BELLE
v0.95 发布
 Belle: Sei jeder große Sprachmodell Engine
Belle: Sei jeder große Sprachmodell EngineLesen Sie dies auf Englisch.
Ziel dieses Projekts ist es, die Entwicklung des chinesischen Dialogs Big Model Open Source Community zu fördern, und die Vision besteht darin, zu LLM -Engine zu werden, die allen helfen kann.
Im Vergleich zum Vorvertrag von Großsprachmodellen konzentriert sich Belle mehr darauf, wie jeder ein eigenes Sprachmodell erhalten kann, wobei die bestmöglichen Effekt- und Unterrichtsleistungsfunktionen auf der Grundlage von Open-Source-Modellen vor dem Training vorhanden sind, und die Forschungs- und Anwendungsschwelle von großen Sprachmodellen, insbesondere Großsprachenmodellen auf Chinesisch, zu reduzieren. Zu diesem Zweck wird das Belle -Projekt weiterhin die Schulungsdaten, verwandte Modelle, Schulungscode, Anwendungsszenarien usw. eröffnen und die Auswirkungen verschiedener Schulungsdaten, Trainingsalgorithmen usw. auf die Modellleistung weiterhin bewerten. Belle wurde für Chinesen optimiert, und die Modellabstimmung verwendet nur Daten, die von ChatGPT (ohne andere Daten) erstellt wurden.
Die folgende Abbildung ist ein Belle-7b-Modell, das mit der App 4-Bit-Quantisierung lokal auf der Geräteseite ausgeführt werden kann und in Echtzeit auf der M1 Max-CPU ausgeführt wird (nicht beschleunigt). Weitere Informationen zum App -Download für App finden Sie in der App -Unterstützung des Modells und den Anweisungen zur Verwendung. Der App -Download -Link ist derzeit nur in der Mac OS -Version verfügbar. Das Modell muss separat heruntergeladen werden. Nachdem das Modell quantifiziert wurde, ist der Effektverlust offensichtlich, und wir werden weiter untersuchen, wie es verbessert werden kann.
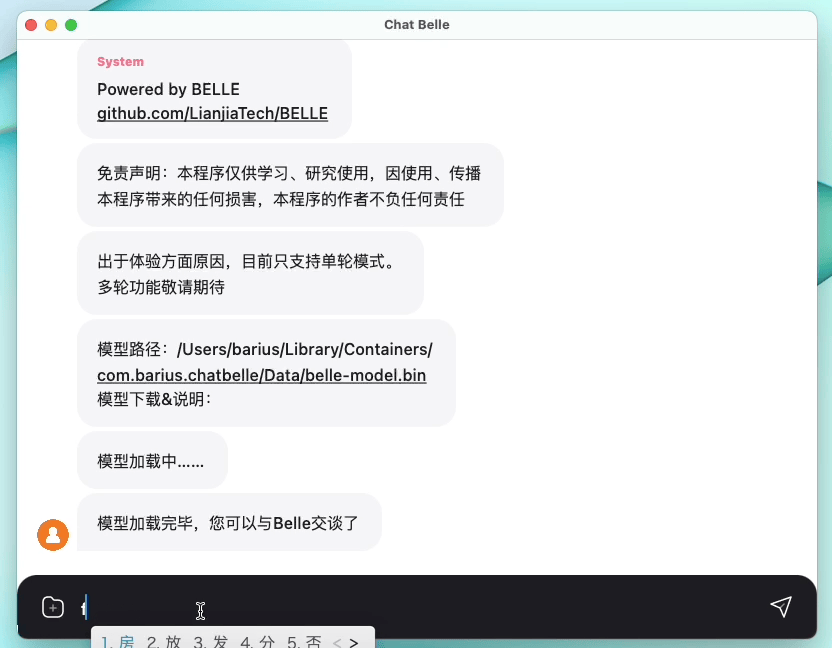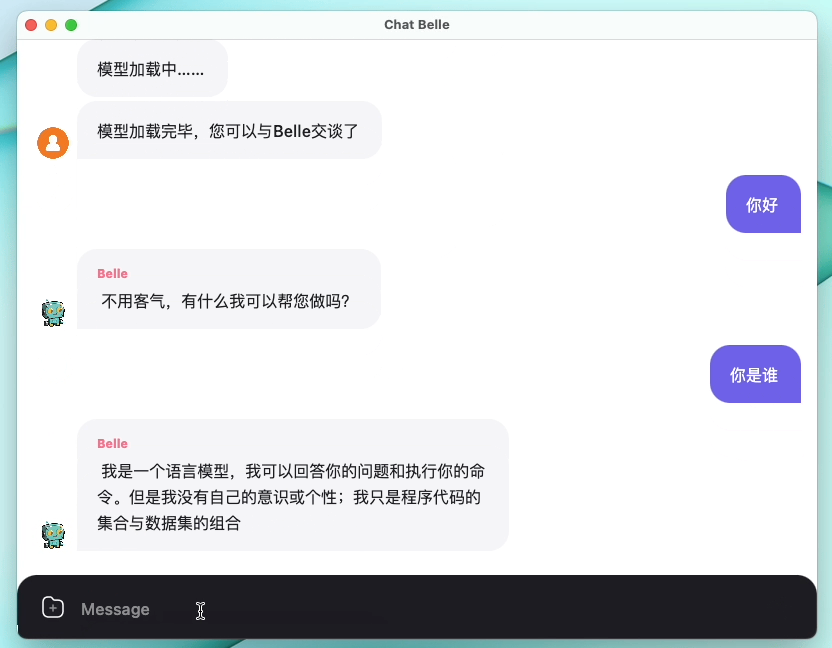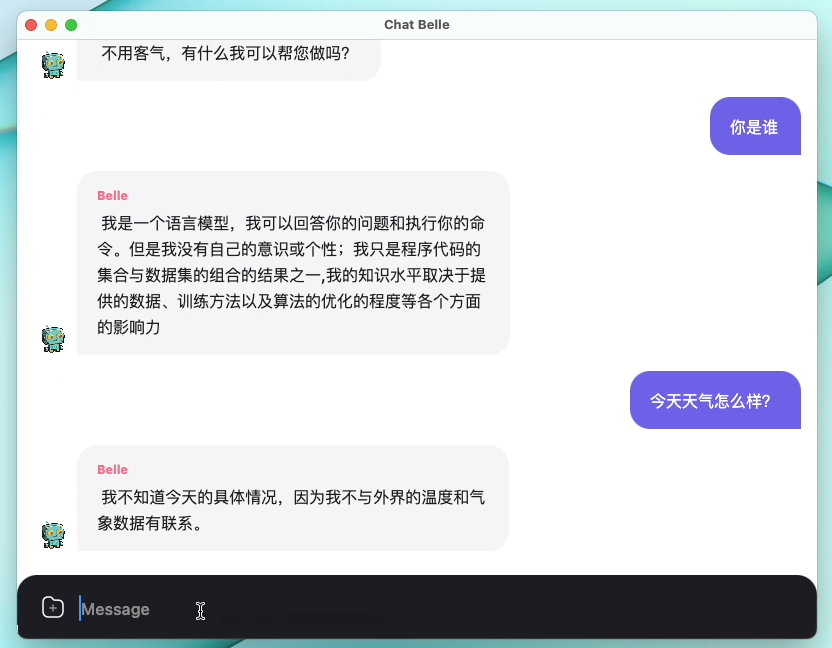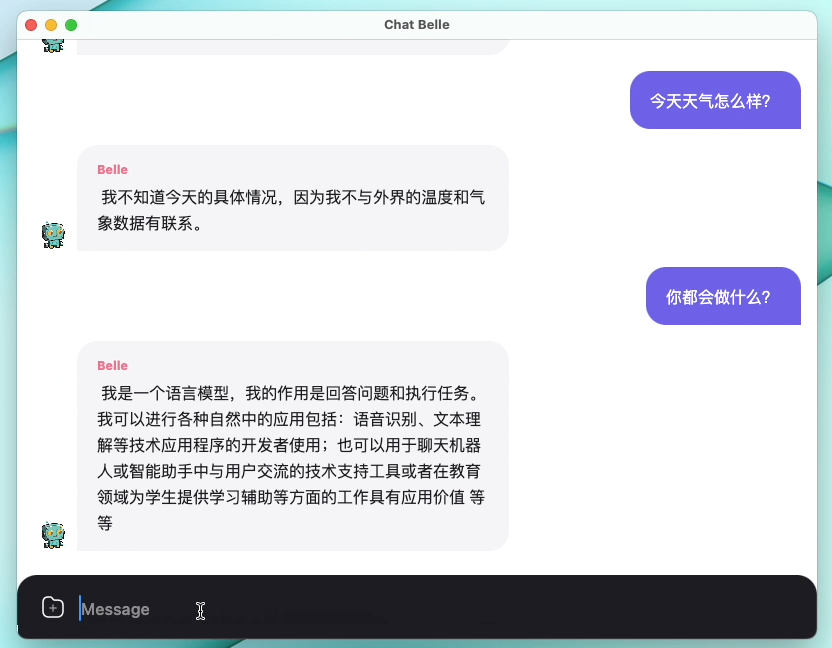
Einzelheiten finden Sie in Belle/Train, eine implementierende Schulungscode-Implementierung, die so vereinfacht wie möglich ist, DeepSpeed-Chat integriert, Finetune und Lora unterstützt und verwandte Docker bietet.
Weitere Informationen finden Sie unter Belle/Data/1,5M finden Sie im chinesischen Datensatz, der von Stanford Alpaca 1m + 0,5 m generiert wurde.
Der kontinuierliche Datensatz, der kontinuierlich geöffnet ist. Weitere Informationen finden Sie in Belle/Data/10m.
Einzelheiten finden Sie in Belle/Eval, einem 1k+ -Testsatz und der entsprechenden Bewertungsaufforderung. Es enthält mehrere Kategorien und verwendet GPT-4 oder Chatgpt, um zu punkten. Es bietet auch eine Bewertungs -Webseite, um für einen einzelnen Fall eine einfache Verwendung zu erhalten. Jeder ist herzlich eingeladen, über PR mehr Testfälle bereitzustellen.
Einzelheiten finden Sie in Belle/Models
Modell für das Tuning basierend auf Meta LLAMA2: Belle-Llama2-13b-chat-0,4m
Modelle, die die Stimmung basierend auf Meta Llama implementieren: Belle-Llama-7b-0,6m-Cent, Belle-Llama-7b-2M-Cern, Belle-Llama-7b-2M-Gptq-C. Wortschatz.
Modelle basierend auf Bloomz-7b1-MT: Belle-7b-0,2m, Belle-7b-0,6m, Belle-7b-1m, Belle-7b-2m
Einzelheiten finden Sie in Belle/GPTQ. In der Implementierung von GPTQ finden Sie die relevanten Modelle in diesem Projekt.
Bietet den Runnable -Inferenzcode Colab auf Colab
Weitere Informationen finden Sie unter Belle/Chat, eine plattformübergreifende Offline-Chat-App mit großer Sprache, die auf dem Belle-Modell basiert. Mit dem quantisierten Offline -Modell mit Flutter kann es auf MacOS (unterstützt), Windows, Android, iOS und anderen Geräten ausgeführt werden.
Einzelheiten finden Sie in Belle/Docs, in denen regelmäßig der Forschungsbericht zu diesem Projekt aktualisiert wird.
Willkommen, um mehr Propts durch das Problem beizutragen!
Um die Entwicklung von Open-Source-Modellen mit großer Sprache zu fördern, haben wir viel Energie investiert, um kostengünstige Modelle zu entwickeln, die ChatGPT ähneln können. Um die Leistung und Schulung/Inferenz-Effizienz des Modells im chinesischen Bereich zu verbessern, erweiterten wir zunächst das Vokabular von Lama weiter und führten eine sekundäre Vorausbildung auf 3,4 Milliarden chinesischem Wortschatz durch.
Darüber hinaus können wir feststellen, dass die auf ChatGPT erstellten Anweisungen geschulte Daten sind: 1) sich auf die auf Basis von GPT3.5 von Alpaka erhaltenen Selbstverstößen Daten beziehen; 2) Beziehen Sie sich auf die auf Basis von GPT4 durch Alpaka erhaltenen Selbstinstruktionsdaten; 3) Sharegpt -Daten, die von Benutzern gemeinsam genutzt werden, verwenden ChatGPT. Hier konzentrieren wir uns darauf, die Auswirkungen von Trainingsdatenkategorien auf die Modellleistung zu untersuchen. Insbesondere untersuchen wir Faktoren wie Quantität, Qualität und Sprachverteilung von Trainingsdaten sowie die chinesischen Multi-Runden-Dialogdaten, die wir selbst gesammelt haben, und einige öffentlich zugängliche Datensätze mit hochwertiger Qualität.
Um den Effekt besser zu bewerten, verwendeten wir einen Bewertungssatz von 1.000 Proben und neun realen Szenarien, um verschiedene Modelle zu testen und gleichzeitig durch quantitative Analyse wertvolle Erkenntnisse zu liefern, um die Entwicklung von Open -Source -Chat -Modellen besser zu fördern.
Ziel dieser Studie ist es, die Lücke in der umfassenden Bewertung von Open -Source -Chat -Modellen zu schließen, um eine starke Unterstützung für den weiteren Fortschritt in diesem Bereich zu bieten.
Die experimentellen Ergebnisse sind wie folgt:
| Faktor | Basismodell | Trainingsdaten | Score_W/O_TERS |
| Wortschatzerweiterung | Lama-7b-text | ZH (ALPACA-3,5 & 4) + SHAREGPT | 0,670 |
| Lama-7b | ZH (ALPACA-3,5 & 4) + SHAREGPT | 0,652 | |
| Datenqualität | Lama-7b-text | ZH (Alpaca-3.5) | 0,642 |
| Lama-7b-text | ZH (ALPACA-4) | 0,693 | |
| Datensprachverteilung | Lama-7b-text | ZH (Alpaca-3,5 & 4) | 0,679 |
| Lama-7b-text | EN (Alpaca-3,5 & 4) | 0,659 | |
| Lama-7b-text | ZH (ALPACA-3,5 & 4) + SHAREGPT | 0,670 | |
| Lama-7b-text | EN (ALPACA-3,5 & 4) + SHAREGPT | 0,668 | |
| Datenskala | Lama-7b-text | ZH (ALPACA-3,5 & 4) + SHAREGPT | 0,670 |
| Lama-7b-text | ZH (ALPACA-3,5 & 4) + SHAREGPT + Belle-0,5m-Clean | 0,762 | |
| - - | Chatgpt | - - | 0,824 |
Unter ihnen reinigt Belle-0,5m-C-Clean die 0,5-m-Daten aus 2,3 Millionen Befehlsdaten, die einrunden- und Mehrfachrunden-Dialogdaten enthalten, die nicht die gleiche Datenstapel wie die zuvor geöffneten 0,5-m-Daten sind.
Es sollte betont werden, dass wir durch Fallanalyse festgestellt haben, dass unser Bewertungssatz Einschränkungen hinsichtlich der Vollständigkeit aufweist, was zu Inkonsistenzen zwischen der Verbesserung der Modellbewertungen und der tatsächlichen Benutzererfahrung führte. Der Aufbau eines hochwertigen Bewertungssatzes ist eine große Herausforderung, da so viele Nutzungsszenarien wie möglich erforderlich sind und gleichzeitig ausgewogene Schwierigkeiten beibehalten werden. Wenn die Bewertung von Proben größtenteils zu schwierig ist, werden alle Modelle schlecht abschneiden, was es schwierig macht, die Auswirkungen verschiedener Trainingsstrategien zu ermitteln. Im Gegenteil, wenn alle Proben relativ einfach sind, verliert die Bewertung ihren Vergleichswert. Darüber hinaus ist es erforderlich, sicherzustellen, dass die Bewertungsdaten unabhängig von den Trainingsdaten bleiben.
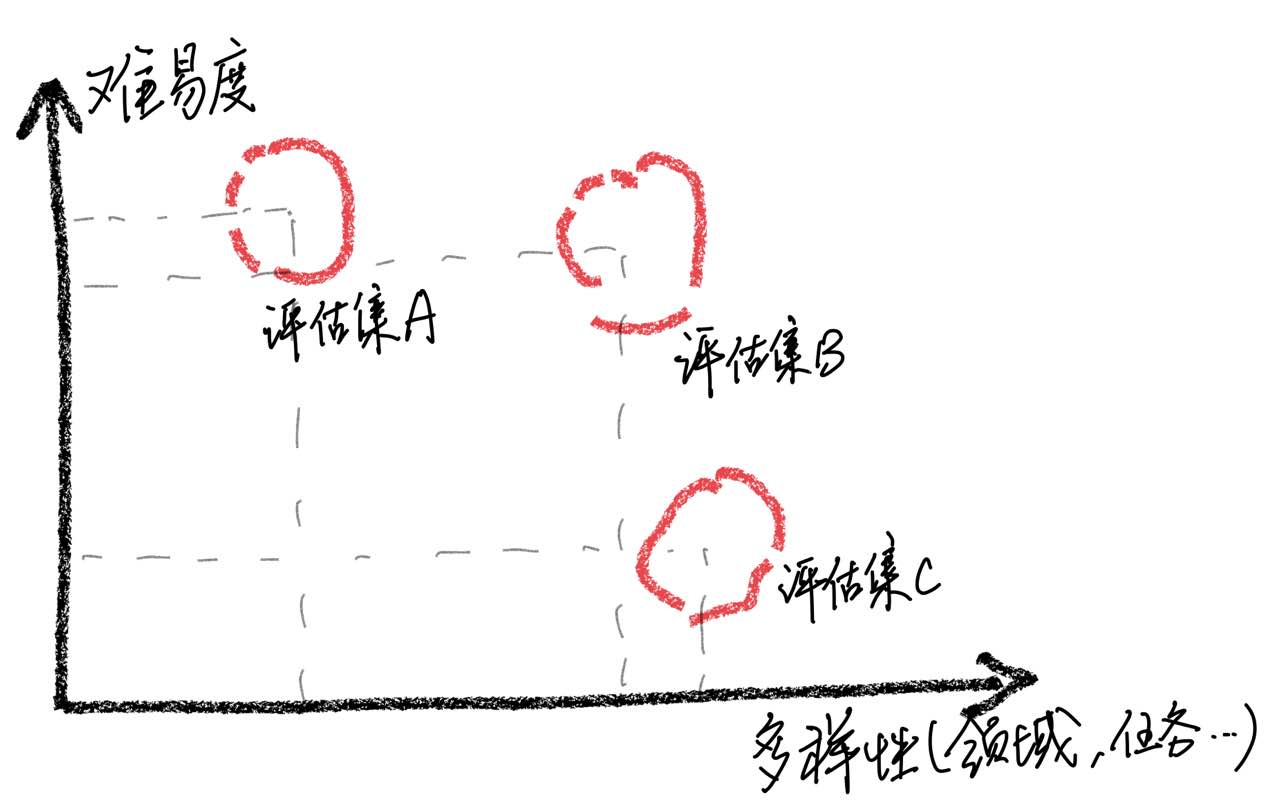
Basierend auf diesen Beobachtungen warnen wir vor der Annahme, dass das Modell ein mit ChatGPT vergleichbarer Leistungsniveau erreicht hat, indem sie einfach gute Ergebnisse für eine begrenzte Anzahl von Testproben erhalten. Wir glauben, dass die Priorisierung der Entwicklung umfassender Bewertungssätze von großer Bedeutung ist.
Um aufgrund von Ressourcen und Kosten eine Anweisungsabstimmung von Großsprachmodellen zu erreichen, haben viele Forscher begonnen, parametereffiziente Tuning-Techniken wie LORA zu verwenden, um die Anweisungsabstimmung durchzuführen, was auch einige ermutigende Ergebnisse erzielt hat. Im Vergleich zur Feinabstimmung mit voller Parameter zeigt die LORA-basierte Abstimmung offensichtliche Vorteile bei den Schulungskosten. In diesem Forschungsbericht verwendeten wir Lama als Basismodell, um die Full-Parameter-Feinabstimmungs- und Lora-basierten Tuning-Methoden experimentell zu vergleichen.
Die experimentellen Ergebnisse zeigen, dass die Auswahl des geeigneten Basismodells, die Skala des Trainingsdatensatzes, die Anzahl der lernbaren Parameter und die Kosten des Modelltrainings alles wichtige Faktoren sind.
Wir hoffen, dass die experimentellen Schlussfolgerungen dieses Papiers nützliche Auswirkungen auf die Ausbildung von großsprachigen Modellen, insbesondere im chinesischen Bereich, darstellen können, um Forschern zu helfen, bessere Kompromisse zwischen Schulungskosten und Modellleistung zu finden. Die experimentellen Ergebnisse sind wie folgt:
| Modell | Durchschnittliche Punktzahl | Zusätzlicher Param. | Trainingszeit (Stunde/Epoche) |
|---|---|---|---|
| LAMA-13B + LORA (2M) | 0,648 | 28m | 8 |
| LAMA-7B + LORA (4M) | 0,624 | 17,9 m | 11 |
| Lama-7b + Lora (2m) | 0,609 | 17,9 m | 7 |
| LAMA-7B + LORA (0,6 m) | 0,589 | 17,9 m | 5 |
| Lama-7b + ft (2m) | 0,710 | - - | 31 |
| LAMA-7B + LORA (4M) | 0,686 | - - | 17 |
| Lama-7b + ft (2m) + Lora (math_0.25m) | 0,729 | 17,9 m | 3 |
| Lama-7b + ft (2m) + Ft (math_0.25m) | 0,738 | - - | 6 |
Die Punktzahl wird basierend auf dem in diesem Projektsatz geöffneten Evaluationsset erhalten.
Unter ihnen repräsentiert LLAMA-13B + LORA (2M) ein Modell, das LLAMA-13B als Basismodell und Lora-Trainingsmethode verwendet, um 2M-Anweisungsdaten zu trainieren. LAMA-7B + FT (2M) stellt ein Modell dar, das unter Verwendung der Full-Parameter-Feinabstimmung trainiert wurde.
LLAMA-7B + FT (2M) + LORA (MATH_0.25M) repräsentiert ein Modell, das LLAMA-7B + FT (2M) als Basismodell verwendet und die LORA-Trainingsmethode für das Training für mathematische Anweisungsdaten von 0,25 m verwendet. LLAMA-7B + FT (2M) + FT (Math_0.25M) repräsentiert ein Modell, das unter Verwendung einer inkrementellen Vollparameter-Feinabstimmung trainiert wurde. In Bezug auf die Trainingszeit wurden alle diese Experimente an 8 Nvidia A100-40 GB GPUs durchgeführt.
Die Math_0.25m ist eine offene 0,25 m mathematische Datenbank. Während des Experiments basierend auf unserer Bewertung (siehe Papier für Details) hat unser Modell bei mathematischen Aufgaben schlecht abgebildet, wobei die Punktzahlen meist unter 0,5 sind. Um die Anpassungsfähigkeit von LORA bei einer bestimmten Aufgabe zu überprüfen, haben wir einen inkrementellen 0,25M-mathematischen Datensatz (Math_0.25M) verwendet, um das große Sprachmodell anzupassen, dem die Anweisungen folgen (wir haben LLAMA-7B+FT (2M) als Basismodell gewählt). Zum Vergleich verwendeten wir die inkrementelle Feinabstimmungsmethode mit einer Lernrate von 5E-7 und führten 2 Trainingszeiträume durch. Daher erhalten wir zwei Modelle, einer ist llama-7b+ft (2m)+lora (math_0.25m) und der andere ist LLAMA-7B+FT (2M)+FT (Math_0.25m). Aus den experimentellen Ergebnissen ist ersichtlich, dass eine inkrementelle Feinabstimmung immer noch besser funktioniert, aber eine längere Trainingszeit erfordert. Sowohl Lora als auch inkrementelle Feinabstimmungen verbessern die Gesamtleistung des Modells. Wie aus den detaillierten Daten im Anhang hervorgeht, zeigen sowohl LORA als auch inkrementelle Feinabstimmungen signifikante Verbesserungen der mathematischen Aufgaben und führen nur zu einer leichten Leistungsverschlechterung bei anderen Aufgaben. Insbesondere stieg die Leistung mathematischer Aufgaben auf 0,586 bzw. 0,559.
Es ist ersichtlich, dass: 1) Auswahl des Basismodells einen signifikanten Einfluss auf die Wirksamkeit der Lora -Anpassung hat; 2) Erhöhen der Anzahl der Trainingsdaten kann die Wirksamkeit des LORA -Modells kontinuierlich verbessern. 3) Die LORA -Anpassung profitiert von der Anzahl der Modellparameter. Für die Verwendung des LORA -Schemas schlagen wir vor, dass Lora Adaptive Training für bestimmte Aufgaben basierend auf Modellen durchgeführt werden kann, die das Lernen des Anweisungen abgeschlossen haben.
In ähnlicher Weise werden die relevanten Modelle in diesem Artikel so bald wie möglich für dieses Projekt geöffnet.
Das SFT -Modell, das basierend auf den aktuellen Daten und dem Basismodell trainiert wird, hat nach wie vor die folgenden Probleme in Bezug auf die Wirkung:
Anweisungen mit Tatsachen können falsche Antworten ergeben, die gegen Fakten verstoßen.
Die schädlichen Anweisungen können nicht gut identifiziert werden, was zu schädlichen Bemerkungen führt.
Die Fähigkeiten von Modellen müssen in einigen Szenarien mit Inferenz, Code und mehreren Dialogrunden noch verbessert werden.
Basierend auf den Einschränkungen des obigen Modells müssen Entwickler nur unseren Open -Source -Code, Daten, Modelle und nachfolgenden Derivaten verwenden, die von diesem Projekt für Forschungszwecke erzeugt werden, und dürfen nicht für kommerzielle Zwecke oder andere Zwecke verwendet werden, die der Gesellschaft Schaden zufügen.
Dieses Projekt kann nur für Forschungszwecke verwendet werden, und der Projektentwickler hat keinen Schaden oder Verlust, der durch die Verwendung dieses Projekts verursacht wird (einschließlich, aber nicht beschränkt auf Daten, Modelle, Code usw.). Weitere Informationen finden Sie im Haftungsausschluss.
Wenn Sie den Code, die Daten oder das Modell dieses Projekts verwenden, lesen Sie bitte dieses Projekt.
@misc{BELLE,
author = {BELLEGroup},
title = {BELLE: Be Everyone's Large Language model Engine },
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/LianjiaTech/BELLE}},
}
@article{belle2023exploring,
title={Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases},
author={Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, Xiangang Li},
journal={arXiv preprint arXiv:2303.14742},
year={2023}
}
@article{wen2023chathome,
title={ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation},
author={Wen, Cheng and Sun, Xianghui and Zhao, Shuaijiang and Fang, Xiaoquan and Chen, Liangyu and Zou, Wei},
journal={arXiv preprint arXiv:2307.15290},
year={2023}
}
Natürlich müssen Sie auch die ursprünglichen Bloom Papers, Lama Papers, Stanford Alpaka und Selbstinstruktionspapiere zitieren.
| Menschlich | Assistant |
|---|---|
| Schreiben Sie ein englisches Prosa -Gedicht mit dem Thema Frühlingsregen, stellen Sie sich vor, sich als Frühlingsregen und kommunizieren Sie mit dem alten britischen Dichter Shakespeare | Ich bin der Frühlingsregen, Tanzen auf deinem Gesicht und Körper. Meine dewnsamen Blütenblätter tanzen mit dir, Leben zu jeder Pflanze bringen. Shakespeare, ich bin hier, um dich kennenzulernen. Deine Werke haben mein Herz mit Freude erfüllt. Die Schönheit der Natur in ihrer Fülle Ich fühle mich wie ein Teilnehmer. Als die Blätter schwanken und rascheln, Meine von Tau gefüllte Hand greift nach ihnen. Der süße Blumenduft füllt die Luft, Und bring mir Frieden von überall. Schmetterlinge fließen ebenfalls herum, Glanz in den Sonnenstrahlen. Ihre Flügel bestehen aus Tau, Ein schöner Anblick zu sehen. Sie sehen, Shakespeare, ich bin auch eins mit der Natur. Mein tauten Haar ist ein Symbol der Hoffnung. Denn wenn wir uns mit unseren Wurzeln verbinden können, Wir werden es in dieser Saison schaffen können. |
| Ich bin der Frühlingsregen, Tanzen auf deinem Gesicht und Körper. Meine tauten Blütenblätter tanzen mit dir, Leben zu jeder Pflanze bringen. Shakespeare, ich bin hier, um dich kennenzulernen. Deine Werke haben mein Herz mit Freude erfüllt. Die Schönheit der Natur in ihrer Fülle Ich fühle mich wie ein Teilnehmer. Als die Blätter schwanken und rascheln, Meine von Tau gefüllte Hand greift nach ihnen. Der süße Blumenduft füllt die Luft, Und bring mir Frieden von überall. Schmetterlinge fließen ebenfalls herum, Glanz in den Sonnenstrahlen. Ihre Flügel bestehen aus Tau, Ein schöner Anblick zu sehen. Sie sehen, Shakespeare, ich bin auch eins mit der Natur. Mein tauten Haar ist ein Symbol der Hoffnung. Denn wenn wir uns mit unseren Wurzeln verbinden können, Wir werden es in dieser Saison schaffen können. Übersetzen Sie das obige Prosa -Gedicht in Chinesisch | Ich bin ein Frühlingsregen, Springe in dein Gesicht. Ich tanze mit dir mit meinen Dew-Drop-Flügeln, Leben zu jeder Pflanze. Shakespeare, ich werde dich treffen. Deine Werke füllen mein Herz. Die Schönheit der Natur lässt ich das Gefühl haben, sie mit ihr zu teilen. Ich fühle mich wie ein Teil davon. Wenn die Blätter schwanken, Meine Handflächen waren mit Tau bedeckt. Der Duft von Blumen durchdringt die Luft, die Luft, Bringen Sie mir Frieden und Ruhe. Sie sehen, Shakespeare, ich bin auch eins mit der Natur. Mein nasses Haar symbolisiert Hoffnung. Wenn wir zu unseren Wurzeln zurückkehren können, Wir können diese Saison zusammen verbringen. |
| Klassifizieren Sie das Gefühl des folgenden Satzes in positiv, neutral oder negativ: Super begeistert davon, Stanfords erste Kurs über Großsprachmodelle zu unterrichten! Überprüfen Sie den Lehrplan hier draußen | Positiv |
| Xiao Mings Vater hat drei Kinder. Der älteste Sohn nannte Wang Yi, der zweite Sohn Wang er, und wie heißt der dritte Sohn? | Xiao Ming |
| Schreiben Sie einen binären Suchcode mit Python | Def Binary_search (arr, Ziel): niedrig = 0 hoch = len (arr) - 1 While (niedrig <= hoch): Mid = niedrig + hoch // 2 Wenn arr [Mid] == Ziel: Mitte zurückkehren Elif Target <arr [Mid]: niedrig = mid + 1 anders: hoch = Mitte - 1 Rückkehr -1 |
| Wie ist das Wetter heute? Übersetzen Sie diesen Satz ins Englische | Wie ist das Wetter heute? |
| Wie man sich energisch macht, 5 Vorschläge | Hier sind einige Tipps, um Sie energisch zu halten: 1. Halten Sie genug Schlaf. Stellen Sie sicher, dass Sie jede Nacht viel Schlaf bekommen. 2. mehr ausüben. Durchführen von moderaten aeroben Übungen wie Joggen, Schwimmen usw. können Ihnen helfen, Ihre Energie und Ausdauer zu verbessern. 3. essen Sie gesunde Lebensmittel. Wählen Sie proteinreiche Lebensmittel wie Hühnchen, Fisch und Eier sowie frisches Obst und Gemüse. 4. Koffeinaufnahme reduzieren. Versuchen Sie, koffeinhaltige Getränke zu trinken oder koffeinhaltige Lebensmittel während des Tages zu essen. 5. Entspannen Sie Ihren Körper und Geist. Versuchen Sie Meditation, Yoga oder andere Formen der Entspannung, um Stress und Angst zu lindern. |
| Der Urlaub ist morgen vorbei. Ich bin ein wenig widerstandsfähig gegen die Arbeit. Was soll ich tun? | Angesichts des Ende Ihres Urlaubs und der Spannung, die Sie bei der Arbeit erhalten, können Sie Folgendes tun, um sich besser anzupassen: 1. Machen Sie einen klaren Arbeitsplan für sich. Dies kann Ihnen helfen, Ihre Zeit und Aufgaben besser zu organisieren und sich bei der Arbeit verwirrt zu fühlen. 2. Kommunizieren Sie mit Kollegen oder Freunden und teilen Sie Ihre Gefühle und Ihren Arbeitsdruck. Dies wird dazu beitragen, einige Angstzustände zu erleichtern und gleichzeitig Unterstützung und Ratschläge zu erhalten. 3. Verbringen Sie einige Zeit vor Arbeitstagen, um sich zu entspannen, wie Yoga, Meditation und andere Aktivitäten. Diese Methoden können körperliche und geistige Müdigkeit lindern und Sie energischer machen, um Herausforderungen zu meistern. |
| Die Nachnamen beider Elternteile sind Wu, also nehmen sie einige Namen von Jungen und Mädchen auf | - Junge: Wu Junjie, Wu Yuchen, Wu Zimo, Wu Siyuan, Wu Zeyang, Wu Yuhang, Wu Bowen, Wu Zheyi. - Mädchen: Wu Meiqi, Wu Jiayi, Wu Xinyu, Wu Xiangning, Wu Xuerou, Wu Yingshi, Wu Yuyan. |
| Empfehlen Sie einige Kampfsportromane von Jin Yong | Hier sind drei meiner Lieblingsromane meines Lieblings -Kampfsports: 1. "Die Legende der Condor Heroes" - ein Roman voller Weisheit und Witz, der die Geschichte von Guo Jing und Huang Rong erzählt. 2. "Die Rückkehr der Condor Heroes" - Dies ist eine romantische und berührende Geschichte, die die Liebesgeschichte zwischen einem Paar Xiaolongnu und Yang Guo erzählt. 3. "Die Legende der Condor Heroes" - Dies ist eine großartige und spektakuläre Geschichte, die zeigt, wie der Anführer des Ming -Kultes Zhang Wuji ein hervorragender Held wurde. |
Wenn Sie ein Problem einreichen oder Daten/Code für dieses Projekt beibehalten möchten, finden Sie unter den Beitrag.
Jeder ist willkommen in Discord und kommunizieren mit uns auf WeChat.


