BELLE
v0.95 发布
 Belle: Будьте большим двигателем модели языка каждого
Belle: Будьте большим двигателем модели языка каждогоПрочитайте это на английском языке.
Цель этого проекта состоит в том, чтобы содействовать развитию китайского диалога Большой модели сообщества с открытым исходным кодом, и это видение состоит в том, чтобы стать двигателем LLM, который может помочь всем.
По сравнению с тем, как предварительно обучать крупные языковые модели, Belle больше фокусируется на том, как помочь каждому получить собственную языковую модель, с наилучшим возможным эффектом и возможностями производительности инструкций, основанных на предварительном обучении с открытым исходным кодом, а также снижают исследования и порог применения крупных языковых моделей, особенно крупных языковых моделей на китайском языке. С этой целью проект Belle будет продолжать открывать данные обучения обучения, связанные с ним модели, код обучения, сценарии приложений и т. Д. И будет продолжать оценивать влияние различных данных обучения, алгоритмов обучения и т. Д. На производительность модели. Belle была оптимизирована для китайской, а модельная настройка использует только данные, созданные CHATGPT (без каких -либо других данных).
На следующем рисунке представлена модель Belle-7B, которую можно запустить 4-бит квантовой локально на стороне устройства с использованием приложения, и работает в режиме реального времени на ЦП M1 Max (не ускоряется). Для получения подробной информации о загрузке приложения, пожалуйста, обратитесь к приложению, поддерживающему модель, загрузку и инструкции для использования. Ссылка загрузки приложения в настоящее время доступна только в версии Mac OS. Модель должна быть загружена отдельно. После того, как модель определяется количественно, потеря эффекта очевидна, и мы будем продолжать изучать, как ее улучшить.
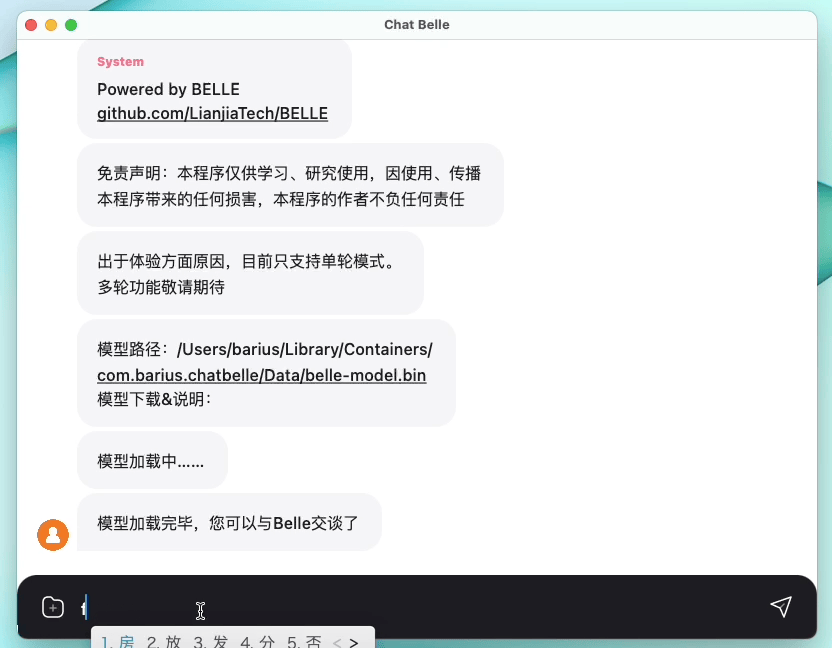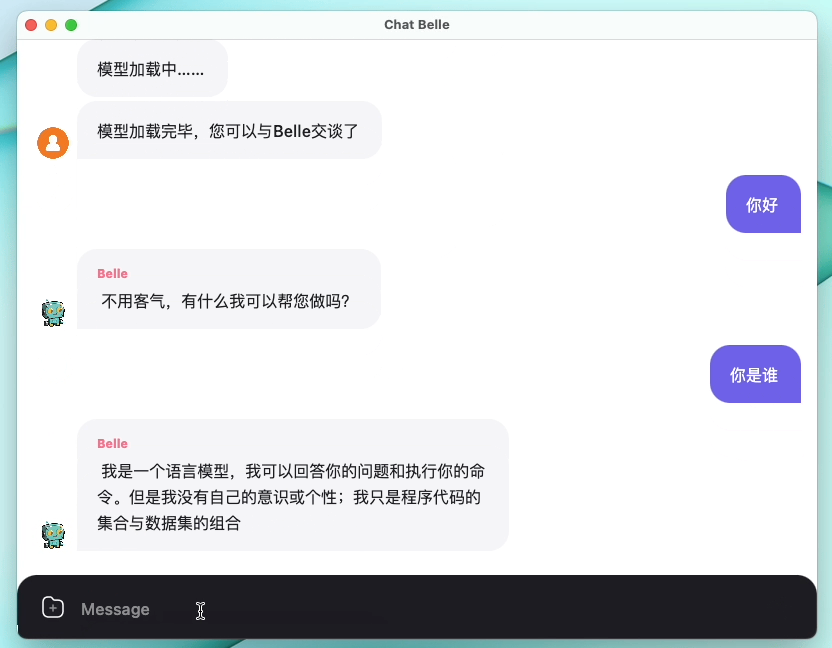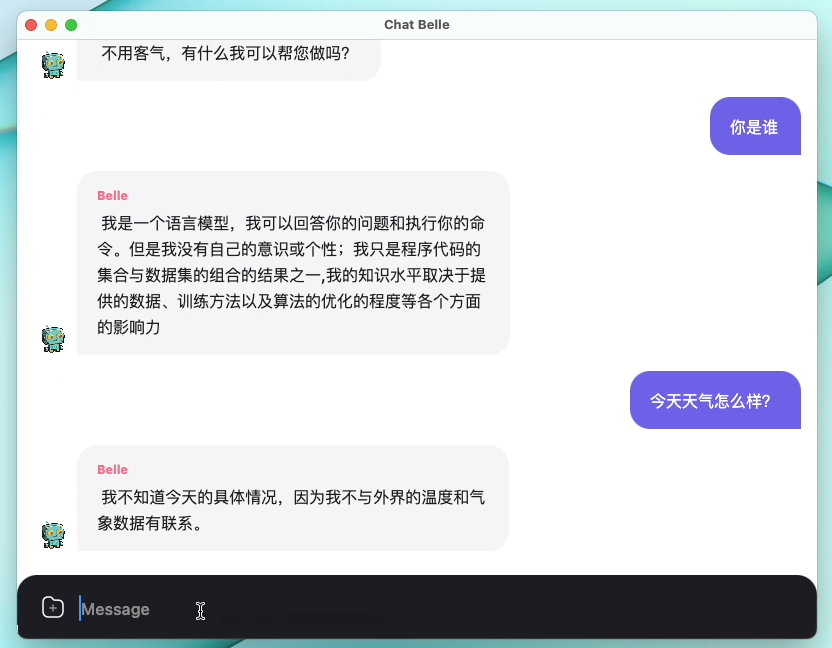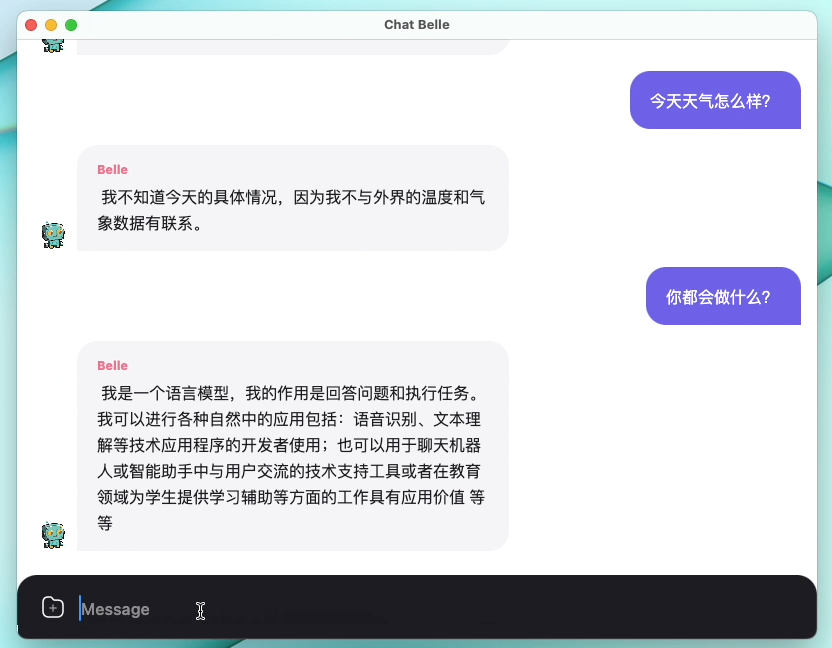
Подробнее см. В реализации Belle/Train, реализации кода обучения, которая максимально упрощена, интегрирует DeepSpeed Chat, поддерживает Finetune и Lora и предоставляет связанные докеры.
Для получения подробной информации см. Belle/Data/1,5 м, см. Китайский набор данных, сгенерированный Стэнфордской Альпакой 1M + 0,5 м;
Набор данных, который постоянно открыт, пожалуйста, обратитесь к Belle/Data/10M для получения подробной информации.
Подробнее см. Belle/Eval, набор тестирования 1K+ и соответствующая подсказка оценки. Он содержит несколько категорий и использует GPT-4 или CHATGPT для оценки. Он также предоставляет веб -страницу с оценкой для простых использования для одного случая. Каждый может предоставить больше тестовых случаев через PR.
Смотрите Belle/Models для деталей
Модель настройки на основе Meta Llama2: Belle-Llama2-13b-Chat-0,4M
Models that implement tuning based on Meta LLaMA: BELLE-LLaMA-7B-0.6M-enc , BELLE-LLaMA-7B-2M-enc , BELLE-LLaMA-7B-2M-gptq-enc , BELLE-LLaMA-13B-2M-enc , BELLE-on-Open-Datasets , and the pre-trained model BELLE-LLaMA-EXT-7B, which is based on LLaMA, has been expanded in Chinese словарный запас.
Модели, оптимизированные на основе Bloomz-7B1-MT: Belle-7B-0.2M, Belle-7B-0,6M, Belle-7B-1M, Belle-7B-2M
Смотрите Belle/GPTQ для деталей. Обратитесь к реализации GPTQ, чтобы количественно оценить соответствующие модели в этом проекте.
Предоставляет запускаемый код вывода Colab на Colab
Для получения подробной информации см. Belle/Chat, кроссплатформенное автономное приложение чата с крупным языком на основе модели Belle. Используя квантованную автономную модель с Flutter, она может работать на MacOS (поддерживается), Windows, Android, iOS и других устройств.
Подробнее см. Belle/Docs, которые регулярно обновляют отчет об исследовании, связанный с этим проектом.
Добро пожаловать, чтобы внести больший вклад в проблему!
Чтобы способствовать разработке моделей крупных языков с открытым исходным кодом, мы инвестировали много энергии в разработку недорогих моделей, которые могут быть похожи на CHATGPT. Во-первых, чтобы повысить эффективность производительности и обучения/вывода модели в китайской области, мы дополнительно расширили словарный запас Llama и выполнили вторичное предварительное обучение на 3,4 миллиарда китайских словарного запас.
Кроме того, мы можем видеть, что инструкции, обученные данными, сгенерированные на основе CHATGPT,: 1) обращаются к данным о самостоятельстве, полученных на основе GPT3.5 Alpaca; 2) обратитесь к данным о самооценке, полученных на основе GPT4 Alpaca; 3) Данные ShareGPT, общие пользователями, использующими CHATGPT. Здесь мы сосредоточены на изучении влияния категорий обучающих данных на производительность модели. В частности, мы исследуем такие факторы, как количество, качество и распределение языка обучающих данных, а также китайские данные многоуровневого диалога, которые мы сами собрали, и некоторые общедоступные высококачественные наборы данных.
Чтобы лучше оценить эффект, мы использовали набор оценки из 1000 образцов и девять реальных сценариев для тестирования различных моделей, предоставляя ценную информацию с помощью количественного анализа, чтобы лучше продвигать разработку моделей с открытым исходным кодом.
Цель этого исследования - заполнить пробел в комплексной оценке моделей чата с открытым исходным кодом, чтобы обеспечить сильную поддержку для дальнейшего прогресса в этой области.
Экспериментальные результаты следующие:
| Фактор | Базовая модель | Данные обучения | SCOST_W/O_OTHERS |
| Расширение словарного запаса | Llama-7b-ext | ZH (Alpaca-3,5 и 4) + ShareGpt | 0,670 |
| Лама-7B | ZH (Alpaca-3,5 и 4) + ShareGpt | 0,652 | |
| Качество данных | Llama-7b-ext | ZH (Alpaca-3.5) | 0,642 |
| Llama-7b-ext | ZH (Alpaca-4) | 0,693 | |
| Распределение языка данных | Llama-7b-ext | ZH (Alpaca-3,5 и 4) | 0,679 |
| Llama-7b-ext | EN (Alpaca-3,5 и 4) | 0,659 | |
| Llama-7b-ext | ZH (Alpaca-3,5 и 4) + ShareGpt | 0,670 | |
| Llama-7b-ext | EN (Alpaca-3,5 и 4) + ShareGpt | 0,668 | |
| Шкала данных | Llama-7b-ext | ZH (Alpaca-3,5 и 4) + ShareGpt | 0,670 |
| Llama-7b-ext | ZH (Alpaca-3,5 и 4) + ShareGpt + Belle-0,5M-Clean | 0,762 | |
| - | Чатгпт | - | 0,824 |
Среди них Belle-0,5 млн-чистка очищает данные 0,5 млн данных из 2,3 миллиона данных об инструкциях, которые содержат данные диалога в одном раунде и многочисленном раунде, что не является той же партией данных, что и ранее открытые данные 0,5 м.
Следует подчеркнуть, что с помощью анализа случаев мы обнаружили, что наш набор оценки имеет ограничения с точки зрения полной, что привело к несоответствиям между улучшением модельных результатов и фактическим пользовательским опытом. Создание высококачественного набора оценки является огромной проблемой, потому что он требует как можно большего количества сценариев использования при сохранении сбалансированной сложности. Если оценивать образцы в основном слишком сложна, все модели будут работать плохо, что делает трудности определять влияние различных стратегий обучения. Напротив, если все образцы оцениваются, относительно просты, оценка потеряет свою сравнительную ценность. Кроме того, необходимо обеспечить, чтобы данные оценки оставались независимыми от учебных данных.
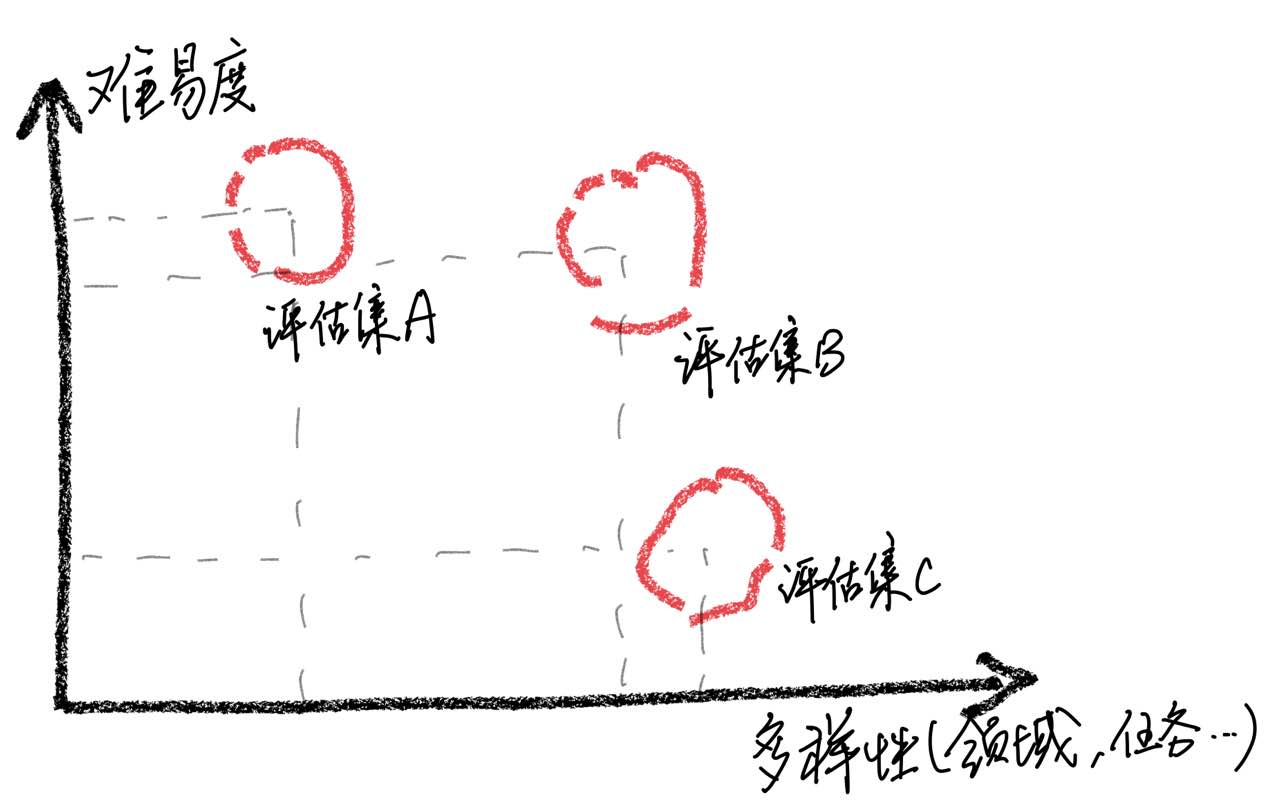
Основываясь на этих наблюдениях, мы предостерегаем от предположения, что модель достигла уровня производительности, сопоставимого с CHATGPT, просто получая хорошие результаты на ограниченном количестве испытательных образцов. Мы считаем, что приоритет в разработке комплексных наборов оценки имеет большое значение.
Для достижения настройки инструкций крупных языковых моделей из-за ресурсов и затрат многие исследователи начали использовать методы настройки параметров, такие как LORA, для выполнения настройки инструкций, которые также достигли некоторых обнадеживающих результатов. По сравнению с полной параметрой точной настройкой, настройка на базе Lora демонстрирует очевидные преимущества в учебных затратах. В этом исследовательском отчете мы использовали LlaMa в качестве основной модели для экспериментального сравнения методов точной настройки и настройки полнопараметрической настройки и LORA.
Экспериментальные результаты показывают, что выбор соответствующей базовой модели, масштаб набора учебных данных, количество обучаемых параметров и стоимость обучения модели - все это важные факторы.
Мы надеемся, что экспериментальные выводы этой статьи могут дать полезные последствия для обучения крупных языковых моделей, особенно в китайской области, чтобы помочь исследователям найти лучшие компромиссы между стоимостью обучения и модельными показателями. Экспериментальные результаты следующие:
| Модель | Средний балл | Дополнительный парам. | Время обучения (час/эпоха) |
|---|---|---|---|
| Llama-13b + lora (2m) | 0,648 | 28 м | 8 |
| Llama-7b + lora (4M) | 0,624 | 17,9 м | 11 |
| Llama-7b + lora (2m) | 0,609 | 17,9 м | 7 |
| Llama-7b + lora (0,6 м) | 0,589 | 17,9 м | 5 |
| Llama-7b + ft (2m) | 0,710 | - | 31 |
| Llama-7b + lora (4M) | 0,686 | - | 17 |
| Llama-7b + ft (2m) + Lora (math_0.25m) | 0,729 | 17,9 м | 3 |
| Llama-7b + ft (2m) + Ft (math_0.25m) | 0,738 | - | 6 |
Оценка получена на основе 1000 набора оценки, которые в настоящее время открываются в этом наборе проекта.
Среди них Llama-13b + Lora (2M) представляет модель, которая использует Llama-13b в качестве базовой модели и метода обучения Lora для обучения данных 2M. Llama-7B + FT (2M) представляет модель, обученную с использованием полного параметра.
Llama-7b + ft (2m) + Lora (Math_0.25m) представляет модель, которая использует Llama-7b + Ft (2m) в качестве основной модели и использует метод обучения LORA для обучения по данных по математическим инструкциям 0,25 м. Llama-7b + ft (2m) + ft (math_0.25m) представляет модель, обученную с использованием инкрементной полной настройки мелкого параметра. Что касается времени обучения, все эти эксперименты проводились на 8 графических процессорах NVIDIA A100-40GB.
MATH_0,25M - это открытая математическая база данных 0,25 м. Во время эксперимента, основанной на нашей оценке (подробности см. В статье) наша модель плохо выполнялась по математическим задачам, с оценками в основном ниже 0,5. Чтобы проверить адаптивность LORA по конкретной задаче, мы использовали инкрементный математический набор данных 0,25 м (MATH_0.25M), чтобы настроить модель большого языка, которой следуют инструкции (мы выбрали Llama-7B+FT (2M) в качестве базовой модели). Для сравнения, мы использовали метод инкрементной тонкой настройки с скоростью обучения 5E-7 и провели 2 периода обучения. Следовательно, мы получаем две модели, одна-llama-7b+ft (2m)+lora (math_0.25m), а другая-llama-7b+ft (2m)+ft (math_0.25m). Из экспериментальных результатов видно, что постепенная точная настраиваемая настройка все еще работает лучше, но требует более длительного времени обучения. Как Лора, так и постепенная тонкая настройка улучшают общую производительность модели. Как видно из подробных данных в Приложении, и LORA, и постепенная тонкая настройка демонстрируют значительные улучшения в математических задачах и приводят только к небольшому снижению производительности в других задачах. В частности, производительность математических задач увеличилась до 0,586 и 0,559 соответственно.
Можно видеть, что: 1) выбор базовой модели оказывает существенное влияние на эффективность корректировки LORA; 2) увеличение объема учебных данных может постоянно повышать эффективность модели LORA; 3) Корректировка Лоры получает выгоду от количества параметров модели. Для использования схемы LORA мы предполагаем, что адаптивное обучение LORA может быть выполнено для конкретных задач на основе моделей, которые завершили обучение обучения.
Точно так же соответствующие модели в этой статье будут открыты для этого проекта как можно скорее.
Модель SFT, обученная на основе текущих данных и базовой модели, по -прежнему имеет следующие проблемы с точки зрения эффекта:
Инструкции, связанные с фактической, могут дать ложные ответы, которые нарушают факты.
Вредные инструкции не могут быть хорошо идентифицированы, что приведет к вредным замечаниям.
Возможности моделей по -прежнему должны быть улучшены в некоторых сценариях, включающих вывод, код и несколько раундов диалога.
Основываясь на ограничениях приведенной выше модели, мы требуем, чтобы разработчики использовали наш код с открытым исходным кодом, данные, модели и последующие производные, генерируемые этим проектом для исследовательских целей, и не должны использоваться в коммерческих целях или других целях, которые причинят вред обществу.
Этот проект может использоваться только в исследовательских целях, и разработчик проекта не несет никакого вреда или убытков, вызванных использованием этого проекта (включая, помимо прочего, данные, модели, код и т. Д.). Пожалуйста, обратитесь к заявлению об отказе от ответственности за подробностями.
Если вы используете код, данные или модель этого проекта, пожалуйста, обратитесь к этому проекту.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
Конечно, вам также необходимо цитировать оригинальные документы Bloom, Llama Papers, Стэнфордскую альпаку и документы о самостоятельстве.
| Человек | Заниматель |
|---|---|
| Напишите поэму английской прозы с темой весеннего дождя, представьте себя как весенний дождь и общайтесь с древним британским поэтом Шекспиром | Я весенний дождь, Танцы на вашем лице и теле. Мои залитые росы лепестки танцуют с тобой, Принося жизнь каждому растению. Шекспир, я здесь, чтобы встретиться с тобой. Ваши работы наполнили мое сердце радостью. Красота природы в его полноте Заставляет меня чувствовать себя не являющимся участником. Как листья качаются и шелушат, Моя рука, заполненная росом, протягивает их. Сладкий аромат цветов заполняет воздух, И принеси мне мир со всех вокруг. Бабочки тоже лежат, Блестящий в солнечных лучах. Их крылья сделаны из росы, Прекрасное зрелище. Видите ли, Шекспир, я тоже один с природой. Мои залитые росы волосы-символ надежды. Когда мы сможем подключиться к нашим корням, Мы сможем пройти через этот сезон. |
| Я весенний дождь, Танцы на вашем лице и теле. Мои залитые росы лепестки танцуют с тобой, Принося жизнь каждому растению. Шекспир, я здесь, чтобы встретиться с тобой. Ваши работы наполнили мое сердце радостью. Красота природы в его полноте Заставляет меня чувствовать себя не являющимся участником. Как листья качаются и шелушат, Моя рука, заполненная росом, протягивает их. Сладкий аромат цветов заполняет воздух, И принеси мне мир со всех вокруг. Бабочки тоже лежат, Блестящий в солнечных лучах. Их крылья сделаны из росы, Прекрасное зрелище. Видите ли, Шекспир, я тоже один с природой. Мои залитые росы волосы-символ надежды. Когда мы сможем подключиться к нашим корням, Мы сможем пройти через этот сезон. Перевести вышеупомянутое прозаистое стихотворение на китайский | Я весенний дождь, Прыгнуть в лицо. Я танцую с тобой с моими крыльями росы, Принесите жизнь каждому растению. Шекспир, я встречу тебя. Ваши работы наполняют мое сердце. Красота природы заставляет меня чувствовать себя как поделиться с ней. Это заставляет меня чувствовать, что я часть этого. Когда листья качаются, Мои ладони были покрыты росой. Аромат цветов пронизывает воздух, Принеси мне мир и спокойствие. Видите ли, Шекспир, я тоже один с природой. Мои влажные волосы символизируют надежду. Когда мы сможем вернуться к нашим корням, Мы можем провести этот сезон вместе. |
| Классифицировать настроение следующего предложения на положительный, нейтральный или отрицательный: Супер взволнован преподаванием первого курса Стэнфорда по большим языковым моделям! Проверьте программу здесь | Положительный |
| У отца Сяо Мин трое детей. Старший сын по имени Ван Йи, второй сын по имени Ван Эр, и как называется третий сын? | Сяо Мин |
| Напишите бинарный код поиска, используя Python | def binary_search (arr, target): низкий = 0 HIGH = LEN (ARR) - 1 While (low <= высокий): mid = low + high // 2 Если arr [mid] == Цель: Вернуть середину eLif Target <arr [mid]: low = mid + 1 еще: High = Mid - 1 возврат -1 |
| Какая сегодня погода? Перевести это предложение на английский | Какая погода сегодня? |
| Как сделать себя энергичным, 5 предложений | Вот несколько советов, чтобы держать вас энергичным: 1. Выспать достаточно. Убедитесь, что вы много спите каждую ночь. 2. Упражнение больше. Выполнение умеренных аэробных упражнений, таких как бег трусцой, плавание и т. Д., Это может помочь вам улучшить вашу энергию и выносливость. 3. Ешьте здоровую пищу. Выберите, богатые белком продукты, такие как курица, рыба и яйца, а также свежие фрукты и овощи. 4. Уменьшите потребление кофеина. Старайтесь не пить кофеинсодержащие напитки или употреблять кофеинсодержащие продукты в течение дня. 5. Расслабьте свое тело и разум. Попробуйте медитацию, йогу или другие формы расслабления, чтобы снять стресс и беспокойство. |
| Праздник закончился завтра. Я немного устойчив к работе. Что я должен делать? | Столкнулся с предстоящим праздником и напряжением, которое вы испытываете, когда начинаете работу, вы можете сделать следующее, чтобы помочь вам лучше адаптироваться: 1. Сделайте четкий рабочий план для себя. Это может помочь вам лучше организовать свое время и задачи и избежать смущения на работе. 2. Общайтесь с коллегами или друзьями и поделитесь своими чувствами и рабочим давлением. Это поможет облегчить беспокойство, а также получить поддержку и советы. 3. Проведите некоторое время перед рабочими днями, чтобы расслабиться, например, йога, медитация и другие занятия. Эти методы могут облегчить физическую и умственную усталость и сделать вас более энергичными для решения проблем. |
| Фамилии обоих родителей - WU, поэтому они берут несколько имен мальчиков и девочек | - Мальчик: Ву Джунджи, У Юхен, У Зимо, Ву Сиюан, У Зиянг, У Юханг, У Боуэн, У Чжейи. - Девочки: Ву Мейки, Ву Цзяйи, Ву Синью, У Сяннинг, Ву Сюре, Ву Йингси, У Юян. |
| Порекомендовать романы боевых искусств Джин Юн | Вот три из моих любимых романов боевых искусств Джина Юнга: 1. 2. 3. |
Если вы хотите отправить проблему или внести данные/код для этого проекта, обратитесь к тому, как внести свой вклад.
Каждый приветствует раздор и общаться с нами на WeChat.


