文和英文数据,采用Stanford-Alpaca方式,但是数据获取用的是GPT-4
中文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data_zh.json
英文:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/blob/main/data/alpaca_gpt4_data.json
ShareChat数据集,其将ChatGPT上获取的数据清洗/翻译成高质量的中文语料,从而推进国内AI的发展,让中国人人可炼优质中文Chat模型,约约九万个对话数据,英文68000,中文11000条。
https://paratranz.cn/projects/6725/files
OpenAssistant Conversations, 该数据集是由LAION AI等机构的研究者收集的大量基于文本的输入和反馈的多样化和独特数据集。该数据集有161443条消息,涵盖35种不同的语言。该数据集的诞生主要是众包的形式,参与者超过了13500名志愿者,数据集目前面向所有人开源开放。
https://huggingface.co/datasets/OpenAssistant/oasst1
firefly-train-1.1M数据集,该数据集是一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。利用该数据集,研究者微调训练了一个中文对话式大语言模型(Firefly(流萤))。
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
LLaVA-Instruct-150K,该数据集是一份高质量多模态指令数据,综合考虑了图像的符号化表示、GPT-4、提示工程等。
https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K
UltraChat,该项目采用了两个独立的ChatGPT Turbo API来确保数据质量,其中一个模型扮演用户角色来生成问题或指令,另一个模型生成反馈。该项目的另一个质量保障措施是不会直接使用互联网上的数据作为提示。UltraChat对对话数据覆盖的主题和任务类型进行了系统的分类和设计,还对用户模型和回复模型进行了细致的提示工程,它包含三个部分:关于世界的问题、写作与创作和对于现有资料的辅助改写。该数据集目前只放出了英文版,期待中文版的开源。
https://huggingface.co/datasets/stingning/ultrachat
MOSS数据集,MOSS在开源其模型的同时,开源了部分数据集,其中包括moss-002-sft-data、moss-003-sft-data、moss-003-sft-plugin-data和moss-003-pm-data,其中只有moss-002-sft-data完全开源,其由text-davinci-003生成,包括中、英各约59万条、57万条。
moss-002-sft-data:https://huggingface.co/datasets/fnlp/moss-002-sft-data
Alpaca-CoT,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合,尤其是CoT数据集。该项目已经汇集了不少规模的数据,项目地址是:
https://github.com/PhoebusSi/Alpaca-CoT/blob/main/CN_README.md
zhihu_26k,知乎26k的指令数据,中文,项目地址是:
https://huggingface.co/datasets/liyucheng/zhihu_26k
Gorilla APIBench指令数据集,该数据集从公开模型Hub(TorchHub、TensorHub和HuggingFace。)中抓取的机器学习模型API,使用自指示为每个API生成了10个合成的prompt。根据这个数据集基于LLaMA-7B微调得到了Gorilla,但遗憾的是微调后的模型没有开源:
https://github.com/ShishirPatil/gorilla/tree/main/data
GuanacoDataset 在52K Alpaca数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)等。
https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
ShareGPT,ShareGPT是一个由用户主动贡献和分享的对话数据集,它包含了来自不同领域、主题、风格和情感的对话样本,覆盖了闲聊、问答、故事、诗歌、歌词等多种类型。这种数据集具有很高的质量、多样性、个性化和情感化,目前数据量已达160K对话。
https://sharegpt.com/
HC3,其是由人类-ChatGPT 问答对比组成的数据集,总共大约87k
中文:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese 英文:https://huggingface.co/datasets/Hello-SimpleAI/HC3
OIG,该数据集涵盖43M高质量指令,如多轮对话、问答、分类、提取和总结等。
https://huggingface.co/datasets/laion/OIG
COIG,由BAAI发布中文通用开源指令数据集,相比之前的中文指令数据集,COIG数据集在领域适应性、多样性、数据质量等方面具有一定的优势。目前COIG数据集主要包括:通用翻译指令数据集、考试指令数据集、价值对其数据集、反事实校正数据集、代码指令数据集。
https://huggingface.co/datasets/BAAI/COIG
gpt4all-clean,该数据集由原始的GPT4All清洗而来,共374K左右大小。
https://huggingface.co/datasets/crumb/gpt4all-clean
baize数据集,100k的ChatGPT跟自己聊天数据集
https://github.com/project-baize/baize-chatbot/tree/main/data
databricks-dolly-15k,由Databricks员工在2023年3月-4月期间人工标注生成的自然语言指令。
https://huggingface.co/datasets/databricks/databricks-dolly-15k
chinese_chatgpt_corpus,该数据集收集了5M+ChatGPT样式的对话语料,源数据涵盖百科、知道问答、对联、古文、古诗词和微博新闻评论等。
https://huggingface.co/datasets/sunzeyeah/chinese_chatgpt_corpus
kd_conv,多轮对话数据,总共4.5K条,每条都是多轮对话,涉及旅游、电影和音乐三个领域。
https://huggingface.co/datasets/kd_conv
Dureader,该数据集是由百度发布的中文阅读理解和问答数据集,在2017年就发布了,这里考虑将其列入在内,也是基于其本质也是对话形式,并且通过合理的指令设计,可以讲问题、证据、答案进行巧妙组合,甚至做出一些CoT形式,该数据集超过30万个问题,140万个证据文档,66万的人工生成答案,应用价值较大。
https://aistudio.baidu.com/aistudio/datasetdetail/177185
logiqa-zh,逻辑理解问题数据集,根据中国国家公务员考试公开试题中的逻辑理解问题构建的,旨在测试公务员考生的批判性思维和问题解决能力
https://huggingface.co/datasets/jiacheng-ye/logiqa-zh
awesome-chatgpt-prompts,该项目基本通过众筹的方式,大家一起设计Prompts,可以用来调教ChatGPT,也可以拿来用Stanford-alpaca形式自行获取语料,有中英两个版本:
英文:https://github.com/f/awesome-chatgpt-prompts/blob/main/prompts.csv
简体中文:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh.json
中国台湾繁体:https://github.com/PlexPt/awesome-chatgpt-prompts-zh/blob/main/prompts-zh-TW.json
PKU-Beaver,该项目首次公开了RLHF所需的数据集、训练和验证代码,是目前首个开源的可复现的RLHF基准。其首次提出了带有约束的价值对齐技术CVA,旨在解决人类标注产生的偏见和歧视等不安全因素。但目前该数据集只有英文。
英文:https://github.com/PKU-Alignment/safe-rlhf
zhihu_rlhf_3k,基于知乎的强化学习反馈数据集,使用知乎的点赞数来作为评判标准,将同一问题下的回答构成正负样本对(chosen or reject)。
https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k


