BELLE
v0.95 发布
 เบลล์: เป็นเครื่องมือโมเดลภาษาขนาดใหญ่ของทุกคน
เบลล์: เป็นเครื่องมือโมเดลภาษาขนาดใหญ่ของทุกคนอ่านสิ่งนี้เป็นภาษาอังกฤษ
เป้าหมายของโครงการนี้คือการส่งเสริมการพัฒนาชุมชนโอเพ่นซอร์สขนาดใหญ่ของจีนบทสนทนาและวิสัยทัศน์คือการเป็นเครื่องมือ LLM ที่สามารถช่วยเหลือทุกคนได้
เมื่อเทียบกับวิธีการฝึกอบรมแบบจำลองภาษาขนาดใหญ่ก่อนหน้านี้เบลล์มุ่งเน้นไปที่วิธีที่จะช่วยให้ทุกคนได้รับแบบจำลองภาษาของตนเองด้วยเอฟเฟกต์ที่ดีที่สุดและความสามารถด้านประสิทธิภาพการเรียนการสอนตามแบบจำลองภาษาโอเพนซอร์สก่อนการฝึกอบรมภาษาขนาดใหญ่และลดการวิจัยและเกณฑ์การใช้งานของแบบจำลองภาษาขนาดใหญ่โดยเฉพาะแบบจำลองภาษาขนาดใหญ่ในภาษาจีน ด้วยเหตุนี้โครงการ Belle จะยังคงเปิดข้อมูลการฝึกอบรมการเรียนการสอนแบบจำลองที่เกี่ยวข้องรหัสการฝึกอบรมสถานการณ์แอปพลิเคชัน ฯลฯ และจะประเมินผลกระทบของข้อมูลการฝึกอบรมที่แตกต่างกันอัลกอริทึมการฝึกอบรม ฯลฯ เกี่ยวกับประสิทธิภาพของโมเดล Belle ได้รับการปรับให้เหมาะสมสำหรับภาษาจีนและการปรับแต่งแบบจำลองใช้ข้อมูลที่ผลิตโดย ChatGPT เท่านั้น (ไม่มีข้อมูลอื่น ๆ )
รูปต่อไปนี้เป็นรุ่น Belle-7B ที่สามารถเรียกใช้ 4 บิตเชิงปริมาณในด้านอุปกรณ์โดยใช้แอพและทำงานแบบเรียลไทม์บน M1 MAX CPU (ไม่เร่งความเร็ว) สำหรับรายละเอียดเกี่ยวกับการดาวน์โหลดแอปโปรดดูที่แอพสนับสนุนการดาวน์โหลดรุ่นและคำแนะนำสำหรับการใช้งาน ลิงค์ดาวน์โหลดแอพนี้มีเฉพาะในเวอร์ชัน Mac OS เท่านั้น ต้องดาวน์โหลดโมเดลแยกต่างหาก หลังจากแบบจำลองเป็นปริมาณการสูญเสียผลจะเห็นได้ชัดและเราจะศึกษาวิธีปรับปรุงวิธีการปรับปรุง
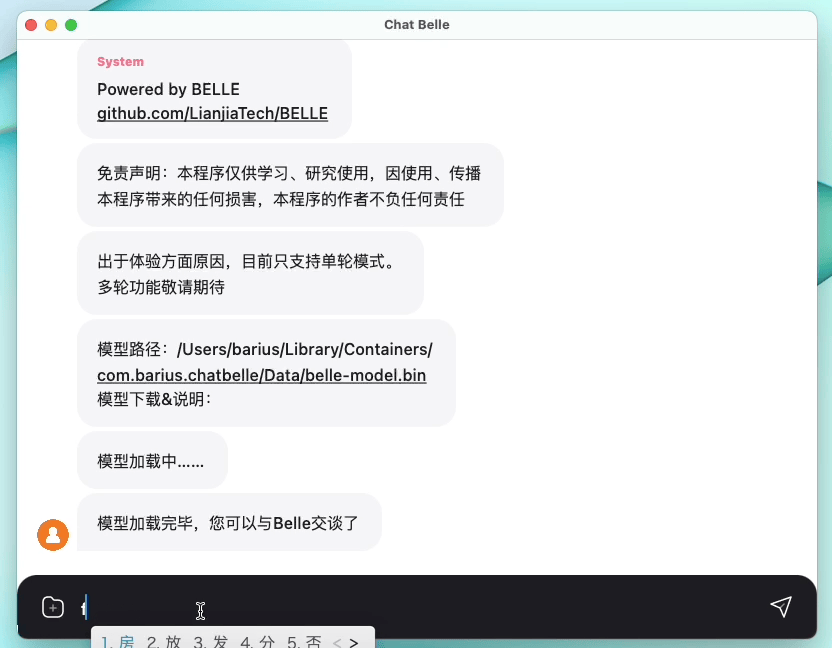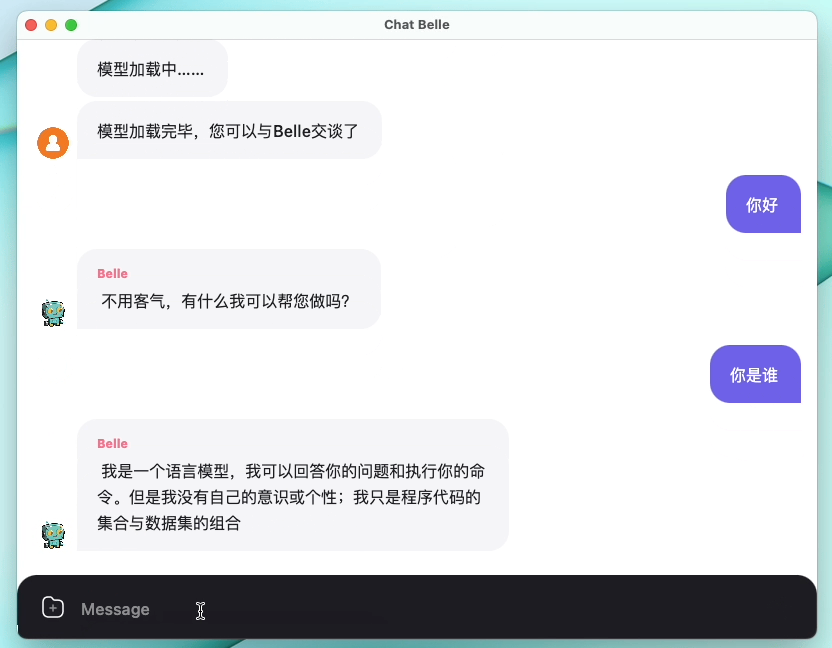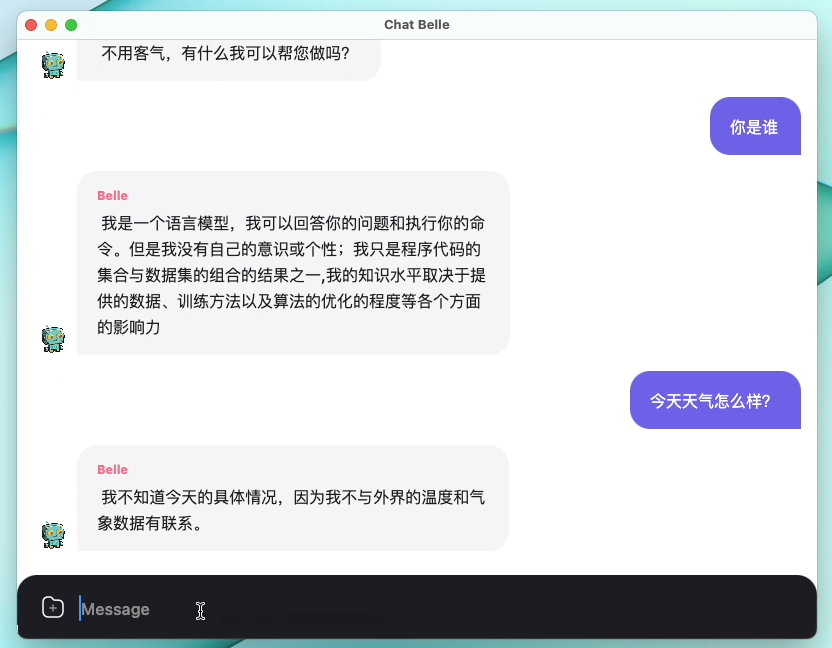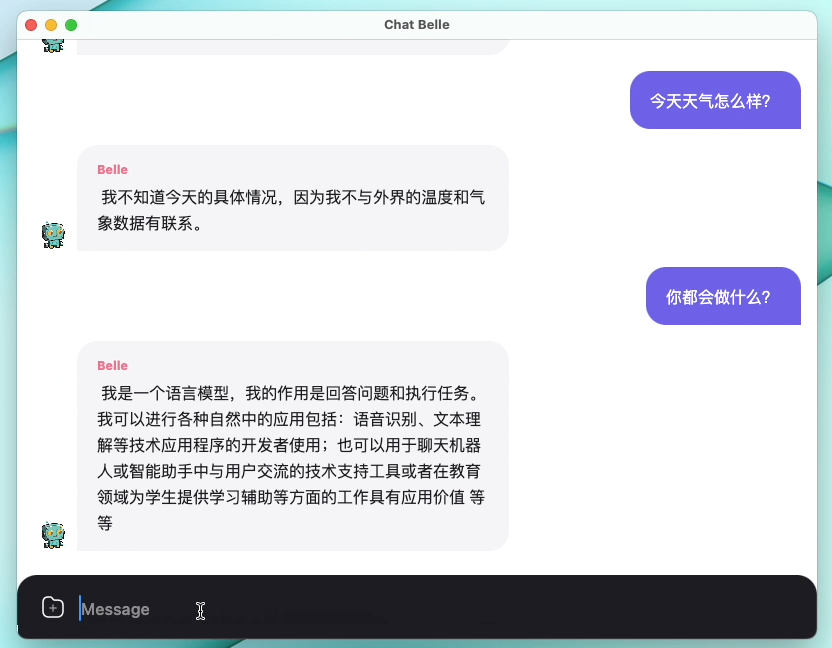
ดูรายละเอียดของ Belle/Train การใช้รหัสการฝึกอบรมที่ง่ายที่สุดเท่าที่จะเป็นไปได้
สำหรับรายละเอียดดู Belle/Data/1.5m โปรดดูชุดข้อมูลภาษาจีนที่สร้างโดย Stanford Alpaca 1m + 0.5m;
ชุดข้อมูลที่เปิดอย่างต่อเนื่องโปรดดูที่ Belle/Data/10m สำหรับรายละเอียด
สำหรับรายละเอียดดู Belle/Eval ชุดทดสอบ 1K+ และพรอมต์การให้คะแนนที่สอดคล้องกัน มันมีหลายหมวดหมู่และใช้ GPT-4 หรือ CHATGPT เพื่อให้คะแนน นอกจากนี้ยังมีเว็บเพจการให้คะแนนเพื่อใช้งานง่ายสำหรับเคสเดียว ทุกคนยินดีที่จะให้กรณีทดสอบเพิ่มเติมผ่าน PR
ดูรายละเอียดของ Belle/Models
แบบจำลองสำหรับการปรับแต่งตาม meta llama2: belle-llama2-13b-chat-0.4m
แบบจำลองที่ใช้การปรับแต่งตาม Meta Llama: Belle-llama-7b-0.6m-enc, Belle-llama-7b-2m-enc, Belle-llama-7b-2m-gptq-enc, belle-llama-13b-2m-enc, belle-on-open-datasets คำศัพท์.
โมเดลที่ได้รับการปรับปรุงตาม Bloomz-7b1-MT: Belle-7b-0.2m, Belle-7b-0.6m, Belle-7b-1M, Belle-7b-2m
ดูรายละเอียด Belle/GPTQ อ้างถึงการดำเนินการของ GPTQ เพื่อหาจำนวนโมเดลที่เกี่ยวข้องในโครงการนี้
จัดเตรียมรหัสการอนุมานที่เรียกใช้บน colab
สำหรับรายละเอียดดู Belle/Chat แอพพลิเคชั่นแชทแบบจำลองภาษาขนาดใหญ่แบบออฟไลน์แบบข้ามแพลตฟอร์มตามโมเดล Belle การใช้โมเดลออฟไลน์เชิงปริมาณที่มีกระพือมันสามารถทำงานบน MacOS (รองรับ), Windows, Android, iOS และอุปกรณ์อื่น ๆ
ดูรายละเอียดของ Belle/Docs ซึ่งจะอัปเดตรายงานการวิจัยที่เกี่ยวข้องกับโครงการนี้เป็นประจำ
ยินดีต้อนรับสู่การมีส่วนร่วมเพิ่มเติมผ่านปัญหา!
เพื่อส่งเสริมการพัฒนาแบบจำลองภาษาโอเพนซอร์สขนาดใหญ่เราได้ลงทุนพลังงานจำนวนมากเพื่อพัฒนาโมเดลราคาประหยัดที่สามารถคล้ายกับ CHATGPT อย่างแรกเพื่อปรับปรุงประสิทธิภาพการทำงานและการฝึกอบรม/การอนุมานของแบบจำลองในสนามจีนเราได้ขยายคำศัพท์ของ Llama และดำเนินการฝึกอบรมก่อนการฝึกอบรมก่อนการฝึกอบรมฉบับที่ 3.4 พันล้านคำศัพท์ภาษาจีน
นอกจากนี้เราจะเห็นได้ว่าคำแนะนำที่ได้รับการฝึกอบรมจากข้อมูลที่สร้างขึ้นตาม chatgpt คือ: 1) อ้างถึงข้อมูลการประมวลผลตนเองที่ได้รับตาม GPT3.5 โดย Alpaca; 2) อ้างถึงข้อมูล Instruct ตัวเองที่ได้รับจาก GPT4 โดย Alpaca; 3) ข้อมูล ShareGPT ที่แชร์โดยผู้ใช้โดยใช้ CHATGPT ที่นี่เรามุ่งเน้นไปที่การสำรวจผลกระทบของหมวดหมู่ข้อมูลการฝึกอบรมเกี่ยวกับประสิทธิภาพของโมเดล โดยเฉพาะเราตรวจสอบปัจจัยต่าง ๆ เช่นปริมาณคุณภาพและการกระจายภาษาของข้อมูลการฝึกอบรมรวมถึงข้อมูลการสนทนาหลายรอบจีนที่เรารวบรวมตัวเองและชุดข้อมูลแนวทางที่มีคุณภาพสูง
เพื่อประเมินผลที่ดีขึ้นเราใช้ชุดการประเมินผล 1,000 ตัวอย่างและเก้าสถานการณ์จริงเพื่อทดสอบโมเดลต่าง ๆ ในขณะที่ให้ข้อมูลเชิงลึกที่มีคุณค่าผ่านการวิเคราะห์เชิงปริมาณเพื่อส่งเสริมการพัฒนาแบบจำลองการแชทโอเพนซอร์สได้ดีขึ้น
เป้าหมายของการศึกษานี้คือการเติมช่องว่างในการประเมินที่ครอบคลุมของแบบจำลองการแชทโอเพนซอร์สเพื่อให้การสนับสนุนที่แข็งแกร่งสำหรับความคืบหน้าอย่างต่อเนื่องในสาขานี้
ผลการทดลองมีดังนี้:
| ปัจจัย | รุ่นฐาน | ข้อมูลการฝึกอบรม | คะแนน _w/o_others |
| การขยายคำศัพท์ | llama-7b-ext | ZH (Alpaca-3.5 & 4) + ShareGpt | 0.670 |
| LLAMA-7B | ZH (Alpaca-3.5 & 4) + ShareGpt | 0.652 | |
| คุณภาพข้อมูล | llama-7b-ext | ZH (Alpaca-3.5) | 0.642 |
| llama-7b-ext | ZH (Alpaca-4) | 0.693 | |
| การกระจายภาษาข้อมูล | llama-7b-ext | ZH (Alpaca-3.5 & 4) | 0.679 |
| llama-7b-ext | EN (Alpaca-3.5 & 4) | 0.659 | |
| llama-7b-ext | ZH (Alpaca-3.5 & 4) + ShareGpt | 0.670 | |
| llama-7b-ext | EN (Alpaca-3.5 & 4) + ShareGpt | 0.668 | |
| มาตราส่วนข้อมูล | llama-7b-ext | ZH (Alpaca-3.5 & 4) + ShareGpt | 0.670 |
| llama-7b-ext | ZH (Alpaca-3.5 & 4) + ShareGpt + Belle-0.5m-clean | 0.762 | |
| - | CHATGPT | - | 0.824 |
ในหมู่พวกเขา Belle-0.5m-Clean ทำความสะอาดข้อมูล 0.5m จากข้อมูลคำสั่ง 2.3 ล้านซึ่งมีข้อมูลการสนทนารอบรอบเดียวและหลายรอบซึ่งไม่ใช่ชุดข้อมูลชุดเดียวกับข้อมูล 0.5m ที่เปิดก่อนหน้านี้
ควรเน้นว่า ผ่านการวิเคราะห์กรณีเราพบว่าชุดการประเมินผลของเรามีข้อ จำกัด ในแง่ของความครอบคลุมซึ่งนำไปสู่ความไม่สอดคล้องกันระหว่างการปรับปรุงคะแนนแบบจำลองและประสบการณ์ผู้ใช้จริง การสร้างชุดการประเมินคุณภาพสูงเป็นความท้าทายที่ยิ่งใหญ่เพราะต้องใช้สถานการณ์การใช้งานมากที่สุดเท่าที่จะเป็นไปได้ในขณะที่ยังคงความยากลำบาก หากการประเมินตัวอย่างส่วนใหญ่ยากเกินไปทุกรุ่นจะทำงานได้ไม่ดีทำให้มันท้าทายที่จะระบุผลกระทบของกลยุทธ์การฝึกอบรมที่หลากหลาย ในทางตรงกันข้ามหากตัวอย่างทั้งหมดได้รับการประเมินค่อนข้างง่ายการประเมินจะสูญเสียค่าเปรียบเทียบ นอกจากนี้ยังมีความจำเป็นเพื่อให้แน่ใจว่าข้อมูลการประเมินยังคงเป็นอิสระจากข้อมูลการฝึกอบรม
จากการสังเกตเหล่านี้เราเตือนไม่ให้สมมติว่าโมเดลได้รับระดับประสิทธิภาพที่เทียบเท่ากับ ChatGPT โดยเพียงแค่ได้รับผลลัพธ์ที่ดีจากตัวอย่างการทดสอบจำนวน จำกัด เราเชื่อว่าการจัดลำดับความสำคัญของการพัฒนาชุดการประเมินที่ครอบคลุมนั้นมีความสำคัญอย่างยิ่ง
เพื่อให้บรรลุการปรับแต่งการเรียนการสอนแบบจำลองภาษาขนาดใหญ่เนื่องจากทรัพยากรและค่าใช้จ่ายนักวิจัยหลายคนได้เริ่มใช้เทคนิคการปรับแต่งพารามิเตอร์ที่มีประสิทธิภาพเช่น LORA เพื่อทำการปรับแต่งการสอน เมื่อเปรียบเทียบกับการปรับแต่งแบบเต็มพารามิเตอร์การปรับแต่งที่ใช้ LORA แสดงให้เห็นถึงข้อดีที่ชัดเจนในค่าใช้จ่ายในการฝึกอบรม ในรายงานการวิจัยนี้เราใช้ Llama เป็นแบบจำลองพื้นฐานในการทดลองเปรียบเทียบการปรับแต่งแบบเต็มพารามิเตอร์และวิธีการปรับแต่งตาม LORA
ผลการทดลองแสดงให้เห็นว่าการเลือกแบบจำลองพื้นฐานที่เหมาะสมขนาดของชุดข้อมูลการฝึกอบรมจำนวนพารามิเตอร์ที่เรียนรู้ได้และค่าใช้จ่ายในการฝึกอบรมแบบจำลองเป็นปัจจัยสำคัญทั้งหมด
เราหวังว่าข้อสรุปการทดลองของบทความนี้สามารถให้ผลกระทบที่เป็นประโยชน์สำหรับการฝึกอบรมแบบจำลองภาษาขนาดใหญ่โดยเฉพาะในสาขาจีนเพื่อช่วยให้นักวิจัยพบการแลกเปลี่ยนระหว่างต้นทุนการฝึกอบรมที่ดีขึ้นและประสิทธิภาพของแบบจำลอง ผลการทดลองมีดังนี้:
| แบบอย่าง | คะแนนเฉลี่ย | พารามิเตอร์เพิ่มเติม | เวลาฝึกอบรม (ชั่วโมง/ยุค) |
|---|---|---|---|
| LLAMA-13B + LORA (2M) | 0.648 | 28m | 8 |
| LLAMA-7B + LORA (4M) | 0.624 | 17.9m | 11 |
| LLAMA-7B + LORA (2M) | 0.609 | 17.9m | 7 |
| LLAMA-7B + LORA (0.6M) | 0.589 | 17.9m | 5 |
| LLAMA-7B + FT (2M) | 0.710 | - | 31 |
| LLAMA-7B + LORA (4M) | 0.686 | - | 17 |
| LLAMA-7B + FT (2M) + Lora (Math_0.25m) | 0.729 | 17.9m | 3 |
| LLAMA-7B + FT (2M) + ft (math_0.25m) | 0.738 | - | 6 |
คะแนนจะได้รับตามชุดการประเมินผล 1,000 ชุดที่เปิดอยู่ในชุดโครงการนี้
ในหมู่พวกเขา LLAMA-13B + LORA (2M) แสดงถึงรูปแบบที่ใช้ LLAMA-13B เป็นแบบจำลองพื้นฐานและวิธีการฝึกอบรม LORA เพื่อฝึกอบรมข้อมูลการเรียนการสอน 2M LLAMA-7B + FT (2M) แสดงถึงรุ่นที่ผ่านการฝึกอบรมโดยใช้การปรับค่าพารามิเตอร์แบบเต็ม
LLAMA-7B + FT (2M) + LORA (MATH_0.25M) แสดงถึงรูปแบบที่ใช้ LLAMA-7B + FT (2M) เป็นแบบจำลองพื้นฐานและใช้วิธีการฝึกอบรม LORA สำหรับการฝึกอบรมข้อมูลการเรียนการสอนทางคณิตศาสตร์ 0.25M LLAMA-7B + FT (2M) + FT (MATH_0.25M) หมายถึงโมเดลที่ผ่านการฝึกอบรมโดยใช้พารามิเตอร์ที่เพิ่มขึ้นอย่างละเอียด เกี่ยวกับเวลาการฝึกอบรมการทดลองทั้งหมดเหล่านี้ดำเนินการใน GPU 8 NVIDIA A100-40GB
MATH_0.25M เป็นฐานข้อมูลทางคณิตศาสตร์ที่เปิดกว้าง 0.25M ในระหว่างการทดลองขึ้นอยู่กับการประเมินของเรา (ดูเอกสารสำหรับรายละเอียด) แบบจำลองของเราทำงานได้ไม่ดีในงานคณิตศาสตร์โดยมีคะแนนต่ำกว่า 0.5 ในการตรวจสอบความสามารถในการปรับตัวของ LORA ในงานเฉพาะเราใช้ชุดข้อมูลทางคณิตศาสตร์ 0.25m ที่เพิ่มขึ้น (MATH_0.25M) เพื่อปรับรูปแบบภาษาขนาดใหญ่ที่คำแนะนำดังต่อไปนี้ (เราเลือก LLAMA-7B+FT (2M) เป็นแบบจำลองพื้นฐาน) สำหรับการเปรียบเทียบเราใช้วิธีการปรับจูนที่เพิ่มขึ้นด้วยอัตราการเรียนรู้ 5E-7 และดำเนินการฝึกอบรม 2 ช่วงเวลา ดังนั้นเราจึงได้รับสองรุ่นหนึ่งคือ Llama-7b+ft (2m)+Lora (Math_0.25m) และอื่น ๆ คือ Llama-7b+ft (2m)+ft (Math_0.25m) จากผลการทดลองจะเห็นได้ว่าการปรับจูนที่เพิ่มขึ้นยังคงทำงานได้ดีขึ้น แต่ต้องใช้เวลาในการฝึกอบรมนานขึ้น ทั้ง LORA และการปรับจูนที่เพิ่มขึ้นช่วยปรับปรุงประสิทธิภาพโดยรวมของโมเดล ดังที่เห็นได้จากข้อมูลรายละเอียดในภาคผนวกทั้ง LORA และการปรับแต่งที่เพิ่มขึ้นแสดงการปรับปรุงที่สำคัญในงานคณิตศาสตร์และนำไปสู่การเสื่อมสภาพของประสิทธิภาพเล็กน้อยในงานอื่น ๆ โดยเฉพาะประสิทธิภาพของงานทางคณิตศาสตร์เพิ่มขึ้นเป็น 0.586 และ 0.559 ตามลำดับ
จะเห็นได้ว่า: 1) การเลือกแบบจำลองพื้นฐานมีผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพของการปรับ Lora; 2) การเพิ่มปริมาณข้อมูลการฝึกอบรมสามารถปรับปรุงประสิทธิภาพของแบบจำลอง LORA ได้อย่างต่อเนื่อง 3) การปรับ LORA ได้รับประโยชน์จากจำนวนพารามิเตอร์แบบจำลอง สำหรับการใช้โครงการ LORA เราขอแนะนำว่าการฝึกอบรม LORA Adaptive สามารถทำได้สำหรับงานเฉพาะตามแบบจำลองที่ได้เรียนรู้การเรียนการสอนเสร็จ
ในทำนองเดียวกันโมเดลที่เกี่ยวข้องในบทความนี้จะเปิดให้โครงการนี้โดยเร็วที่สุด
โมเดล SFT ที่ผ่านการฝึกอบรมตามข้อมูลปัจจุบันและโมเดลพื้นฐานยังคงมีปัญหาดังต่อไปนี้ในแง่ของผลกระทบ:
คำแนะนำที่เกี่ยวข้องกับข้อเท็จจริงอาจสร้างคำตอบที่ผิดพลาดซึ่งละเมิดข้อเท็จจริง
คำแนะนำที่เป็นอันตรายไม่สามารถระบุได้อย่างดีซึ่งจะนำไปสู่คำพูดที่เป็นอันตราย
ความสามารถของโมเดลยังคงต้องได้รับการปรับปรุงในบางสถานการณ์ที่เกี่ยวข้องกับการอนุมานรหัสและบทสนทนาหลายรอบ
ตามข้อ จำกัด ของโมเดลข้างต้นเรากำหนดให้นักพัฒนาใช้รหัสโอเพ่นซอร์สข้อมูลโมเดลและอนุพันธ์ที่ตามมาที่สร้างขึ้นโดยโครงการนี้เพื่อวัตถุประสงค์ในการวิจัยและจะไม่ถูกใช้เพื่อวัตถุประสงค์ทางการค้าหรือวัตถุประสงค์อื่น ๆ ที่จะก่อให้เกิดอันตรายต่อสังคม
โครงการนี้สามารถใช้เพื่อวัตถุประสงค์ในการวิจัยเท่านั้นและผู้พัฒนาโครงการไม่ได้รับอันตรายหรือการสูญเสียใด ๆ ที่เกิดจากการใช้โครงการนี้ (รวมถึง แต่ไม่ จำกัด เฉพาะข้อมูลโมเดลรหัส ฯลฯ ) โปรดดูรายละเอียดข้อจำกัดความรับผิดชอบ
หากคุณใช้รหัสข้อมูลหรือรูปแบบของโครงการนี้โปรดดูที่โครงการนี้
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
แน่นอนว่าคุณต้องอ้างถึงเอกสาร Bloom ต้นฉบับเอกสาร Llama, Stanford Alpaca และเอกสารที่มีความสำคัญด้วยตนเอง
| มนุษย์ | ผู้ช่วย |
|---|---|
| เขียนบทกวีร้อยแก้วภาษาอังกฤษด้วยธีมของฝนฤดูใบไม้ผลิลองจินตนาการว่าตัวเองเป็นฝนฤดูใบไม้ผลิและสื่อสารกับเชกสเปียร์กวีชาวอังกฤษโบราณ | ฉันคือฝนฤดูใบไม้ผลิ เต้นรำบนใบหน้าและร่างกายของคุณ กลีบดอกน้ำค้างของฉันเต้นกับคุณ นำชีวิตมาสู่ทุกพืช เช็คสเปียร์ฉันมาที่นี่เพื่อพบคุณ ผลงานของคุณทำให้หัวใจของฉันเต็มไปด้วยความสุข ความงามของธรรมชาติในความบริบูรณ์ ทำให้ฉันรู้สึกเหมือนเป็นผู้เข้าร่วม ในขณะที่ใบไม้แกว่งไปมาและเป็นสนิมโดย มือที่เต็มไปด้วยน้ำค้างของฉันเอื้อมมือไปหาพวกเขา กลิ่นหอมหวานของดอกไม้เติมอากาศ และนำความสงบสุขมาให้ฉันจากทั่วทุกมุม ผีเสื้อพุ่งออกมาเช่นกัน เปล่งประกายในรังสีของดวงอาทิตย์ ปีกของพวกเขาทำจากน้ำค้าง ภาพที่สวยงามที่จะเห็น คุณเห็นว่าเช็คสเปียร์ฉันเป็นหนึ่งเดียวกับธรรมชาติ ผมที่เต็มไปด้วยน้ำค้างของฉันเป็นสัญลักษณ์ของความหวัง สำหรับเวลาที่เราสามารถเชื่อมต่อกลับไปที่รากของเรา เราจะสามารถทำมันได้ตลอดฤดูกาลนี้ |
| ฉันคือฝนฤดูใบไม้ผลิ เต้นรำบนใบหน้าและร่างกายของคุณ กลีบดอกน้ำค้างของฉันเต้นกับคุณ นำชีวิตมาสู่ทุกพืช เช็คสเปียร์ฉันมาที่นี่เพื่อพบคุณ ผลงานของคุณทำให้หัวใจของฉันเต็มไปด้วยความสุข ความงามของธรรมชาติในความบริบูรณ์ ทำให้ฉันรู้สึกเหมือนเป็นผู้เข้าร่วม ในขณะที่ใบไม้แกว่งไปมาและเป็นสนิมโดย มือที่เต็มไปด้วยน้ำค้างของฉันเอื้อมมือไปหาพวกเขา กลิ่นหอมหวานของดอกไม้เติมอากาศ และนำความสงบสุขมาให้ฉันจากทั่วทุกมุม ผีเสื้อพุ่งออกมาเช่นกัน เปล่งประกายในรังสีของดวงอาทิตย์ ปีกของพวกเขาทำจากน้ำค้าง ภาพที่สวยงามที่จะเห็น คุณเห็นว่าเช็คสเปียร์ฉันเป็นหนึ่งเดียวกับธรรมชาติ ผมที่เต็มไปด้วยน้ำค้างของฉันเป็นสัญลักษณ์ของความหวัง สำหรับเวลาที่เราสามารถเชื่อมต่อกลับไปที่รากของเรา เราจะสามารถทำมันได้ตลอดฤดูกาลนี้ แปลบทกวีร้อยแก้วข้างต้นเป็นภาษาจีน | ฉันเป็นฝนฤดูใบไม้ผลิ กระโดดเข้ามาในใบหน้าของคุณ ฉันเต้นรำกับคุณด้วยปีกน้ำค้างของฉัน นำชีวิตมาสู่ทุกพืช เช็คสเปียร์ฉันจะพบคุณ งานของคุณเติมเต็มหัวใจของฉัน ความงามของธรรมชาติทำให้ฉันรู้สึกอยากแบ่งปันกับมัน มันทำให้ฉันรู้สึกว่าฉันเป็นส่วนหนึ่งของมัน เมื่อใบไม้แกว่งไปมา ฝ่ามือของฉันถูกปกคลุมไปด้วยน้ำค้าง กลิ่นหอมของดอกไม้แทรกซึมเข้าไปในอากาศ นำความสงบและความเงียบสงบมาให้ฉัน คุณเห็นว่าเช็คสเปียร์ฉันเป็นหนึ่งเดียวกับธรรมชาติ ผมเปียกของฉันเป็นสัญลักษณ์ของความหวัง เมื่อเราสามารถกลับไปที่รากของเราได้ เราสามารถใช้เวลาร่วมกันในฤดูกาลนี้ |
| จำแนกความเชื่อมั่นของประโยคต่อไปนี้เป็นบวกเป็นกลางหรือลบ: ตื่นเต้นสุด ๆ เกี่ยวกับการสอนหลักสูตรแรกของสแตนฟอร์ดเกี่ยวกับโมเดลภาษาขนาดใหญ่! ตรวจสอบหลักสูตรที่นี่ | เชิงบวก |
| พ่อของ Xiao Ming มีลูกสามคน ลูกชายคนโตที่เรียกว่าวังยี่ลูกชายคนที่สองเรียกว่าวังเอ่อและลูกชายคนที่สามเรียกว่าอะไร? | Xiao Ming |
| เขียนรหัสค้นหาไบนารีโดยใช้ Python | def binary_search (arr, target): ต่ำ = 0 High = Len (arr) - 1 ในขณะที่ (ต่ำ <= สูง): mid = ต่ำ + สูง // 2 ถ้า arr [mid] == เป้าหมาย: กลับกลาง Elif Target <arr [mid]: ต่ำ = กลาง + 1 อื่น: สูง = กลาง - 1 กลับ -1 |
| วันนี้อากาศเป็นอย่างไรบ้าง? แปลประโยคนี้เป็นภาษาอังกฤษ | วันนี้อากาศเป็นอย่างไร? |
| วิธีทำให้ตัวเองมีพลัง 5 คำแนะนำ | นี่คือเคล็ดลับที่จะทำให้คุณมีพลัง: 1. นอนหลับเพียงพอ ตรวจสอบให้แน่ใจว่าคุณนอนหลับได้มากทุกคืน 2. ออกกำลังกายมากขึ้น การออกกำลังกายแบบแอโรบิคในระดับปานกลางเช่นการวิ่งเหยาะๆว่ายน้ำ ฯลฯ สามารถช่วยคุณปรับปรุงพลังงานและความอดทนของคุณ 3. กินอาหารเพื่อสุขภาพ เลือกอาหารที่อุดมด้วยโปรตีนเช่นไก่ปลาและไข่รวมถึงผักและผลไม้สด 4. ลดปริมาณคาเฟอีน พยายามหลีกเลี่ยงการดื่มเครื่องดื่มที่มีคาเฟอีนหรือกินอาหารที่มีคาเฟอีนในระหว่างวัน 5. ผ่อนคลายร่างกายและจิตใจของคุณ ลองทำสมาธิโยคะหรือการผ่อนคลายในรูปแบบอื่น ๆ เพื่อบรรเทาความเครียดและความวิตกกังวล |
| วันหยุดสิ้นสุดในวันพรุ่งนี้ ฉันทนต่อการทำงานเล็กน้อย ฉันควรทำอย่างไร? | ต้องเผชิญกับวันหยุดที่กำลังจะมาถึงและความตึงเครียดที่คุณได้รับเมื่อคุณเริ่มทำงานคุณสามารถทำสิ่งต่อไปนี้เพื่อช่วยให้คุณปรับตัวได้ดีขึ้น: 1. ทำแผนการทำงานที่ชัดเจนสำหรับตัวคุณเอง สิ่งนี้สามารถช่วยให้คุณจัดระเบียบเวลาและงานของคุณได้ดีขึ้นและหลีกเลี่ยงความรู้สึกสับสนในที่ทำงาน 2. สื่อสารกับเพื่อนร่วมงานหรือเพื่อนและแบ่งปันความรู้สึกและความกดดันในการทำงาน สิ่งนี้จะช่วยบรรเทาความวิตกกังวลในขณะที่ได้รับการสนับสนุนและคำแนะนำ 3. ใช้เวลาก่อนวันทำงานเพื่อพักผ่อนเช่นโยคะการทำสมาธิและกิจกรรมอื่น ๆ วิธีการเหล่านี้สามารถบรรเทาความเหนื่อยล้าทางร่างกายและจิตใจและทำให้คุณมีพลังมากขึ้นเพื่อตอบสนองความท้าทาย |
| นามสกุลของพ่อแม่เป็นวูดังนั้นพวกเขาจึงใช้ชื่อของเด็กชายและเด็กหญิง | - Boy: Wu Junjie, Wu Yuchen, Wu Zimo, Wu Siyuan, Wu Zeyang, Wu Yuhang, Wu Bowen, Wu Zheyi - สาว ๆ : Wu Meiqi, Wu Jiayi, Wu Xinyu, Wu Xiangning, Wu Xuerou, Wu Yingshi, Wu Yuyan |
| แนะนำนวนิยายศิลปะการต่อสู้โดยจินยง | นี่คือนวนิยายศิลปะการต่อสู้ของจินยงที่ฉันโปรดปรานสามเล่ม: 1. "The Legend of the Condor Heroes" - นวนิยายที่เต็มไปด้วยภูมิปัญญาและปัญญาบอกเล่าเรื่องราวของ Guo Jing และ Huang Rong 2. "The Return of the Condor Heroes" - นี่เป็นเรื่องราวที่โรแมนติกและน่าประทับใจบอกเล่าเรื่องราวความรักระหว่างคู่ Xiaolongnu และ Yang Guo 3. "The Legend of the Condor Heroes" - นี่เป็นเรื่องราวที่งดงามและงดงามที่แสดงให้เห็นว่าผู้นำของลัทธิหมิงจางวูจิกลายเป็นฮีโร่ที่โดดเด่นอย่างไร |
หากคุณต้องการส่งปัญหาหรือมีส่วนร่วมข้อมูล/รหัสสำหรับโครงการนี้โปรดดูวิธีการมีส่วนร่วม
ทุกคนยินดีต้อนรับสู่ความไม่ลงรอยกันและสื่อสารกับเราใน WeChat


