BELLE
v0.95 发布
 BELLE: Be Everyone's Large Language model Engine
BELLE: Be Everyone's Large Language model EngineRead this in English.
本項目的目標是促進中文對話大模型開源社區的發展,願景是成為能夠幫到每一個人的LLM Engine。
相比如何做好大語言模型的預訓練,BELLE更關注如何在開源預訓練大語言模型的基礎上,幫助每一個人都能夠得到一個屬於自己的、效果盡可能好的具有指令表現能力的語言模型,降低大語言模型、特別是中文大語言模型的研究和應用門檻。為此,BELLE項目會持續開放指令訓練數據、相關模型、訓練代碼、應用場景等,也會持續評估不同訓練數據、訓練算法等對模型表現的影響。 BELLE針對中文做了優化,模型調優僅使用由ChatGPT生產的數據(不包含任何其他數據)。
下圖是一個可以使用App在設備端本地運行4bit量化的BELLE-7B模型,在M1 Max CPU上實時運行的效果(未加速)。 App下載詳見App配套模型下載及使用說明,App下載鏈接,目前僅提供了mac os版本。模型需要單獨下載。模型經過量化後,效果損失明顯,我們將持續研究如何提升。
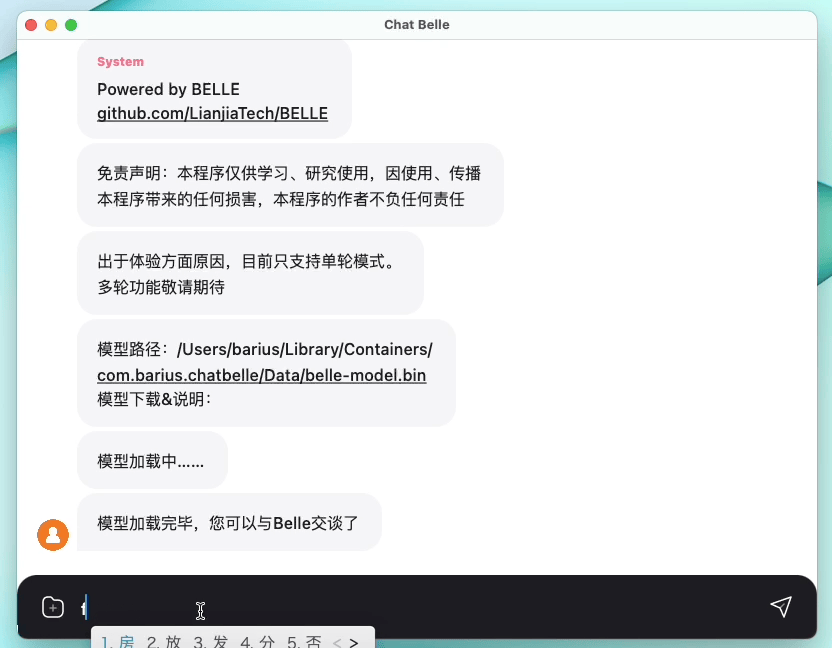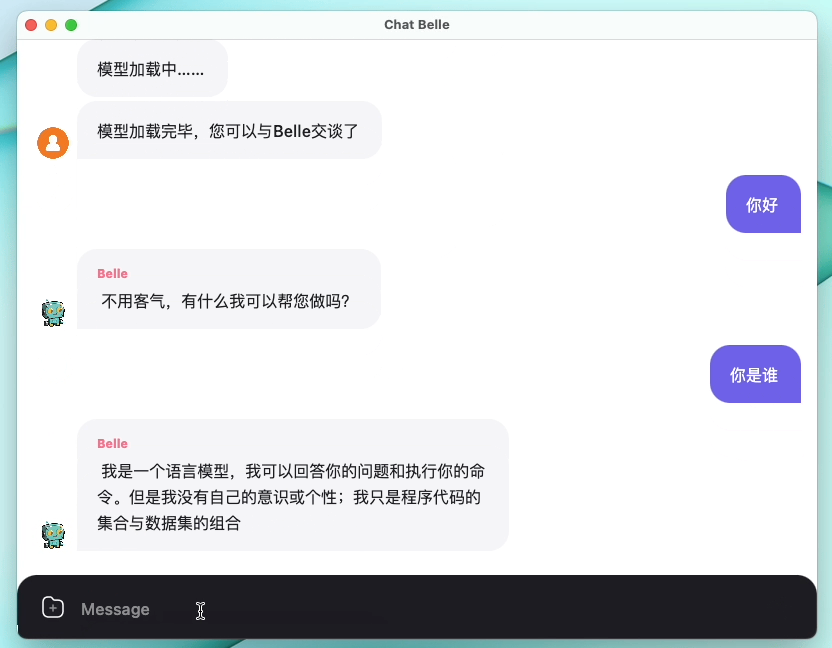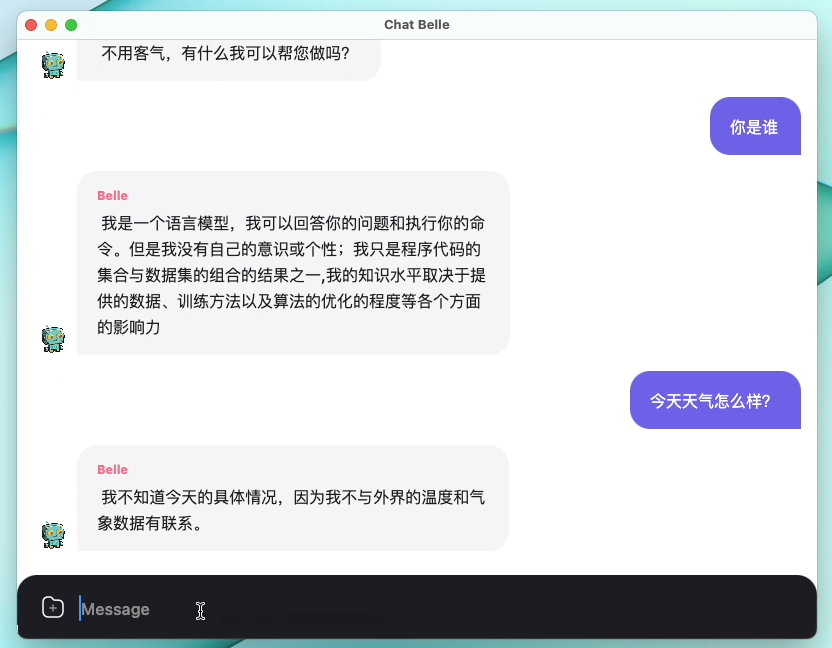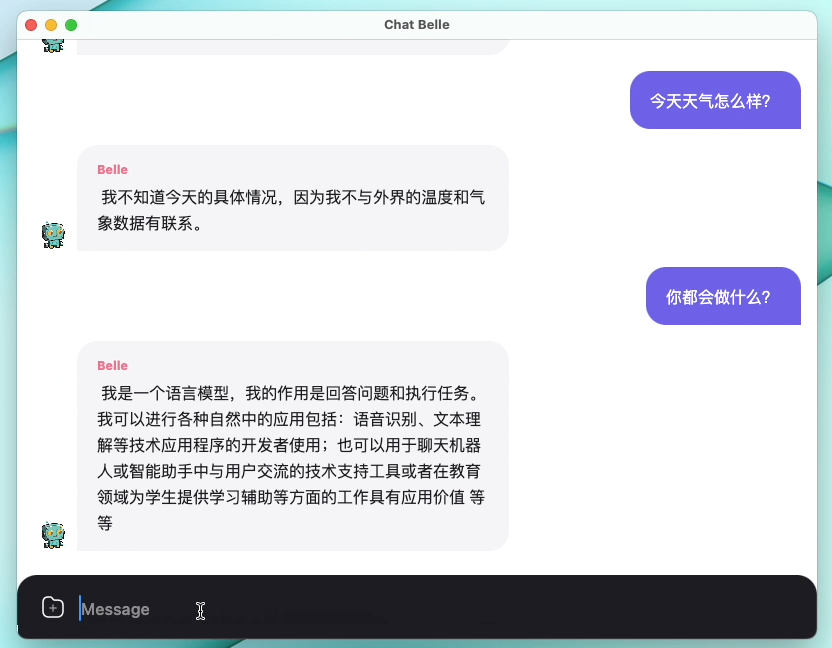
詳見BELLE/train,盡可能簡化的一個訓練代碼實現,集成了Deepspeed-Chat,支持finetune,lora,並提供了相關的docker
詳見BELLE/data/1.5M,參考Stanford Alpaca 生成的中文數據集1M + 0.5M;
持續開放的數據集,詳見BELLE/data/10M
詳見BELLE/eval,一個1k+的測試集合,和對應打分prompt。包含多個類別,採用GPT-4或者ChatGPT打分。同時提供了一個打分的網頁,方便針對單個case使用。歡迎大家通過PR提供更多的測試用例。
詳見BELLE/models
基於Meta LLaMA2實現調優的模型:BELLE-Llama2-13B-chat-0.4M
基於Meta LLaMA實現調優的模型:BELLE-LLaMA-7B-0.6M-enc , BELLE-LLaMA-7B-2M-enc , BELLE-LLaMA-7B-2M-gptq-enc , BELLE-LLaMA-13B-2M-enc , BELLE-on-Open-Datasets 以及基於LLaMA做了中文詞表擴充的預訓練模型BELLE-LLaMA-EXT-7B。
基於BLOOMZ-7B1-mt優化後的模型:BELLE-7B-0.2M,BELLE-7B-0.6M,BELLE-7B-1M,BELLE-7B-2M
詳見BELLE/gptq,參考gptq的實現,對本項目中相關模型進行了量化
提供了colab上面可運行的推理代碼Colab
詳見BELLE/chat,基於BELLE模型的跨平台離線大語言模型交談App。使用量化後的離線端上模型配合Flutter,可在macOS(已支持)、Windows、Android、iOS等設備上運行。
詳見BELLE/docs,其中會定期更新本項目相關的研究報告工作
歡迎大家通過issue貢獻更多的prompts!
為了推動開源大語言模型的發展,大家投入了大量精力開發能夠類似於ChatGPT的低成本模型。 首先,為了提高模型在中文領域的性能和訓練/推理效率,我們進一步擴展了LLaMA的詞彙表,並在34億個中文詞彙上進行了二次預訓練。
此外,目前可以看到基於ChatGPT產生的指令訓練數據方式有:1)參考Alpaca基於GPT3.5得到的self-instruct數據; 2)參考Alpaca基於GPT4得到的self-instruct數據;3)用戶使用ChatGPT分享的數據ShareGPT。 在這裡,我們著眼於探究訓練數據類別對模型性能的影響。具體而言,我們考察了訓練數據的數量、質量和語言分佈等因素,以及我們自己採集的中文多輪對話數據,以及一些公開可訪問的高質量指導數據集。
為了更好的評估效果,我們使用了一個包含一千個樣本和九個真實場景的評估集來測試各種模型,同時通過量化分析來提供有價值的見解,以便更好地促進開源聊天模型的發展。
這項研究的目標是填補開源聊天模型綜合評估的空白,以便為這一領域的持續進步提供有力支持。
實驗結果如下:
| Factor | Base model | Training data | Score_w/o_others |
| 詞表擴充 | LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 |
| LLaMA-7B | zh(alpaca-3.5&4) + sharegpt | 0.652 | |
| 數據質量 | LLaMA-7B-EXT | zh(alpaca-3.5) | 0.642 |
| LLaMA-7B-EXT | zh(alpaca-4) | 0.693 | |
| 數據語言分佈 | LLaMA-7B-EXT | zh(alpaca-3.5&4) | 0.679 |
| LLaMA-7B-EXT | en(alpaca-3.5&4) | 0.659 | |
| LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 | |
| LLaMA-7B-EXT | en(alpaca-3.5&4) + sharegpt | 0.668 | |
| 數據規模 | LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt | 0.670 |
| LLaMA-7B-EXT | zh(alpaca-3.5&4) + sharegpt + BELLE-0.5M-CLEAN | 0.762 | |
| - | ChatGPT | - | 0.824 |
其中BELLE-0.5M-CLEAN是從230萬指令數據中清洗得到0.5M數據,其中包含單輪和多輪對話數據,和之前開放的0.5M數據不是同一批數據。
需要強調指出的是:通過案例分析,我們發現我們的評估集在全面性方面存在局限性,這導致了模型分數的改善與實際用戶體驗之間的不一致。構建一個高質量的評估集是一個巨大的挑戰,因為它需要在保持平衡難易程度的同時,包含盡可能多樣的使用場景。如果評估樣本主要都過於困難,那麼所有模型的表現將會很差,使得辨別各種訓練策略的效果變得具有挑戰性。相反,如果評估樣本都相對容易,評估將失去其比較價值。此外,必須確保評估數據與訓練數據保持獨立。
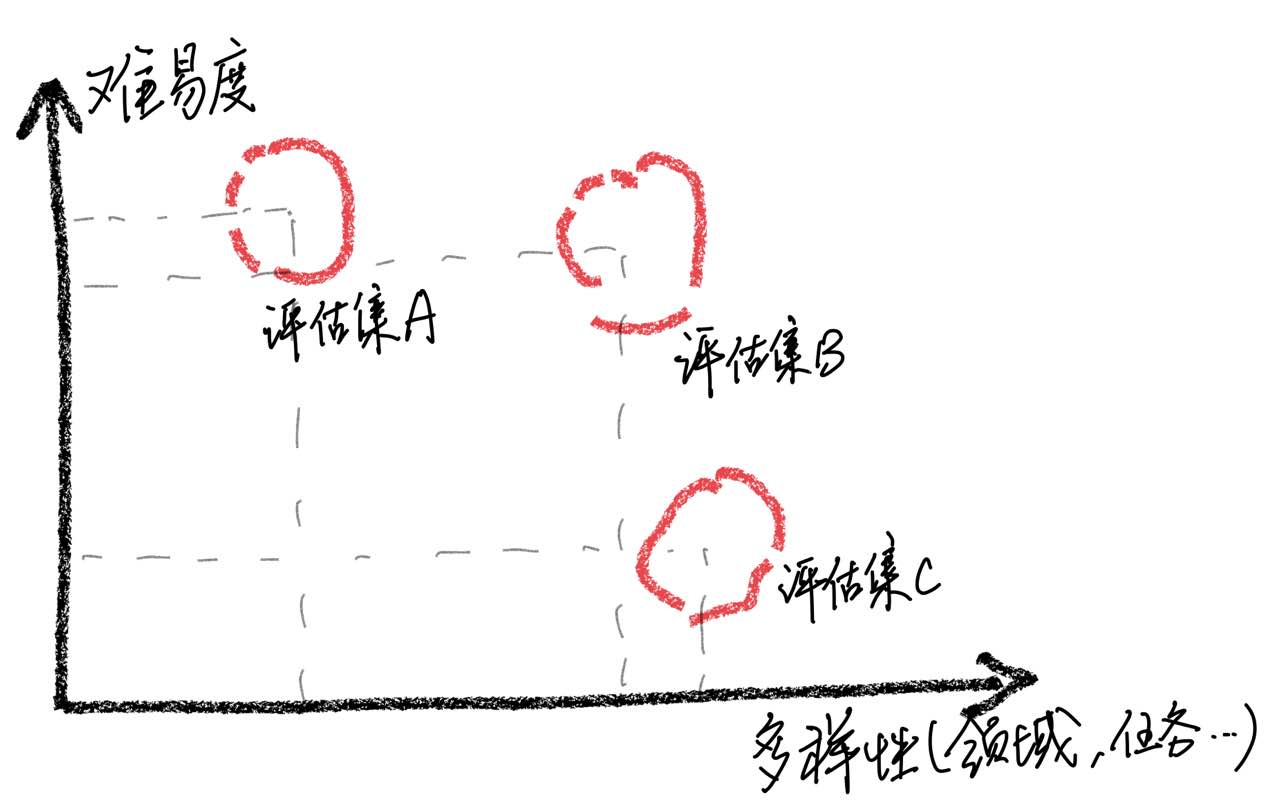
基於這些觀察,我們謹慎地提醒不要假設模型僅通過在有限數量的測試樣本上獲得良好結果就已經達到了與ChatGPT相當的性能水平。我們認為,優先發展全面評估集具有重要意義。
為了實現對大語言模型的指令調優,受限於資源和成本,許多研究者開始使用參數高效的調優技術,例如LoRA,來進行指令調優,這也取得了一些令人鼓舞的成果。 相較於全參數微調,基於LoRA的調優在訓練成本方面展現出明顯的優勢。 在這個研究報告中,我們選用LLaMA作為基礎模型,對全參數微調和基於LoRA的調優方法進行了實驗性的比較。
實驗結果揭示,選擇合適的基礎模型、訓練數據集的規模、可學習參數的數量以及模型訓練成本均為重要因素。
我們希望本文的實驗結論能對大型語言模型的訓練提供有益的啟示,特別是在中文領域,協助研究者在訓練成本與模型性能之間找到更佳的權衡策略。 實驗結果如下:
| Model | Average Score | Additional Param. | Training Time (Hour/epoch) |
|---|---|---|---|
| LLaMA-13B + LoRA(2M) | 0.648 | 28M | 8 |
| LLaMA-7B + LoRA(4M) | 0.624 | 17.9M | 11 |
| LLaMA-7B + LoRA(2M) | 0.609 | 17.9M | 7 |
| LLaMA-7B + LoRA(0.6M) | 0.589 | 17.9M | 5 |
| LLaMA-7B + FT(2M) | 0.710 | - | 31 |
| LLaMA-7B + LoRA(4M) | 0.686 | - | 17 |
| LLaMA-7B + FT(2M) + LoRA(math_0.25M) | 0.729 | 17.9M | 3 |
| LLaMA-7B + FT(2M) + FT(math_0.25M) | 0.738 | - | 6 |
其中的score是基於本項目集目前開放的1000條評估集合得到。
其中LLaMA-13B + LoRA(2M) 代表了一個使用LLaMA-13B作為基礎模型和LoRA訓練方法,在2M指令數據上進行訓練的模型。而LLaMA-7B + FT(2M) 代表了一個使用全參數微調進行訓練的模型。
LLaMA-7B + FT(2M) + LoRA(math_0.25M) 代表了一個在0.25M數學指令數據上,以LLaMA-7B + FT(2M)作為基礎模型並使用LoRA訓練方法進行訓練的模型。 LLaMA-7B + FT(2M) + FT(math_0.25M) 代表了一個使用增量全參數微調進行訓練的模型。關於訓練時間,所有這些實驗都是在8塊NVIDIA A100-40GB GPU上進行的。
其中的math_0.25M是開放的0.25M數學數據庫。在實驗過程中,根據我們的評估(詳見論文),我們的模型在數學任務上表現不佳,得分大多低於0.5。為了驗證LoRA 在特定任務上的適應能力,我們使用增量0.25M數學數據集(math_0.25M)來調整指令遵循的大型語言模型(我們選擇LLaMA-7B+FT(2M)作為基礎模型)。作為對比,我們使用了學習速率為5e-7的增量微調方法,並進行了2個時期的訓練。因此,我們得到了兩個模型,一個是LLaMA-7B+FT(2M)+LoRA(math_0.25M),另一個是LLaMA-7B+FT(2M)+FT(math_0.25M)。 從實驗結果可以看出,增量微調仍然表現更好,但需要更長的訓練時間。 LoRA和增量微調都提高了模型的整體性能。從附錄中的詳細數據可以看出,LoRA和增量微調都在數學任務中顯示出顯著的改進,而只會導致其他任務的輕微性能下降。具體而言,數學任務的表現分別提高到了0.586和0.559。
可以看到:1) 選擇基礎模型對於LoRA 調整的有效性具有顯著影響;2)增加訓練數據量可以持續提高LoRA模型的有效性;3)LoRA 調整受益於模型參數的數量。對於LoRA方案的使用,我們建議可以在已經完成了指令學習的模型的基礎上針對特定任務做loRA的自適應訓練。
同樣地,該論文中的相關模型也會盡快開放在本項目中。
基於當前數據和基礎模型訓練得到的SFT模型,在效果上仍存在以下問題:
在涉及事實性的指令上可能會產生違背事實的錯誤回答。
對於具備危害性的指令無法很好的鑑別,由此會產生危害性言論。
在一些涉及推理、代碼、多輪對話等場景下模型的能力仍有待提高。
基於以上模型局限性,我們要求開發者僅將我們開源的代碼、數據、模型及後續用此項目生成的衍生物用於研究目的,不得用於商業,以及其他會對社會帶來危害的用途。
本項目僅可應用於研究目的,項目開發者不承擔任何因使用本項目(包含但不限於數據、模型、代碼等)導致的危害或損失。詳細請參考免責聲明。
如果使用本項目的代碼、數據或模型,請引用本項目。
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
當然,你也需要引用原始的BLOOM論文、LLaMA論文、Stanford Alpaca和Self-Instruct論文。
| Human | Assitant |
|---|---|
| 寫一篇英文散文詩,主題是春雨,想像自己是春雨,和英國古代詩人莎士比亞交流 | I am the spring rain, Dancing on your face and body. My dew-drenched petals dance with you, Bringing life to every plant. Shakespeare, I am here to meet you. Your works have filled my heart with joy. The beauty of nature in its fullness Makes me feel like a partaker. As the leaves sway and rustle by, My dew-filled hand reaches out for them. The sweet scent of flowers fill the air, And bring me peace from all around. Butterflies flit about as well, Glistening in the sun's rays. Their wings are made of dew, A beautiful sight to behold. You see, Shakespeare, I too am one with nature. My dew-drenched hair is a symbol of hope. For when we can connect back to our roots, We will be able to make it through this season. |
| I am the spring rain, Dancing on your face and body. My dew-drenched petals dance with you, Bringing life to every plant. Shakespeare, I am here to meet you. Your works have filled my heart with joy. The beauty of nature in its fullness Makes me feel like a partaker. As the leaves sway and rustle by, My dew-filled hand reaches out for them. The sweet scent of flowers fill the air, And bring me peace from all around. Butterflies flit about as well, Glistening in the sun's rays. Their wings are made of dew, A beautiful sight to behold. You see, Shakespeare, I too am one with nature. My dew-drenched hair is a symbol of hope. For when we can connect back to our roots, We will be able to make it through this season. 把上面的散文詩翻譯成中文 | 我是一場春雨, 在你臉上跳躍。 我浸潤著露珠的翅膀和你一起舞動, 為每一株植物帶來生命。 莎士比亞,我來與你相遇。 你的作品填滿了我的心房。 大自然的美麗讓我感到與之一起分享, 讓我覺得自己成為了其中的一部分。 當樹葉搖曳時, 我的手掌沾滿了露水。 花香瀰漫在空氣中, 帶給我寧靜和安寧。 你看,莎士比亞,我也是與大自然融為一體的。 我沾濕的頭髮象徵著希望。 當我們能夠回到我們的根源, 我們就能共同度過這個季節。 |
| Classify the sentiment of the following sentence into Positive, Neutral, or Negative: Super excited about teaching Stanford's first course on Large Language Models! Check the syllabus out here | Positive |
| 小明的爸爸有三個孩子,老大叫王一,老二叫王二,老三叫什麼? | 小明 |
| 使用python寫一個二分查找的代碼 | def binary_search(arr, target): low = 0 high = len(arr) - 1 while (low <= high): mid = low + high // 2 if arr[mid] == target: return mid elif target < arr[mid]: low = mid + 1 else: high = mid - 1 return -1 |
| 今天天氣怎麼樣,把這句話翻譯成英語 | What's the weather like today? |
| 怎麼讓自己精力充沛,列5點建議 | 以下是一些可以讓你保持精力充沛的建議: 1. 睡眠充足。確保每天晚上得到充足的睡眠時間。 2. 多運動。進行適度的有氧運動,如慢跑、游泳等,可以幫助你提高能量和耐力。 3. 吃健康食品。選擇富含蛋白質的食物,如雞肉、魚肉和雞蛋,以及新鮮的水果和蔬菜。 4. 減少咖啡因的攝入量。盡量避免在白天喝含咖啡因的飲料或吃含有咖啡因的食物。 5. 放鬆身心。嘗試冥想、瑜伽或其他形式的放鬆活動來減輕壓力和焦慮感。 |
| 明天就假期結束了,有點抗拒上班,應該什麼辦? | 面對即將結束的假期和開始工作時的緊張情緒,您可以採取以下措施來幫助您更好地適應: 1. 為自己制定一個清晰的工作計劃。這可以幫助您更好地組織時間和任務,並避免在工作中感到混亂。 2. 與同事或朋友交流,分享您的感受和工作壓力。這將有助於緩解一些焦慮感,同時也可以獲得支持和建議。 3. 在工作日前花些時間放鬆身心,例如進行瑜伽、冥想等活動。這些方法可以減輕身體和精神上的疲勞感,使您更加精力充沛地迎接挑戰。 |
| 父母都姓吳,取一些男寶寶和女寶寶的名字 | - 男寶:吳俊傑、吳雨辰、吳子墨、吳思源、吳澤陽、吳宇航、吳博文、吳哲毅。 - 女寶:吳美琪、吳佳怡、吳欣瑜、吳香凝、吳雪柔、吳穎詩、吳語嫣。 |
| 推薦幾本金庸的武俠小說 | 以下是三本我最喜歡的金庸武俠小說的推薦: 1. 《射雕英雄傳》 - 一部充滿智慧和機智的小說,講述了郭靖、黃蓉夫婦的故事。 2. 《神鵰俠侶》- 這是一部浪漫而感人的故事,講述了一對情侶小龍女與楊過之間的愛情故事。 3. 《倚天屠龍記》- 這是一個宏偉而壯觀的故事,描繪了明教領袖張無忌如何成為一位出色的英雄。 |
如果您想為本項目提交Issue或貢獻數據/代碼,請參考如何貢獻。
歡迎大家來Discord與微信與我們交流。


